
使用专家系统分析报告
1. 专家系统
专家系统是Asight Systems中的一个智能分析系统,可以帮助识别常见的性能问题。专家系统分析报告中事件,并提出优化建议,以便能够更有效地进行性能优化。
1.1 从命令行端使用专家系统
可以通过执行asys analyze子命令,使用asys专家系统对asysrep文件进行分析,生成一系列分析报告。asys analyze子命令的使用方式为:asys analyze [option] <file.asysrep>。
1.1.1 指定报告分析类型
asys analyze支持多种报告分析类型,通过asys analyze --help-rules ALL可查看分析类型的详细说明。
通过--rule选项可指定报告分析类型,该选项可以多次指定,也可以使用逗号分隔列表来指定多个分析类型。如果未指定报告分析类型,将使用默认报告分析类型来生成报告。
例如:指定使用ppu_gaps和ppu_time_util报告分析类型生成报告:
asys analyze --rule ppu_gaps,ppu_time_util report.asysrep1.1.2 指定报告输出格式
asys analyze支持通过--format选项,指定统计报告输出格式。通过asys analyze --help-formats ALL可查看支持的输出格式和帮助信息。
column:输出到终端的默认格式,按照列表方式打印,易于阅读的输出格式,支持选项列举如下:
设置单位:设置输出数据的单位和精度。
csv:输出到文件的默认格式,按照CSV表格格式打印,易于导出表格以后续处理,支持选项列举如下:
设置单位:设置输出数据的单位和精度。
xlsx:按照xlsx格式输出电子表格,支持在Excel、WPS、LibOffice等办公软件打开,统计结果更加易读,支持选项列举如下:
设置单位:设置输出数据的单位和精度。
设置单位选项允许指定显示指定种类数据时使用的单位,支持的种类和单位选项列举如下:
ratio:比例 / 百分比类型数据,支持的单位:%或者.1%:精确到小数点后一位。.2%:精确到小数点后两位。.3%:精确到小数点后三位。
例如指定按照列表方式输出,ratio种类数据精确到小数点后三位:
asys analyze -r ppu_time_util --format column:ratio=.3% report.asysrepTips:若报告输出列较多,column输出格式将默认隐藏部分列,可通过指定报告类型的column选项控制显示的列。
1.1.3 指定报告输出类型
通过--output选项可指定报告输出的输出类型,目前有3种输出类型: 打印到console控制台,输出到文件,或者输出到命令。不指定默认打印到控制台。
通过--output %指定输出类型%表示输出到控制台console,例如:
asys analyze --output % --rule ppu_gaps report.asysrep通过--output指定输出类型为输出到asysrep报告所在目录,则asys将会根据asysrep报告文件名、指定的报告分析类型和输出格式生成报告输出的文件名,输出文件名格式为:<report_name>_<rule_name>.<format>。例如指定--output在报告所在目录生成report.asysrep的ppu_gaps分析类型的分析报告,本地报告文件名称为report_ppu_gaps.csv:
asys analyze --output . --rule ppu_gaps report.asysrep通过--output @post_command指定输出结果通过post_command进行二次处理,分析报告的内容将通过管道传输到给定的命令。例如:通过grep 1142417匹配结果包含关键字1142417的结果:
asys analyze --output "@grep 1142417" --rule ppu_gaps report.asysrep1.1.4 指定报告输出的列
asys analyze支持为每种报告类型指定输出的列,在输出统计结果时,仅会输出指定列的统计结果。在指定报告类型时,使用column选项指定列的名称,多个列通过/分割,例如:
asys analyze -r "ppu_gaps:column=Duration/Device ID" -r "ppu_time_util:column=In-Use/Device ID" report.asysrep统计报告
ppu_gaps仅输出Duration和Device ID列。统计报告
ppu_time_util仅输出In-Use和Device ID列。
1.1.5 指定统计时间范围
可通过--filter-time选项指定统计的时间范围,时间格式为开始时间/结束时间,单位为纳秒,时间指从采集开始的偏移时间,其中开始时间或者结束时间可以省略一种。例如指定统计从第10秒到第20秒的跟踪数据:
asys analyze --filter-time 10000000000/20000000000 --rule ppu_gaps report.asysrep可通过--filter-hgtx选项通过HGTX标注指定统计的时间范围,当--filter-hgtx选项被指定时,将忽略--filter-time选项。
使用--filter-hgtx选项可指定匹配的HGTX range的名称、domain和匹配索引,格式为range_name@domain/index,若匹配的HGTX range不存在domain,则@domain可省略,否则@domain需要指定。
默认asys将使用匹配的第一个HGTX range作为统计的时间范围,此时/index部分可省略,若需要指定匹配索引,则通过/index指定,索引从0开始。
