
DataWorks Notebook 提供一个交互式、模块化的数据分析与开发环境。您可以使用 Python、SQL 和 Markdown 单元格,连接 MaxCompute、EMR、AnalyticDB 等多种计算引擎,实现从数据处理、探索性分析、可视化到模型开发的全链路任务。本文档将指导您如何高效使用 Notebook 完成数据开发与调度任务。
快速入门:5分钟运行您的第一个Notebook
本节将引导您完成一个最简流程:创建一个 Notebook,使用 Python 传递参数给 SQL,并查询 MaxCompute 表数据。
开始前,请确保您已满足以下条件:
当前工作空间已开通并使用新版数据开发(Data Studio)。
已创建Serverless 资源组。Notebook在生产环境运行需要依赖Serverless资源组。
已创建个人开发环境实例。如果您使用包含Python单元格的Notebook,在开发环境调试运行时需要依赖个人开发环境实例。
如果您尚未创建,请参见创建个人开发环境实例。
操作步骤:
创建 Notebook 节点
进入 Data Studio,在数据开发的项目目录下,新建 Notebook 节点。
为 Notebook 命名(例如
hello_notebook)并提交。
选择个人开发环境
在顶部导航处单击个人开发环境,从下拉列表中选择您已创建的个人开发环境实例。
编写 Python 单元格以定义参数
添加一个Python单元格,并输入以下代码。此步骤定义一个城市变量,用于后续的 SQL 查询。
# 定义一个变量,用于后续SQL查询 city = 'Beijing' print(f"已定义城市变量 city = {city}")编写 SQL 单元格以查询数据
在第一个单元格下方,新增一个 SQL 单元格。
在单元格右下角,将 SQL 类型切换为
MaxCompute SQL。输入以下 SQL 代码。代码通过
${city}语法引用了上一步 Python 单元格中定义的city变量。-- 使用Python中定义的变量进行查询 SELECT '${city}' AS city;
运行并查看结果
单击 Notebook 上方工具栏的全部运行按钮。
观察每个单元格的运行情况:
Python 单元格下方会输出
已定义城市变量 city = Beijing。SQL 单元格下方会显示查询结果的表格。
至此,您已成功创建并运行一个包含 Python 和 SQL 交互的 Notebook。
核心概念
理解以下核心概念,是确保 Notebook 在开发和生产环境中行为一致的关键。
Notebook 模式
DataWorks Notebook 支持两种使用模式:
纯SQL和Markdown模式:仅包含 SQL 和 Markdown 单元格,适用于纯数据查询和文档编写场景。此模式下,无论是开发环境还是生产环境,都仅需 Serverless 资源组即可运行,不依赖个人开发环境实例。默认情况下为此模式,Notebook右上角显示为SQL内核。
完整模式(Python + SQL + Markdown):支持 Python、SQL 和 Markdown 单元格的混合使用,适用于需要数据处理、分析和可视化的复杂场景。在开发环境调试运行时,需要依赖个人开发环境实例来执行 Python 代码。请您选择个人开发环境后,Notebook右上角将显示为
 (Python版本仅供参考)。
(Python版本仅供参考)。
开发环境 vs. 生产环境
对比项 | 开发环境 | 生产环境 |
运行载体 | 个人开发环境实例 | 调度配置中指定的资源组和镜像 |
