
ACS集群LLM/CV模型训练使用指导和最佳实践
本文介绍如何在ACS集群中使用ACS AI容器镜像创建工作负载,快速构建LLM/CV模型训练环境。
前提条件
已创建ACS集群。具体操作,请参见创建ACS集群。
已创建带有模型文件的NAS存储卷。
ACS AI容器镜像介绍
ACS AI容器镜像是提供给使用GPU实例的ACS集群的专用容器镜像,为运行在ACS集群上的人工智能相关的工作负载提供一个可靠、灵活、可移植、高效和可管理的环境。
ACS AI容器镜像预先安装了主流开源AI框架、算子库、网络库、分布式训练框架、Python虚拟机和工具等,并集成了阿里自研的多项优化技术,加速模型开发人员高效开启训练流程。
按照如下示例获取ACS AI容器镜像,以便您在ACS实例上配置工作负载时使用。
ACS AI容器镜像为灵骏产品提供的标准镜像,您可以免费使用。关于最新的镜像发布信息,请参见ACS容器镜像版本发布记录。
建议您使用VPC方式加速拉取AI容器镜像,减少镜像拉取的时间。
镜像名称 | 镜像Tag | 公网镜像地址 | VPC镜像地址 | 说明 |
training-xpu-pytorch | 25.03 | egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-xpu-pytorch:25.03 |
|
|
您可以基于此镜像增量开发自己的镜像,镜像可以存放在您的ACR仓库中,可以提升镜像拉取速度(需额外付费)。
关于镜像内置的核心AI库清单,请参见最新的镜像组件列表。
创建训练/Finetune任务
单机多卡训练任务
以下内容以自定义资源类型的工作负载的创建为例说明(使用其他方式创建任务是类似的)。
登录容器计算服务控制台,在左侧导航栏选择集群列表。
在集群列表页面,单击目标集群名称,然后在左侧导航栏,选择工作负载 > 自定义资源。
在资源定义(CustomResourceDefinition)页签中,点击使用YAML创建资源,使用以下YAML创建资源。
下面是一个模型训练的示例编排,通过该编排模板,即可快速创建一个属于模型训练的任务。
apiVersion: v1 kind: Pod metadata: name: cv-demo #名字可以/需要修改 labels: alibabacloud.com/compute-class: gpu-hpn alibabacloud.com/hpn-type: "rdma" spec: imagePullSecrets: - name: acs-image-secret #需要和上述创建Secret的name一致 containers: - name: ssd-demo image: egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-xpu-pytorch:24.09 env: - name: USE_PRETRAIN value: "true" - name: PRETRAIN_PATH value: "/opt/ljperf/benchmark/models/mmdetection/model_configs/ssd/" command: ["/bin/bash"] args: ["-c", "ljperf benchmark --model cv/ssd"] resources: limits: #结合上述运行模型的command args按需调整 cpu: 90 memory: 500G alibabacloud.com/ppu: 16 requests: #结合上述运行模型的command args按需调整 cpu: 90 memory: 500G alibabacloud.com/ppu: 16 volumeMounts: # 需要提前准备好挂载的网络存储(PV/NAS等)和Model/Data文件,以下挂载的目录需要按需调整 - name: dshm mountPath: /dev/shm - name: data mountPath: /opt/ljperf/benchmark/models/mmdetection/model_configs/ssd/ subPath: shared/public/model_configs/ssd - name: data mountPath: /opt/ljperf/benchmark/models/mmdetection/data/coco subPath: shared/public/dataset/coco volumes: - emptyDir: medium: Memory sizeLimit: 1000Gi name: dshm - name: data persistentVolumeClaim: claimName: cnp单击创建后会提示部署状态信息。
镜像中不包含模型训练所需的Checkpoint文件和数据集,需要通过volume方式自行挂载到pod中。示例YAML文件中的mountPath分别为:
/opt/ljperf/benchmark/models/mmdetection/model_configs/ssd/是ssd模型Checkpoint文件,模型Checkpoint文件可以从model_configs.tar.gz下载。/opt/ljperf/benchmark/models/mmdetection/data/coco是ssd模型训练时所需使用的数据集,数据集文件可以从datasets.tar.gz下载。
args中包含了启动模型训练的命令,核心为
ljperf benchmark --model cv/ssd。通过该命令可以快速启动镜像中已内置好的benchmark模型,cv类模型目前在24.09镜像中支持 cv/ssd、cv/mask_rcnn、cv/fcn、cv/mask2former等几种。关于ljperf的详细使用帮助,请参见容器镜像中内置Demo应用ljperf用法说明。
多机多卡训练任务
多机多卡任务需要调度编排支持,如果您有自己的编排调度方案,可以在训练任务中部署自己的方案。
如果您对编排调度无特殊要求,可以部署社区的Kubeflow方案。关于部署社区版Kubeflow(每个新建集群都需要部署一次)的内容,请参见在ACS上部署社区版Kubeflow。
确保平台已经支持Kubeflow PytorchJob CRD之后,您可以使用单机多卡训练任务中的方式,创建PyTorchJob多机训练任务。
示例YAML文件如下。
apiVersion: "kubeflow.org/v1" kind: PyTorchJob metadata: name: pytorchjob-llama3-8b namespace: llm-training labels: alibabacloud.com/compute-class: gpu-hpn alibabacloud.com/hpn-type: "rdma" spec: pytorchReplicaSpecs: Master: replicas: 1 restartPolicy: Never template: metadata: labels: alibabacloud.com/compute-class: gpu-hpn alibabacloud.com/hpn-type: "rdma" annotations: sidecar.istio.io/inject: "false" spec: imagePullSecrets: - name: acs-image-secret #需要和上述创建Secret的name一致 containers: - name: pytorch imagePullPolicy: Always image: egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-xpu-pytorch:24.09 securityContext: privileged: true capabilities: add: - IPC_LOCK command: ["/bin/bash"] args: ["-c", "ljperf benchmark --model deepspeed/llama3-8b"] resources: limits: alibabacloud.com/ppu: 16 cpu: "90" memory: 1000Gi ephemeral-storage: 1000Gi volumeMounts: - mountPath: /dev/shm name: dshm env: - name: KUBERNETES_POD_NAME valueFrom: fieldRef: apiVersion: v1 fieldPath: metadata.name hostNetwork: true hostIPC: true dnsPolicy: ClusterFirstWithHostNet volumes: - emptyDir: medium: Memory sizeLimit: 1000Gi name: dshm Worker: replicas: 1 restartPolicy: Never template: metadata: labels: alibabacloud.com/compute-class: gpu-hpn alibabacloud.com/hpn-type: "rdma" annotations: sidecar.istio.io/inject: "false" spec: imagePullSecrets: - name: acs-image-secret #需要和上述创建Secret的name一致 containers: - name: pytorch imagePullPolicy: Always image: egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-xpu-pytorch:24.09 