例如:使用名称为self_attention的HGTX range指定统计时间范围,无domain,使用首个匹配的HGTX range的时间范围。
asys analyze --filter-hgtx self_attention --rule ppu_gaps report.asysrep例如:使用名称为pcclGroupEnd的HGTX range指定统计时间范围,domain为NCCL,使用第9个匹配的HGTX range的时间范围(索引为8)。
asys analyze --filter-hgtx "pcclGroupEnd@NCCL/8" --rule ppu_gaps report.asysrepTips:
asys analyze输出的时间戳信息可能由于
--rule选项不同而不同。若希望统一时间戳信息,可指定选项--ts-normalize true使能转换时间戳为UTC时间。asys analyze支持通过选项
--ts-shift手动调整时间戳偏移值,此选项可以和--ts-normalize配合使用。
1.2 专家系统规则
1.2.1 PPU长时间空闲分析
分析和汇总asysrep报告中PPU长时间空闲的时间段(PPU bubble),并按照空闲时长排序降序输出。
对于各个PPU设备,对每个进程进行检查,从该设备上的第一个PPU活动开始到该设备上的最后一个PPU活动结束的时间范围内,查找满足设置门限的空闲时间。
依赖的asys采集选项:--trace hggc
分析规则
当PPU没有下述活动时,视为PPU空闲:
执行kernel
执行memcpy / memset
执行video编解码
按照每进程、每PPU级别,统计PPU空闲时间段。若空闲时间段大于参数gap设置的门限,则此空闲时间段汇入统计结果。
统计结果按照空闲时长排序降序输出。
ppu_gaps表格列说明如下:
Row# : Row number of the PPU gap
Duration [ns] : Duration of the PPU gap
Start [ns] : Start time of the PPU gap
PID : Process identifier
Device ID : PPU device identifier命令行使用方法
asys analyze --rule ppu_gaps report.asysrep通过--rule选定ppu_gaps时,可通过拼接多个:option的方式指定分析的相关参数,可通过asys analyze --help-rules ppu_gaps查看具体帮助信息,支持的选项举例如下:
rows=<limit>:限制输出的PPU长时间空闲结果的条数。gap=<threshold>:设置长时间空闲的时间门限,单位为毫秒。
例如:分析PPU长时间空闲,空闲时间门限为20ms,输出空闲时长最长的前10条结果:
asys analyze --rule ppu_gaps:rows=10:gap=20 report.asysrep报告结果示例如下:
Row#,Duration,Start,PID,Device ID,
1,1232895501,126020393150,1142419,6,
2,1219910832,126016153086,1142417,4,
3,1219804936,126017799911,1142416,3,
...GUI使用指南
规则设置(Settings)
Maximum number of results:限制输出的PPU长时间空闲结果的条数上限,默认值为50。
Minimum duration of PPU gaps in ms:设置长时间空闲的时间门限,单位为
毫秒,默认值为500。
表格右键菜单功能
支持在Timeline View中高亮或缩放至所选的范围。
饼图统计:对每个进程/设备的长时间空闲的持续时间进行汇总。通过饼图可以查看哪个进程/设备的bubble更多。
1.2.2 PPU时间利用率分析
分析和汇总asysrep报告中PPU时间层面的利用率,并按照时间利用率升序输出。对于各个PPU设备,对每个进程进行基于Range Mode的检查。将该时间范围划分为相等的块(chunks),并计算每个块的PPU时间利用率。
如果选择了“PPU Active Time Range”模式,则统计的时间范围从该设备上的第一个 PPU 操作开始,到该设备上的最后一个 PPU 操作结束。如果选择了“Filtered Time Range”范围模式,则时间范围与指定的过滤时间范围相同。请注意,利用率是指“时间”利用率,而不是“资源”利用率。因此,一个简单的memcpy的“利用率”与调用所有资源的复杂kernel相同。如果多个操作在同一块中同时运行,则它们的利用率将加起来为100%。展示的结果为利用率百分比小于设定阈值的块。如果多个连续块的利用率较低,则多个块将合并展示为一条结果,并加权平均计算利用率,因此得到的各条结果的时间长度可能不同。
依赖的asys采集选项:--trace hggc
分析规则
当PPU有下述活动时,视为PPU繁忙:
执行kernel
执行memcpy / memset
执行video编解码
按照每进程、每PPU级别,计算PPU整体有活动的时间:从第一个活动开始到最后一个活动结束。
整体有活动的时间按照参数chunks分为等长的时间段,对每个时间段计算PPU在本时间段的时间利用率:繁忙时间/时间段长度。
时间利用率低于参数threshold的时间段将汇入统计结果。若多个相邻的时间段利用率均低于参数threshold,这些时间段将被合并计算利用率作为统计结果输出。
统计结果按照时间利用率升序输出。
Tips:
时间上重叠的kernel / memcpy等活动,重叠部分的时间不会重复计算,每个时间段的时间利用率不会高于100%。
