企业构建和应用数据湖一般需要经历数据入湖、数据湖存储与管理、数据湖探索与分析等几个过程。本文主要介绍基于阿里云数据湖构建(DLF)构建一站式的数据入湖与分析实战。
背景信息
随着数据时代的不断发展,数据量爆发式增长,数据形式也变的更加多样。传统数据仓库模式的成本高、响应慢、格式少等问题日益凸显。于是拥有成本更低、数据形式更丰富、分析计算更灵活的数据湖应运而生。
数据湖作为一个集中化的数据存储仓库,支持的数据类型具有多样性,包括结构化、半结构化以及非结构化的数据,数据来源上包含数据库数据、binglog 增量数据、日志数据以及已有数仓上的存量数据等。数据湖能够将这些不同来源、不同格式的数据集中存储管理在高性价比的存储如 OSS等对象存储中,并对外提供统一的数据目录,支持多种计算分析方式,有效解决了企业中面临的数据孤岛问题,同时大大降低了企业存储和使用数据的成本。
企业级数据湖架构
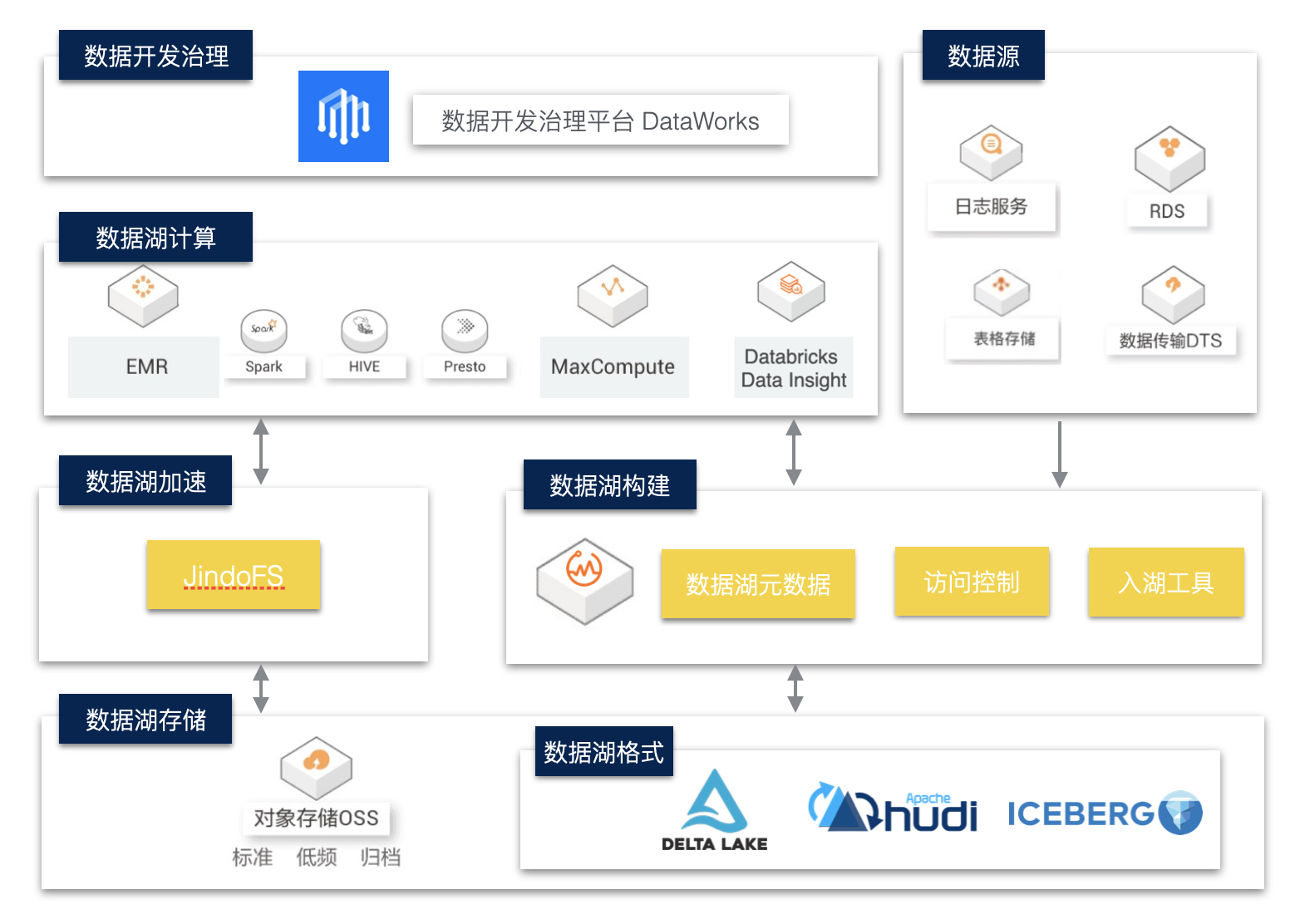
数据湖存储与格式
