StarRocks数据源为您提供读取和写入StarRocks的双向通道,本文为您介绍DataWorks对StarRocks数据同步的能力支持情况。
支持版本
支持EMR Serverless StarRocks各种版本。
支持EMR on ECS:StarRocks 2.1版本。
支持社区版StarRocks。
说明由于DataWorks仅支持内网连接StarRocks,社区版StarRocks需部署在EMR on ECS上。
社区版StarRocks的开放性较强,若在数据源使用过程中出现适配性问题,可提交工单进行反馈。
支持字段类型
仅支持数值类型、字符串类型和日期类型的字段。
数据同步前准备(网络连通)
EMR Serverless StarRocks
为保证资源组网络连通性,您需要提前将后续要使用的DataWorks资源组的IP地址添加至EMR Serverless StarRocks实例的内网白名单中。
DataWorks资源组的白名单IP地址请参见:通用配置:添加白名单。
添加EMR Serverless StarRocks实例白名单的操作入口如下。
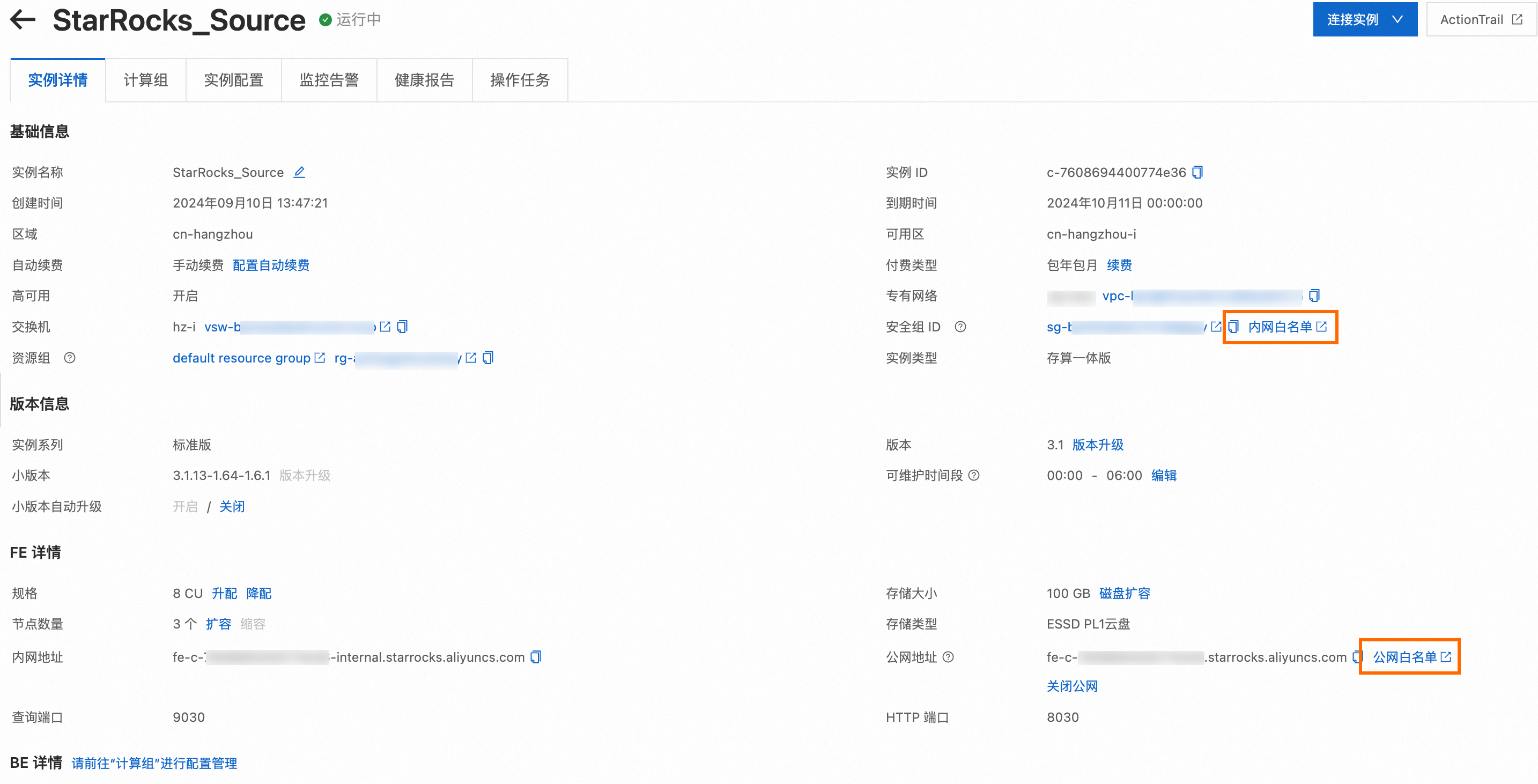
自建StarRocks
确保DataWorks的资源组可以访问StartRocks的查询端口、FE端口和BE端口,通常为9030、8030、8040。
创建数据源
在进行数据同步任务开发时,您需要在DataWorks上创建一个对应的数据源,操作流程请参见数据源管理,详细的配置参数解释可在配置界面查看对应参数的文案提示。
请根据您的网络环境选择StarRocks连接模式:
场景一:内网连接(推荐)
内网链路延迟低、数据传输更安全,无需额外配置公网权限。
适用场景:您的StarRocks实例与Serverless资源组处于同一VPC内。
支持使用阿里云实例模式和连接串模式:
选择阿里云实例模式:直接选择同VPC下的StarRocks实例,系统自动获取连接信息,无需手动配置。
