
本文以“使用DataWorks实时同步公共数据至Hologres,并通过Hologres进行实时数据分析”为例,为您展示DataWorks的数据同步能力与Hologres的实时分析能力。本教程以申请免费资源为例为您示例详细操作步骤,您也可以使用付费资源,操作类似。
教程简介
本教程基于GitHub Archive公开数据集,通过DataWorks将GitHub中的项目、行为等20多种事件类型数据实时采集至Hologres进行分析,同时使用DataV内置模板,快速搭建实时可视化数据大屏,从开发者、项目、编程语言等多个维度了解GitHub实时数据变化情况。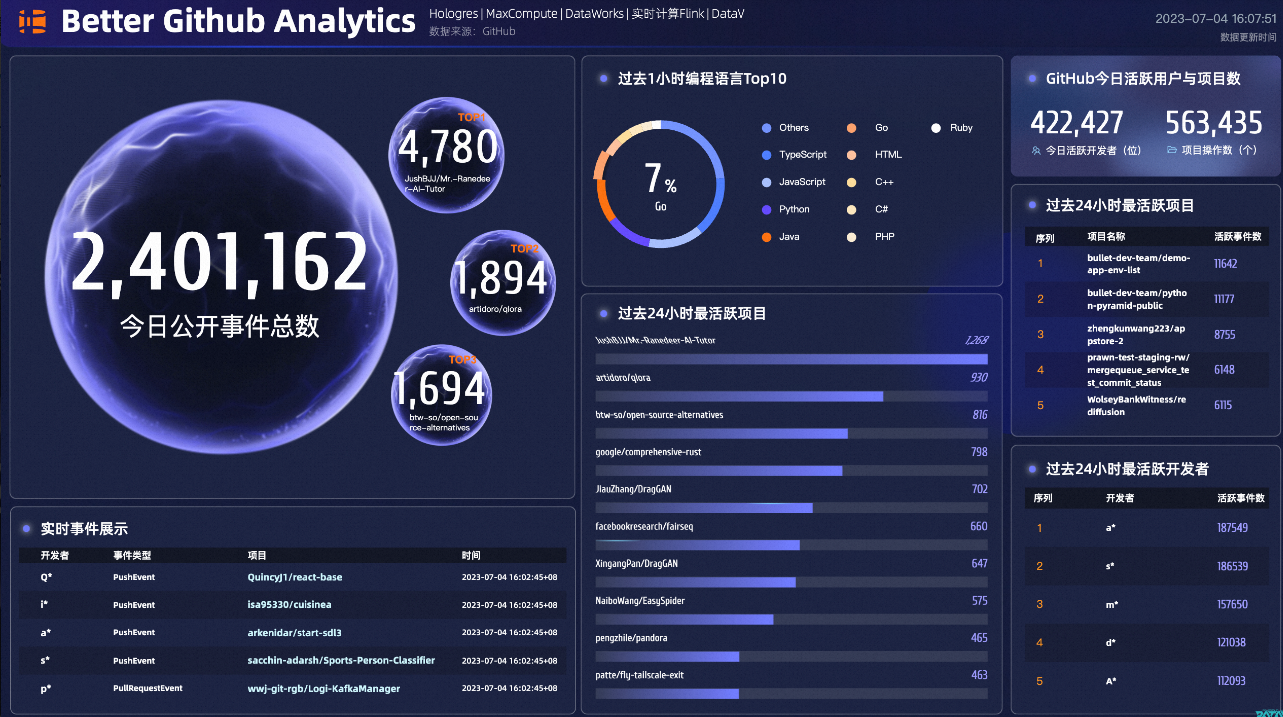
我能学到什么
学会通过DataWorks实时同步数据。
熟悉使用DataV大屏进行可视化操作。
操作难度 | 易 |
所需时间 | 55分钟 |
使用的阿里云产品 | |
所需费用 |
|
准备环境和资源
新用户准备阿里云账号
进入阿里云官网,单击免费注册,创建阿里云账号。
对阿里云账号进行实名认证。
创建访问密钥AccessKey。
成功创建AccessKey后,返回AccessKey页面。您可查看当前账号的AccessKey状态。
相关操作,详情请参见准备阿里云账号。
创建专有网络VPC和交换机
为确保后续任务的网络连通,请务必保证DataWorks资源组与Hologres使用同一个VPC。创建VPC及交换机操作如下:
登录专有网络管理控制台,在顶部菜单栏切换至华东2(上海)地域。
在左侧导航栏单击专有网络。
在专有网络页面,单击创建专有网络。
在创建专有网络页面,配置1个专有网络(VPC)和1台交换机,交换机的可用区选择上海可用区E,然后单击确定。详情请参见创建专有网络和交换机。
单击已创建的VPC实例ID,在资源管理页签添加安全组。详情请参见创建安全组。
为VPC绑定EIP
本教程使用了GitHub Archive公开数据集,DataWorks的通用型资源组默认不具备公网能力,因此需要为资源组绑定的VPC配置公网NAT网关,使其与公开数据网络打通,从而获取数据。
登录专有网络-公网NAT网关控制台,在顶部菜单栏切换至华东2(上海)地域。
单击创建NAT网关。配置相关参数:
参数
取值
所属地域
华东2(上海)。
所属专有网络
选择已创建的VPC和交换机。
关联交换机
访问模式
VPC全通模式(SNAT)。
弹性公网IP
新购弹性公网IP。
说明上表中未说明的参数保持默认值即可。
单击立即购买,勾选服务协议后,单击确认订单,完成购买。
申请Hologres免费试用
登录Hologres免费试用,单击立即试用,在弹出的实时数仓Hologres界面配置参数信息。本试用教程以表格中的参数信息为例,未提及参数保持默认值。
参数
示例值
地域
华东2(上海)
实例类型
通用型
可用区
可用区E
计算资源
32核128G(计算节点数量:2)
专有网络(VPC)
选择已创建的VPC。
专有网络交换机
选择已创建的交换机。
实例名称
hologres_test
服务关联角色
按照界面指引创建。
角色名称:
AliyunServiceRoleForHologresIdentityMgmt权限说明:Hologres使用此角色来访问您在其他云产品中的资源。
资源组
默认资源组
勾选服务协议后,单击立即试用,并根据页面提示完成试用申请。
单击控制台,开启试用体验。
申请MaxCompute免费试用
体验本文案例,您需开通DataWorks及MaxCompute。对于MaxCompute,可选择如下类型产品:
免费试用:您可申请MaxCompute提供的免费试用资源。试用期结束后,如需继续使用,则会收取相应费用。详情请参见新用户免费试用额度。
按量付费:开通DataWorks时,平台默认为您开通按量付费的MaxCompute。
如需使用免费试用的MaxCompute,请务必在“开通DataWorks”前执行“申请MaxCompute免费试用”操作。
在云原生大数据计算服务 MaxCompute卡片上,单击立即试用。
在弹出的试用云原生大数据计算服务 MaxCompute产品的面板中配置开通地域为华东2(上海),其他参数保持默认。
勾选服务协议,单击立即试用,并根据页面提示完成试用申请。
开通DataWorks
体验本文案例,您需开通DataWorks的基础版产品及资源组,以及MaxCompute产品。开通流程如下:
对于MaxCompute,您可选择如下类型产品:
免费试用:您可申请MaxCompute提供的免费试用资源。试用期结束后,如需继续使用,则会收取相应费用。详情请参见新用户免费试用额度。
按量付费:开通DataWorks后,为帮助您体验核心场景,平台默认为您开通按量付费的MaxCompute。
如需使用免费试用的MaxCompute,请务必在“开通DataWorks”前执行“申请MaxCompute免费试用”操作。
进入DataWorks服务开通页。
进入阿里云DataWorks官网,单击立即开通,即可进入DataWorks服务开通页。
按如下配置购买产品。
参数
配置
地域
华东2(上海)
DataWorks版本
基础版
资源组
名称:自定义。
网络配置:选择已创建的VPC和交换机。
说明VPC及交换机将自动绑定至创建的资源组中,后续可直接进行数据同步使用。
服务关联角色:按界面指引创建。
角色名称:
AliyunServiceRoleForDataWorks角色权限策略:
AliyunServiceRolePolicyForDataWorks
勾选服务协议,按界面指引完成支付。更多购买产品的参考,请参见开通DataWorks服务。
说明DataWorks服务开通后,平台将为您创建默认的工作空间,且新建的资源组默认归属该工作空间,您可直接使用。
DataWorks服务开通后,请前往授权页面,授予DataWorks进行云资源访问权限。
申请DataV免费试用
登录DataV数据可视化官网,单击立即购买。
在产品版本区域,单击下方的0元试用。
单击立即购买,按照界面指引开通。
创建Hologres表
初始化Hologres环境。
进入Hologres控制台-实例列表页面,单击目标实例名称,进入实例详情页面。
在实例详情页面单击登录实例,进入HoloWeb。
在元数据管理页面中单击数据库。
在新建数据库对话框中配置如下参数,并单击确认。
参数
说明
实例名
选择在哪个Hologres实例上创建数据库。默认展示当前已登录实例的名称,您也可以在下拉框中选择其他Hologres实例。
数据库名称
本示例数据库名称设置为
holo_tutorial。权限策略
选择默认的SPM。更多关于权限策略的说明,请参见:
SPM:简单权限模型,该权限模型授权是以DB为粒度,划分admin(管理员)、developer(开发者)、writer(读写者)以及viewer(分析师)四种角色,您可以通过少量的权限管理函数,即可对DB中的对象进行方便且安全的权限管理。