securityContext: privileged: true capabilities: add: - IPC_LOCK command: ["/bin/bash"] args: ["-c", "ljperf benchmark --model deepspeed/llama3-8b"] resources: limits: alibabacloud.com/ppu: 16 cpu: "90" memory: 1000Gi ephemeral-storage: 1000Gi volumeMounts: - mountPath: /dev/shm name: dshm env: - name: KUBERNETES_POD_NAME valueFrom: fieldRef: apiVersion: v1 fieldPath: metadata.name hostNetwork: true hostIPC: true dnsPolicy: ClusterFirstWithHostNet volumes: - emptyDir: medium: Memory sizeLimit: 1000Gi name: dshm查看成功提交的PyTorchJob任务。
kubectl get PyTorchJob -n llm-training预期输出中,
STATE为Running表示任务正在运行中,Succeeded表示任务已完成。
查看运行结果
运行成功后,在ACS控制台上通过工作负载 > 容器组 > 日志查看训练任务的运行日志。
FAQ
ACS集群中利用存储卷配置模型Checkpoint和Dataset
在NAS文件系统控制台,购买文件存储系统NAS。
购买选择VPC时需要选择和ACS集群同一VPC,否则无法正常连接NAS。
在容器计算服务控制台,创建存储声明PVC。
在集群管理页面的左侧导航栏,选择。
选择上文中训练任务所在的命名空间,点击创建。
选择NAS、填写名称、使用挂载点域名,然后点击创建。
名称:与上文任务YAML中claimName一致,挂载点域名选择所购买的NAS的域名。
挂载点域名:点击购买的NAS,选择挂载使用,复制挂载点地址。
将模型Checkpoint和dataset拷贝至NAS中,NAS中的文件路径应与YAML的subPath相同。
购买同一VPC下的ECS。
将NAS文件系统挂载到ECS实例上。具体操作,请参见一键挂载NFS协议文件系统。
以挂载在/mnt目录为例,将模型Checkpoint和数据集拷贝到NAS中即ECS的/mnt目录下。
Checkpoint:/mnt/shared/public/model_configs/ssd
数据集: /mnt/shared/public/dataset/coco
容器镜像中内置Demo应用ljperf用法说明
提交任务时需要根据选择的xPU的种类调整待测模型,避免OOM等低级问题。
容器镜像中已经安装好了标准的transformers、accelerate、diffusers、opencv、vllm等AI核心库,熟悉的用户可以以标准方式直接使用。
便于演示、快速上手或者集群性能测试目的,镜像中内置了一个自研应用
ljperf(仅为测试用,生产场景需客户自备特定模型),默认情况下只需要添加位置参数benchmark,并且指定一个待测的模型--model cv/ssd,即形如ljperf benchmark --model cv/ssd的最简命令。此外,您还可以按需指定其他训练参数,具体参数可以参考以下示例帮助信息。说明以下示例帮助信息为24.10版本,新版本会支持更多模型,请以镜像实际情况为准。
usage: ljperf [-h] [--model {deepspeed/llama3-8b, deepspeed/llama2-7b, deepspeed/llama2-70b, deepspeed/qwen2-7b, deepspeed/qwen-7b, deepspeed/qwen-72b, megatron/llama3-8b, megatron/llama2-70b, megatron/mixtral-8*7b, megatron/mixtral-8*22b, megatron/mixtral-310b, cv/mask_rcnn, cv/ssd, cv/fcn, cv/yolo, cv/open-clip, cv/bevformer}] [--mbs MBS] [--seqlen SEQLEN] [--iters ITERS] [--dataset DATASET] [--overlap-comm] [--grad-ckpt] [--ga GA] [--zero ZERO] [--zeropp ZEROPP] [--zero-offload] [--use-pretrain] [--attn-impl {flash_attention_2,eager}] [--bf16] [--fp16] [--tc] [--enable-lora] [--sp