可通过GUI端通过在timeline界面圈选一段时间范围,右键
Filter and zoom in指定过滤的时间范围。可通过调整
chunks和threshold参数计算整个报告的PPU时间利用率,例如:asys analyze --rule ppu_time_util:threshold=100:chunks=1:range-mode=full report.asysrep。
ppu_time_util表格列说明如下:
Row# : Row number of the chunk
In-Use [%] : Percentage of time the PPU is being used
Duration [ns] : Duration of the chunk
Start [ns] : Start time of the chunk
PID : Process identifier
Device ID : PPU device identifier命令行使用方法
asys analyze --rule ppu_time_util report.asysrep通过--rule选定ppu_time_util时,可通过拼接多个:option的方式指定分析的相关参数,可通过asys analyze --help-rules ppu_time_util查看具体帮助信息,支持的选项举例如下:
rows=<limit>:限制输出的PPU低利用率时间段的结果的条数。threshold=<percent>:设置PPU繁忙占比的百分比门限。chunks=<number>:PPU整体有活动的时间段的切分个数。range-mode=<mode>:统计时间范围的选择模式,支持active和full模式:active:默认模式,时间范围从第一个PPU活动开始,到最后一个PPU活动结束截止。full:时间范围选取为用户指定的统计时间范围,若没有指定统计时间范围,则统计报告整体的时间范围。
compute-pipe=<index_list>:参与统计的Compute Pipe列表,多个Pipe Index之间通过/分割,若不指定,默认统计所有的Compute Pipe,可用于分析MPS模式使能时的时间利用率。merge-process-id:合并进程统计结果,按照PPU设备级别统计时间利用率。
例如:分析PPU时间利用率,利用率门限为60%,时间等分为80段,输出利用率最低的前20条结果:
asys analyze --rule ppu_time_util:rows=20:threshold=60:chunks=80 report.asysrep报告结果示例如下:
Row#,In-Use,Duration,Start,PID,Device ID,
1,0.000000,12411,124667294244,1142418,5,
2,0.000000,7648,124667369358,1142419,6,
3,0.000000,7648,124667378918,1142419,6,
4,2.425268,7092,124667285970,1142418,5,
5,4.258319,7092,124667278287,1142418,5,
...GUI使用指南
规则设置(Settings)
Maximum number of results:限制输出的PPU低利用率时间段的结果的条数上限,默认值为50。
MPS Compute Pipe Index:设置参与统计的MPS Compute Pipe Index,默认为All(统计所有的Compute Pipe)。
Minimum percentage of PPU utilization:设置PPU繁忙占比的百分比门限,输出PPU时间利用率低于该值的区间,默认值为50。
Number of equal-duration chunks:PPU整体有活动的时间段的切分个数,默认值为100。
Time Range Mode:设置统计时间范围的模式:
PPU Active Time Range:默认模式,时间范围从第一个PPU活动开始,到最后一个PPU活动结束截止。Filtered Time Range:时间范围选取为用户指定的统计时间范围,若没有指定统计时间范围,则统计报告整体的时间范围。
表格右键菜单功能
支持在Timeline View中高亮或缩放至所选的范围。
饼图统计:对每个进程/设备的低利用率的持续时间进行汇总。通过饼图可以查看哪个进程/设备的利用率更低。
2. 统计系统
统计系统是Asight Systems中的一项重要功能,它对报告中数据的进行统计,可以通过这些统计结果全面了解程序的性能。
2.1 从GUI端使用统计系统
与Function View类似,可以通过下方tab切换到统计系统页面,如下所示:
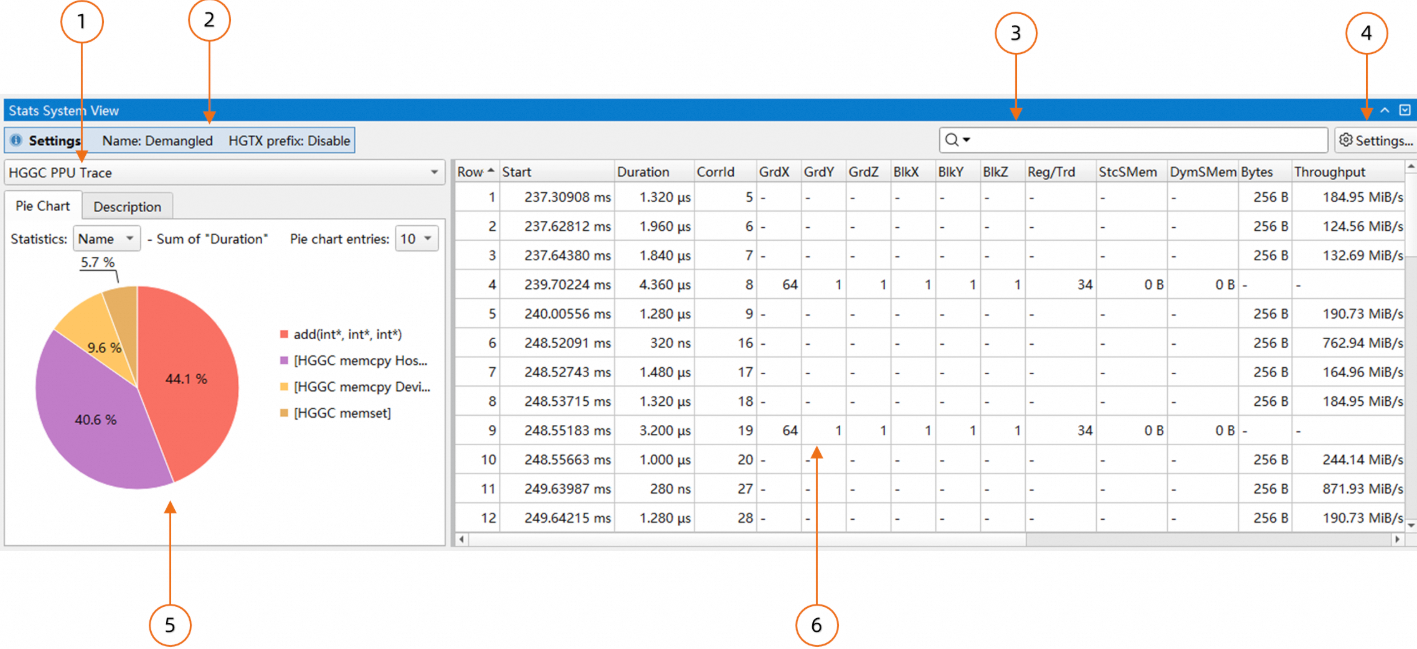
规则列表,可以在此选择统计规则。
当前生效侧参数配置,鼠标悬停时会显示参数的详细信息。
搜索框,支持搜索和过滤两种模式。
规则参数配置对话框,可以在此改变当前统计规则的配置。
统计结果的饼图,以及相关的优化建议,可以通过顶部tab切换。
统计结果表格,显示当前规则的分析结果,可以通过右键菜单导出分析结果。
2.1.1 设置统计区间
可以Timeline View的filter功能设置一个时间区间,统计系统只会对该时间区间内的事件进行统计。在Timeline View中按住鼠标左键拖动,在选定的区间内打开右键菜单,点击“Filter and Zoom in”,即可设置统计区间。
2.1.2 跳转至Timeline View
对于部分规则(目前包括Trace和Detail类的规则),支持从表格中跳转至Timeline View,可以通过在表格中打开右键菜单选择跳转的方式。
2.1.3 统计结果的饼图