数据湖存储主要以云上对象存储作为主要介质,其具有低成本、高稳定性、高可扩展性等优点。
数据湖上我们可以采用支持ACID的数据湖存储格式,如Delta Lake、Hudi、Iceberg。这些数据湖格式有自己的数据meta管理能力,能够支持Update、Delete等操作,以批流一体的方式解决了大数据场景下数据实时更新的问题。
数据湖构建与管理
1. 数据入湖
企业的原始数据存在于多种数据库或存储系统,如关系数据库MySQL、日志系统SLS、NoSQL存储HBase、消息数据库Kafka等。其中大部分的在线存储都面向在线事务型业务,并不适合在线分析的场景,所以需要将数据以无侵入的方式同步至成本更低且更适合计算分析的对象存储。
常用的数据同步方式有基于DataX、Sqoop等数据同步工具做批量同步;同时在对于实时性要求较高的场景下,配合使用Kafka+spark Streaming / flink等流式同步链路。目前很多云厂商提供了一站式入湖的解决方案,帮助客户以更快捷更低成本的方式实现数据入湖,如阿里云DLF数据入湖。
2. 统一元数据服务
对象存储本身是没有面向大数据分析的语义的,需要结合Hive Metastore Service等元数据服务为上层各种分析引擎提供数据的Meta信息。
数据湖计算与分析
相比于数据仓库,数据湖以更开放的方式对接多种不同的计算引擎,如传统开源大数据计算引擎Hive、Spark、Presto、Flink等,同时也支持云厂商自研的大数据引擎,如阿里云MaxCompute、Hologres等。在数据湖存储与计算引擎之间,一般还会提供数据湖加速的服务,以提高计算分析的性能,同时减少带宽的成本和压力。
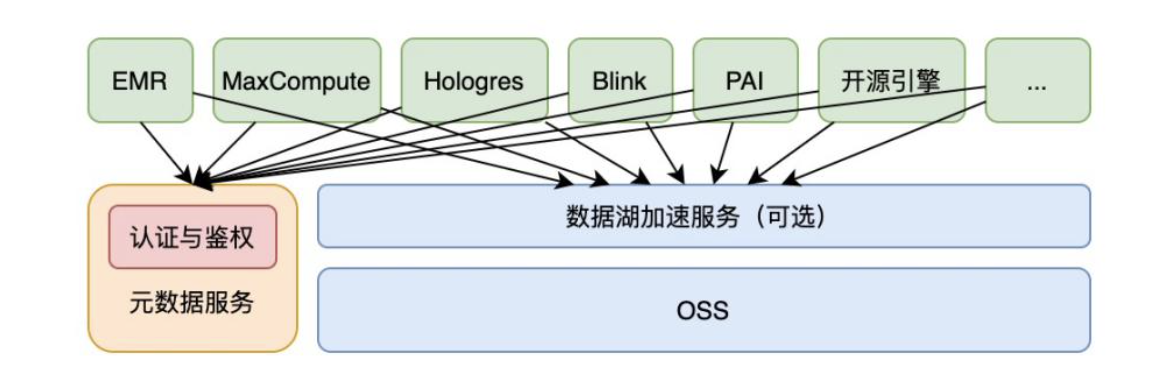
操作流程
数据湖构建与分析链路
企业构建和应用数据湖一般需要经历数据入湖、数据湖存储与管理、数据湖探索与分析等几个过程。本文主要介绍基于阿里云数据湖构建(DLF)构建一站式的数据入湖与分析实战。
其主要数据链路如下: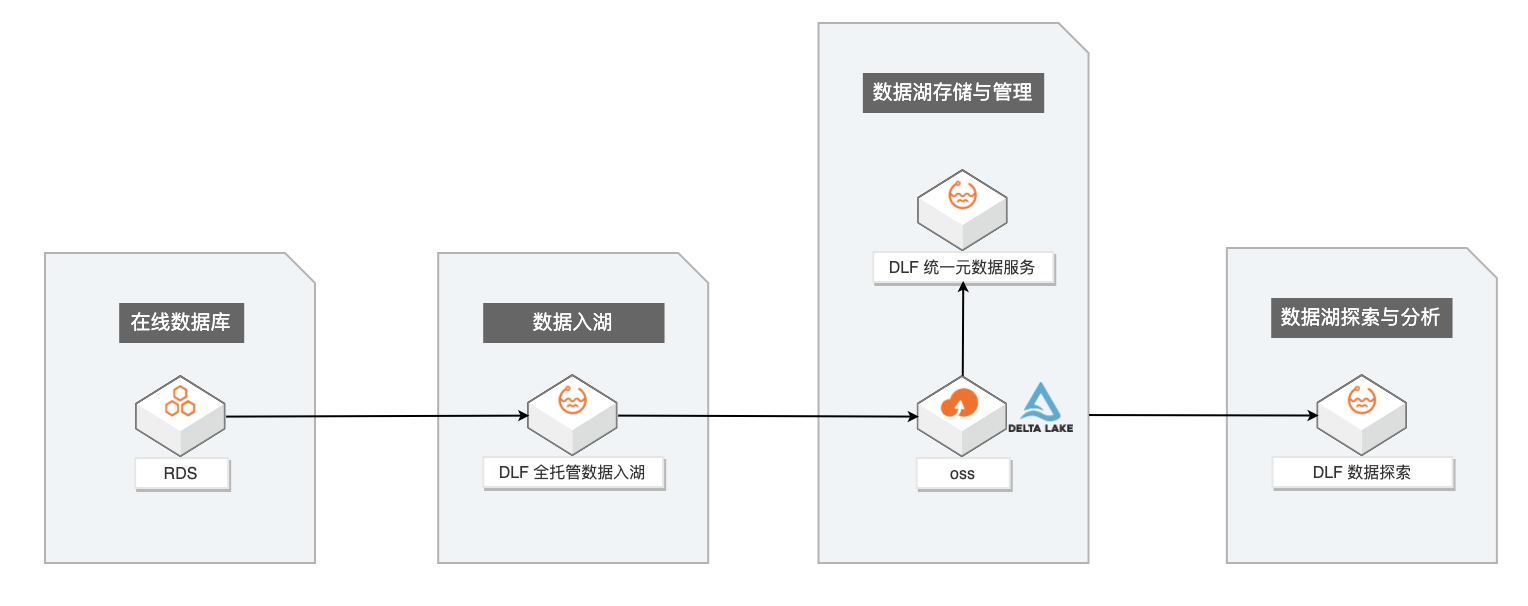