SP] [--tprof] [--tprof-skip TORCH_PROFILE_SKIP] [--tprof-warmup TORCH_PROFILE_WARMUP] [--tprof-wait TORCH_PROFILE_WAIT] [--tprof-active TORCH_PROFILE_ACTIVE] [--tprof-dir TORCH_PROFILE_OUTPUT_DIR] [--fsdp] [--gbs GBS] [--tp TP] [--pp PP] [--ep EP] [--cp CP] [--te] [--do] [--ac {full,selective}] {benchmark} lingjun perf toolkit command tool for AI performance testing, diagnose and profiling. positional arguments: {benchmark} Specify ljperf action, you can choose from action benchmark or healthcheck. options: -h, --help show this help message and exit Group benchmark: --model {deepspeed/llama3-8b, deepspeed/llama2-7b, deepspeed/llama2-70b, deepspeed/qwen2-7b, deepspeed/qwen7b, deepspeed/qwen-72b, megatron/llama3-8b, megatron/llama2-70b, megatron/mixtral-8*7b, megatron/mixtral-8*22b, megatron/mixtral-310b, cv/mask_rcnn, cv/ssd, cv/fcn, cv/yolo, cv/open-clip, cv/bevformer} --mbs MBS --seqlen SEQLEN --iters ITERS --dataset DATASET --overlap-comm --grad-ckpt --ga GA --zero ZERO --zeropp ZEROPP --zero-offload --use-pretrain --attn-impl {flash_attention_2,eager} --bf16 --fp16 --tc --enable-lora --sp SP --tprof --tprof-skip TORCH_PROFILE_SKIP --tprof-warmup TORCH_PROFILE_WARMUP --tprof-wait TORCH_PROFILE_WAIT --tprof-active TORCH_PROFILE_ACTIVE --tprof-dir TORCH_PROFILE_OUTPUT_DIR --fsdp --gbs GBS --tp TP --pp PP --ep EP --cp CP --te --do --ac {full,selective}
镜像拉取时间长的解法建议
目前提供的镜像如
egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-xpu-pytorch:24.12使用的是公网地址,相比使用专有网络(VPC)地址,拉取镜像会消耗更长时间。建议您在ACR控制台创建一个ACR实例,拉取和推送training-xpu-pytorch公网镜像,后续就可以通过专有网络(VPC)地址高速拉取镜像。您可以基于此镜像进行增量开发,并将生成的镜像存储在您的ACR仓库中,从而提高镜像的拉取速度。
关于ACR的费用信息,请参见计费说明。
最佳实践YAML
DeepSpeed Llama3-70B
主要信息 | 说明 |
配置 | mbs 2 / gradient_accumulation_steps 1 / seqlen 4096 / zero 3 / flash-attn 2 / bf16 |
主要包版本 | |
模型 | |
数据集 | oss://lingjun-public/deepspeed/WuDaoCorpus2.0_selected_proc-llama/ |
代码 | 镜像目录/opt/ljperf/benchmark/models/transformers-model |
执行命令(torchrun) | |
YAML示例 | |
Megatron Mixtral-8x7B
主要信息 | 说明 |