规则的统计结果除了以表格的形式展示外,统计系统还支持以饼图的形式展示结果:
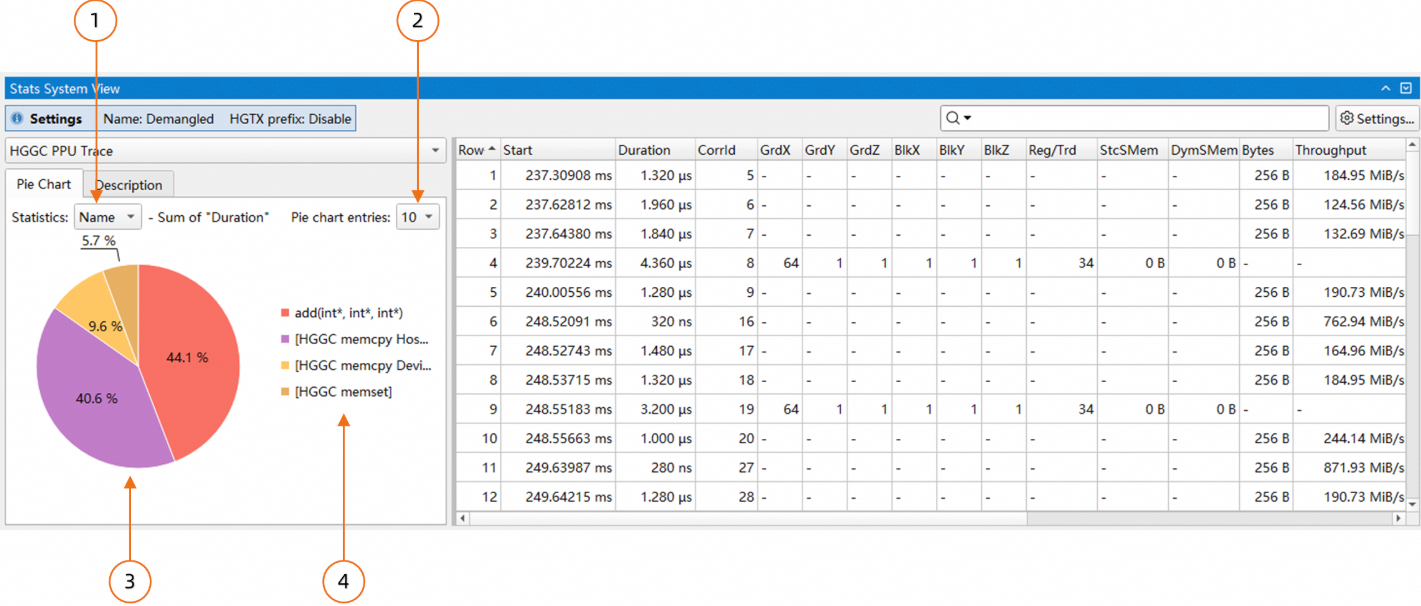
上图中:
当前饼图实现的是以"Name"为key,将右侧的表格的每一行进行分类,每一类将"Duration"这一列的值进行累加,最终计算"Duration"的时间占比显示在饼图中。这里的key可以通过组合框进行选择。
设置显示的扇形数量。
饼图,每个扇形显示的百分比是每"Name"的"Duration"占整体"Duration"的时间占比。
图例,上图中显示的"Name",并按"Duration"的降序排列。
饼图中的扇形支持点击,点击后表格只会显示对应key的行。如下图所示:
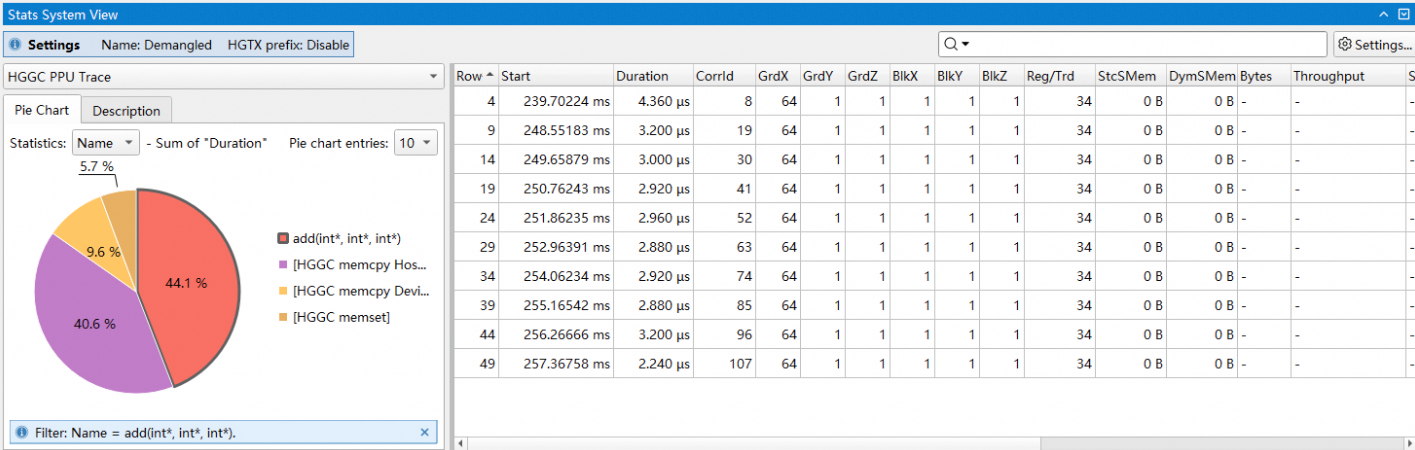
上图中,点击了name为add(int*,int*,int*)的扇形,因此在右侧表格中只会显示该名字的项,其他项被隐藏。再次点击扇形或饼图空白部分表格会复位。
2.1.4 通过选中行来统计列和
统计系统中,部分规则支持通过选中行来统计列和,并将结果显示在表头中,如下图所示:
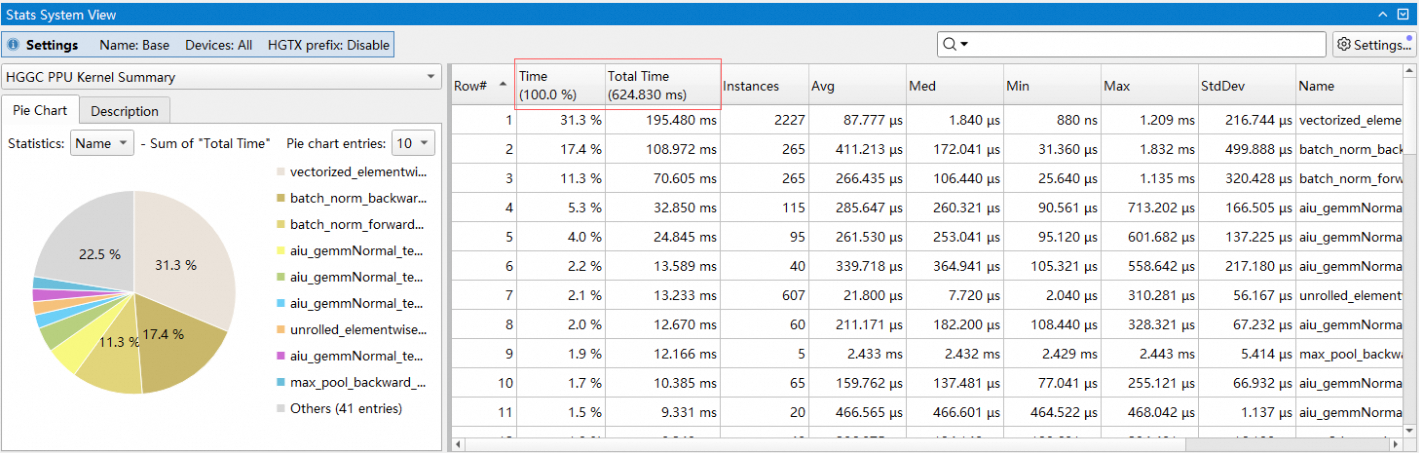
上图中选中了前三行,这三行的Time和Total Time列的值会累加显示在表头中。
2.2 从命令行端使用统计系统
在命令行端,可以通过执行asys stats命令,对指定报告进行统计分析,提供高效的统计功能和跟踪导出功能,分析结果支持输出到控制台、文件或命令管道,方便用户对数据进行查阅和二次处理。部分统计和分析功能也可通过Asight Systems GUI查看结果。
stats子命令的使用方式为:
asys stats [option] <file.asysrep>可以在使用asys profile命令采集跟踪时,通过指定--stats true选项,在生成报告后输出报告统计结果,输出结果和使用asys stats report.asysrep类似。例如:
asys profile --stats true python test_linear.py--stats true:采集结束输出报告统计结果
2.2.1 指定统计报告类型
asys stats支持多种统计报告类型,通过asys stats --help-reports ALL可查看统计报告类型的详细说明。
通过--report选项可指定统计报告类型,该选项可以多次指定,也可以使用逗号分隔列表来指定多个统计报告类型。若未指定统计报告类型,将使用默认统计报告类型来生成报告。
例如:指定使用hggc_ppu_kern_sum和device_memory_usage_summary统计报告类型生成报告:
asys stats --report hggc_ppu_kern_sum,device_memory_usage_summary report.asysrep--report选项指定的报告类型可能包含配置选项,配置选项的逗号,和冒号:需要使用反斜线\逃脱,若在bash等命令行环境中使用,配置选项的取值请使用"包裹,例如:
asys stats --report ppu_op_sum:range-include="seqlen_q\:1\,is_fixed_seqs\:0\,head_dim\:128/data_type\:fp8\,groups\:1\,m\:925":range-exclude="em\:0\,gpu\:1" report.asysrep2.2.2 指定报告输出格式
asys stats支持多种输出格式,通过asys stats --help-formats ALL可查看支持的输出格式和帮助信息。
通过--format 选项可指定统计报告输出格式。该选项可以多次指定,也可以使用逗号分隔列表来指定多个统计报告输出格式。
若未指定报告输出格式,输出到终端默认为column格式,输出到文件默认为csv格式
column:按照列表方式打印,易于阅读的输出格式,支持选项列举如下:
设置单位:设置输出数据的单位和精度
csv:按照csv表格格式打印,易于导出表格以后续处理,支持选项列举如下:
设置单位:设置输出数据的单位和精度
xlsx:按照xlsx格式输出电子表格,支持在Excel、WPS、LibOffice等办公软件打开,统计结果更加易读,支持选项列举如下:
设置单位:设置输出数据的单位和精度
设置单位选项允许指定显示指定种类数据时使用的单位,支持的种类和单位选项列举如下:
ratio:比例 / 百分比类型数据,支持的单位:%或者.1%:精确到小数点后一位.2%:精确到小数点后两位.3%:精确到小数点后三位
例如指定按照列表方式输出,ratio种类数据精确到小数点后三位:
asys stats -r hgtx_ppu_proj_sum --format column:ratio=.3% report.asysrepTips:
若报告输出列较多,column输出格式将默认隐藏部分列,可通过指定统计报告类型的
column选项控制显示的列。xlsx格式不支持输出到终端,若指定输出到终端,将按照
column格式输出。
2.2.3 指定报告输出类型
asys stats支持多种报告输出类型,包括输出到console控制台,输出到文件和输出到命令。
通过--output选项可指定报告输出的输出类型,该选项可以多次指定,也可以使用逗号分隔列表来指定多个报告输出类型。不指定时,默认输出到控制台。
如果指定的输出名称是
"%",则分析结果会显示在控制台上。如果输出名称以
"@"开头,表示输出目标是一个要执行的命令。除此之外,任何其他输出名称都被认为是
文件输出的目录和文件名前缀的组合,格式为<output_dir>/<prefix>。前缀可以为空,路径最后一个/之前的路径被认为是输出目录。