步骤一:服务开通并准备数据
1. 服务开通
确保DLF、OSS、DDI、RDS、DTS等云产品服务已开通。注意DLF、RDS、DDI实例均需在同一Region下。
2. 数据准备
RDS数据准备,在RDS中创建数据库dlf-demo。在账户中心创建能够读取employees数据库的用户账号,如dlf_admin。
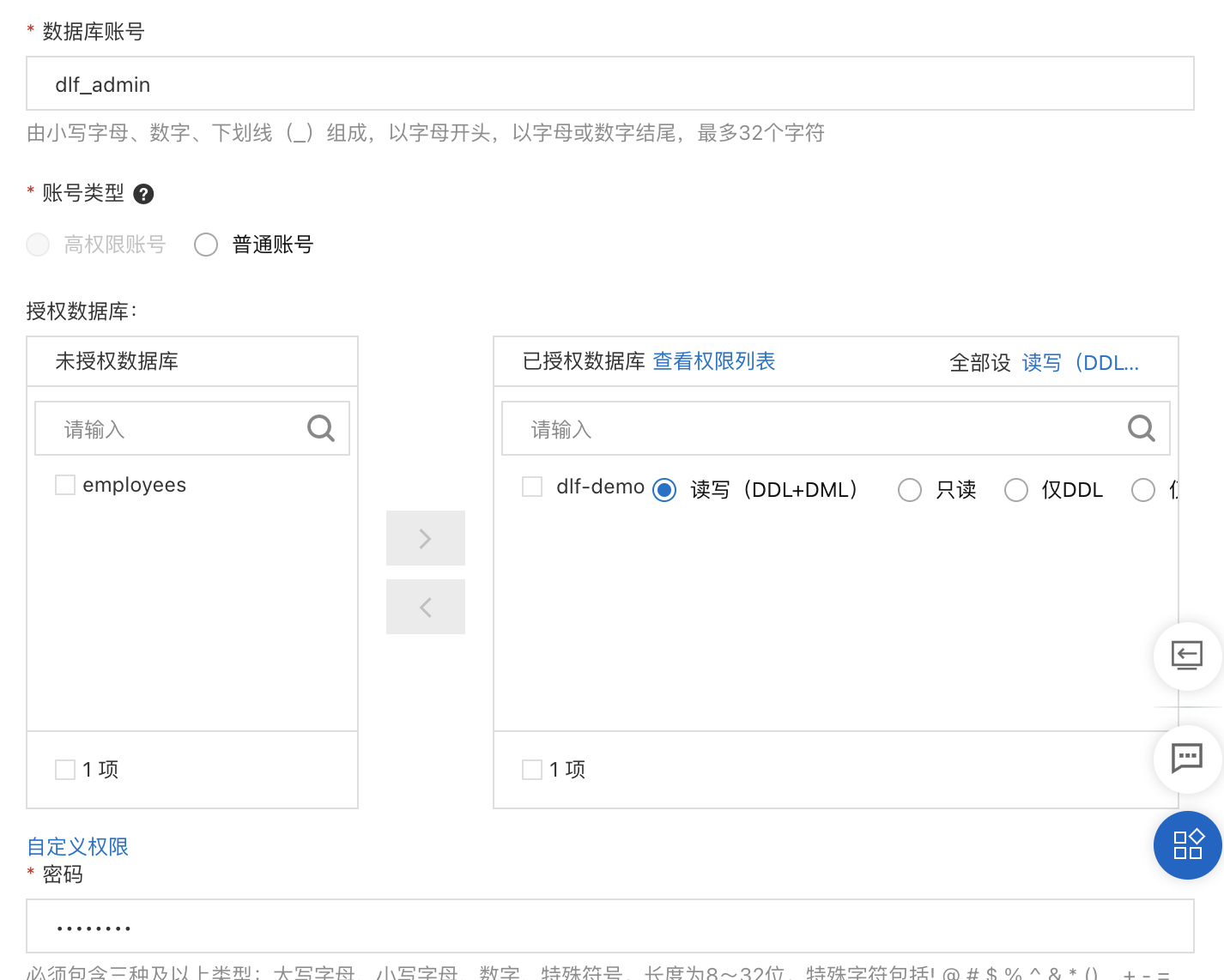
通过DMS登录数据库,运行以下语句创建employees表,及插入少量数据。
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` enum('M','F') NOT NULL,
`hire_date` date NOT NULL,
`create_time` DATETIME NOT NULL,
`update_time` DATETIME NOT NULL,