SLPM:基于Schema级别的简单权限模型,该权限模型以Schema为粒度,划分 <db>.admin(DB管理员)、<db>.<schema>.developer(开发者)、<db>.<schema>.writer(读写者)以及 <db>.<schema>.viewer(分析师),相比于简单权限模型更为细粒度。
专家:Hologres兼容PostgreSQL,使用与Postgres完全一致的权限系统。
立即登录
选择是。
进入顶部菜单栏的SQL编辑器页面,单击左上角的
 图标,打开临时Query查询页面。
图标,打开临时Query查询页面。
新建Hologres内部表。
在临时Query查询页面执行如下示例命令,创建Hologres内部表
hologres_dataset_github_event.hologres_github_event,后续会将数据实时写入至该表中。-- 新建schema用于创建内表并导入数据 CREATE SCHEMA IF NOT EXISTS hologres_dataset_github_event; DROP TABLE IF EXISTS hologres_dataset_github_event.hologres_github_event; BEGIN; CREATE TABLE hologres_dataset_github_event.hologres_github_event ( id bigint PRIMARY KEY, actor_id bigint, actor_login text, repo_id bigint, repo_name text, org_id bigint, org_login text, type text, created_at timestamp with time zone NOT NULL, action text, commit_id text, member_id bigint, language text ); CALL set_table_property ('hologres_dataset_github_event.hologres_github_event', 'distribution_key', 'id'); CALL set_table_property ('hologres_dataset_github_event.hologres_github_event', 'event_time_column', 'created_at'); CALL set_table_property ('hologres_dataset_github_event.hologres_github_event', 'clustering_key', 'created_at'); COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.id IS '事件ID'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.actor_id IS '事件发起人ID'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.actor_login IS '事件发起人登录名'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.repo_id IS 'repoID'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.repo_name