输出类型对照表如下:
输出类型 | 参数写法 | 说明 |
控制台输出 |
| 将分析结果直接打印到控制台(stdout),不生成文件。 |
默认文件输出 |
| 输出到asysrep报告所在目录,使用默认基础文件名,格式为:
|
自定义文件输出 |
| 输出到
|
命令管道输出 |
| 将分析结果通过管道传给指定命令的标准输入,命令的 stdout/stderr 仍输出到控制台。 |
使用--output %可以将分析结果直接输出到控制台console,例如:
asys stats --output % --report hgtx_sum report.asysrep使用--output .可以将分析结果输出到asysrep报告所在目录则asys将会根据asysrep报告文件名、指定的统计报告类型和输出格式生成报告输出的文件名,
例如:指定--output .在报告所在目录生成report.asysrep的hggc_api_sum类型的统计报告,本地报告文件名称为report_hggc_api_sum.csv:
asys stats --output . --report hggc_api_sum report.asysrep例如:指定--output /test/mytest,在目录/test 生成report.asysrep的hggc_api_sum类型的统计报告,本地报告文件名称为mytest_hggc_api_sum.csv:
asys stats --output /test/mytest --report hggc_api_sum report.asysrep使用--output @post_command可以将统计报告的输出结果通过指定的命令行post_command进行二次处理,统计结果将通过管道传输到给定的命令。
例如:使用grep 1142417筛选结果包含关键字1142417的结果:
asys stats --output "@grep 1142417" --report device_memory_usage_summary report.asysrep2.2.4 指定报告输出的列
asys stats支持为每种统计报告类型指定输出的列,在输出统计结果时,仅会输出指定列的统计结果。在指定统计报告类型时,使用column选项指定列的名称,多个列通过/分割,例如:
asys stats -r "hggc_ppu_kern_sum:column=Time/Name" -r "hgtx_ppu_proj_sum:column=Range/Total Proj Time" report.asysrep统计报告
hggc_ppu_kern_sum仅输出Time和Name列。统计报告
hgtx_ppu_proj_sum仅输出Range和Total Proj Time列。
2.2.5 指定算子识别规则
asys stats的统计结果中包含PPU算子相关对比,通过内置的PPU算子识别规则识别报告中的算子并统计相关性能,可通过--ppu-op-config选项自定义算子识别规则,可指定正则表达式通过匹配HGTX range名称或者kernel名称识别指定算子类型,格式为算子类型=匹配类型:过滤规则,可多次通过--ppu-op-config选项创建多个算子识别规则,例如:
asys stats --ppu-op-config GEMM=kernel:gemv --ppu-op-config Pytorch=hgtx:aten report.asysrep--ppu-op-config GEMM=kernel:gemv:匹配kernel名称包含gemv关键字的kernel,分类到GEMM算子类型--ppu-op-config Pytorch=hgtx:aten:匹配HGTX range名称包含aten关键字,HGTX range关联的PPU活动分类到Pytorch算子类型
2.2.6 指定统计时间范围
可通过--filter-time选项指定统计的时间范围,时间格式为开始时间/结束时间,单位为纳秒,时间指从采集开始的偏移时间,其中开始时间或者结束时间可以省略一种。例如指定统计从第10秒到第20秒的跟踪数据:
asys stats --filter-time 10000000000/20000000000 --report device_memory_usage_summary report.asysrep可通过--filter-hgtx选项通过HGTX标注指定统计的时间范围,当--filter-hgtx选项被指定时,将忽略--filter-time选项。
使用--filter-hgtx选项可指定匹配的HGTX range的名称、domain和匹配索引,格式为range_name@domain/index,若匹配的HGTX range不存在domain,则@domain可省略,否则@domain需要指定。
默认asys将使用匹配的第一个HGTX range作为统计的时间范围,此时/index部分可省略,若需要指定匹配索引,则通过/index指定,索引从0开始。
例如:使用名称为self_attention的HGTX range指定统计时间范围,无domain,使用首个匹配的HGTX range的时间范围。
asys stats --filter-hgtx self_attention --report device_memory_usage_summary report.asysrep例如:使用名称为pcclGroupEnd的HGTX range指定统计时间范围,domain为NCCL,使用第9个匹配的HGTX range的时间范围(索引为8)。
asys stats --filter-hgtx "pcclGroupEnd@NCCL/8" --report device_memory_usage_summary report.asysrep2.2.7 参数匹配规则
