
本指南详细说明了如何在阿里云数据管理工作空间中,创建、配置并使用托管的 MLFlow 服务。DMS MLFlow 为您提供一个安全、稳定、运行在您专有网络内的机器学习实验跟踪平台,帮助您高效管理模型训练的元数据、参数和指标。
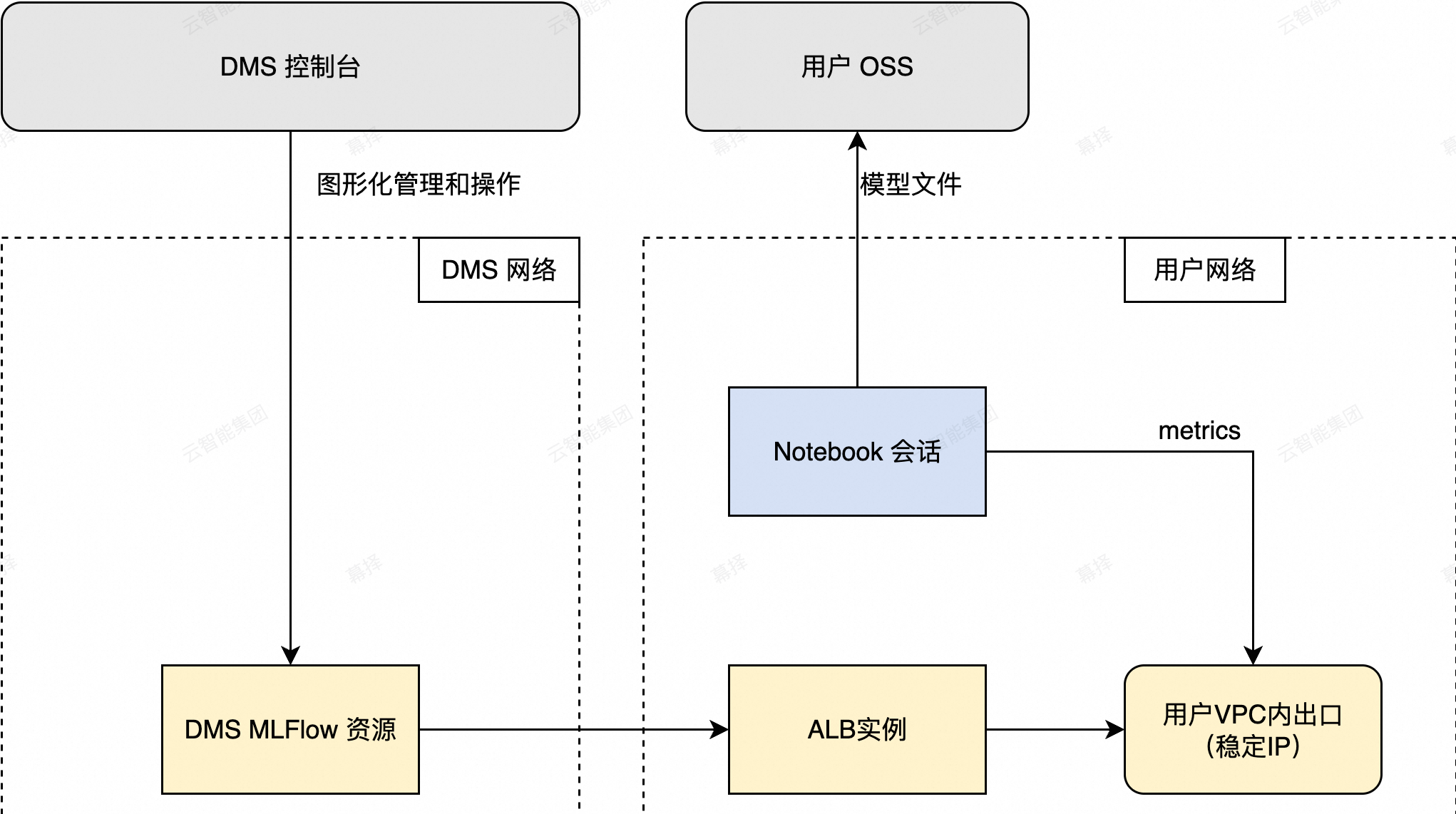
核心架构
服务托管:DMS 负责 MLFlow 实例的生命周期管理和底层资源的运维。
VPC 原生集成:通过应用型负载均衡将 MLFlow 服务稳定地暴露在您的 VPC 内,确保网络隔离与安全。
按需使用:与 DMS Notebook 等环境无缝集成,按实际计算资源消耗付费。
支持地域
华北2(北京)、华东2(上海)、华东1(杭州)。(当前处于灰度开放阶段,具体可用性以控制台入口是否可见为准)
准备工作
在创建 MLFlow 实例之前,请进行以下准备工作。
网络资源
对象存储 OSS
用途:存放模型训练的产物(如模型文件、数据集等)。DMS MLFlow 本身仅负责记录元数据(含训练过程指标信息和产物存储位置元信息等),产物需要存储到用户准备的OSS。
操作步骤:创建存储空间
工作空间
用途:工作空间是DMS的协作单元,DMS MLFlow的创建、管理以及可视化展示均需要在空间内完成。
操作步骤:工作空间准备
ALB服务关联角色
用途:DMS MLFlow通过应用型负载均衡(ALB)提供VPC内访问。如果您的账号从未使用过ALB产品,系统中不存在ALB服务关联角色,将导致MLFlow实例创建失败。
操作步骤:参见创建服务关联角色,在创建服务关联角色面板中,为信任的云服务选择ALB即可。
