当您需要大文件或多文件的纯文件复制时,可以使用DataWorks创建DistCp任务,该方式能够极大的提高同步传输的效率,实现跨文件系统、大规模数据迁移和同步需求。
背景信息
什么是DistCp任务
DistCp(Distributed Copy)是一种分布式数据拷贝工具,最初是 Apache Hadoop 生态系统中的核心组件,用于在 Hadoop 集群之间或 HDFS 内部进行大规模数据迁移。
在阿里云 DataWorks 环境中,您可以为DataWorks工作空间绑定E-MapReduce计算资源,使用Hadoop组件里的distcp 工具创建跨文件系统(如 OSS、HDFS等)的数据传输任务,实现企业级大批量文件数据迁移和同步。
DistCp任务的优势
跨文件系统:
支持多种文件系统间同步,包括:OSS、OSS-HDFS、HDFS、AWS S3、腾讯云COS等文件系统。
分布式并行处理:
通过多线程并行拷贝,利用集群资源加速传输,避免单点性能瓶颈。
适用场景
适用于大文件或多文件的纯文件复制传输,例如将数据从HDFS 迁移到阿里云 OSS。
前提条件
开通基础版DataWorks服务并创建简单模式工作空间即可实现此功能,您也可以按需选择。
已创建Serverless资源组并绑定至已创建的工作空间。
该功能仅使用调度能力,Serverless资源组任务调度计费按实例运行成功数计费,不使用计算资源,因此,本案例购买按量付费资源组,不会产生CU计算费用。
注意事项
一、DataWorks工作空间绑定EMR计算资源
创建DistCp任务需要使用EMR集群中的distcp工具,因此需要先创建EMR集群并将其绑定为DataWorks的计算资源。
配置要点(以下仅为关键配置,其他参数保持默认或按需配置即可):
业务场景选择数据湖。
专有网络和交换机推荐与DataWorks资源组选择相同专有网络和交换机。
您需要确保EMR集群配置的专有网络和交换机与即将进行的数据传输来源和去向网络已连通。
二、创建手动任务EMR Shell节点
DistCp任务需要在DataWorks数据开发中创建手动任务来执行。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
在左侧导航栏单击
 ,进入手动业务流程,然后单击,自定义业务流程名称(本教程业务流程名称设置为
,进入手动业务流程,然后单击,自定义业务流程名称(本教程业务流程名称设置为distcp_flow)。右键已创建的业务流程,选择,自定义节点名称(本教程节点名称设置为
distcp_test)。
三、配置DistCp任务
在EMR Shell节点编辑区域,配置如下DistCp任务内容。
cat>dataworks.distcp.json<<EOF
<同步任务配置JSON>
EOF
/opt/taobao/tbdpapp/emrwrapper/dataworks-distcp.sh dataworks.distcp.json