选择连接串模式:手动输入实例的内网地址/IP、端口、Load URL。
场景二:公网连接
公网传输存在安全风险,建议搭配白名单、IP鉴权等安全策略。
适用场景:需要通过公网访问StarRocks实例(如跨地域、本地环境访问)。
支持使用连接串模式(请确保StarRocks实例已开启公网访问权限):
选择连接串模式:手动填写实例的公网地址/IP、端口、Load URL。
Serverless资源组默认不具备公网访问能力,使用公网地址连接StarRocks实例时,需要为绑定的VPC配置公网NAT网关和EIP后,才支持公网访问数据源。且需保证Serverless资源组可以访问StarRocks的查询端口、FE端口和BE端口,通常为9030、8030、8040。
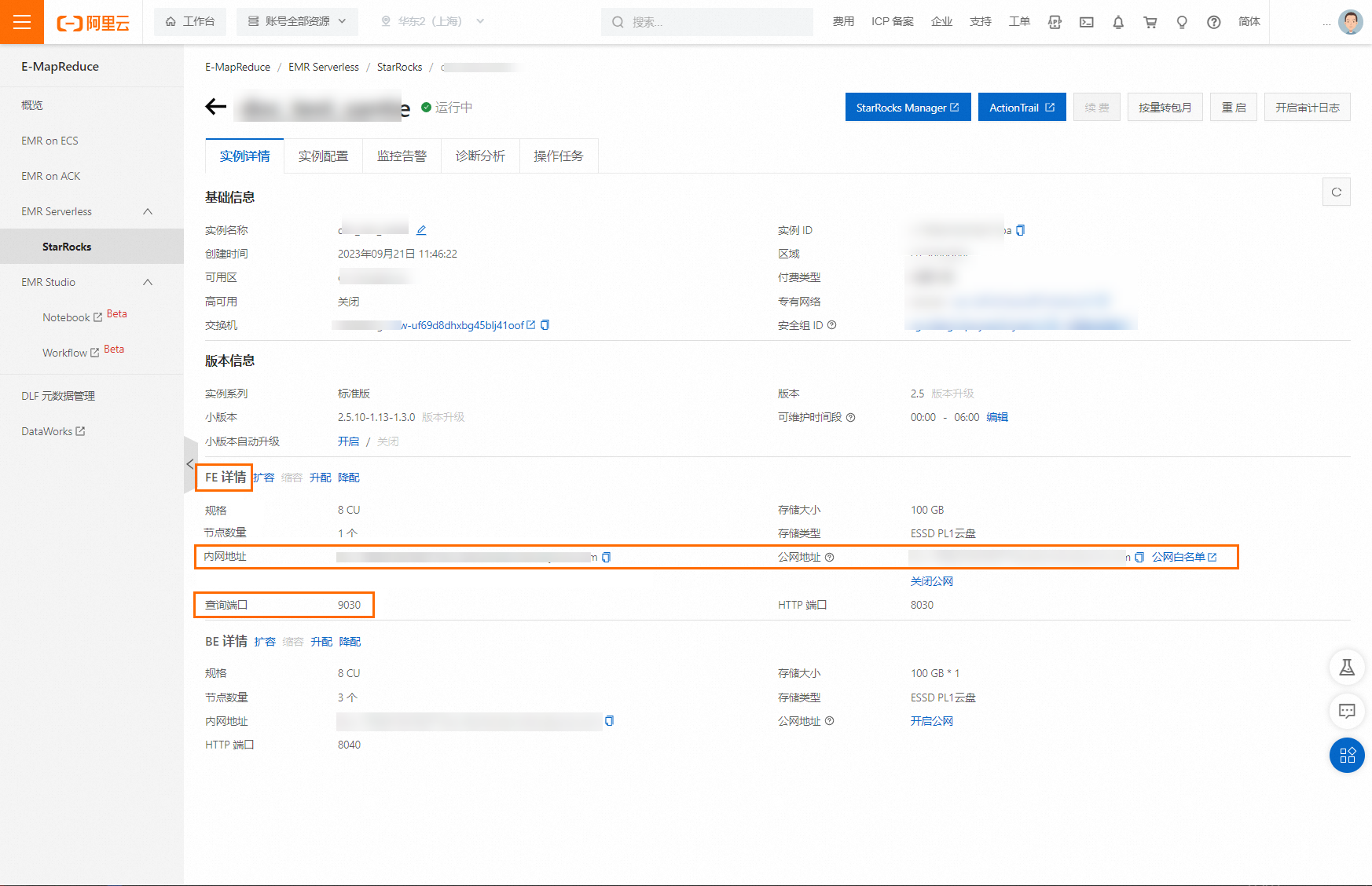
如果您使用的是阿里云EMR StarRocks Serverless,主机地址/IP使用内网地址或公网地址,端口使用查询端口。
FE:您可以在实例详情页获取。
数据库:使用EMR StarRocks Manager连接实例后,可以在SQL Editor或者元数据管理查看到对应的数据库。
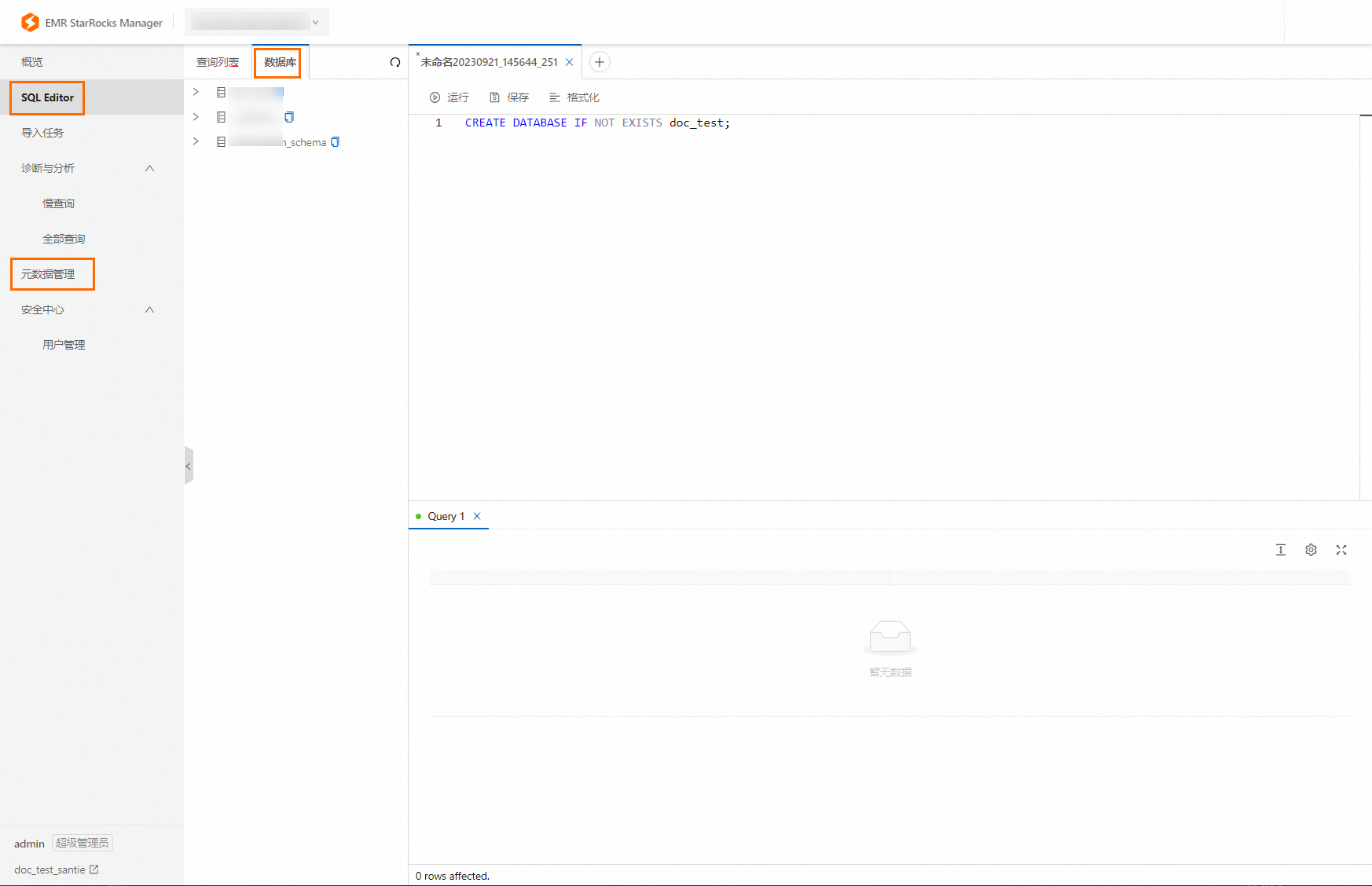 说明
说明如果需要创建数据库,可以直接在SQL Editor里执行SQL命令进行创建。
数据同步任务开发
数据同步任务的配置入口和通用配置流程可参见下文的配置指导。
单表离线同步任务配置指导
脚本模式配置的全量参数和脚本Demo请参见下文的附录:脚本Demo与参数说明。
附录:脚本Demo与参数说明
离线任务脚本配置方式
如果您配置离线任务时使用脚本模式的方式进行配置,您需要按照统一的脚本格式要求,在任务脚本中编写相应的参数,详情请参见脚本模式配置,以下为您介绍脚本模式下数据源的参数配置详情。
Reader脚本Demo
{
"stepType": "starrocks",
"parameter": {
"selectedDatabase": "didb1",