核心差异 | 对于包含 Python 单元格的 Notebook,使用个人独占的开发实例,您可以在其中自由安装 Python 库进行调试。 对于仅包含 SQL 和 Markdown 单元格的 Notebook,仅需 Serverless 资源组即可运行。 | 无论是通过运维中心周期性调度,还是在 Data Studio 中手动触发工作流运行,任务都会在调度配置中指定的资源组上运行。其环境(如依赖库、网络等)完全由您选择的镜像和资源组配置决定。 |
如何保障一致 | 如果您在个人开发环境实例中通过 pip install 等方式进行了Python包的安装,为确保生产环境具备与开发环境相同的依赖,您需将个人开发环境制作DataWorks镜像,并在调度配置中选用该自定义镜像。 重要 网络连通情况说明:个人开发环境不绑定VPC时,默认绑定一个带宽有限的随机公网IP,可直接连通公网;但发布至生产环境的Notebook节点网络是跟随调度配置里配置的资源组。建议在个人开发环境中绑定调度配置的资源组,此时两者环境保持网络一致。 | |
计算资源与内核
在 DataWorks Notebook 中,代码的执行由计算资源和内核两个核心概念共同决定。
计算资源:计算资源是负责最终执行和处理数据任务的后端计算引擎。它定义了任务运行的环境、计算能力和所遵循的执行逻辑。
定义:一个独立的、可被调度的计算服务实例。例如:MaxCompute 项目、EMR Serverless Spark 集群等。
作用:为 SQL 查询、Spark 作业等提供实际的算力。
选择:您需要在执行任务时,明确将其绑定到一个具体的计算资源上。
内核:内核是 Notebook 环境中负责解析并执行用户在代码单元格内所编写代码的组件。它决定了该单元格接受的编程语言。
Python 内核:
功能:执行 Python 语言编写的代码,支持数据处理、算法实现、任务调度等复杂逻辑。
交互模式:在 Python 内核中,可以通过
Magic Command(如%sql) 或 SDK 库,将封装好的计算任务(如一段 SQL 语句)提交给指定的计算资源执行,并能获取其返回结果用于进一步分析。
SQL 内核:
功能:直接解释和提交 SQL 语言编写的查询。
交互模式:使用 SQL 内核时,它将 SQL 语句直接转发给用户为该单元格指定的后端计算资源(例如 EMR Spark SQL 或 MaxCompute SQL Session)来执行。
Markdown 内核:
功能:用于渲染 Markdown 格式的富文本文档,不执行任何计算逻辑。
关系总结:
内核是前端的语言解释器,决定“写什么”(Python 或 SQL)。
计算资源是后端的执行引擎,决定代码“在哪里运行”(在 MaxCompute 还是 Spark 上)。
目录类型与适用场景
您创建 Notebook 的位置决定其协作模式、权限和发布流程。
目录类型 | 适用场景 | 协作与发布 |
项目目录 | 团队协作与周期性生产任务。此目录下的节点是工作空间共享的,遵循标准的开发、提交、发布流程。 | 允许多人协作开发。节点需要发布到生产环境,才能被周期性调度。 |
个人目录 | 个人开发与调试。此目录对其他工作空间成员不可见,用于存放个人脚本和临时任务。 | 仅自己可见。若要被调度,需先提交到项目目录,再进行发布。 |
开发与调试 Notebook
Data Studio默认不自动保存,建议您开发过程及时手动保存,避免丢失代码。您也可在Data Studio的编辑器设置 > Files: Auto Save中,设置为自动保存。
若运行过程中卡顿或长时间无反应,可点击上方工具栏的重启按钮重启Notebook内核。
单元格管理
添加单元格:将鼠标悬停在现有单元格的上方或下方边缘,单击出现的+ SQL等按钮。也可以使用顶部工具栏的按钮。
切换单元格类型:单击单元格右下角的类型标识(如