配置 | mbs 1 / gradient_accumulation_steps 64 / seqlen 2048 / tp 1 / pp 4 / expert-parallel 8 / context-parallel 1 / flash-attn2 / transformer-engine / recompute-activations(selective) / bf16 (获得稳定throughput需要跑200 iteration以上) |
依赖包版本信息 | |
代码 | 镜像目录/opt/ljperf/benchmark/models/megatron-model |
数据集 | oss://lingjun-public/megatron/enwiki-llama2/ |
执行命令(torchrun) | |
YAML示例 | |
StableDiffusion XL
主要信息 | 说明 |
依赖包版本信息 | |
代码 | |
模型和数据集 | oss://lingjun-public/sdxl (外网可访问)下载 |
执行命令(torchrun) | |
YAML示例 | |
BEVformer
主要信息 | 说明 |
依赖包版本信息 | |
模型Checkpoint文件 | https://lingjun-public.oss-cn-wulanchabu.aliyuncs.com/cv-models/model_configs/bevformer/ |
数据集 | https://lingjun-public.oss-cn-wulanchabu.aliyuncs.com/cv-models(子目录为/datasets/nuscenes/) |
代码仓库地址 | |
参数配置文件 | BEVFormer/projects/configs/bevformer/bevformer_base.py |
下载完成后按照图中目录结构,放置文件
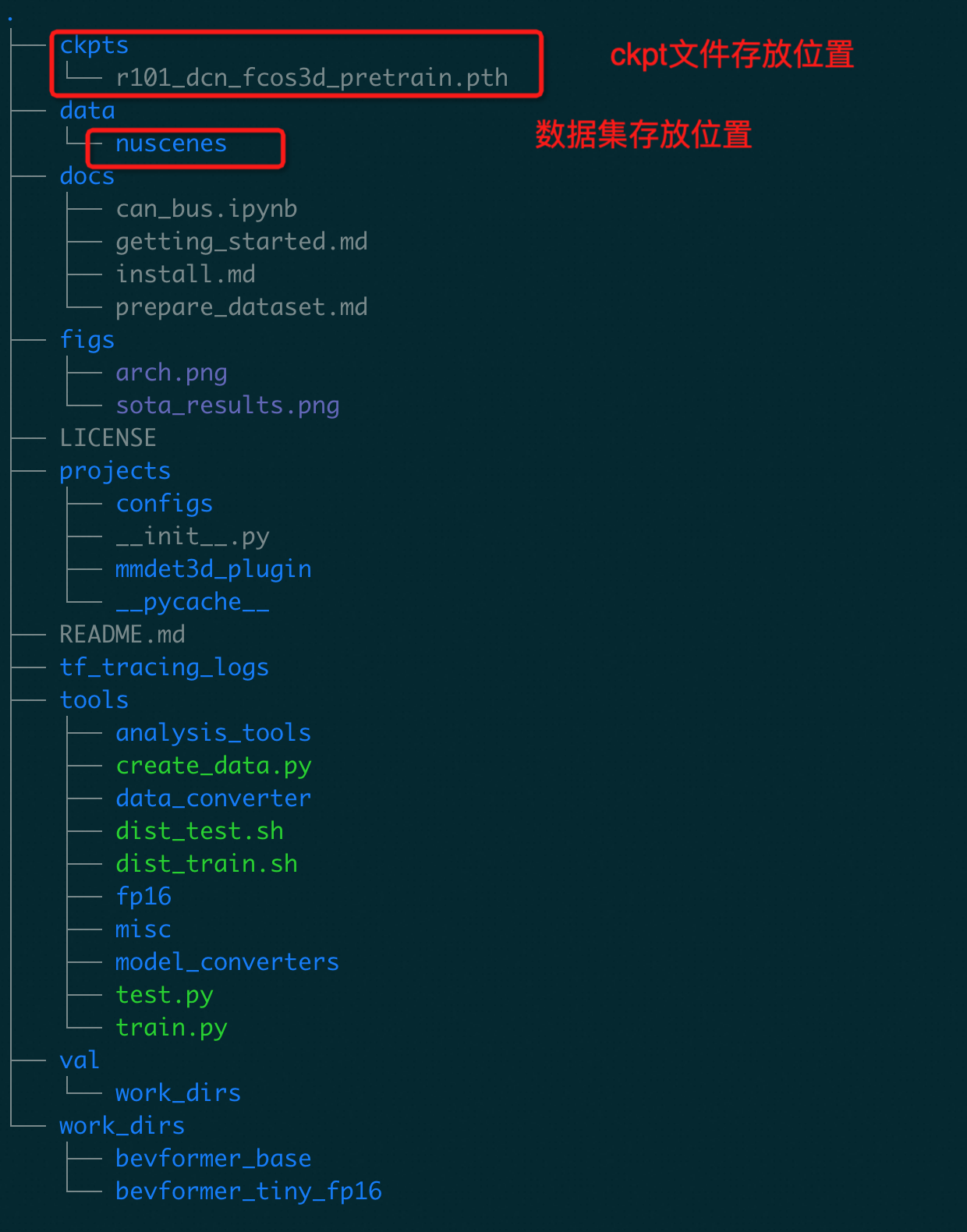
放置好数据集和模型权重文件后,将整个BEVFormer目录挂载到运行容器中,以
/mnt/BEVFormer路径为例。apiVersion: v1 kind: Pod metadata: name: bevformer-demo #名字可以/需要修改 labels: alibabacloud.com/compute-class: gpu-hpn alibabacloud.com/hpn-type: "rdma" spec: imagePullSecrets: - name: acs-image-secret #需要和上述创建Secret的name一致 containers: - name: bevformer-demo image: egslingjun-registry.cn-wulanchabu.cr.aliyuncs.com/egslingjun/training-xpu-pytorch:24.10-nightly-20241030 command: ["/bin/bash"] args: ["-c", "cd /mnt/BEVFormer;bash tools/dist_train.sh ./projects/configs/bevformer/bevformer_base.py 16"] resources: limits: #结合上述运行模型的command args按需调整 cpu: 90 memory: 500G alibabacloud.com/ppu: 16 requests: #结合上述运行模型的command args按需调整 cpu: 90 memory: 500G alibabacloud.com/ppu: 16 volumeMounts: # 需要提前准备好挂载的网络存储(PV/NAS等)和Model/Data文件,以下挂载的目录需要按需调整 - name: dshm mountPath: /dev/shm - name: data mountPath: /mnt/BEVFormer subPath: shared/public/BEVFormer volumes: - emptyDir: medium: Memory sizeLimit: 1000Gi name: dshm - name: data persistentVolumeClaim: claimName: lingjun-ai查看运行成功日志。
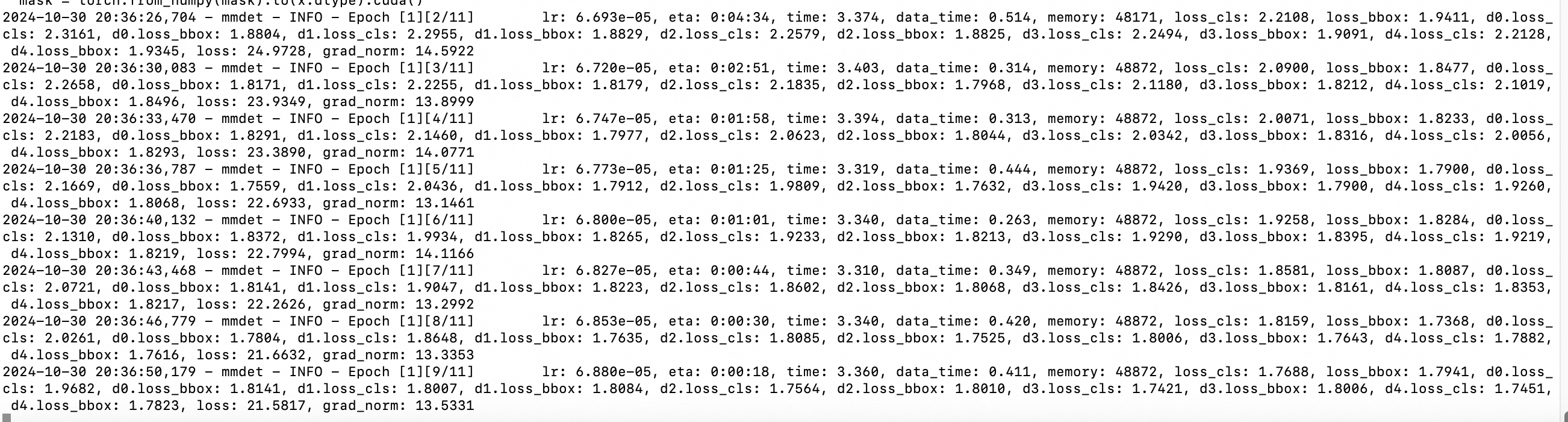
SparseDrive
主要信息 | 说明 |
依赖包版本信息 | |
代码地址 | |
参数配置参考 | https://github.com/swc-17/SparseDrive/blob/main/projects/configs/sparsedrive_small_stage2.py |
数据集 | nuscenes-v1.0-mini |
执行命令 | |
YAML示例 | |
查看运行成功日志。

已知问题
以下为真武810E在使用过程中相对于Nvidia GPU默认使用方式、生态支持等方面的差异说明。
需要获取源码或者Patch的情况