"datasource": "starrocks_datasource",
"column": [
"id",
"name"
],
"where": "id>100",
"table": "table1",
"splitPk": "id"
},
"name": "Reader",
"category": "reader"
}Reader脚本参数
参数 | 描述 | 是否必选 | 默认值 |
datasource | StarRocks数据源名称。 | 是 | 无 |
selectedDatabase | StarRocks数据库名称。 | 否 | StarRocks数据源内配置的数据库名称。 |
column | 所配置的表中需要同步的列名集合。 | 是 | 无 |
where | 筛选条件,在实际业务场景中,往往会选择当天的数据进行同步,将where条件指定为
| 否 | 无 |
table | 选取的需要同步的表名称。 | 是 | 无 |
splitPk | StarRocks Reader进行数据抽取时,如果指定splitPk,表示您希望使用splitPk代表的字段进行数据分片,数据同步因此会启动并发任务进行数据同步,提高数据同步的效能。推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。 | 否 | 无 |
Writer脚本Demo
{
"stepType": "starrocks",
"parameter": {
"selectedDatabase": "didb1",
"loadProps": {
"row_delimiter": "\\x02",
"column_separator": "\\x01"
},
"datasource": "starrocks_public",
"column": [
"id",
"name"
],
"loadUrl": [
"1.1.X.X:8030"
],
"table": "table1",
"preSql": [