PRIMARY KEY (`emp_no`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
INSERT INTO `employees` VALUES (10001,'1953-09-02','Georgi','Facello','M','1986-06-26', now(), now());
INSERT INTO `employees` VALUES (10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21', now(), now());
步骤二:数据入湖
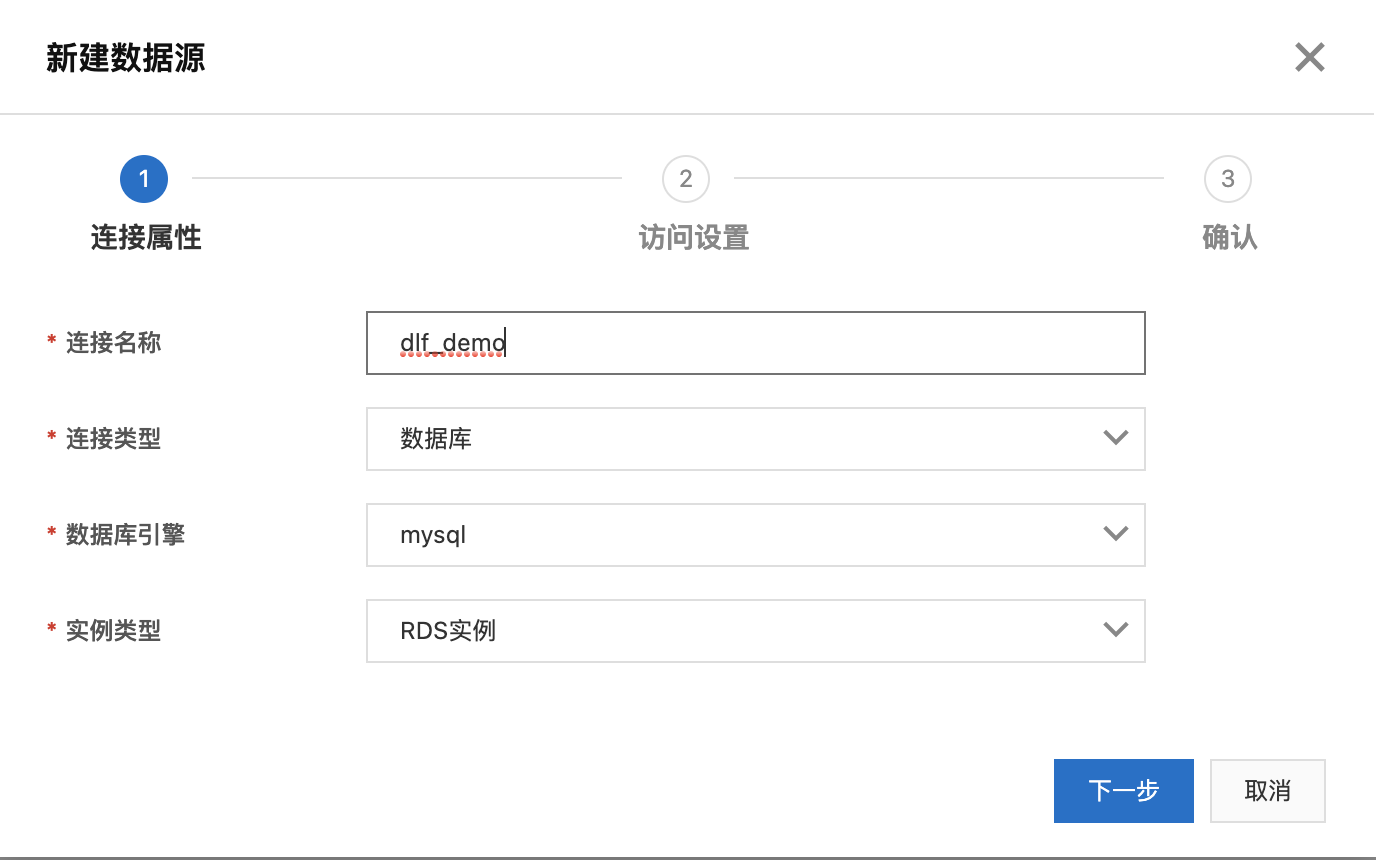
1. 创建数据源
a. 进入DLF控制台界面:https://dlf.console.aliyun.com/cn-hangzhou/home,点击菜单“数据入湖 -> 数据源管理”。
b. 点击“新建数据源”。填写连接名称,选择数据准备中的使用的RDS实例,填写账号密码,点击“连接测试”验证网络连通性及账号可用性。