IS 'repo名称'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.org_id IS 'repo所属组织ID'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.org_login IS 'repo所属组织名称'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.type IS '事件类型'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.created_at IS '事件发生时间'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.action IS '事件行为'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.commit_id IS '提交记录ID'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.member_id IS '成员ID'; COMMENT ON COLUMN hologres_dataset_github_event.hologres_github_event.language IS '编程语言'; COMMIT;
实时同步数据至Hologres
该数据源仅支持数据同步场景去读取使用,其他模块不支持。
创建同步任务所需的数据源。
登录DataWorks控制台,切换至华东2(上海)地域后,在左侧导航栏单击,在下拉框中选择对应工作空间后单击进入管理中心。
单击左侧导航栏的。
在数据源页面单击新增数据源。
按照界面指引创建MySQL及Hologres数据源。数据源的核心参数配置如下。
MySQL数据源:来源数据源。
参数
说明
数据源名称
自定义。本文以mysqlData为例。
配置模式
选择连接串模式。
JDBC连接地址
单击新增地址,配置信息如下:
主机地址IP:
rm-bp1z69dodhh85z9qa.mysql.rds.aliyuncs.com端口号:
3306
输入数据库名称后,完整的JDBC URL为
jdbc:mysql://rm-bp1z69dodhh85z9qa.mysql.rds.aliyuncs.com:3306/github_events_share。数据库名称
github_events_share
用户名
workshop
密码
workshop#2017
此密码仅为本教程示例,请勿在实际业务中使用。
认证选项
无认证。
Hologres数据源:去向数据源。
参数
说明
数据源名称
自定义。本文示例为
hologresData。认证方式
默认为阿里云账号及阿里云RAM角色。
所属云账号
当前阿里云主账号。
地域
华东2(上海)。
Hologres实例
选择已创建的实例。
数据库名称
填写上述已创建的Hologres数据库名称
holo_tutorial。默认访问身份
选择阿里云主账号。
认证选项
无认证。
创建实时同步任务。
进入DataWorks数据集成页面。
在创建同步任务中,选择来源与去向数据源,单击开始创建。
来源:选择MySQL。
去向:选择Hologres。
配置任务基本信息。
新任务名称:data_test。
同步类型:整库实时。
配置任务网络连通。
在网络与资源配置区域,选择数据源及资源组。
数据来源:选择mysqlData。