专家系统的报告生成需要指定3个方面的参数:
1)报告类型(以及相关参数);
2)报告格式(以及相关参数);
3)输出类型(文件名、控制台或命令)。
这三个参数均可以多次指定,也可以使用逗号分隔列表来指定多个选项。
第一个报告会使用第一个指定的格式,并通过第一个指定的输出类型进行呈现;第二个报告则使用第二个格式,配合第二个输出,以此类推。
如果指定的报告数量多于格式或输出类型数量,那么会通过重复列表中最后一个指定的元素(或者默认值,如果未指定)来扩展格式和/或输出列表,从而使它们与报告的数量相匹配。
例如:
下面的命令将生成三个报告。其中 "hggc_api_sum" 报告将以CSV 格式输出到文件"report1_hggc_api_sum.csv"。另外两个报告 "osrt_sum" 和 "hgtx_sum" 将以 CSV 数据的形式输出到控制台。尽管指定了三个报告,但只指定了一个输出格式和两个输出类型。为了匹配报告数量,格式列表和输出列表都会通过重复最后一个元素来扩展到与报告列表数量一致。
asys stats --report hggc_api_sum --report osrt_sum --report hgtx_sum --format csv --output .,% report1.asysrepTips:
asys stats输出的时间戳信息可能由于
--report选项不同而不同。若希望统一时间戳信息,可指定选项--ts-normalize true使能转换时间戳为UTC时间。asys stats支持通过选项
--ts-shift手动调整时间戳偏移值,此选项可以和--ts-normalize配合使用。
2.3 统计系统规则
2.3.1 设备内存使用分组汇总
分析和汇总asysrep报告中多种数据种类的PPU设备内存使用记录,按照分组(如算子库、框架)统计内存使用量,输出各个分组的内存使用汇总和详细信息。
依赖的asys采集选项:--hggc-memory-usage device
统计规则
按照每进程、每PPU级别,汇总已申请且没有释放的PPU设备内存使用记录。
对于每个申请且没有释放的内存使用记录,根据内存申请时的调用栈信息(帧的排列顺序,每帧匹配的关键字),匹配分组规则。
内存使用记录可能匹配到多个分组,输出的分组信息将显示记录归属的所有分组,通过/间隔。
汇总每种分组组合的内存使用量,结果按照内存使用量汇总降序排列。
device_memory_usage_detail表格列说明如下:
Row# : Row number of the device memory usage
PID : Process identifier
Device ID : PPU device identifier
Group List : Memory usage belonged group list, splited by '/'
Time [ns] : Memory usage timestamp
TID : Thread identifier
Context ID : Context identifier
Memory : Memory identifier
Size [bytes] : Memory usage size
Access Flag : Memory access flag
Event ID : Memory usage event identifierdevice_memory_usage_summary表格列说明如下:
Row# : Row number of the device memory usage
PID : Process identifier
Device ID : PPU device identifier
Group List : Memory usage belonged group list, splited by '/'
Memory Usage [bytes] : Device memory usage命令行使用方法
可通过-r <rule>:usage-mode=<mode>选项指定数据种类
device_memory_usage_detail 规则支持两种数据种类:
'all':支持导出申请和释放的内存跟踪。
'unreleased':支持导出泄漏的内存跟踪(默认值)。
device_memory_usage_summary 规则支持四种数据种类:
'alloc-count': 申请的内存次数汇总。
'alloc-size': 申请的内存量汇总。
'unreleased-count': 泄漏的内存次数汇总。
'unreleased-size': 泄漏的内存量汇总(默认值)。
可通过--callstack-group-config选项添加分组规则,可通过:match-first-group选项指定分组策略按第一个匹配组(默认匹配所有组)。
通过--report指定分组统计报告,举例如下:
asys stats -r device_memory_usage_summary:usage-mode=unreleased-szie:match-first-group \
--callstack-group-config "acompute=(libacblas|libacdnn)" \
--callstack-group-config "launch_kernel=libtorch/LaunchKernel" \
--callstack-group-config "loss=loss.py" \