"truncate table table1"
],
"postSql": [
],
"maxBatchRows": 500000,
"maxBatchSize": 5242880,
"strategyOnError": "exit"
},
"name": "Writer",
"category": "writer"
}Writer脚本参数
参数 | 描述 | 是否必选 | 默认值 |
datasource | StarRocks数据源名称。 | 是 | 无 |
selectedDatabase | StarRocks数据库名称。 | 否 | StarRocks数据源内配置的数据库名称。 |
loadProps | StarRocks StreamLoad请求参数。使用StreamLoad CSV导入,此处可选择配置导入参数。如果无特殊配置则使用{}。可配置参数包括:
如果您的数据中本身包含\t、\n,则需自定义使用其他字符作为分隔符,使用特殊字符示例如下: StreamLoad同时也支持JSON格式导入,您可以配置: JSON格式下可配置的参数:
| 是 | 无 |
column | 所配置的表中需要同步的列名集合。 | 是 | 无 |
loadUrl | 填写StarRocks FrontEnd IP、Http Port(一般默认是 | 是 | 无 |
table | 选取的需要同步的表名称。 | 是 | 无 |
preSql | 执行数据同步任务之前率先执行的SQL语句。例如,执行前清空表中的旧数据(truncate table tablename)。 | 否 | 无 |
postSql | 执行数据同步任务之后执行的SQL语句。 | 否 | 无 |
maxBatchRows | 最大每次写入行数。 | 否 | 500000 |
maxBatchSize | 最大每次写入字节数。 | 否 | 5242880 |
strategyOnError | 批量写入StarRocks异常时的处理策略。 取值范围:
默认值: | 否 | exit |