
本文介绍如何在ACS集群中使用ACS LLM推理容器镜像创建工作负载,快速构建LLM推理环境。
前提条件
已创建ACS集群。具体操作,请参见创建ACS集群。
已创建带有模型文件的NAS存储卷。
ACS LLM推理容器镜像介绍
按照如下示例获取ACS LLM推理容器镜像,以便您在ACS实例上配置工作负载时使用。
ACS AI容器镜像为灵骏产品提供的标准镜像,您可以免费使用。关于最新的镜像发布信息,请参见ACS容器镜像版本发布记录。
建议您使用VPC方式加速拉取AI容器镜像,减少镜像拉取的时间。
镜像名称 | 镜像Tag | 公网镜像地址 | VPC镜像地址 | 说明 |
inference-xpu-pytorch | 25.03-v1.4.3-hotfix-vllm0.7.3-torch2.5-cu123-20250331 | egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/inference-xpu-pytorch:25.03-v1.4.3-hotfix-vllm0.7.3-torch2.5-cu123-20250331 |
|
|
部署大模型推理任务
步骤一:配置无状态工作负载(Deployment)
使用kubectl命令行工具或直接在阿里云ACS控制台操作,创建一个Deployment来部署大模型推理任务。
第一次创建需要拉取镜像,大约需要20分钟左右,您可以在目标集群工作负载>容器组>事件下查看Pod的运行状态。Qwen2.5-7B-Instruct模型加载大约需要5-10分钟。请以实际部署环境为准。
您也可以直接创建一个Pod进行测试,下面是创建Pod的YAML示例,可快速启动一个真武810E Pod。
控制台方式
以下内容以无状态工作负载的创建为例说明(使用其他方式创建任务是类似的)。
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 无状态。
点击使用YAML创建资源,使用以下YAML创建无状态工作负载。配置完成后,点击创建。
apiVersion: apps/v1 kind: Deployment metadata: labels: app: llm-test name: llm-test namespace: default spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app: llm-test template: metadata: labels: alibabacloud.com/hpn-type: rdma alibabacloud.com/compute-class: gpu-hpn app: llm-test spec: containers: - command: - sh - -c - python3 -m vllm.entrypoints.openai.api_server --model /mnt/Qwen2.5-7B-Instruct --trust-remote-code --tensor-parallel-size 8 --disable-custom-all-reduce # --tensor-parallel-size 8 为8卡并行 # /mnt/Qwen2.5-7B-Instruct #为模型在pod中的路径 image: acs-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/egslingjun/llm-inference-xpu:vllm0.4.2-pytorch2.3-cuda12.3-ubuntu22.04 imagePullPolicy: IfNotPresent name: llm-test resources: limits: cpu: 176 memory: 1800G alibabacloud.com/ppu: 16 requests: cpu: 176 memory: 1800G alibabacloud.com/ppu: 16 terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /mnt #NAS挂载路径 name: data - mountPath: /dev/shm name: cache-volume dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 volumes: - name: data persistentVolumeClaim: claimName: nas-pvc-fs #nas-pvc-fs为通过NAS创建的存储声明 - name: cache-volume emptyDir: medium: Memory sizeLimit: 500G返回集群工作负载页面,查看已创建的无状态工作负载Deployment。
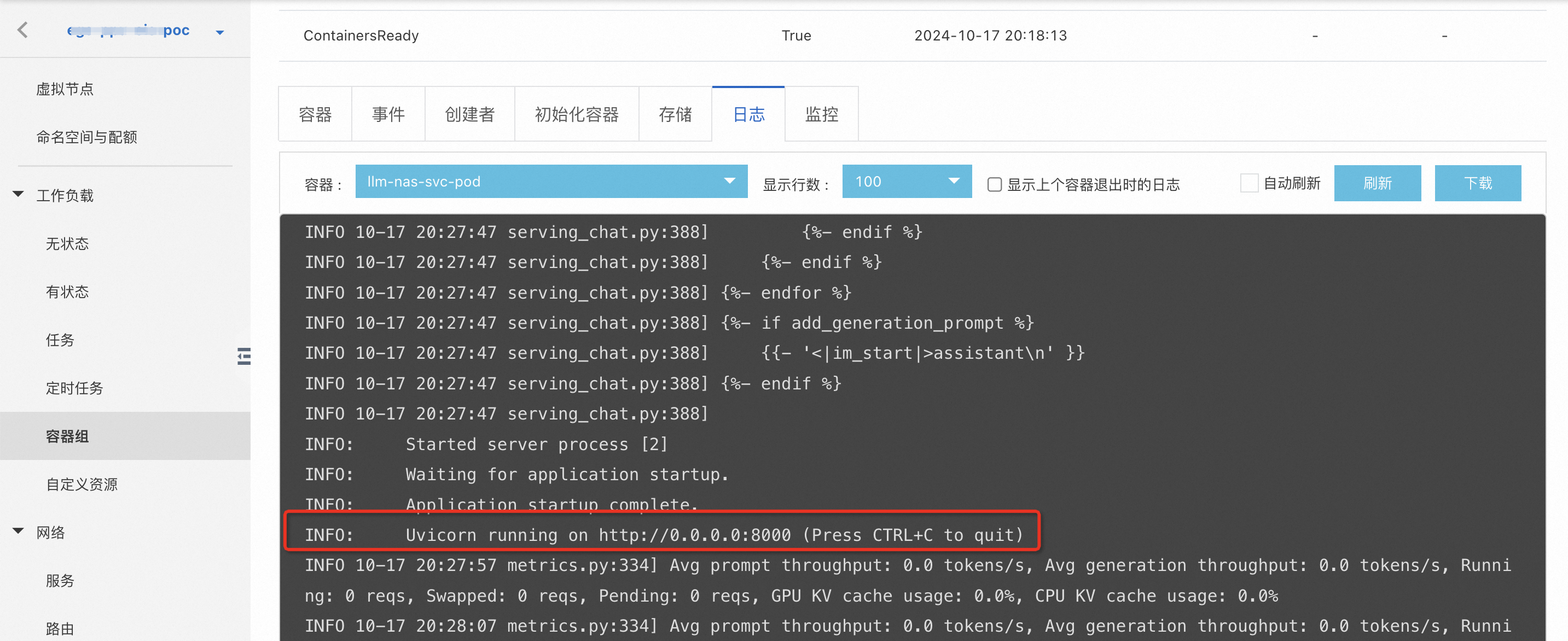
Pod为running状态即为创建成功,Pod启动后会自动启动vLLM serving服务。
在工作负载的下查看服务日志,有如下输出则说明服务启动成功。
kubectl方式
通过kubectl客户端连接集群。具体操作,请参见获取集群kubeconfig并通过kubectl工具连接集群。
将以下YAML示例内容写入文件llm-test.yaml。