以下这些模块需要额外打PPU A910E提供的补丁,建议您使用镜像已经内置好的版本,如果使用非镜像配套的版本,自行安装的版本可能无法正常工作。
onnxruntime
vllm
xformers
CuPy
GroupGemm
transformer engine
cutlass
TransformerEngine
TE Fused Attention UT test_fused_attn.py存在FAIL CASE。
FAILED test_fused_attn.py::test_dot_product_attention[False-None-True-False-base_1_0-model_configs0-dtype0] - RuntimeError: /root/TransformerEngine/transformer_engine/common/fused_attn/fused_attn_f16_max512_seqlen.cu:836 in function fused_attn_max_512_fwd_impl: CUDNN_BAC... FAILED test_fused_attn.py::test_dot_product_attention[False-None-True-False-base_1_0-model_configs0-dtype1] - RuntimeError: /root/TransformerEngine/transformer_engine/common/fused_attn/fused_attn_f16_max512_seqlen.cu:836 in function fused_attn_max_512_fwd_impl: CUDNN_BAC... FAILED test_fused_attn.py::test_dot_product_attention[False-None-True-False-base_1_1-model_configs0-dtype0] - RuntimeError: /root/TransformerEngine/transformer_engine/common/fused_attn/fused_attn_f16_max512_seqlen.cu:836 in function fused_attn_max_512_fwd_impl: CUDNN_BAC... FAILED test_fused_attn.py::test_dot_product_attention[False-None-True-False-base_1_1-model_configs0-dtype1] - RuntimeError: /root/TransformerEngine/transformer_engine/common/fused_attn/fused_attn_f16_max512_seqlen.cu:836 in function fused_attn_max_512_fwd_impl: CUDNN_BAC... ....FAIL说明:xPU兼容的cudnn目前不支持fma功能,因此xPU兼容的TE无法走FusedAttention (cuDNN) ,可以优先使用FlashAttention:
export NVTE_FLASH_ATTN=1 && export NVTE_FUSED_ATTN=0;。TE numeric UT存在FAIL CASE。
FAILED test_numerics.py::test_gpt_checkpointing[126m-1-dtype0] - RuntimeError: /root/TransformerEngine/transformer_engine/common/gemm/cublaslt_gemm.cu:207 in function cublas_gemm: cuBLAS Error: an ... FAILED test_numerics.py::test_gpt_checkpointing[126m-1-dtype1] - RuntimeError: /root/TransformerEngine/transformer_engine/common/gemm/cublaslt_gemm.cu:207 in function cublas_gemm: cuBLAS Error: an ... FAILED test_numerics.py::test_gpt_checkpointing[126m-1-dtype2] - RuntimeError: /root/TransformerEngine/transformer_engine/common/gemm/cublaslt_gemm.cu:207 in function cublas_gemm: cuBLAS Error: an ... FAILED test_numerics.py::test_gpt_checkpointing[126m-2-dtype0] - RuntimeError: /root/TransformerEngine/transformer_engine/common/gemm/cublaslt_gemm.cu:207 in function cublas_gemm: cuBLAS Error: an ... .....FAIL说明:case对应的输入类型组合目前暂不支持。