Python),在弹出的菜单中选择新的类型,如SQL、Markdown。切换类型时,单元格内的代码内容会保留,您需要手动修改以适应新类型。移动单元格:将鼠标悬停在单元格左侧的蓝色竖线上,按住并拖动即可调整顺序。
运行单元格:
运行单个:单击单元格左侧的运行按钮。
运行全部:单击 Notebook 顶部工具栏的全部运行按钮。
参数传递
Python 变量传递至 SQL
在 Python 单元格中定义的变量,可以在后续的 SQL 单元格中通过 ${变量名} 的格式直接引用。
示例:
Python 单元格
table_name = "dwd_user_info_d" limit_num = 10SQL 单元格
SELECT * FROM ${table_name} LIMIT ${limit_num};
SQL 结果传递至 Python
当一个 SQL 单元格执行SELECT 查询后,其结果会自动生成一个 DataFrame 变量,可供后续的 Python 单元格使用。
若存在多个SQL语句,仅会将最后一条SQL语句的结果存入DataFrame变量。
变量命名:默认变量名为
df_开头,您可以单击 SQL 单元格左下角的变量名进行重命名。变量类型:
若支持多种变量类型,点击左下角DataFrame也切换类型。
对于 MaxCompute SQL,支持
Pandas DataFrame和MaxCompute MaxFrame对象。对于ADB Spark SQL,支持
Pandas DataFrame和PySpark MaxFrame对象。对于其他 SQL 类型,生成的是
Pandas DataFrame对象。
示例:

查看血缘(Beta)
支持地域:华东1(杭州)、华东2(上海)、华北2(北京)、华北3(张家口)、华北6(乌兰察布)、华南1(深圳)、西南1(成都)、中国香港。
当 Notebook 代码变得复杂,涉及多个数据表或文件的读写时,理解数据流向会变得困难。血缘分析功能通过静态解析Notebook 中的 Python(支持MaxFrame框架),快速理清数据的来龙去脉。
操作步骤
在 Notebook 的顶部工具栏,单击血缘按钮。系统会自动解析当前 Notebook 中所有单元格的代码,并在下方展示数据血缘关系图。
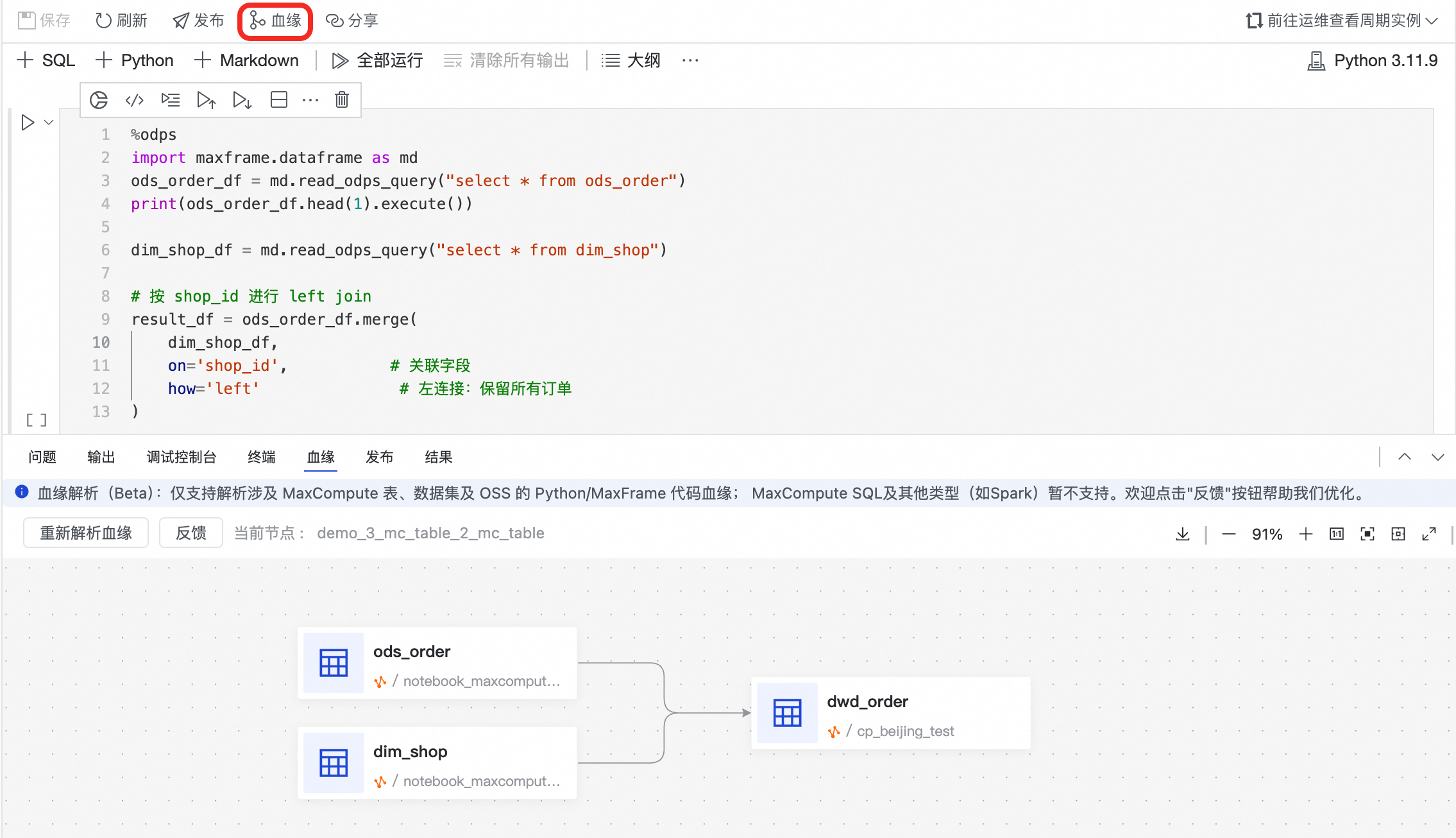
血缘分析是基于对 Notebook 代码的静态解析,它反映的是代码中描述的数据逻辑,而非任务运行后的实际数据流。因此,无需运行代码即可查看血缘。
当前该功能主要用于开发和调试,分析出的血缘关系暂时不会自动上报至数据地图中。
如果修改代码,需要再次单击血缘或刷新按钮来获取最新的血缘关系图。
支持的场景
血缘分析功能当前仅支持以下场景:
MaxCompute 表间的血缘:当您从一张或多张 MaxCompute 表读取数据,经过 MaxFrame 处理后,再写入到另一张 MaxCompute 表时,系统能清晰地展示出表与表之间的加工关系。
例如,将订单表(ods_order)和店铺维表(dim_shop)进行关联,并将结果写入到订单宽表(dwd_order)。
MaxCompute 表与外部数据的血缘: 当您在代码中处理 MaxCompute 表与外部数据(如绑定的数据集、OSS文件)的交互时,血缘分析能够清晰地展示它们之间的链路关系。
通过绑定的数据集:当您在代码中通过个人开发环境的挂载路径(如
/mnt/data/)访问绑定的数据集,并与 MaxCompute 表进行数据交换时(例如,从数据集读取数据写入表,或从表读取数据写入数据集),血缘图中会展示两者之间的完整数据链路。
