DataWorks基于MaxCompute、Hologres、EMR、AnalyticDB、CDP等大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。本文以DataWorks的部分核心功能为例,指导您使用DataWorks接入数据并进行业务处理、周期调度以及数据可视化。
入门简介
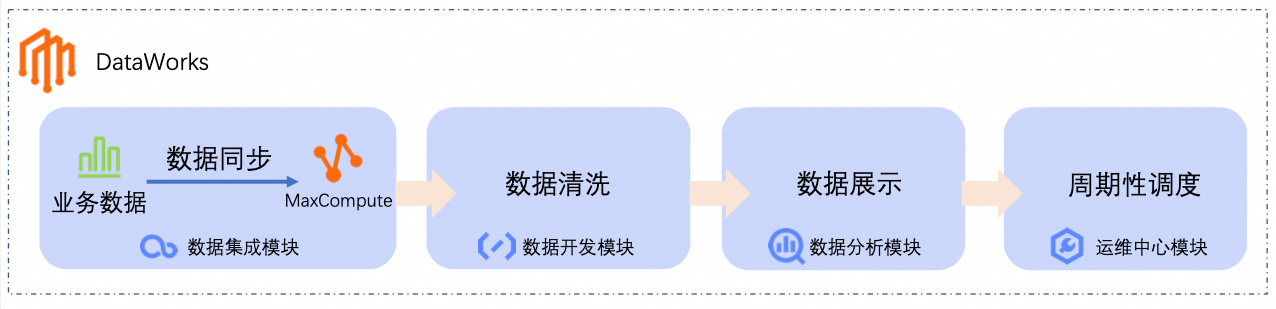
本教程以电商场景为例,演示如何构建从原始数据接入→数据分析计算→可视化输出的完整数据管道,通过标准化的开发流程,快速搭建可复用的数据生产链路,保证调度可靠性与运维可观测性。使业务人员无需深入技术细节即可完成数据价值转换,降低企业大数据应用门槛。
通过本教程,您可以快速完成以下操作。
数据同步:通过DataWorks的数据集成模块,创建离线同步任务,将业务数据同步至大数据计算平台(如MaxCompute)。
数据清洗:在DataWorks的数据开发模块中,对业务数据进行处理、分析和挖掘。
数据展示:在DataWorks的数据分析模块中,将分析结果转化为图表,便于业务人员理解。
周期性调度:为数据同步和数据清洗流程配置周期性调度,使其定时执行。
本教程从公开数据源同步原始商品和订单数据至MaxCompute中,通过如下数据分析流程,产出每日最畅销商品类目排名:

前提条件
为确保本教程可以顺利进行,推荐使用阿里云主账号或具备AliyunDataWorksFullAccess权限的RAM用户。具体操作,请参见准备阿里云账号(主账号)或准备RAM用户(子账号)。
DataWorks提供了完善的权限管控机制,支持在产品级与模块级对权限进行管控,如果您需要更精细的权限控制,请参见DataWorks权限体系功能概述。
准备工作
(可选)开通免费试用
开通DataWorks
本教程以华东2(上海)地域为例,介绍DataWorks快速入门,您需要登录DataWorks管理控制台,切换至华东2(上海)地域,查看该地域是否开通DataWorks。
本教程以华东2(上海)为例,在实际使用中,请根据实际业务数据所在位置确定开通地域:
如果您的业务数据位于阿里云的其他云服务,请选择与其相同的地域。
如果您的业务在本地,需要通过公网访问,请选择与您实际地理位置较近的地域,以降低访问延迟。
全新用户
如果您为新用户,首次使用DataWorks,将显示如下内容,表示当前地域尚未开通DataWorks,需要单击0元组合购买。

配置组合购买页相关参数。
参数
说明
示例
地域
选择需要开通DataWorks的地域。
华东2(上海)
DataWorks版本
选择需要购买的DataWorks版本。
说明本教程以基础版为例,所有版本均可体验本教程所涉及的功能,您可以参考DataWorks各版本功能详情,根据实际业务需要,选择合适的DataWorks版本。
基础版
DataWorks资源组
通过DataWorks进行数据集成、数据开发、数据调度等任务时,需要消耗计算资源,您需要配套购买资源组,以确保后续任务的顺利运行。
资源组名称:自定义
专有网络(VPC)、交换机(V-Switch):
没有VPC和交换机:如果不配置,DataWorks将自动创建。您也可以单击参数说明中对应的控制台链接手动创建。
已有VPC和交换机:选择已有的VPC和交换机。
说明VPC和交换机的更多信息,请参见什么是专有网络VPC。
服务关联角色:根据页面提示,单击创建服务关联角色。
单击确认订单并支付,完成后续支付。
开通过但已到期
如果您在华东2(上海)地域曾经开通过DataWorks,但DataWorks版本已到期,则会出现如下提示,需要单击购买版本。