创建Notebook
登录数据管理DMS 5.0。
在顶部菜单栏中,选择Data + AI > 工作空间,或在极简模式的控制台,点击控制台左上角的
 图标,选择全部功能 > Data + AI > 工作空间。
图标,选择全部功能 > Data + AI > 工作空间。在工作空间列表页,找到目标空间,点击ID进入工作空间。
在工作空间内,找到并进入 Notebook 会话管理页面。
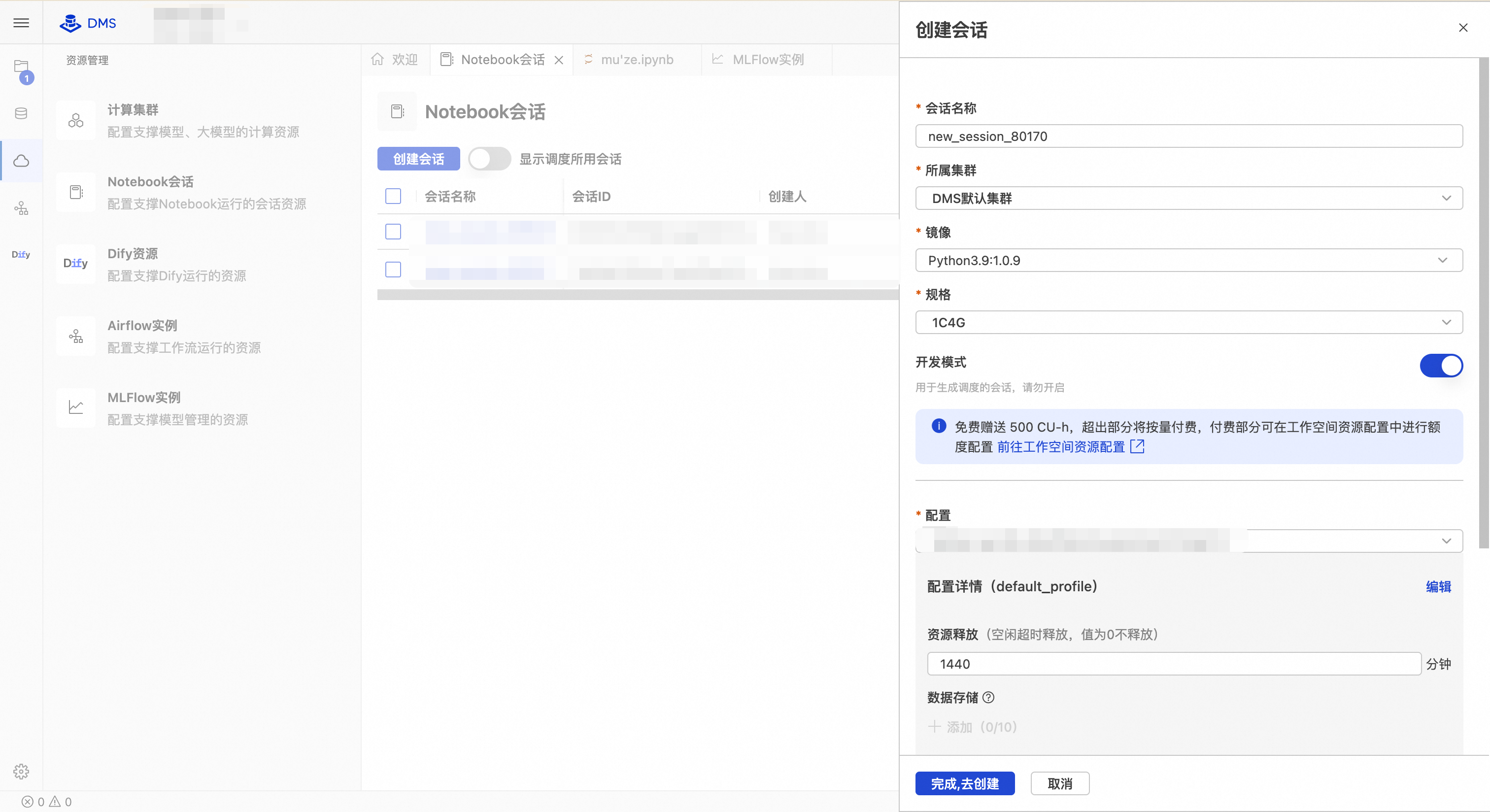
点击创建会话按钮,在创建会话弹窗中,填写对应信息后,点击完成,去创建按钮,完成会话的创建。
参数名称
参数说明
参数示例
会话名称
Notebook 会话的唯一标识名称,用于区分不同任务;支持字母、数字、下划线,长度建议不超过 64 字符。
new_session_20250401所属集群
指定运行 Notebook 的计算集群。默认使用 DMS 提供的共享集群,也可选择已授权的专属集群。
DMS默认集群镜像
运行环境的基础容器镜像,包含预装的 Python 版本及常用 AI/数据科学库(如 pandas、numpy、dashscope 等)。
Python3.9:1.0.9规格
分配给 Notebook 实例的计算资源,格式为“CPU核数 + 内存大小”。资源越高,处理能力越强,计费也相应增加。
1C4G(1 核 CPU,4 GB 内存)开发模式
控制是否启用调试与交互增强功能(如自动保存、热重载等)。开启后资源消耗略高,适合开发调试;生产环境推荐关闭。