数据去向:选择hologresData。
资源组:选择开通DataWorks时创建的资源组,占用的CU量配置为2CU。
说明为保持公共数据源连接稳定,资源组与公共MySQL数据源创建连接后7天将进行释放,不影响资源组与您自己的MySQL创建的连接。
使用新版资源组运行数据集成整库任务,最低要求配置2CU,详情请参见Serverless资源组计费。
单击测试所有连通性,保障数据源与资源组网络连通。更多网络连通介绍,请参见网络连通方案。
测试无误后,单击下一步。
实时同步任务设置。
在选择要同步的库表区域,勾选MySQL中的github表,添加至已选库表。
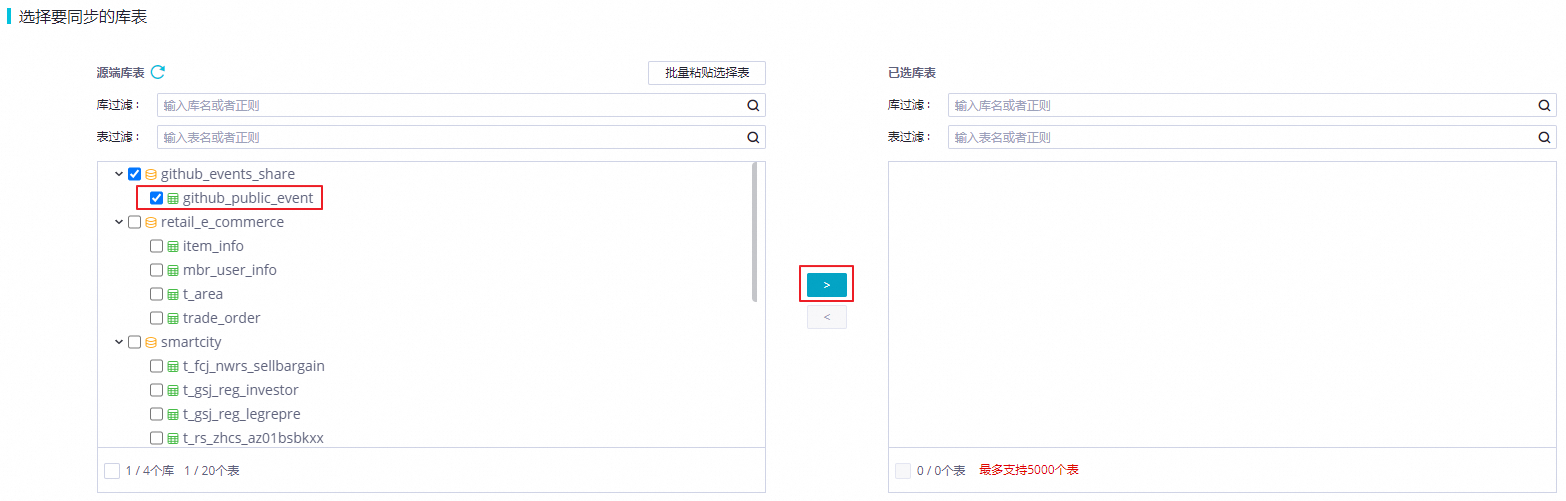
在目标表映射区域,勾选对应表,单击批量刷新映射。
基于上述已创建的Hologres内部表,将目标表名改为
hologres_github_event,目标Schema名改为hologres_dataset_github_event,单击完成配置。
在任务列表页面启动任务,查看执行详情。
公共数据源MySQL中保留近7天数据,离线数据将会通过全量进行同步,实时数据将在全量初始化完成后,实时写入Hologres。

待数据同步成功后,前往Hologres进行实时数据分析。


实时数据分析与可视化
实时数据分析。
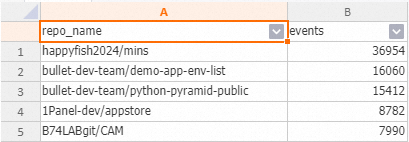
进入HoloWeb SQL编辑器,查询实时更新的过去24小时GitHub最活跃项目。
SELECT repo_name, COUNT(*) AS events FROM hologres_dataset_github_event.hologres_github_event WHERE created_at >= now() - interval '1 day' GROUP BY repo_name ORDER BY events DESC LIMIT 5;可以在元数据管理中自定义实时查询与分析Hologres近7天的数据。后续将其他维度的实时查询分析结果对接到DataV大屏,SQL样例可以查看附录。
实时数据可视化。
基于DataV自带模板,快速完成数据可视化大屏搭建。
前往DataV控制台,在左侧导航栏中选择数据准备 > 数据源。
在数据源页面,单击新建数据源。
在弹出的添加数据源面板中,根据下表参数信息新增Hologres数据源,并单击确定。
参数
说明
类型
实时数仓 Hologres
网络
内网
华东2
VPC ID
在Hologres管控台-实例列表中单击目标实例名称,在实例详情页面的网络信息区域获取VPC ID。
VPC 实例 ID
在Hologres管控台-实例列表中单击目标实例名称,在实例详情页面的网络信息区域获取VPC实例 ID。
名称
自定义命名。
域名
在Hologres管控台-实例列表中单击目标实例名称,在实例详情页面的网络信息区域获取域名。
用户名
进入AccessKey管理页面获取AccessKey ID。
密码
进入AccessKey管理页面获取AccessKey Secret。
端口
在Hologres管控台-实例列表中单击目标实例名称,在实例详情页面的网络信息区域,获取指定VPC的域名列对应的端口。例如:80。
数据库
选择上述已创建的Hologres数据库名称。
前往DataV控制台,单击未分组页面的创建 PC 端看板,选择使用Hologres实时分析GitHub事件数据模板创建看板。