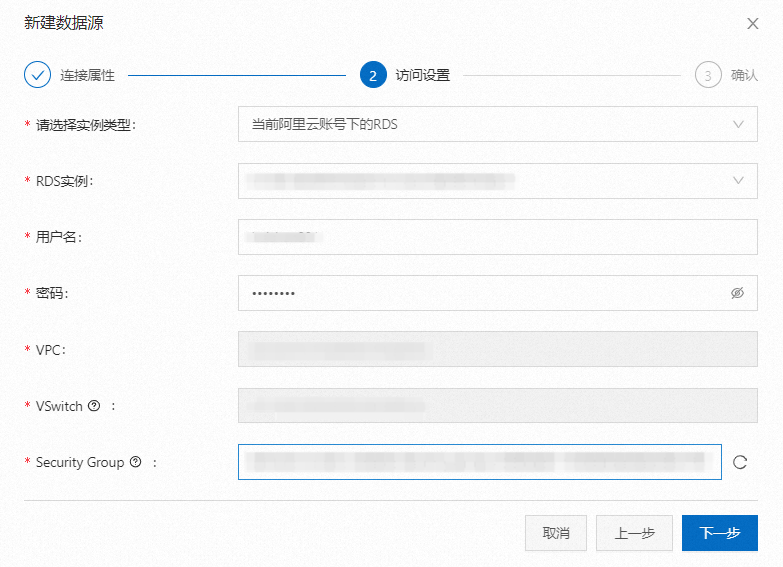 c. 点击下一步,确定,完成数据源创建。
c. 点击下一步,确定,完成数据源创建。
2. 创建元数据库
a. 在OSS中新建Bucket,dlf-demo;
b. 点击左侧菜单“元数据管理”->“元数据库”,点击“新建元数据库”。填写名称,新建目录delta-test,并选择。
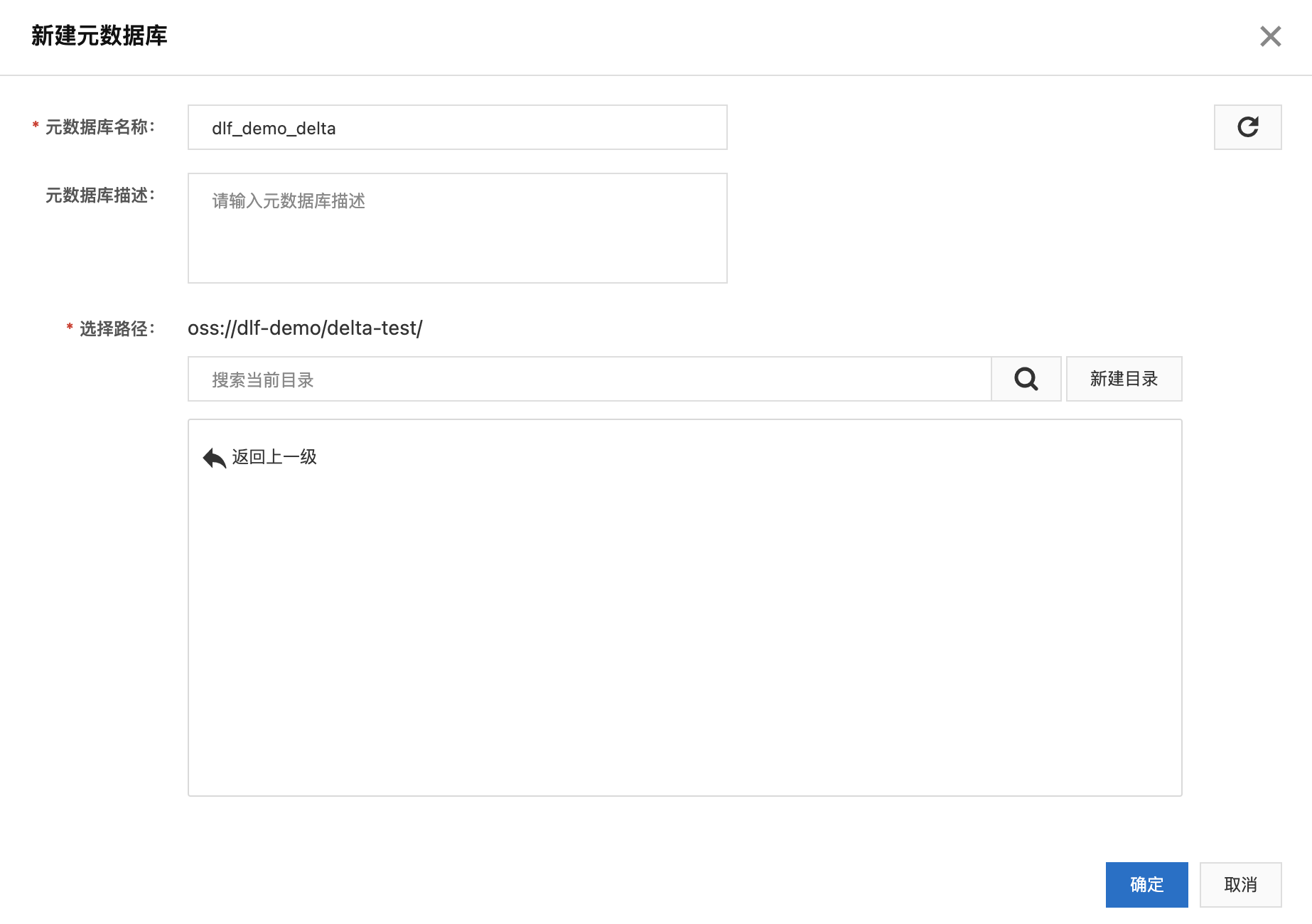
3. 创建入湖任务
a. 点击菜单“数据入湖”->“入湖任务管理”,点击“新建入湖任务”。
b. 选择“关系数据库实时入湖”,按照下图的信息填写数据源、目标数据湖、任务配置等信息。并保存。
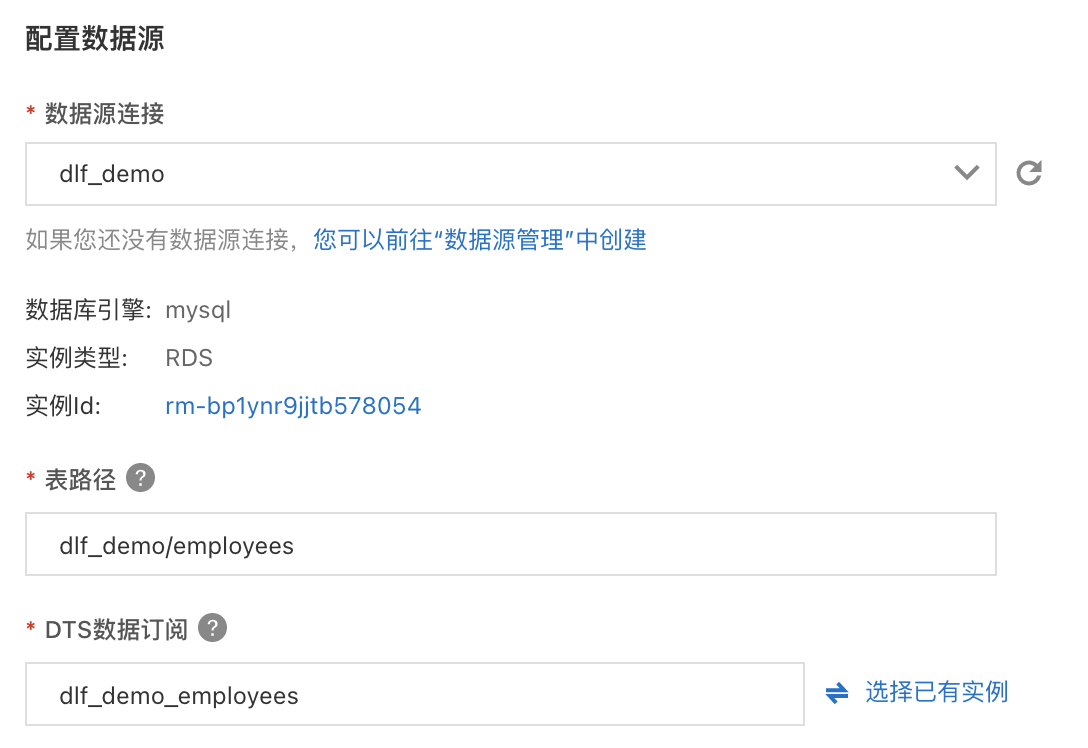
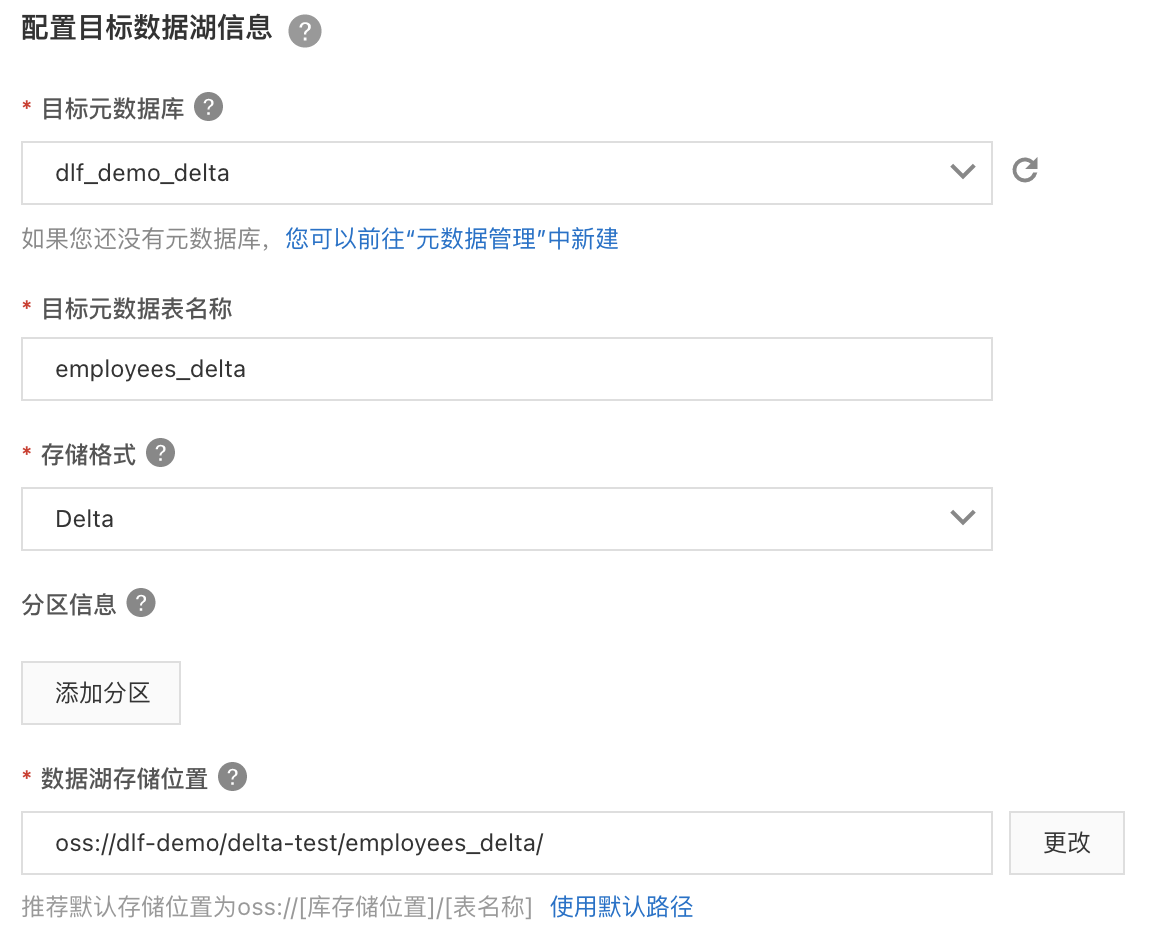