配置购买页相关参数。
参数
说明
示例
版本
选择需要购买的DataWorks版本。
说明本教程以基础版为例,所有版本均可体验本教程所涉及的功能,您可以参考DataWorks各版本功能详情,根据实际业务需要,选择合适的DataWorks版本。
基础版
地域和可用区
选择需要开通DataWorks的地域。
华东2(上海)
单击立即购买,完成后续支付。
您在购买DataWorks版本后,如未找到相关DataWorks版本,可进行以下操作:
等待几分钟刷新页面,系统更新可能会有延迟。
查看所在地域是否与购买DataWorks版本地域一致,防止因地域选择问题,未找到相关DataWorks版本。
已开通
如果您在华东2(上海)地域已开通DataWorks,将会进入DataWorks概览页,可直接进行下一步。
创建工作空间
创建资源组并绑定工作空间
为资源组开通公网
本教程使用的电商平台公开测试业务数据需要通过公网获取,而上一步创建的通用型资源组默认不具备公网访问能力,需要为资源组绑定的VPC配置公网NAT网关,添加EIP,使其与公开数据的网络打通,从而获取数据。
登录专有网络-公网NAT网关控制台,在顶部菜单栏切换至华东2(上海)地域,单击创建公网NAT网关。配置相关参数。
说明表中未说明的参数保持默认值即可。
参数
取值
地域
华东2(上海)。
网络及可用区
选择资源组绑定的VPC和交换机。
您可以前往DataWorks资源组列表页,切换至华东2(上海)地域,找到已创建的资源组,然后单击操作列的网络设置,在数据调度 & 数据集成区域查看绑定专有网络和交换机。VPC和交换机的更多信息,请参见什么是专有网络VPC。
网络类型
公网NAT网关。
弹性公网IP
新购弹性公网IP。
关联角色创建
首次创建NAT网关时,需要创建服务关联角色,请单击创建关联角色。
单击立即购买,完成后续支付,创建NAT网关实例。