<同步任务配置JSON>部分需要按任务配置说明的格式要求进行配置。
任务配置说明
DistCp任务的JSON配置文件主要包括reader、writer、setting三部分。
reader部分主要配置读取端的参数配置,例如读取哪些文件。
writer部分主要配置写入端的参数配置,例如写入目录、写入策略等。
setting部分主要配置任务粒度的整体参数,例如流控、是否容忍脏数据等。
JSON格式如下:
{
"type": "job",
"version": "2.0",
"steps": [
{
"stepType": "hdfs",
"parameter": {},
"name": "Reader",
"category": "reader"
},
{
"stepType": "hdfs",
"parameter": {},
"name": "Writer",
"category": "writer"
}
],
"setting": {}
}在DataWorks中,reader、writer、setting部分的配置方法与开源hadoop distcp类似,具体参数说明如下:
reader端配置
参数 | 说明 | 配置示例 |
path | 用于控制数据同步读取的目录,来自源头的数据会按照目录层次依次读取,写入到对应的目标文件系统。 配置格式:一个字符串数组,表示可以读取多个源头目录。 默认值:无。 |
|
pattern | 用于控制数据读取的文件过滤器,在源头目录path下,只有通过过滤器校验的文件,才会传输到目标端。pattern过滤器会对源头path每个目录地址生效。您可以控制哪些文件应该被包括(include)或排除(exclude)在复制操作中。 配置格式:一个字符串数组,每个过滤元素前面的 默认值:空,表示不做过滤,全部传输。 |
|
splitMode | 用于控制数据同步的策略,主要会影响数据读取端的切分策略。支持的切分并发策略有:
默认值:uniformsize,默认使用统一大小策略。 |
|
listFileConcurrent | 用于控制列出待同步文件的并发数,更大的并发在寻找文件时更快。 默认值:1,最大允许设置为40,超过40会被设置为40。 | |
writer端配置
参数 | 说明 | 配置示例 |
path | 用于控制数据同步写入的目录,来自源头的数据会按照目录层次依次写入到目标path目标下。 配置格式:一个字符串。 默认值:无。 |
|
enableRelative | 用于控制数据同步写入的目录行为。
默认值:false。 |
|
writeMode | 表示数据写入模式,目前支持三种写出模式:overwrite、update、append,各个参数含义如下:
默认值:无,此参数为必选参数。 |
|
preserveStatus | 用于控制文件同步时,是否同步文件元数据。取值范围:
配置格式:一个字符串数组,表示可以同步多个元数据。 默认值:空,表示不同步元数据。 |
|