关闭/开启配置
预设的运行时配置模板,可包含网络策略、挂载点、安全上下文等。
default_profile为系统默认安全配置。default_profile资源释放
会话空闲自动释放时间(单位:分钟)。超时后实例将被回收以节省资源,未保存的内容可能丢失,请及时持久化。
1440(即 24 小时)数据存储
是否挂载持久化存储卷。选择“无”表示所有数据仅保存在临时容器中,重启后丢失;如需持久化,请绑定 OSS 或 NAS。
无/oss://my-bucket/notebookPypi管理包
额外安装的 Python 第三方包列表(通过 pip 安装)。多个包用逗号分隔,支持指定版本(如
dashscope==1.19.0)。无/dashscope, pandas==2.1.0环境变量
自定义运行时环境变量,常用于配置 API Key、区域、日志级别等。格式为
KEY=VALUE,多组用换行或分号分隔。无/DASHSCOPE_API_KEY=sk-xxx在Notebook会话列表,点击目标会话操作列的启动按钮,完成会话的启动。
创建并配置 MLFlow 实例
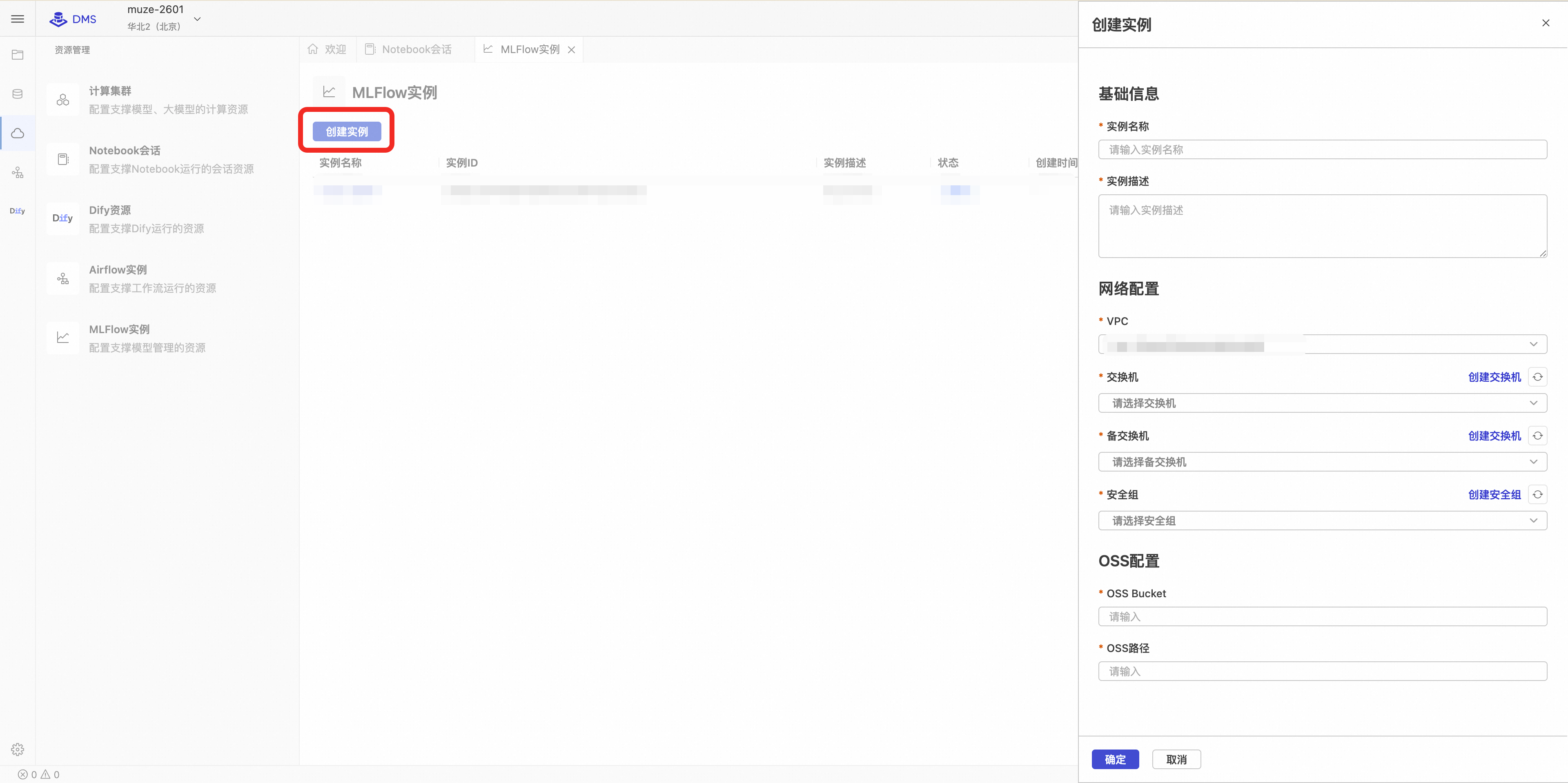
创建 MLFlow 实例
在 DMS 工作空间内,找到并进入 MLFlow 管理页面。
点击创建实例按钮,在弹出的配置向导中填写以下信息:

参数名称
参数说明
参数示例
实例名称
MLFlow实例的名称
my-mlflow
实例描述
MLFlow实例的描述
Description of my MLFlow.