NAT网关实例购买成功后,单击返回控制台,为刚购买的NAT网关实例创建SNAT条目。
说明只有配置了SNAT条目后,使用该VPC的资源组才能访问公网。
单击新购实例操作列的管理按钮,进入目标NAT网关实例的管理页面,并切至SNAT管理页签。
在SNAT条目列表下单击创建SNAT条目按钮,创建NAT条目,以下为关键配置:
参数
取值
SNAT条目粒度
选择VPC粒度,确保NAT网关所属VPC内的所有资源组都可通过配置的弹性公网IP访问公网。
选择弹性公网IP地址
配置当前NAT网关实例绑定的弹性公网IP地址。
完成SNAT条目参数配置后,单击确定创建按钮,创建SNAT条目。
在SNAT条目列表下,当新创建的SNAT条目的状态变成可用后,即表示资源组绑定的VPC已具备公网访问能力。
创建并绑定MaxCompute计算资源
操作步骤
本文以如下场景为例,指导您快速体验DataWorks的相关功能:
假设某一电商平台将商品信息、订单信息存储在MySQL数据库中,需要定期对订单数据进行分析,通过可视化的方式查看每日最畅销商品类目排名表。
一、数据同步
创建数据源
DataWorks通过创建数据源的方式,接入数据来源和数据去向,本步骤需要创建MySQL数据源,用于连接数据来源(存储业务数据的MySQL数据库),为本教程提供原始业务数据。
您无需准备本教程使用的原始业务数据,为方便测试和学习,DataWorks为您提供测试数据集,相关表数据已存储在公网MySQL数据库中,您只需创建MySQL数据源接入即可。
前往DataWorks管理中心页,切换至华东2(上海)地域,在下拉框中选择已创建的工作空间后,单击进入管理中心。
在左侧导航栏单击数据源,进入数据源列表页,单击新增数据源,选择MySQL类型,配置MySQL数据源相关参数。
说明表中未说明的参数保持默认值即可。
首次新增数据源时,需要完成跨服务授权,请根据页面提示,授权服务关联角色AliyunDIDefaultRole。
参数
描述
数据源名称
本示例为MySQL_Source。
配置模式
选择连接串模式。
连接地址
主机地址IP:
rm-bp1z69dodhh85z9qa.mysql.rds.aliyuncs.com端口号:
3306。
重要本教程提供的数据仅作为阿里云大数据开发治理平台 DataWorks数据应用实操使用,所有数据均为测试数据,并且仅支持在数据集成模块读取数据。
数据库名称
配置为
retail_e_commerce。用户名
输入用户名
workshop。密码
输入密码
workshop#2017。在连接配置区域,切换至数据集成页签,找到工作空间已绑定的资源组,单击连通状态列的测试连通性。
说明如果MySQL数据源连通性测试失败,请进行以下操作:
完成连通性诊断工具后续操作。
请检查是否为资源组绑定的VPC配置EIP,MySQL数据源需要资源组具备公网访问能力。详情请参见为资源组开通公网。
单击完成创建。
搭建同步链路
本步骤需要搭建同步链路,将电商平台商品订单数据同步至MaxCompute的表中,为后续加工数据做准备。
单击左上方的
 图标,选择,进入数据开发页面。
图标,选择,进入数据开发页面。在页面顶部切换至本教程创建好的工作空间,在左侧导航栏单击
 ,进入数据开发-项目目录页面。
,进入数据开发-项目目录页面。在项目目录区域,单击
 ,选择新建工作流,设置工作流名称。本教程设置为
,选择新建工作流,设置工作流名称。本教程设置为dw_quickstart。在工作流编排页面,从左侧拖拽虚拟节点和离线同步节点至画布中,分别设置节点名称。
本教程节点名称示例及作用如下:
节点类型
节点名称
节点作用
 虚拟节点
虚拟节点workshop用于统筹管理整个用户画像分析工作流,可使数据流转路径更清晰。该节点为空跑任务,无须编辑代码。
 离线同步节点
离线同步节点ods_item_info用于将存储于MySQL的商品信息源表
item_info同步至MaxCompute的ods_item_info表。离线同步节点ods_trade_order用于将存储于MySQL的订单信息源表
trade_order同步至MaxCompute的ods_trade_order表。手动拖拽连线,将
workshop节点设置为两个离线同步节点的上游节点。最终效果如下:
工作流调度配置。
在工作流编排页面右侧单击调度配置,配置相关参数。以下为本教程所需配置的关键参数,未说明参数保持默认即可。
调度配置参数
说明
调度参数
为整个工作流设置调度参数,工作流中的内部节点可直接使用。
本教程配置为
bizdate=$[yyyymmdd-1],获取前一天的日期。说明DataWorks提供的调度参数,可实现代码动态入参,您可在SQL代码中通过
${变量名}的方式定义代码中的变量,并在调度配置 > 调度参数处,为该变量赋值。调度参数支持的格式,详情请参见调度参数支持的格式。调度周期
本教程配置为
日。调度时间
本教程配置调度时间为
00:30,该工作流会在每日00:30启动。周期依赖
工作流无上游依赖,可不配置。为了方便统一管理,您可以单击使用工作空间根节点,将工作流挂载到工作空间根节点下。
工作空间根节点命名格式为:
工作空间名_root。
配置同步任务
配置初始节点
配置商品信息同步链路(ods_item_info)
配置订单数据同步链路(ods_trade_order)
二、数据清洗
数据从MySQL同步至MaxCompute后,获得两张数据表(商品信息表ods_item_info和订单信息表ods_trade_order),您可以在DataWorks的数据开发模块对表中数据进行清洗、处理和分析,从而获取每日最畅销商品类目排名表。
搭建数据加工链路
在Data Studio左侧导航栏单击
 ,进入数据开发页面,然后在项目目录区域找到已创建好的工作流,单击进入工作流编排页,从左侧拖拽MaxCompute SQL节点至画布中,分别设置节点名称。
,进入数据开发页面,然后在项目目录区域找到已创建好的工作流,单击进入工作流编排页,从左侧拖拽MaxCompute SQL节点至画布中,分别设置节点名称。本教程节点名称示例及作用如下:
节点类型
节点名称
节点作用
 MaxCompute SQL
MaxCompute SQLdim_item_info基于
ods_item_info表,处理商品维度数据,产出商品基础信息维度表dim_item_info。MaxCompute SQLdwd_trade_order基于
ods_trade_order表,对订单的详细交易数据进行初步清洗、转换和业务逻辑处理,产出交易下单明细事实表dwd_trade_order。MaxCompute SQLdws_daily_category_sales基于
dwd_trade_order表和dim_item_info表,对DWD层经过清洗和标准化的明细数据进行汇总,产出每日商品类目销售汇总表dws_daily_category_sales。MaxCompute SQLads_top_selling_categories基于
dws_daily_category_sales表,产出每日最畅销商品类目排名表ads_top_selling_categories。手动拖拽连线,配置各节点的上游节点。最终效果如下:

配置数据加工节点
配置dim_item_info节点
配置dwd_trad_order节点
配置dws_daily_category_sales节点
配置ads_top_selling_categories节点
三、调试运行
工作流配置完成后,在发布到生产环境前,您需要运行整个工作流,验证工作流的配置是否正确。
在Data Studio左侧导航栏单击
,进入数据开发页面,然后在项目目录区域找到已创建好的工作流。单击节点工具栏的运行,填写本次运行值为当前日期的前一天(例如
20250416)。说明在工作流节点配置中,已使用了DataWorks提供的调度参数,实现了代码动态入参,调试运行时需为该参数赋值常量进行测试。
单击确定,进入调试运行页面。
等待运行完成,预期运行结果如下:

四、数据查询与展示
您已经将从MySQL中获取的原始测试数据,经过数据开发处理,汇总于表ads_top_selling_categories中,现在可查询表数据,查看数据分析后的结果。
单击左上角
 图标,在弹出页面中单击。
图标,在弹出页面中单击。在我的文件后单击
 > 新建文件,自定义文件名后单击确定。
> 新建文件,自定义文件名后单击确定。在SQL查询页面,配置如下SQL。
SELECT * FROM ads_top_selling_categories WHERE pt=${bizdate};在右上角选择MaxCompute数据源后单击确定。
单击顶部的运行按钮,在成本预估页面,单击运行。
在查询结果中单击
 ,查看可视化图表结果,您可以单击图表右上角的
,查看可视化图表结果,您可以单击图表右上角的 自定义图表样式。自定义图表样式的更多信息,请参见可视化卡片和报告。
自定义图表样式。自定义图表样式的更多信息,请参见可视化卡片和报告。
您也可以单击图表右上角保存,将图表保存为卡片,然后在左侧导航栏单击卡片(
 )查看。
)查看。
五、周期性调度
通过完成前文操作步骤,您已经获取了前一天各类商品的销售数据,但是,如果需要每天获取最新的销售数据,则可以将工作流发布至生产环境,使其周期性定时执行。
在配置数据同步和数据加工时,已同步为工作流、同步节点以及数据加工节点配置了调度相关参数,此时无需再配置,只需将工作流发布到生产环境即可。调度配置的更多详细信息,请参见节点调度配置。
单击左上角
图标,在弹出页面中单击。在Data Studio左侧导航栏单击
,进入数据开发页面,切换至本案例使用的项目空间,然后在项目目录区域找到已创建好的工作流。单击节点工具栏的发布,在发布面板中单击开始发布生产,等待发布包构建和生产检查器完成后,单击确认发布。
发布到生产环境状态为已完成后,单击去运维,前往运维中心。

在中即可看到工作流的周期任务(本教程工作流命名为
dw_quickstart)。如需查看工作流内子节点的周期任务详情,请右键工作流的周期任务,选择查看内部任务。

预期结果如下:

下一步
附录:资源释放与清理
如果您需要释放本次教程所创建的资源,具体操作步骤如下:
停止周期任务。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入运维中心。
在中,勾选所有之前创建的周期任务(工作空间root节点无需下线),然后在底部单击。
删除数据开发节点并解绑MaxCompute计算资源。
进入DataWorks工作空间列表页,在顶部切换至目标地域,找到已创建的工作空间,单击操作列的,进入Data Studio。
在Data Studio左侧导航栏单击
,进入数据开发页面,然后在项目目录区域找到已创建好的工作流,右键工作流,单击删除。在左侧导航栏,单击
 > 计算资源管理,找到已绑定的MaxCompute计算资源,单击解绑。在确认窗口中勾选选项后按照指引完成解绑。
> 计算资源管理,找到已绑定的MaxCompute计算资源,单击解绑。在确认窗口中勾选选项后按照指引完成解绑。
删除MySQL数据源。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入管理中心。
在左侧导航栏单击数据源,进入数据源列表页,找到已创建的MySQL数据源,单击操作列的删除,按照指引完成删除。
删除MaxCompute项目。
前往MaxCompute项目管理页面,找到已创建的MaxCompute项目,单击操作列的删除,按照指引完成删除。
删除公网NAT网关并释放弹性公网IP。
前往专有网络-公网NAT网关控制台,在顶部菜单栏切换至华东2(上海)地域。
找到已创建的公网NAT网关,单击操作列的
 > 删除,在确认窗口中,勾选强制删除,然后单击确定。
> 删除,在确认窗口中,勾选强制删除,然后单击确定。在左侧导航栏单击,找到已创建的弹性公网IP,单击操作列中
> 实例管理 > 释放,在确认窗口中单击确定。