apiVersion: apps/v1 kind: Deployment metadata: labels: app: llm-test name: llm-test namespace: default spec: progressDeadlineSeconds: 600 replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app: llm-test template: metadata: labels: alibabacloud.com/hpn-type: rdma alibabacloud.com/compute-class: gpu-hpn app: llm-test spec: containers: - command: - sh - -c - python3 -m vllm.entrypoints.openai.api_server --model /mnt/Qwen2.5-7B-Instruct --trust-remote-code --tensor-parallel-size 8 --disable-custom-all-reduce # --tensor-parallel-size 8 为8卡并行 # /mnt/Qwen2.5-7B-Instruct #为模型在pod中的路径 image: acs-registry-vpc.cn-wulanchabu.cr.aliyuncs.com/egslingjun/llm-inference-xpu:vllm0.4.2-pytorch2.3-cuda12.3-ubuntu22.04 imagePullPolicy: IfNotPresent name: llm-test resources: limits: cpu: 176 memory: 1800G alibabacloud.com/ppu: 16 requests: cpu: 176 memory: 1800G alibabacloud.com/ppu: 16 terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /mnt #NAS挂载路径 name: data - mountPath: /dev/shm name: cache-volume dnsPolicy: ClusterFirst restartPolicy: Always schedulerName: default-scheduler securityContext: {} terminationGracePeriodSeconds: 30 volumes: - name: data persistentVolumeClaim: claimName: nas-pvc-fs #nas-pvc-fs为通过NAS创建的存储声明 - name: cache-volume emptyDir: medium: Memory sizeLimit: 500G通过YAML部署Deployment。
kubectl --kubeconfig config apply -f llm-test.yaml创建成功后,通过以下命令查看Pod是否启动成功。
Pod为Running状态即为启动成功。
kubectl --kubeconfig config get podsPod启动成功后,可以通过
kubectl logs查看vLLM服务是否启动成功。kubectl --kubeconfig config logs llm-test-68xxxxx9r5tf
步骤二:创建服务
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择网络 > 服务。
点击创建,使用以下配置创建
llm-svc服务,将服务关联到上一步中创建的工作负载,完成后点击确定。服务关联:
app: llm-test端口映射:
名称:
serving服务端口:
8000容器端口:
8000协议:
TCP
返回服务列表,查看已创建的
llm-svc服务。
步骤三:大模型推理测试
以Qwen2.5-7B-Instruct模型为例,测试vLLM推理对话功能操作如下:
# 将IP改为上一步中创建的服务的外部IP地址 # model为模型在pod中的路径 curl http://IP:8000/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "/mnt/Qwen2.5-7B-Instruct", "messages": [ {"role": "system", "content": "你是个友善的AI助手。"}, {"role": "user", "content": "介绍一下深度学习。"} ]}'
资源清理
使用kubectl命令行工具或直接在阿里云ACS控制台执行资源清理操作。
登录容器计算服务控制台,分别在无状态、存储类和存储声明页面删除对应资源。
使用
kubectl命令行工具删除deployment、StorageClass、PVC。#删除deployment的同时会自动清理pod kubectl --kubeconfig config delete deployment llm-test #删除存储类 kubectl --kubeconfig config delete pvc nas-pvc-fs #删除存储声明 kubectl --kubeconfig config delete sc alicloud-nas-fs