VPC
选择使用的专有网络,默认选中为当前工作空间的专有网络。不同专有网络的Notebook和MLFlow实例之间无法互相联通。
vpc-fs******4a
交换机
选择主交换机。MLFlow资源和负载均衡会分别在该交换机占用一个IP,请确保交换机下可用IP充足。
vsw-sg******7h
备交换机
选择备交换机,该交换机用于提供负载均衡的高可用能力,负载均衡会在该交换机占用一个IP,请确保交换机下可用IP充足。备交换机必须和主交换机在不同的可用区,不然会导致MLFlow创建失败。
vsw-hq******v9
安全组
选择安全组。MLFlow的用户侧网络会受到该安全组的管控。请保证该安全组允许源IP(如Notebook IP)的访问,不然可能导致无法连通MLFlow实例。只能选择普通安全组,使用托管安全组会导致MLFlow实例创建失败。
sg-zb******iq
OSS Bucket
阿里云OSS存储桶名称。若您在创建实验的时候没有指定Artifact Root,DMS MLFlow会默认使用 oss://OSS Bucket/OSS路径作为Artifact Root。
my-bucket
OSS路径
阿里云OSS存储路径。若您在创建实验的时候没有指定Artifact Root,DMS MLFlow会默认使用 oss://OSS Bucket/OSS路径作为Artifact Root。
mlflow-root
确认信息无误后,点击确定。实例的创建过程需要几分钟,请耐心等待其状态变为运行中。
在操作列中有多个按钮,分别对应以下功能:
编辑:可以对名称和描述进行修改。
打开:在内嵌页面中即可查看mlflow页面。
VPC地址:VPC地址是通过ALB在用户VPC内打通的稳定IP。点击复制图标可复制稳定IP地址。两个地址中的任意一个都可以作为MLFlow的后端服务器,端口为80(即通过地址可以直接访问)即可在同一个VPC内访问Mlflow。
