
PPU简介
PPU一款为AI应用加速的芯片,具有高易用性,适用于各类大模型和传统模型的训练及推理场景。它支持主流AI框架和深度学习模型,提供编译器和多种开源加速库,同时配备完整的工具链,帮助您快速、低成本地迁移应用。PPU自研的软件栈可广泛应用于AI训练和推理,通过PPU SDK能够最大化产品算力,显著提升计算效率。
核心竞争力
|
全自研
|
高性价比
|
高易用性
|
应用场景
|
多模态大模型训练推理 完全兼容Qwen、LLaMa等常见开源大模型,Megatron、DeepSpeed、vllm等常见训练、推理框架无缝迁移。 |
自动驾驶模型训练 已验证兼容50+自动驾驶常见模型,在感知模型、预测模型、端到端模型等多种模型架构下均有50%以上的单机性能优势。 |
产品规格
|
产品 |
真武810E |
|
最大热设计功耗 TDP(W) |
400 |
|
外形规格 |
OAM |
|
总线接口 |
PCIe 5.0x16 |
|
存储形态 |
HBM2e |
|
存储容量 (GB) |
96 |
|
存储带宽(GB/s) |
2765 |
|
片间互联形态 |
ICN |
|
片间互联带宽(GB/s) |
700 |
软件栈
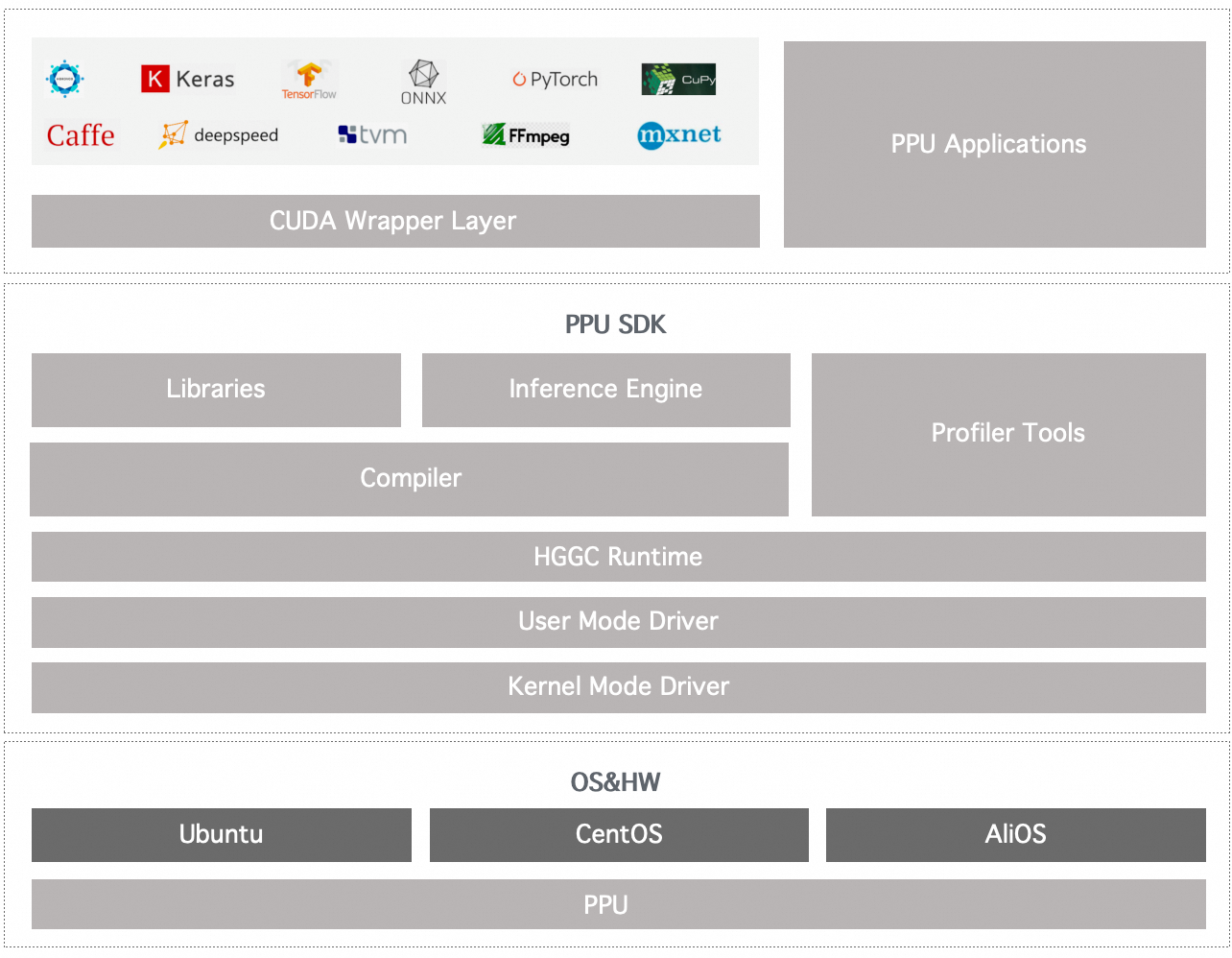
PPU软件生态系统设计由应用层、转换适配层和PPU SDK层组成的软件栈。用户既可以对新开发的应用程序直接调用PPU SDK,也可以通过转换适配层使现有的应用程序间接调用PPU SDK。
-
提供面向DL领域的通用GPU编程API和各类加速库,重点支持CudaRT、CuDNN、CuBlas、NCCL、CuSolver、NVML、NVTX、FFMPEG、Nvcuvid、Nvjpegd等同名接口Lib,用户可以将现有应用进行替换,或使用转换层进行适配。
-
提供完整的工具链,快速实现业务部署和调优,如:设备监控查询工具PPU-SMI、应用程序性能分析套件Asight System、应用程序kernel分析工具Asight Compute、程序调试工具GDB For Kernel Debugger。
使用途径
|
途径 |
使用方式 |
适合场景 |
|
在ACS中创建灵骏资源集群并选择PPU专属镜像,然后使用ACS控制台或命令行工具kubectl等方式,提交模型训练或模型部署任务。 |
适用于了解容器技术,使用控制台或命令行工具kubectl等方式,进行容器化部署模型训练和推理任务的用户,其具有强大的容器管理能力,包括自动化的应用部署、扩展和管理功能。 |
|
|
在PAI中创建灵骏专有资源组并选择PPU专属镜像,然后使用PAI-DSW、PAI-DLC、PAI-EAS开发、训练、部署模型。 |
适用于需要一站式AI开发平台的用户,可以使用云端IDE PAI-DSW开发模型代码,使用PAI-DLC分布式训练模型,使用PAI-EAS将模型部署为在线服务,其具有灵活易用、弹性伸缩、版本管理等特点。 |