chunkSize | 表示在文件传输时,是否将文件根据分块大小做切分传输,传输到目标端后再做文件内容合并。只有源文件系统支持 默认值:0,表示不切分。 |
|
bufferSize | 表示数据缓冲的大小,会影响数据写入的效率。 默认值: |
|
deleteMissingSource | 表示目标端文件存在,但是源头不存在的情况下,是否删除目标端文件和目录。 取值范围:
默认值:false。 |
|
hadoopConfig | 您可以在hadoopConfig中配置访问目标hdfs的高级配置,例如oss、oss-hdfs的访问地址:
| |
setting端配置
参数 | 说明 | 配置示例 |
skipCrcCheck | 用于表示是否跳过源头和目标的CRC校验。 重要 writeMode为append的情况下,skipCrcCheck会被强制设置为true。 取值范围:
默认值:false。 |
|
checksumCombineMode | 在开启CRC检查的情况下,如果源和目标是异构系统,可能出现报错: 您可以设置 也可以使用此参数,确定在使用 DistCp 进行文件复制时,源存储系统与目标存储系统之间校验和的生成和合并策略。取值范围:
|
|
ignoreFailures | 用于控制是否忽略同步传输中的错误,即个别文件同步失败不中断任务执行。 取值范围:
默认值:false。 |
|
concurrent | 用于表示任务传输的并发度,最多会有concurrent个文件处于传输状态。在底层上,concurrent是MapReduce程序的Map最大并行度。 默认值:10,表示传输的并发度是10。 |
|
mbps | 用于控制任务传输中,每个并发的流速上限,同步程序会保障每个并发传输的速度上限在mbps之下。mbps单位为MB/s,整个任务的速度上限为 取值范围:
默认值:-1。 |
|
queue | 用于表示任务运行的队列,文件同步任务在底层是一个MapReduce程序,通过queue限制任务运行的队列(配置为yarn的队列名),可以起到监控和限制任务资源使用的目的。 默认值:无。 |
|
四、发布任务
单击EMR Shell节点顶部工具栏的保存( ),然后单击提交(
),然后单击提交( )。如果是标准模式环境,还需要将节点发布至生产环境,详情请参见发布任务。
)。如果是标准模式环境,还需要将节点发布至生产环境,详情请参见发布任务。
五、运行任务
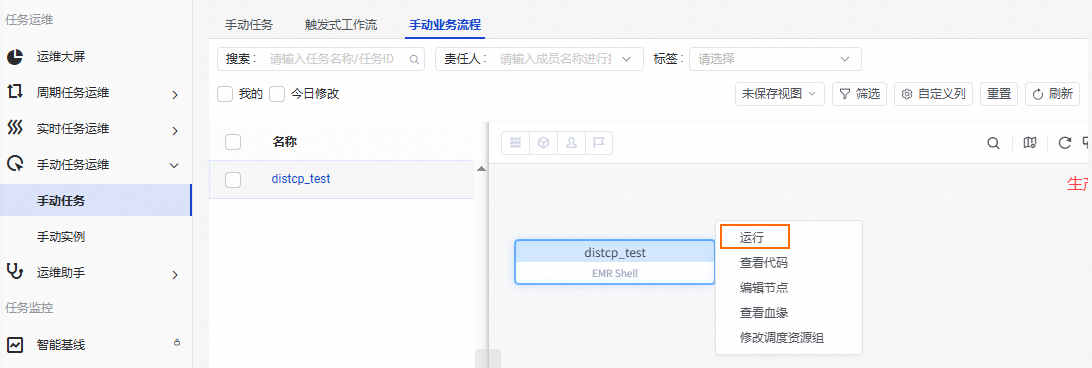
单击页面左上角的
 ,选择,进入运维中心。
,选择,进入运维中心。在运维中心左侧导航栏单击,然后在页面右侧切换至手动业务流程,找到已创建的EMR Shell节点(本教程节点名为
distcp_test)。右键EMR Shell节点,选择运行。
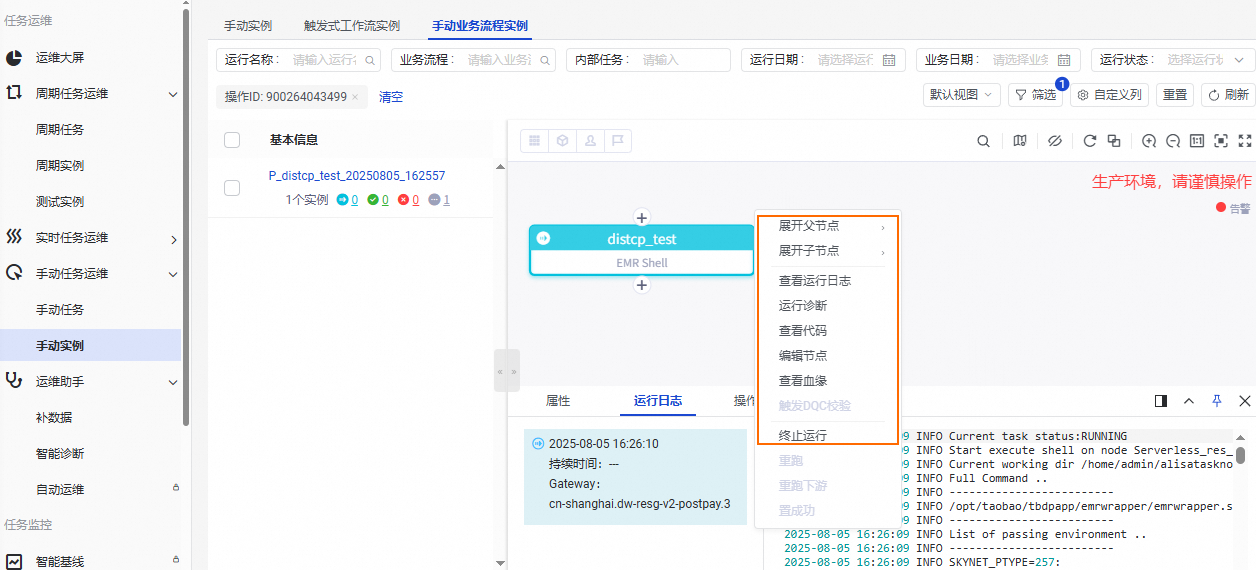
六、查看日志和运维
节点运行后,您可以在左侧导航栏单击,找到已经运行的任务实例,右键选择查看运行日志、停止运行等运维操作。