重新部署:目前暂不支持此操作。
释放:释放后会在后台销毁对应的数据库以及Mlflow计算实例。
配置 ALB 访问控制
为保证网络安全,MLFlow 实例关联的 ALB 默认拒绝所有访问。您必须手动配置访问控制策略,否则无法从 VPC 内访问。
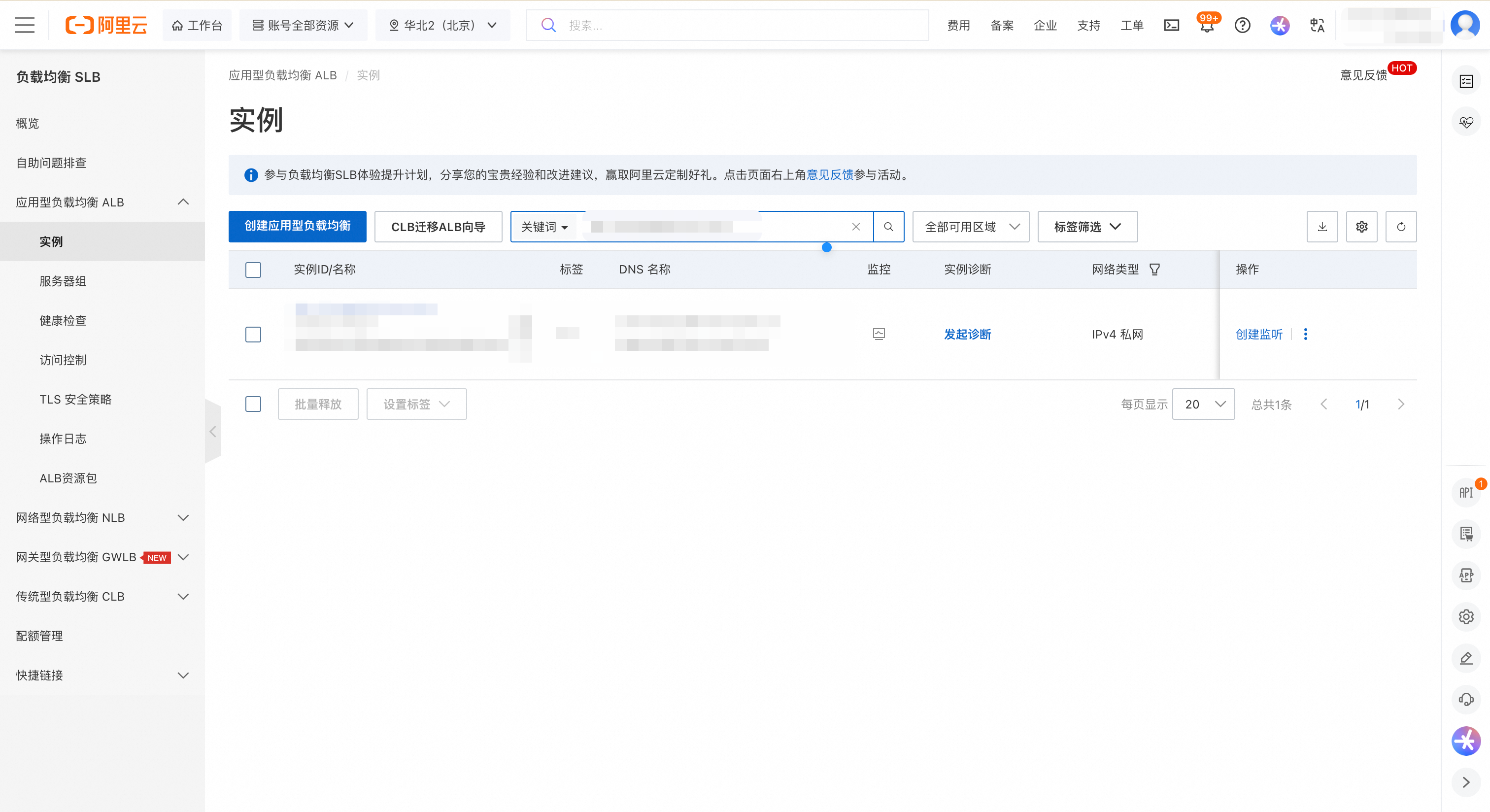
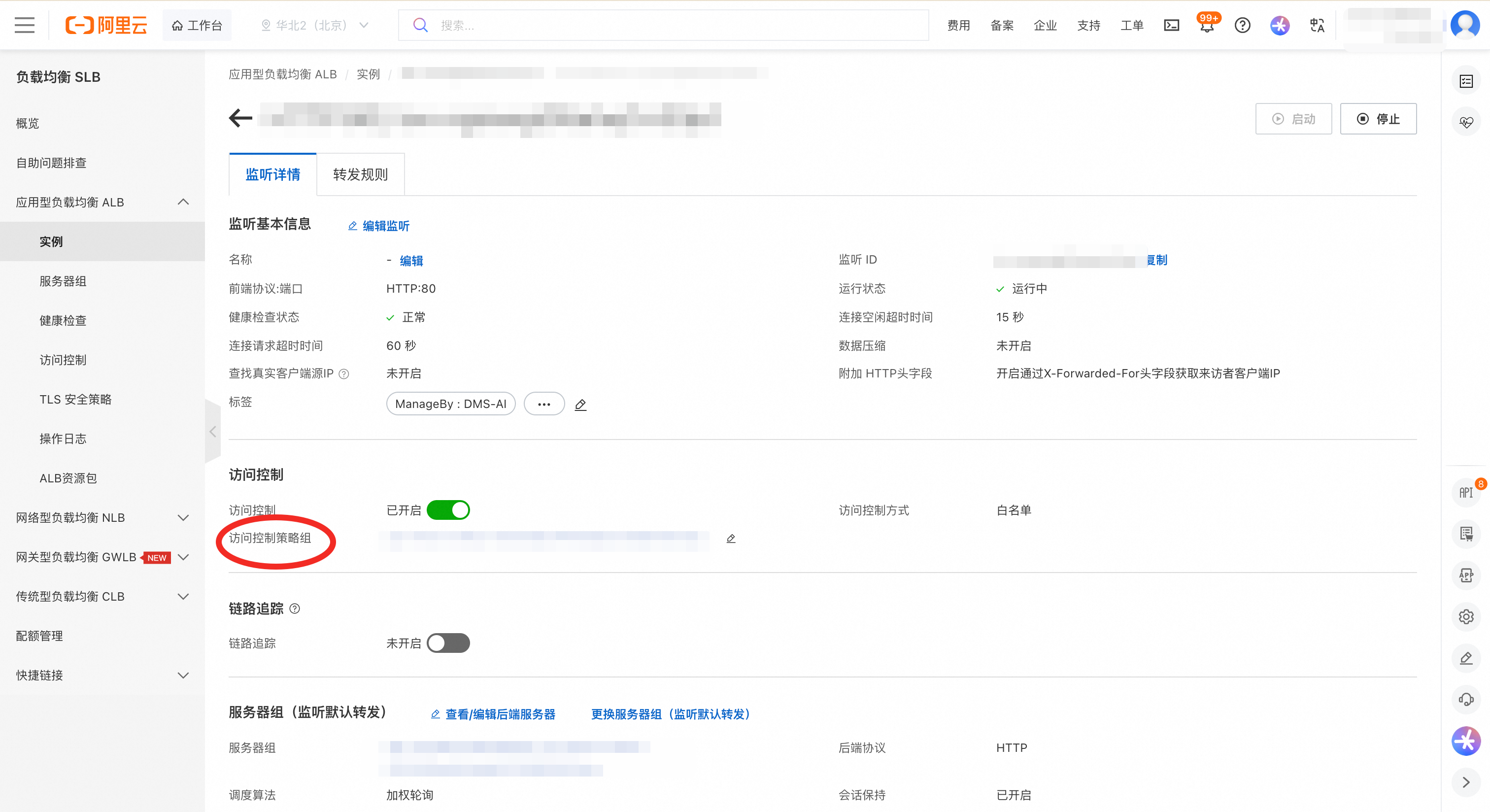
在 MLFlow 实例详情页面,复制实例 ID。
前往 ALB 控制台,注意选择与 MLFlow 实例相同的地域,在左侧导航栏选择实例。
在实例页面中,使用实例 ID 作为关键词搜索,找到对应的 ALB 实例。
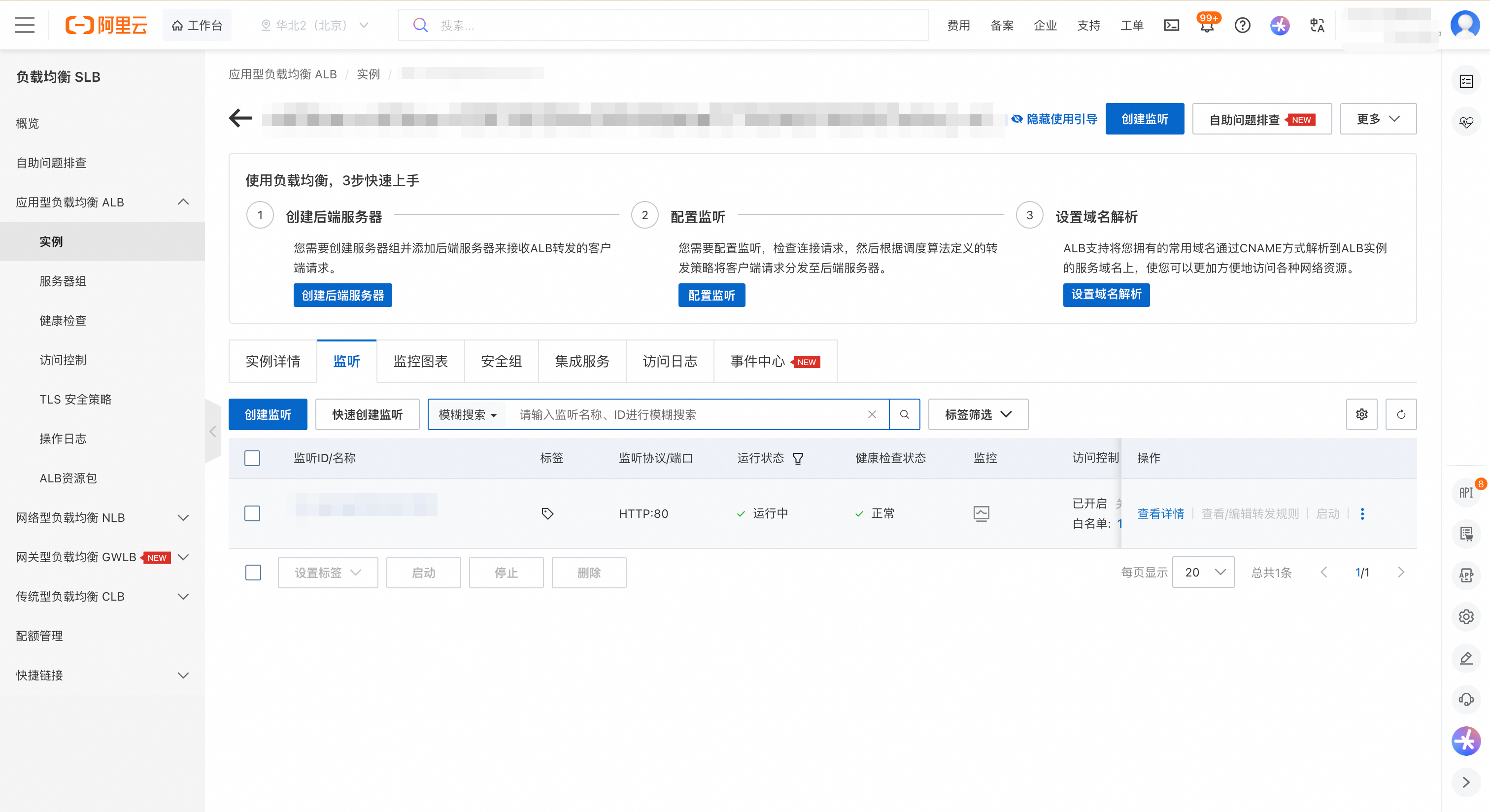
点击实例 ID,进入实例详情页,然后切换到监听页签。
找到 80 端口对应的监听器,在目标操作列,点击查看详情按钮。
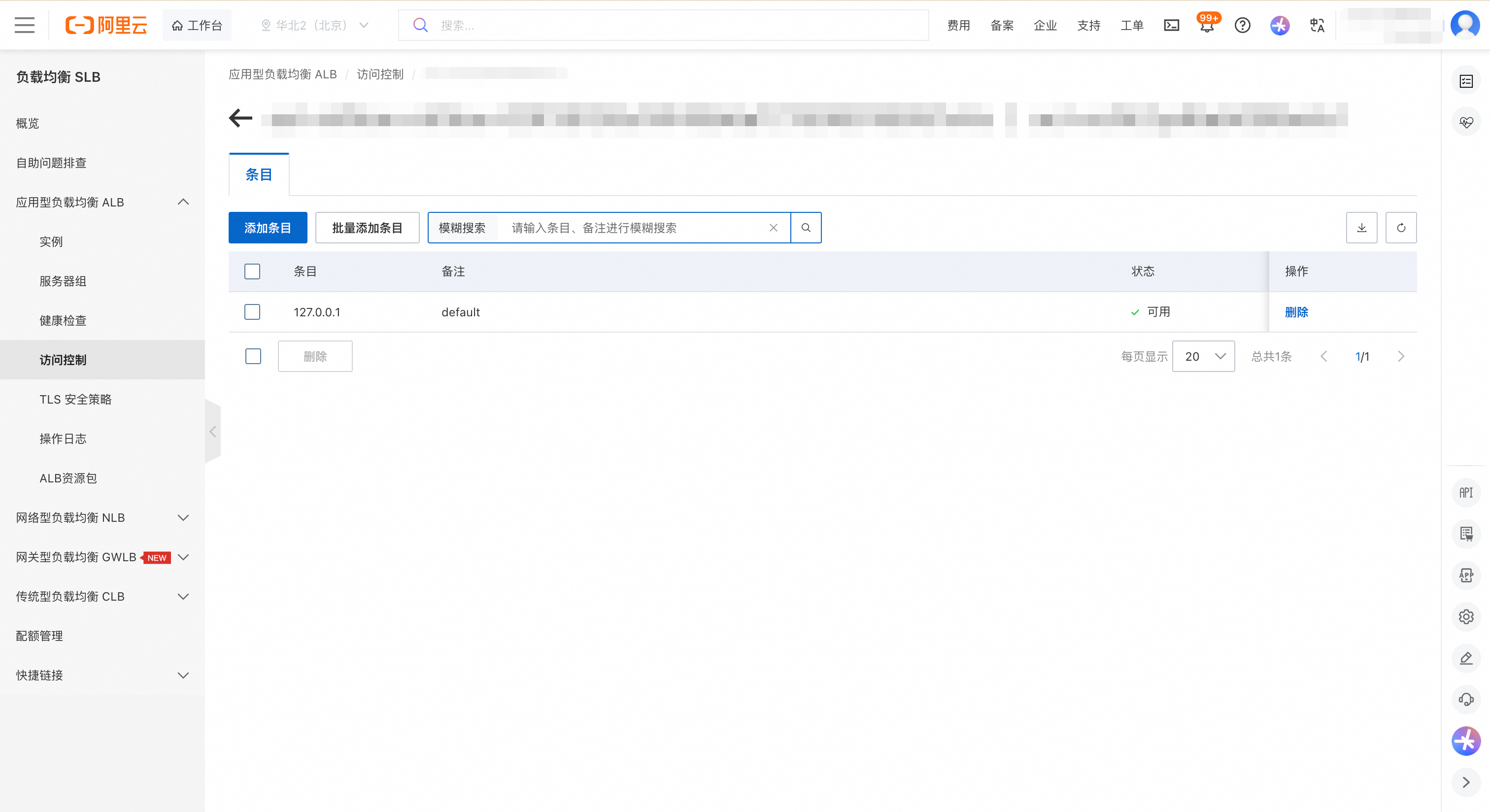
在监听详情页签的访问控制模块,点击访问控制策略组的id。
在条目页签中,点击添加条目按钮,配置允许访问的来源。推荐配置您的 VPC 网段(例如
192.168.0.0/16),或更精确地指定 Notebook 所在网段,以允许来自这些网段的访问。
在 Notebook 中集成和使用 MLFlow
在使用之前,请检查并确认您的 MLFlow 实例已创建完毕,同时 ALB 的访问控制也已设置完成,能够允许 Notebook 环境正常访问 MLFlow 服务。
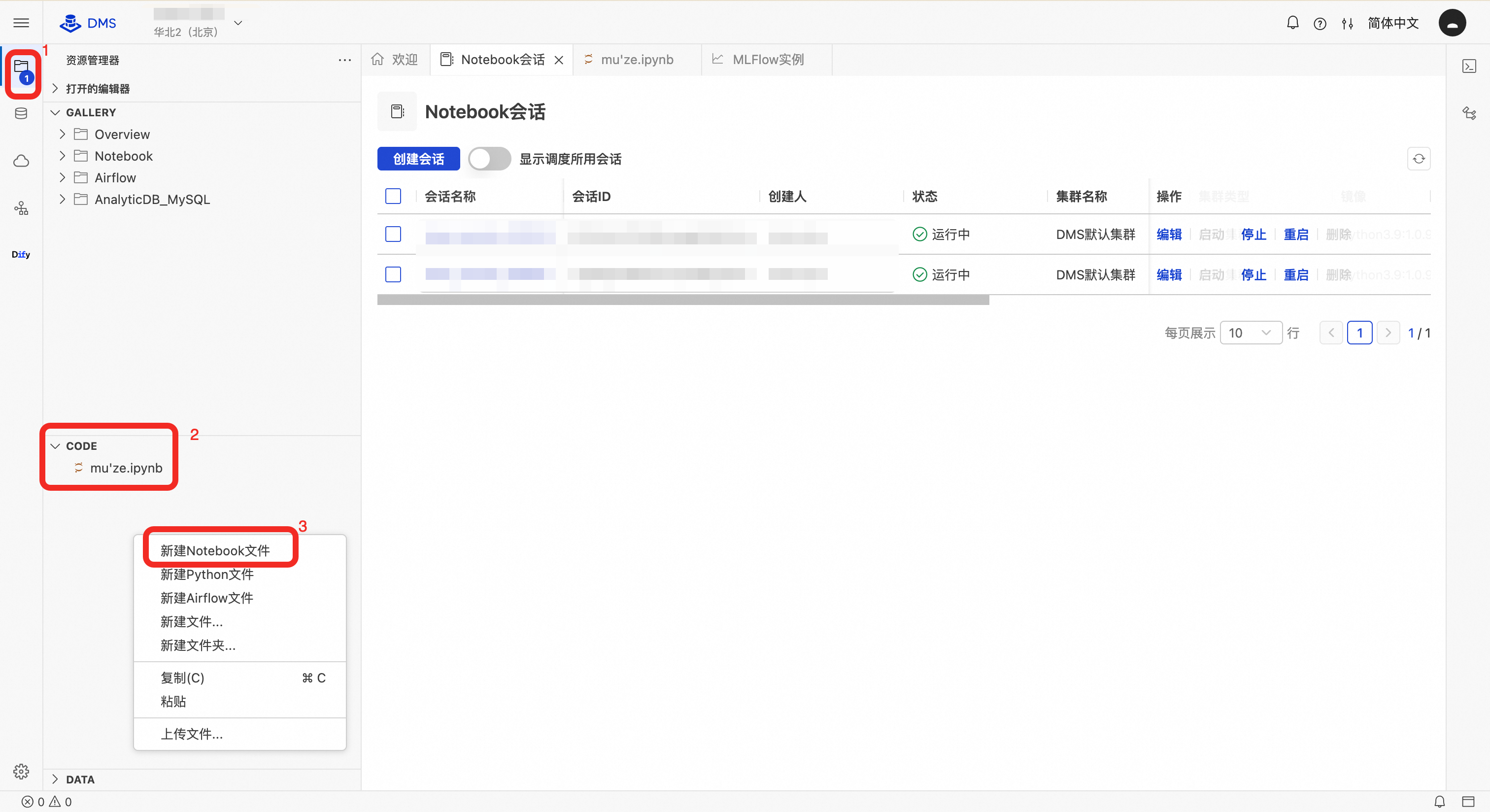
新建文件:在资源管理器的CODE区域右键单击,然后选择新建 Notebook 文件。
安装mlflow python sdk:在新建的Notebook文件执行框中,输入