c. 配置数据源,选择刚才新建的“dlf_demo”连接,使用表路径 “dlf_demo/employees”,选择新建DTS订阅,填写名称。

d. 回到任务管理页面,点击“运行”新建的入湖任务。就会看到任务进入“初始化中”状态,随后会进入“运行”状态。
e. 点击“详情”进入任务详情页,可以看到相应的数据库表信息。
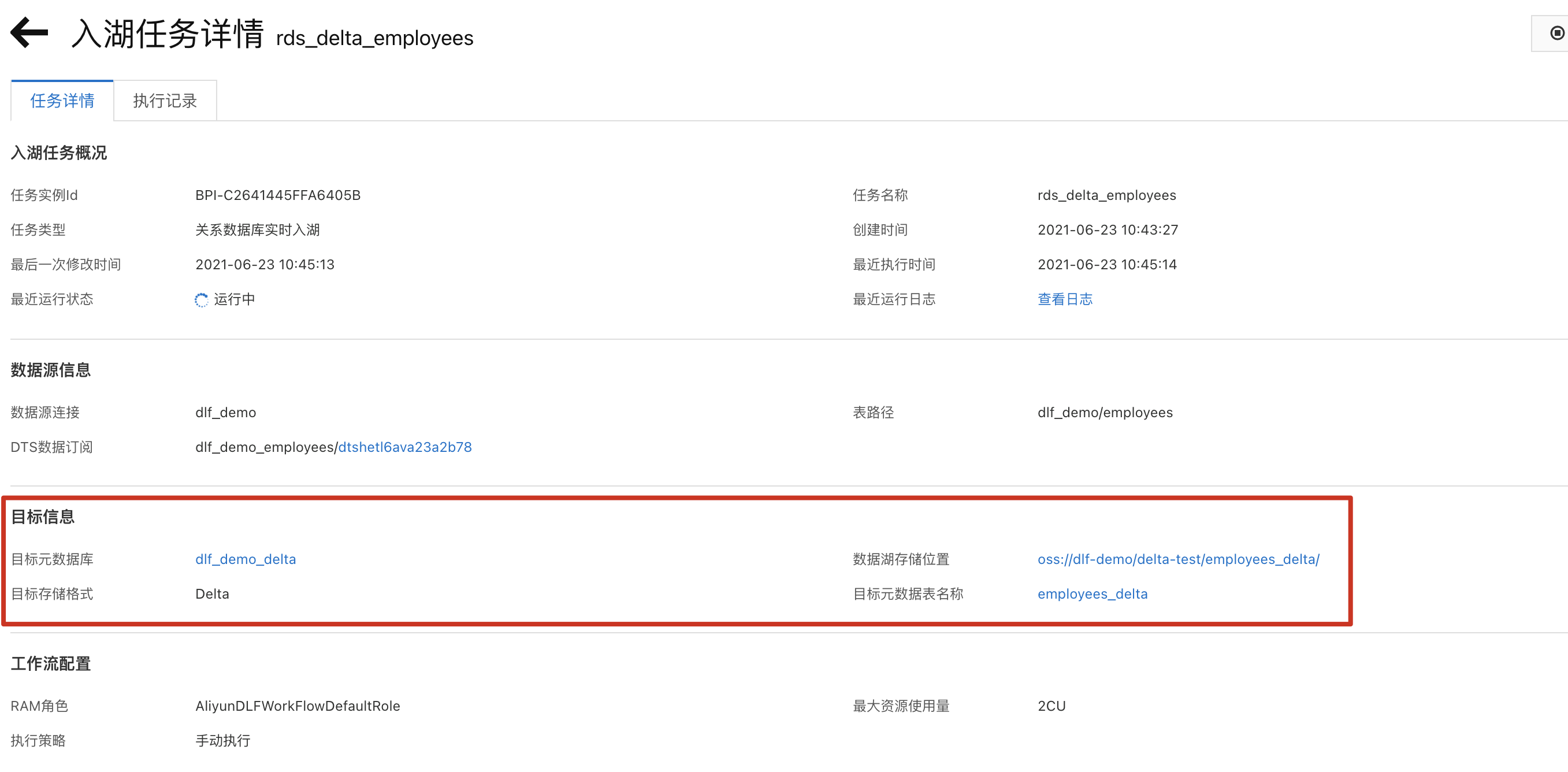
该数据入湖任务,属于全量+增量入湖,大约3至5分钟后,全量数据会完成导入,随后自动进入实时监听状态。如果有数据更新,则会自动更新至Delta Lake数据中。
步骤三:数据湖探索与分析
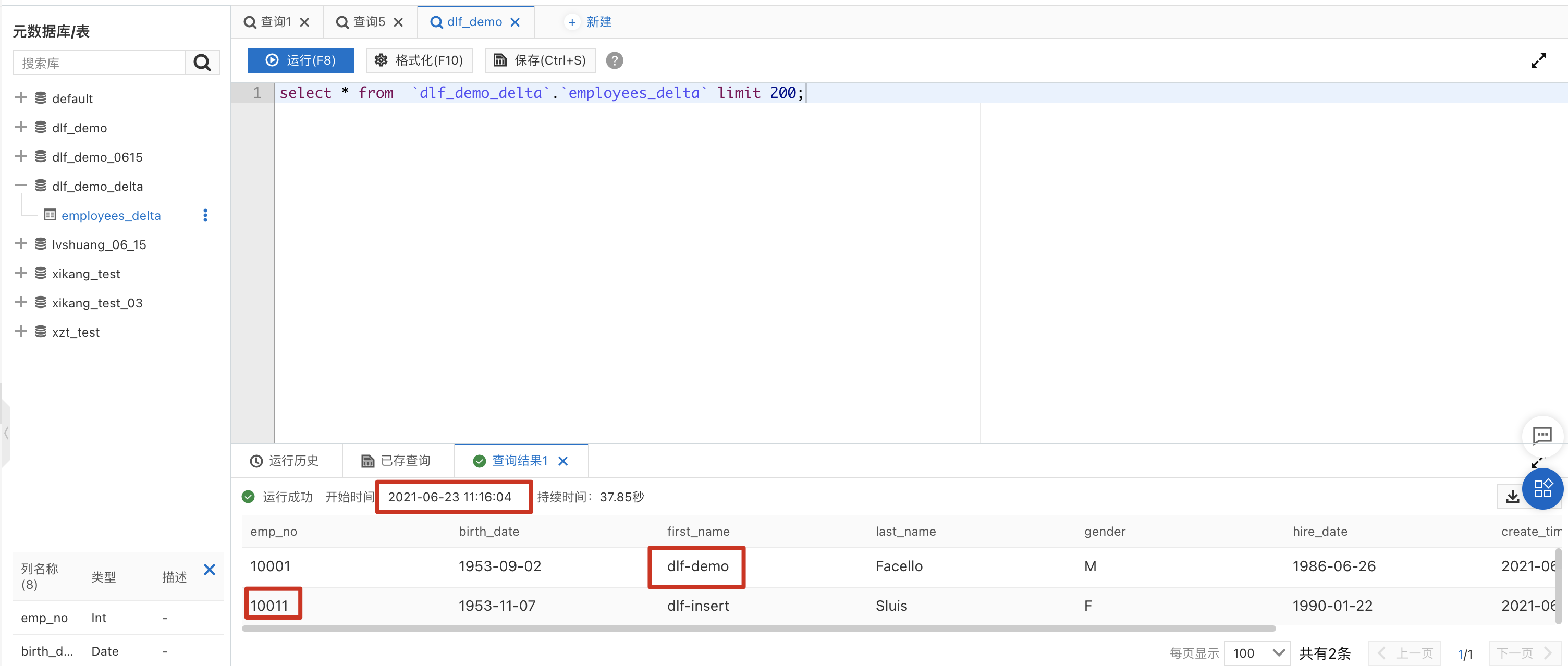
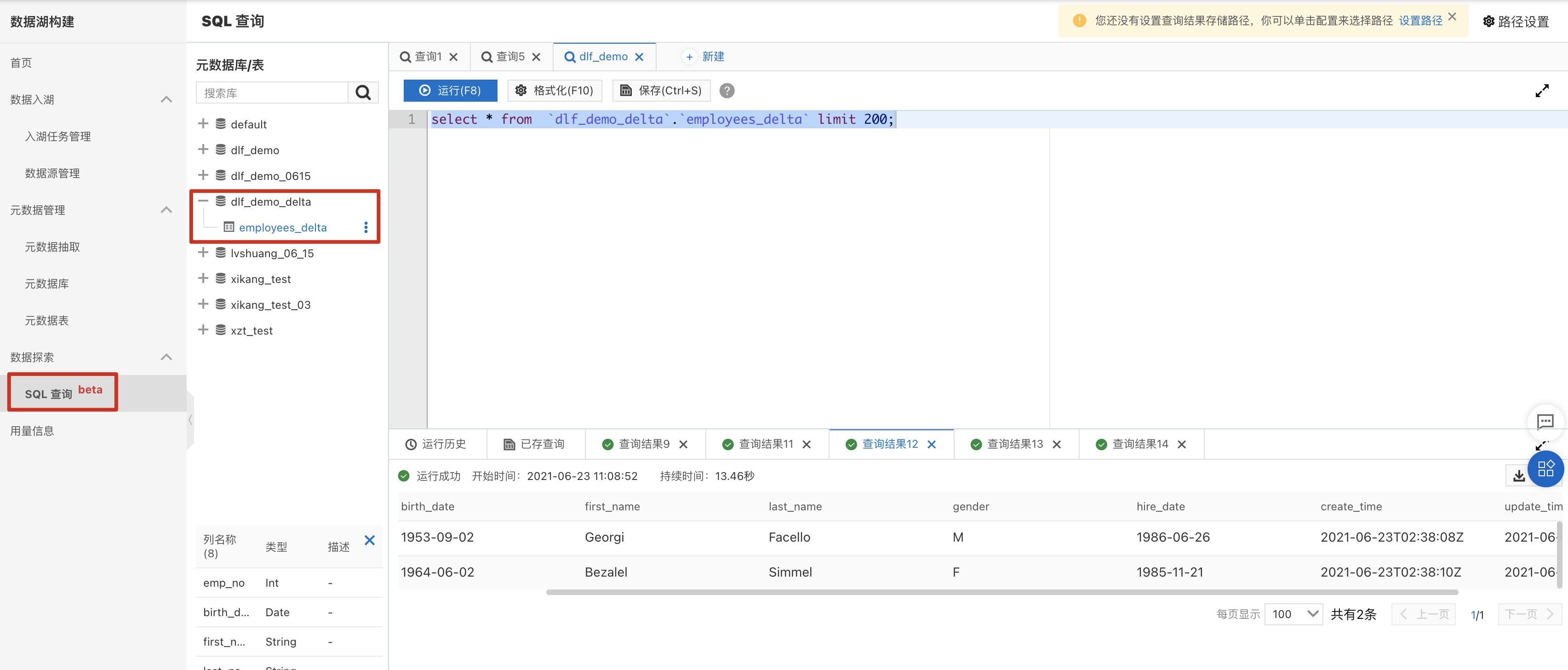
DLF产品提供了轻量级的数据预览和探索功能,点击菜单“数据探索”->“SQL查询”进入数据查询页面。