FAILED test_numerics.py::test_gpt_full_activation_recompute[True-False-False-126m-1-dtype1] - AssertionError: Output mismatches in: FAILED test_numerics.py::test_gpt_full_activation_recompute[True-False-False-126m-1-dtype2] - AssertionError: Output mismatches in: FAILED test_numerics.py::test_gpt_full_activation_recompute[True-False-False-126m-2-dtype1] - AssertionError: Output mismatches in: FAILED test_numerics.py::test_gpt_full_activation_recompute[True-False-False-126m-2-dtype2] - AssertionError: Output mismatches in: ......FAIL说明:对应用例在A100上同样出现Output mismatch。
bitsandbytes
test | pass/total(xPU) | pass rate | 失败原因 | pass/total (GPU) |
test_functional.py | 142/632 | 23% | 由于算子库cutlass gemm不支持INT n,n的问题,抛出CUDA error: unspecified launch fail | 620/632(精度差异,略微超出阈值范围) |
test_autograd.py | 2176/2240 | 97.1% | 精度问题,算子库未支持trans是n&n, n&t, t&t的int8 gemm | 2239/2240(精度差异,略微超出阈值范围) |
Cupy
PPU版本CuPy没有经过完整的CI测试,主要通过3个场景测试:
用于Nvidia DeepLearning Examples TF1 NCF模型 。
vLLM 0.3.3。
API UT。
import cupy as cp
cp.cuda.Device(0).use()
x_gpu_0 = cp.array([1, 2, 3])
l2_gpu = cp.linalg.norm(x_gpu)
sorted_test = cp.sort(x_gpu_0)
sort_indices = cp.argsort(x_gpu_0)
x_gpu_1 = cp.asarray(x_gpu_0)
cp.repeat(x_gpu_1, 2)
cp.logical_not(x_gpu_0)
cp.random.permutation(2)
cp.random.randint(0, high=3, size=4)
cp.get_default_memory_pool().free_all_blocks()Cupy可能会调用CuDNN、CuBlas、CuRand等多个CUDA计算库中xPU当前不支持的API接口,存在报错风险。
ONNX runtime
UT Fail Case
test_parity_huggingface_gpt_attention.py
Attention (unfused backend) 在TF32精度下存在acblas gemm带来的精度误差,超出阈值;FP32/FP16精度达标。
test_flash_attn.py::TestGQA::test_gqa_no_past
test_gqa_no_past 会先后测试 efficient backend 和 FA backend,连跑时受到前面case影响导致测试FA时结果出错;若调换两者顺序或单独测试FA结果正确(FA本身暂未发现精度问题)。
onnxruntime_test_distributed.py::TestDistributed::test_slice_rs_axis1
PCCL暂不支持
mixing different streams within a group call。
SparseAttention只有TRT cubin kernel实现,xPU无法执行。
flash attention暂未替换为xPU flash attention,可能有潜在的性能影响。
Grouped_Gemm
permute和sinkhorn两个OP暂时不支持,后续会增加支持。