!pip install mlflow命令后,点击运行按钮。编写训练代码:在代码中,使用从 MLFlow 实例详情页获取的VPC 地址来替换
SERVER_URL。import mlflow import mlflow.sklearn from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score import pandas as pd def main(): # 设置远程跟踪 URI(仅用于记录 metadata) mlflow.set_tracking_uri("SERVER_URL") # 设置 MLflow 实验名称 mlflow.set_experiment("Iris Classification") # 加载 Iris 数据集 iris = datasets.load_iris() X = iris.data y = iris.target # 创建特征名称的 DataFrame(可选,便于记录) feature_names = iris.feature_names target_names = iris.target_names # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42, stratify=y ) # 定义超参数 n_estimators = 100 max_depth = 3 random_state = 42 # 开始 MLflow 运行 with mlflow.start_run(run_name="RandomForest_Iris"): # 记录超参数 mlflow.log_param("n_estimators", n_estimators) mlflow.log_param("max_depth", max_depth) mlflow.log_param("random_state", random_state) mlflow.log_param("test_size", 0.2) # 创建并训练模型 model = RandomForestClassifier( n_estimators=n_estimators, max_depth=max_depth, random_state=random_state ) model.fit(X_train, y_train) # 进行预测 y_pred = model.predict(X_test) # 计算评估指标 accuracy = accuracy_score(y_test, y_pred) precision = precision_score(y_test, y_pred, average='weighted') recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted') # 记录评估指标 mlflow.log_metric("accuracy", accuracy) mlflow.log_metric("precision", precision) mlflow.log_metric("recall", recall) mlflow.log_metric("f1_score", f1) # 记录特征名称和目标名称作为标签 mlflow.set_tag("features", ", ".join(feature_names)) mlflow.set_tag("targets", ", ".join(target_names)) mlflow.set_tag("algorithm", "RandomForestClassifier") print(f"Model trained successfully!") print(f"Accuracy: {accuracy:.4f}") print(f"Precision: {precision:.4f}") print(f"Recall: {recall:.4f}") print(f"F1 Score: {f1:.4f}") # 记录模型 mlflow.sklearn.log_model(model, "iris_model") # 获取当前运行信息 run_id = mlflow.active_run().info.run_id experiment_id = mlflow.active_run().info.experiment_id print(f"Run ID: {run_id}") print(f"Experiment ID: {experiment_id}") if __name__ == "__main__": main()
常见问题
Q:为什么无法通过 IP 地址访问 DMS MLFlow ?
A:请按以下顺序排查:访问控制:确认已在 ALB 的访问控制策略中,添加了允许您当前设备或 Notebook 网段访问的规则。
安全组:确认 MLFlow 实例关联的安全组入方向规则已放通了来自您访问源 IP 的 80 端口。
网络连通性:确认您的访问环境(如本地 PC、ECS)与 MLFlow 实例所在的 VPC 网络是连通的(例如通过 VPN、云企业网等)。
Q:我训练好的模型文件保存在哪里了?
A:DMS MLFlow 本身不负责存储模型文件等二进制产物。您配置的阿里云OSS桶和路径会成为默认Artifact Root,您也可以在创建实验的时候显式指定Artifact Root。您需要自行配置凭证以保证工件的上传。若您使用阿里云OSS作为工件存储,推荐使用MLFlow插件:https://mlflow.org/docs/latest/ml/plugins/#storage--persistence