report.asysrep-r device_memory_usage_summary:指定设备内存使用汇总报告。:usage-mode=unreleased-size:指定泄漏的内存量汇总。:match-first-group:指定只归属于第一个匹配的组。--callstack-group-config "acompute=(libacblas|libacdnn)":创建分组名称
acompute。匹配的正则表达式
(libacblas|libacdnn):匹配调用栈包含libacblas或者libacdnn关键字的内存使用。
--callstack-group-config "launch_kernel=libtorch/LaunchKernel":创建分组名称
launch_kernel。匹配的正则表达式
libtorch/LaunchKernel:匹配调用栈层级关系:父函数所在帧包含关键字libtorch,且子函数所在帧包含关键字LaunchKernel的内存使用。匹配的父、子函数所在的调用栈帧之间允许存在未匹配的调用栈帧。
--callstack-group-config "loss=loss.py":创建分组名称
loss。匹配的正则表达式
loss.py:匹配调用栈包含loss.py关键字的内存使用。匹配的调用栈支持python调用栈。
分组的统计结果输出示例如下,按照CSV格式输出,可通过--output指定输出到csv文件等处理。
PID,Device ID,Group List,Memory Usage,
1873,0,launch_kernel,213174,
1873,0,others,48674898730,
1873,0,acompute,1610624066,
1873,0,loss,28591报告内容提供了分组
acompute、launch_kernel、loss的已申请且未释放的内存汇总,单位字节。不归属于用户指定组的内存使用,汇总到缺省的
others分组。
设备内存使用分组统计功能提供下述两种报告类型,可通过--report指定单个或者多个报告:
device_memory_usage_summary:输出每进程、每设备、每分组的已申请且未释放的内存汇总。device_memory_usage_detail:输出每笔申请且未释放的内存使用记录,以及所属的分组。
具体设备内存使用分组统计功能的描述信息,可通过 --help-reports选项查询,包含功能描述,输出格式说明等,例如执行asys stats --help-report device_memory_usage_summary,输出结果示例如下:
root@eb4c64fd3401:~# asys stats --help-report device_memory_usage_summary
device_memory_usage_summary -- Device Memory Usage Summary
Options:
match-first-group
Optional argument. When used with --callstack-group-config:
If given, only matching the first callstack group.
Default is matching all callstack group.
usage-mode=<mode>
Possible values are 'alloc-size', 'unreleased-size', 'alloc-count' or 'unreleased-count'.
Specify the memory usage mode.
If 'alloc-size', statistic overall allocated device memory usage.
If 'unreleased-size', statistic allocated but not freed device memory usage.
If 'alloc-count', statistic overall allocated device memory count.
If 'unreleased-count', statistic allocated but not freed device memory count.
Default is 'unreleased-size'.
Use --filter-time / --filter-hgtx to specify report time range.
Use --callstack-group-config to create report group configuration.
Try 'asys stats --help' for more information.
Output:
Row# : Row number of the device memory usage
PID : Process identifier
Device ID : PPU device identifier
Group List : Memory usage belonged group list, splited by '/'
Memory Usage [bytes] : Device memory usage
Group and statistic device memory usage of specified mode,
If 'alloc-size' mode, display allocated device memory usage summary.
If 'alloc-count' mode, display allocated device memory count summary.
If 'unreleased-size' mode, display allocated but not freed device memory usage summary.