在创建看板对话框输入看板名称后,单击创建看板。
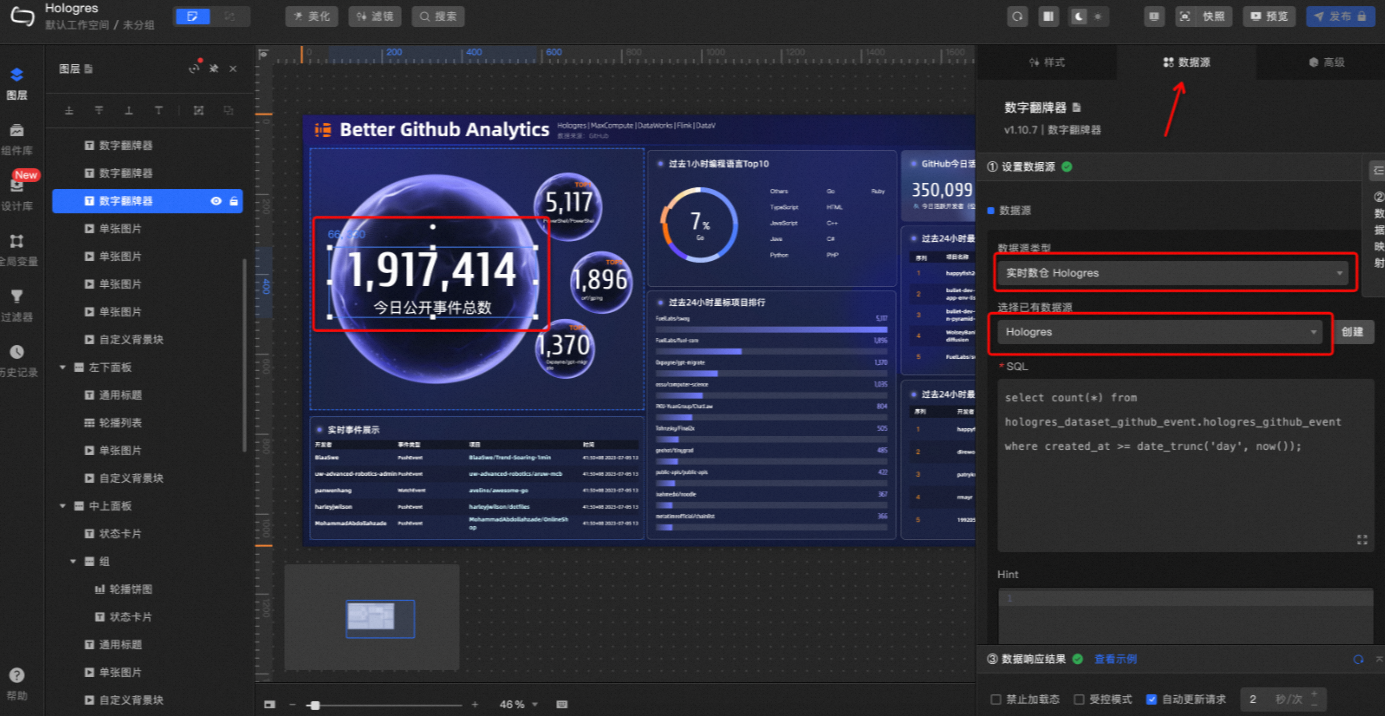
在已创建的看板页面中,单击数字,并在右侧数据源页签中,选择已添加的Hologres数据源。共计需要选择15处。
所有数字涉及的数据源都选择完成后,单击看板右上角的预览,即可获取实时更新的数据大屏预览链接(正式发布需要升级DataV高级版本)。最终效果如下:
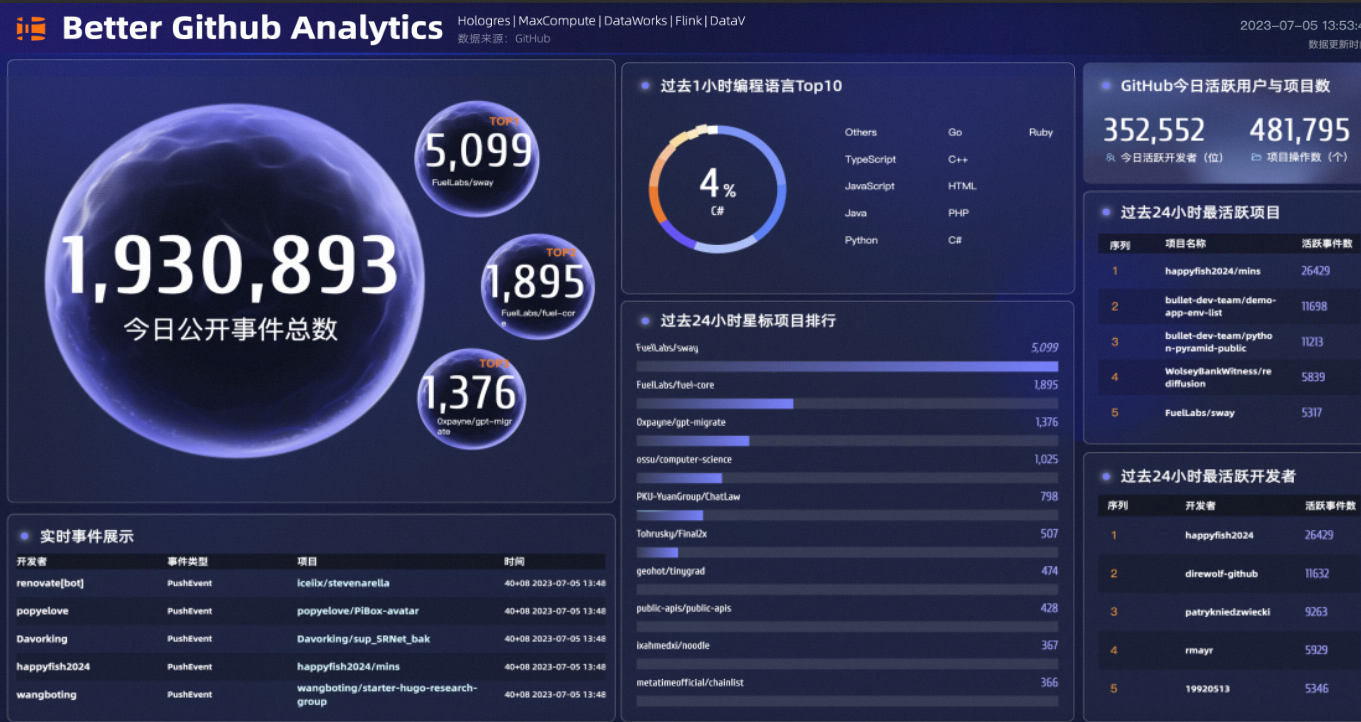
(可选)历史离线数据分析
实时数仓Hologres与大数据计算服务MaxCompute深度融合,可以组成一体化的大数据查询与分析架构。在MaxCompute公共数据集中,存储了历史GitHub全量数据。如果想要做更长时间的数据分析,有两种方式:
使用外部表查询,在不导入数据的情况下,使用Hologres直接查询MaxCompute数据。
使用内部表查询,将历史数据通过0 ETL的形式快速导入Hologres,获得更快的查询速度。
Github每日数据量约为300MB,Hologres免费试用存储额度为20GB,如果导入过多存量历史数据,将会收产生额外费用,外部表查询不受影响。
外部表查询MaxCompute数据。
创建MaxCompute外部表。
DROP FOREIGN TABLE IF EXISTS dwd_github_events_odps; IMPORT FOREIGN SCHEMA "bigdata_public_dataset#github_events" LIMIT to ( dwd_github_events_odps ) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'error',if_unsupported_type 'error');通过外部表直接查询MaxCompute数据。例如查询昨日起最活跃项目:
SELECT repo_name, COUNT(*) AS events FROM dwd_github_events_odps WHERE ds >= (CURRENT_DATE - interval '1 day')::text GROUP BY repo_name ORDER BY events DESC LIMIT 5;
0 ETL导入MaxCompute数据。
创建Hologres内部表。
DROP TABLE IF EXISTS gh_event_data; BEGIN; CREATE TABLE gh_event_data ( id bigint, actor_id bigint, actor_login text, repo_id bigint, repo_name text, org_id bigint, org_login text, type text, created_at timestamp with time zone NOT NULL, action text, iss_or_pr_id bigint, number bigint, comment_id bigint, commit_id text, member_id bigint, rev_or_push_or_rel_id bigint, ref text, ref_type text, state text, author_association text, language text, merged boolean, merged_at timestamp with