通过 OSS 路径:即使您没有绑定数据集,直接在代码中通过 OSS 路径读取或写入文件进行处理,血缘分析也能识别出 OSS 存储路径与 MaxCompute 表之间的双向数据流向。
 说明
说明如果该 OSS 路径恰好在数据地图中被注册为数据集,血缘图会自动将其展示为数据集节点,帮助您更好地进行资产管理。
Copilot 辅助编程
DataWorks Copilot 是内置的智能编程助手,可以帮助您生成和解释代码。
唤起方式:
在选择的单元格左上方单击 Copilot
 图标。
图标。在SQL单元格内右键,选择 Copilot。
使用快捷键
Cmd+I(Mac) 或Ctrl+I(Windows)。
调度与发布 Notebook
为了让 Notebook 能够按计划周期性运行,您需要进行调度配置并将其发布到生产环境。
1、配置调度参数(参数化调度)
如需每次调度运行时,Notebook 中的参数能动态变化(例如,按天处理不同分区的数据),可以设置参数化调度。
标记参数单元格: 在包含核心参数定义的 Python 单元格中,单击右上角的
...菜单,选择 Mark Cell as Parameters。该单元格会被添加一个parameters标签,表明它是调度任务的参数入口。配置调度参数:
在 Notebook 右侧面板,单击调度配置。
在调度参数区域,为您在代码中定义的变量(如
var)赋值。


当任务被调度系统自动执行时,代码中 var 参数的实际值,将由在调度参数中配置的值动态替换。
2、配置运行环境与资源
配置镜像:在调度配置中,选择一个包含 Notebook 运行所需全部依赖的镜像。这是确保生产环境成功运行的关键。
重要如果您在个人开发环境实例中通过 pip install 等方式进行了Python包的安装,为确保生产环境具备与开发环境相同的依赖,您需将个人开发环境制作DataWorks镜像,并在调度配置中选用该自定义镜像。
配置资源组:选择用于执行任务的资源组。对于 Serverless 资源组,建议配置不超过
16CU,以避免因资源不足导致任务启动失败。单个任务最大支持64CU。配置关联角色:如需进行细粒度的权限管控,可以为节点关联一个特定的 RAM角色,使其以该角色的身份运行。详情请参见配置节点关联角色。
3、发布节点
只有项目目录下的节点才能被发布和周期性调度。
对于项目目录下的 Notebook:完成配置后,单击顶部工具栏的发布按钮。
对于个人目录下的 Notebook:需先单击保存按钮,将其提交到项目目录,然后再执行发布操作。
发布成功后,您可以在运维中心的周期任务页面监控和管理您的 Notebook 任务。
常见问题
Q:为什么我的代码在开发时能访问公网,但调度运行时却失败了?
A:这是因为开发环境和生产环境的网络策略不同。
开发环境 (个人开发环境):为了方便调试,个人开发环境实例在未设置VPC的情况下,默认会提供有限的公网访问能力,让您可以临时安装包或调用API。
生产环境 (周期调度任务): 出于安全和稳定考虑,默认在专有网络中运行,不能直接访问公网。任务的网络配置由您在调度配置中选择的资源组决定。如果该资源组所在VPC没有配置NAT网关,则无法访问公网。
解决方案: 确保个人开发环境实例和Serverless资源组设置相同的VPC专有网络。
Q:为什么我的代码在开发环境时成功运行,但调度运行时却找不到三方包?
A:请确保已将所有依赖包(如Python库)提前制作成自定义镜像,并在调度配置中指定该镜像。详情请参见个人开发环境制作DataWorks镜像。
Q:我如何更换Python内核版本?
A:可在个人开发环境的终端
手动安装需要Python版本,然后在Notebook工具栏右侧单击按钮,切换其他Python内核版本。不推荐使用额外安装Python内核,因为新建版本不具备SQL单元格需要的依赖,无法正常使用。