a. 在元数据库表中,找到“dlf_demo_delta”,展开后可以看到employees表已经自动创建完成。双击该表名称,右侧sql编辑框会出现查询该表的sql语句,点击“运行”,即可获得数据查询结果。
b. 回到DMS控制台,运行下方update、delete和insert SQL语句。
update `employees` set `first_name` = 'dlf-demo', `update_time` = now() where `emp_no` =10001;
delete FROM `employees` where `emp_no` = 10002;
INSERT INTO `employees` VALUES (10011,'1953-11-07','dlf-insert','Sluis','F','1990-01-22', now(), now());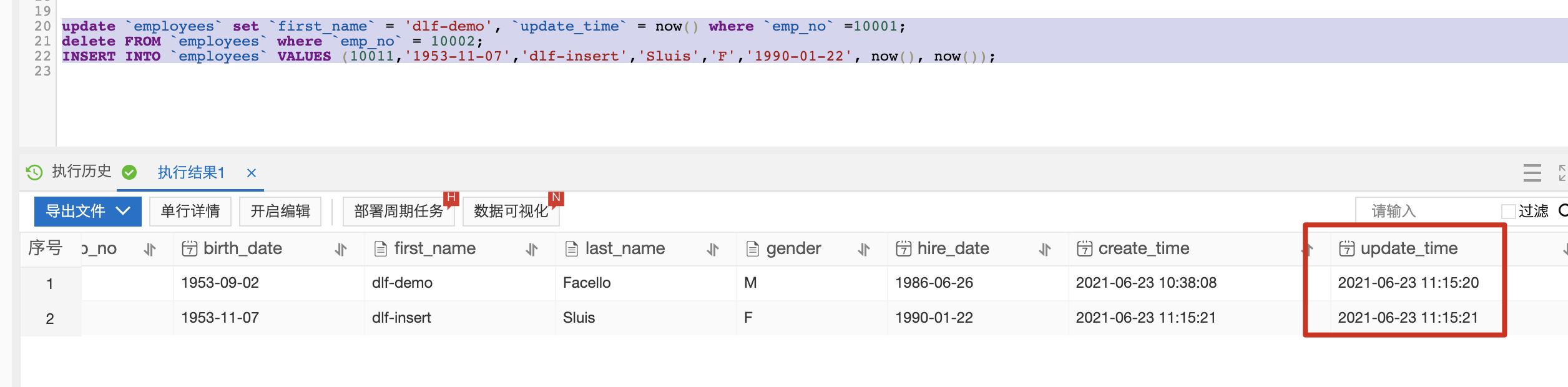
c. 大约1至3分钟后,在DLF 数据探索再次执行刚才的select语句,所有的数据更新已经同步至数据湖中。