time zone, additions bigint, deletions bigint, changed_files bigint, push_size bigint, push_distinct_size bigint, hr text, month text, year text, ds text ); CALL set_table_property('public.gh_event_data', 'distribution_key', 'id'); CALL set_table_property('public.gh_event_data', 'event_time_column', 'created_at'); CALL set_table_property('public.gh_event_data', 'clustering_key', 'created_at'); COMMIT;通过外部表导入数据至内部表。
INSERT INTO gh_event_data SELECT * FROM dwd_github_events_odps WHERE ds >= (CURRENT_DATE - interval '1 day')::text; -- 更新表的统计信息 ANALYZE gh_event_data;通过内部表查询昨日起最活跃项目。
SELECT repo_name, COUNT(*) AS events FROM gh_event_data WHERE ds >= (CURRENT_DATE - interval '1 day')::text GROUP BY repo_name ORDER BY events DESC LIMIT 5;
附录
实验中包含数据大屏涉及到的所有SQL如下,需要将下面的<table_name>分别换成实际的表名。
今日开发者和项目总数。
SELECT uniq (actor_id) actor_num, uniq (repo_id) repo_num FROM <table_name> WHERE created_at > date_trunc('day', now());过去24小时最活跃项目。
SELECT repo_name, COUNT(*) AS events FROM <table_name> WHERE created_at >= now() - interval '1 day' GROUP BY repo_name ORDER BY events DESC LIMIT 5;过去24小时最活跃开发者。
SELECT actor_login, COUNT(*) AS events FROM <table_name> WHERE created_at >= now() - interval '1 day' and actor_login not like '%[bot]' GROUP BY actor_login ORDER BY events DESC LIMIT 5;今日公开事件总数。
select count(*) from <table_name> where created_at >= date_trunc('day', now());过去24小时星标项目排行。
