Tablestore Stream插件主要用于导出Tablestore增量数据,本文将为您介绍如何通过Tablestore Stream配置同步任务。
背景信息
Tablestore Stream插件与全量导出插件不同,增量导出插件仅支持多版本模式,且不支持指定列。增量数据可以看作操作日志,除数据本身外还附有操作信息。详情请参见Tablestore Stream数据源。
Tablestore Stream配置同步任务时,请注意以下问题:
如果配置任务为日调度,您可以读取当前时间24小时以内的数据,但会丢失当前时间前5分钟的数据。建议您配置任务为小时调度。
设置的结束时间不能超过系统显示的时间,即您设置的结束时间要比运行时间早5分钟。
配置日调度会出现数据丢失的情况。
不可以配置周期调度和月调度。
开始时间和结束时间需要包含操作Table Store表的时间。例如,20171019162000您向Table Store插入2条数据,则开始时间设置为20171019161000,结束时间设置为20171019162600。
新增数据源
进入数据集成页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据集成。
单击左侧导航栏中的数据源,进入数据源列表。
单击新增数据源。
在新增数据源对话框中,选择数据源类型为Tablestore 。
填写Tablestore数据源的各配置项。
参数
描述
数据源名称
数据源名称必须以字母、数字、下划线组合,且不能以数字和下划线开头。
数据源描述
对数据源进行简单描述,不得超过80个字符。
Endpoint
Table Store服务对应的Endpoint。
Table Store实例名称
Table Store服务对应的实例名称。
AccessKey ID
访问密钥中的AccessKey ID,您可以进入用户信息管理页面进行复制。
AccessKey Secret
访问密钥中的AccessKey Secret,相当于登录密码。
单击测试连通性。
测试连通性通过后,单击完成。
通过向导模式配置同步任务
进入数据开发页面。
登录DataWorks控制台,切换至目标地域后,单击左侧导航栏的,在下拉框中选择对应工作空间后单击进入数据开发。
在目标业务流程中,右键单击数据集成,选择。
在新建节点对话框中,输入名称并选择路径,单击确认。
选择离线同步任务的数据来源Table Stream和数据去向MaxCompute(ODPS),以及用于执行同步任务的资源组,并测试连通性。
配置数据来源与去向。
类别
参数
描述
数据来源
表
导出增量数据的表的名称。该表需要开启Stream,您可以在建表时开启。
开始时间
增量数据的时间范围(左闭右开)的左边界,格式为yyyymmddhh24miss,单位为毫秒。
结束时间
增量数据的时间范围(左闭右开)的右边界,格式为yyyymmddhh24miss,单位为毫秒。
状态表
用于记录状态的表的名称。
最大重试次数
从TableStore中读增量数据时,每次请求的最大重试次数,默认是30。
导出时序信息
是否导出时序信息,包括数据的写入时间等信息。
数据去向
表
选择需要写入的表。
分区信息
此处需同步的表是非分区表,所以无分区信息。
清理规则
写入前清理已有数据:导数据之前,清空表或者分区的所有数据,相当于
insert overwrite。写入前保留已有数据:导数据之前,不清理任何数据,每次运行数据都是追加进去的,相当于
insert into。
空字符串作为null
默认值为否。
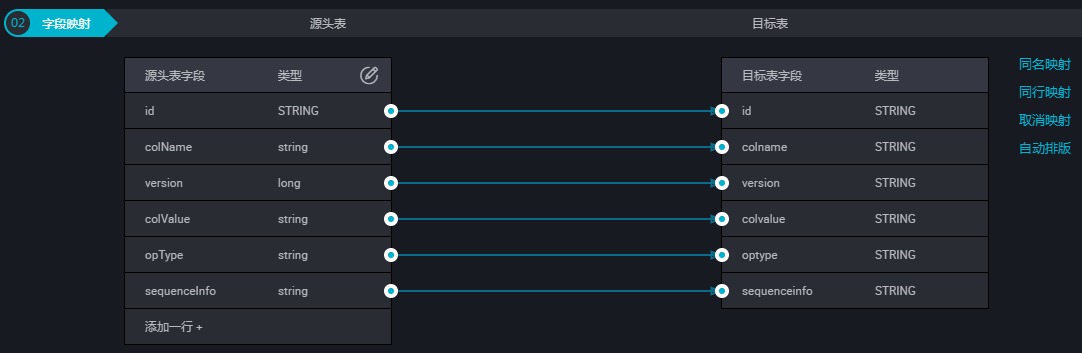
配置字段映射关系。
左侧的源头表字段和右侧的目标表字段为一一对应的关系。单击添加一行可以增加单个字段,鼠标放至需要删除的字段上,即可单击删除图标进行删除。