SELECT repo_id, repo_name, COUNT(actor_login) total FROM <table_name> WHERE type = 'WatchEvent' AND created_at > now() - interval '1 day' GROUP BY repo_id, repo_name ORDER BY total DESC LIMIT 10; WITH agg_language AS ( SELECT CASE LANGUAGE WHEN 'TypeScript' THEN 'TypeScript' WHEN 'JavaScript' THEN 'JavaScript' WHEN 'Python' THEN 'Python' WHEN 'Go' THEN 'Go' WHEN 'Java' THEN 'Java' WHEN 'HTML' THEN 'HTML' WHEN 'C++' THEN 'C++' WHEN 'C#' THEN 'C#' WHEN 'PHP' THEN 'PHP' WHEN 'Ruby' THEN 'Ruby' ELSE 'Others' END AS LANGUAGE, count(*) total FROM <table_name> WHERE created_at > now() - interval '1 hour' AND LANGUAGE IS NOT NULL GROUP BY LANGUAGE ORDER BY total DESC ) SELECT LANGUAGE, sum(total) AS sum FROM agg_language GROUP BY LANGUAGE ORDER BY sum DESC;实时事件展示。
SELECT cast(created_at as text), actor_login, type, repo_name FROM <table_name> ORDER BY created_at DESC LIMIT 5;
完成
完成以上操作后,您已经成功完成了Hologres数据查询操作。查询命令执行成功后,在临时Query查询页面下弹出结果页签,显示如下查询数据结果。
查询实时更新的过去24小时GitHub最活跃项目结果示例:
通过外部表直接查询MaxCompute数据(查询昨日起最活跃项目)结果示例:
通过内部表查询昨日起最活跃项目。


清理及后续
在体验完成本教程后,如果后续您不再使用的话,请及时释放相关资源。
欢迎加入实时数仓Hologres交流群(钉钉群号:32314975)交流。
删除DataV数据源
登录DataV管理控制台,在数据源页面,找到目标数据源并删除。
删除DataWorks中同步任务和数据源
登录DataWorks管理控制台-同步任务页面,找到目标任务,在操作列单击更多 > 删除,按照界面提示删除同步任务。
登录DataWorks管理控制台-数据源页面,找到目标数据源,在操作列单击
图标,按照界面提示删除数据源。
释放Hologres实例
登录Hologres管理控制台,在实例列表页面释放目标Hologres实例,详情请参见删除实例。
释放公网NAT网关
登录专有网络-公网NAT网关控制台,找到目标NAT网关,然后在操作列单击
> 删除,按照界面提示释放实例。释放弹性公网IP
登录专有网络-弹性公网IP控制台,找到目标弹性公网IP,然后在操作列单击
> 释放,按照界面提示释放实例。释放交换机
登录专有网络管理控制台,在交换机页面,找到目标交换机,然后在操作列单击删除,按照界面提示释放实例。
释放专有网络VPC
登录专有网络管理控制台,在专有网络页面,找到目标VPC,然后在操作列单击删除,按照界面提示释放实例。
 图标,按照界面提示删除数据源。
图标,按照界面提示删除数据源。