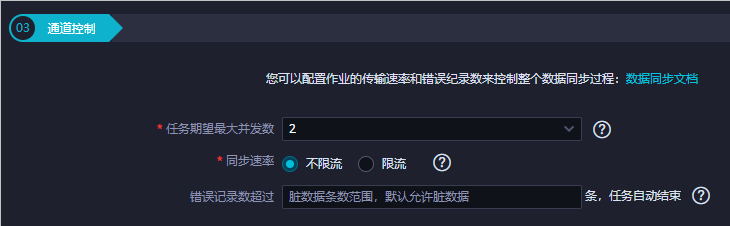
配置通道。
单击工具栏中的保存图标。
单击工具栏中的运行图标,运行之前需要配置自定义参数。
通过脚本模式配置同步任务
如果您需要通过脚本模式配置此任务,单击工具栏中的转换脚本,选择确认即可进入脚本模式。
您可以根据自身进行配置,示例脚本如下。
{
"type": "job",
"version": "1.0",
"configuration": {
"reader": {
"plugin": "Tablestore",
"parameter": {
"datasource": "Tablestore",//数据源名,需要与您添加的数据源名称保持一致。
"dataTable": "person",//导出增量数据的表的名称。该表需要开启Stream,可以在建表时开启。
"startTimeString": "${startTime}",//增量数据的时间范围(左闭右开)的左边界,格式为yyyymmddhh24miss,单位毫秒。
"endTimeString": "${endTime}",//运行时间。
"statusTable": "TableStoreStreamReaderStatusTable",//用于记录状态的表的名称。
"maxRetries": 30,//请求的最大重试次数。
"isExportSequenceInfo": false,
}
},
"writer": {
"plugin": "odps",
"parameter": {
"datasource": "odps_source",//数据源名。
"table": "person",//目标表名。
"truncate": true,
"partition": "pt=${bdp.system.bizdate}",//分区信息。
"column": [//目标列名。
"id",
"colname",
"version",
"colvalue",
"optype",
"sequenceinfo"
]
}
},
"setting": {
"speed": {
"mbps": 7,//作业速率上限,此处1mbps = 1MB/s。
"concurrent": 7//并发数。
}
}
}
}关于运行时间参数和结束时间参数,有以下两种表现形式(配置任务时选择其中一种):
"startTimeString": "${startTime}":增量数据的时间范围(左闭右开)的左边界,格式为yyyymmddhh24miss,单位为毫秒。"endTimeString": "${endTime}":增量数据的时间范围(左闭右开)的右边界,格式为yyyymmddhh24miss,单位为毫秒。"startTimestampMillis":"":增量数据的时间范围(左闭右开)的左边界,单位为毫秒。Reader插件会从statusTable中找对应startTimestampMillis的位点,从该点开始读取开始导出数据。
如果statusTable中找不到对应的位点,则从系统保留的增量数据的第1条开始读取,并跳过写入时间小于startTimestampMillis的数据。
"endTimestampMillis":" ":增量数据的时间范围(左闭右开)的右边界,单位为毫秒。Reader插件startTimestampMillis位置开始导出数据后,当遇到第1条时间戳大于等于endTimestampMillis的数据时,结束导出数据,导出完成。
当读取完当前全部的增量数据时,结束读取,即使未达endTimestampMillis。
如果配置isExportSequenceInfo项为true,如“isExportSequenceInfo”: true,则会导出时序信息,目标会多出1行,目标字段列则多1列。时序信息包含了数据的写入时间等,默认该值为false,即不导出。