If 'unreleased-count' mode, display allocated but not freed device memory count summary.当内存使用记录分组匹配策略按匹配多个分组时,报告输出的分组信息将显示记录归属的所有分组,通过/间隔,例如:
acompute/launch_kernel内存使用同时归属于
acompute和launch_kernel分组。若分组匹配策略按匹配第一组,则只归属于第一个满足条件的分组。
分组的排列顺序取决于命令行选项
--callstack-group-config的创建分组顺序。
通过选项--callstack-group-config可创建分组并通过正则表达式指定匹配规则,格式为group_name=frame_filters,其中frame_filters可指定多个帧的匹配正则表达式,格式为:frame_regex1/frame_regex2/...,帧匹配正则表达式之间通过/间隔,帧的排列方向为从父函数到子函数方向排列。分组的匹配规则说明如下:
帧的匹配方式为:若正则表达式可
部分匹配调用栈的库名称或者函数签名,则判定帧匹配。调用栈的匹配方式为:若调用栈中匹配的帧的层级关系,符合
frame_filters中指定的层级关系,则判定分组匹配。
选项--callstack-group-config举例如下,通过多次使用--callstack-group-config创建多个分组,每个分组指定匹配多个帧的规则:
--callstack-group-config "torch=libtorch" --callstack-group-config "acompute=(libacblas|libacdnn)" --callstack-group-config "buffer_init=_to_copy/empty_strided"Tips:
若没有通过
--callstack-group-config添加分组规则,将会使用默认内置的分组规则。当多个
--callstack-group-config创建的分组名称相同时,匹配任一分组规则的内存使用记录,将被归属到本分组。
GUI使用指南
规则设置(Settings)
Usage Mode:统计数据种类。Device Memory Usage Detail 规则支持两种数据种类:
Unreleased Alloc Trace:支持导出泄漏的内存跟踪(默认值)。
All Alloc and Free Trace:支持导出申请和释放的内存跟踪。
Device Memory Usage Summary 规则支持四种数据种类:
Unreleased Alloc Size: 泄漏的内存量汇总(默认值)。
Total Alloc Size: 申请的内存量汇总。
Unreleased Alloc Count: 泄漏的内存次数汇总。
Total Alloc Count: 申请的内存次数汇总。
Group Config:创建分组并通过正则表达式指定匹配规则。格式为group_name=frame_filters,其中frame_filters可指定一个或多个帧的匹配正则表达式,格式为:frame_regex1/frame_regex2/...,帧匹配正则表达式之间通过/间隔,帧的排列方向为从父函数到子函数方向排列。
Only match the first group in order:指定只归属于按从上至下顺序第一个匹配的组。默认为不勾选,即归属于所有匹配的组。
表格右键菜单功能
Device Memory Usage Detail 规则右键菜单支持在Timeline View中高亮或缩放至所选内存跟踪。
饼图统计:对每个group/进程/设备的未释放内存使用情况进行汇总。通过饼图可以查看每个group/进程/设备可能存在的内存泄露情况。
2.3.2 HGGC API汇总
汇总asysrep报告中HGGC API的耗时,按照API总耗时降序输出。
统计规则
按照每HGGC API名称级别进行统计,累加相同名称API的耗时时间,按照API总耗时降序输出。
hggc_api_sum表格列说明如下:
注意“Time”列是根据“Total Time”列的总和计算得出的,表示该函数占所有列出函数执行时间的百分比,而不是根据应用执行时间得到的百分比。
Row# : Row number of the HGGC API summary
Time [%] : Percentage of 'Total Time'
Total Time [ns] : Total time used by all executions of this function
Num Calls : Number of calls to this function
Avg [ns] : Average execution time of this function
Med [ns] : Median execution time of this function
Min [ns] : Smallest execution time of this function
Max [ns] : Largest execution time of this function
StdDev [ns] : Standard deviation of the time of this function
Name : Name of the function命令行使用方法
依赖的asys采集选项:--trace hggc
asys stats -r hggc_api_sum report.asysrep可通过asys stats --help-report hggc_api_sum查看具体帮助信息。
报告结果示例如下:
Row#,Time (%),Total Time (ns),Num Calls,Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),Name,
1,84.9,393100090,342,1149415,98746,3981,11001565,2011747,"hgMemcpyHtoDAsync_v2",
2,4.3,19851112,1297,15305,5351,2893,3860175,147778,"hgLaunchKernel",
3,2.9,13492044,1486,9079,2861,613,3707197,108998,"hgEventQuery",
4,2.9,13487638,1495,9021,6027,3191,222379,14733,"hggcLaunchKernel",
...GUI使用指南
规则设置(Settings)
该规则没有可以配置的设置选项。
饼图统计:对每个HGGC API的耗时进行汇总。
2.3.3 HGGC API跟踪
导出asysrep报告中的HGGC API跟踪数据,按照API执行时间升序输出。
依赖的asys采集选项:--trace hggc
统计规则
每HGGC API调用导出一行数据,按照API执行时间升序输出。
hggc_api_trace表格列说明如下:
Row# : Row number of the HGGC API trace
Start [ns] : Timestamp when API call was made
Duration [ns] : Length of API calls
Name : API function name
CorrID : Correlation used to map to other HGGC traces
Pid : Process ID that made the call
Tid : Thread ID that made the call
Thread Name : Name of thread that called API function命令行使用方法
asys stats -r hggc_api_trace report.asysrep可通过asys stats --help-report hggc_api_trace查看具体帮助信息。
报告结果示例如下:
Row#,Start (ns),Duration (ns),Name,CorrID,Pid,Tid,Thread Name,
1,41550,12737,"cudaProfilerStart",0,104699,104699,"python",
2,938476,28340,"cudaLaunchKernel",130170,104699,104699,"python",
3,999414,9382,"cudaLaunchKernel",130171,104699,104699,"python",
...GUI使用指南
规则设置(Settings)
该规则没有可以配置的设置选项。
表格右键菜单功能
支持在Timeline View中高亮或缩放至所选HGGC API。
饼图统计:对HGGC API的耗时进行汇总。支持切换至以进程级别对HGGC API耗时进行统计。
2.3.4 HGGC Kernel执行跟踪
导出asysrep报告中的HGGC kernel通过API launch启动到Kernel实际执行的跟踪数据,根据本kernel的launch API的起始时间升序输出。
统计规则
导出结果组织如下:每Kernel执行信息导出一行数据,根据本kernel的launch API的起始时间升序输出。
对于HGGC Graph等单个HGGC API关联多个Kernel的场景,每个Kernel导出一行数据。
Kernel Launch后的等待时间相关列(Queue Start / Queue Dur)的计算方式如下:
认为Kernel存在等待时间:Kernel实际执行开始时间 > 执行HGGC API结束时间。
等待时间计算:Kernel实际执行开始时间 - 执行HGGC API结束时间。
若Kernel在HGGC API执行结束前即开始执行,则Queue Start / Queue Dur列标记为无效值
-。
hggc_kern_exec_trace表格列说明如下:
Row# : Row number of the kernel trace
API Start [ns] : Start timestamp of HGGC API launch call
API Dur [ns] : Duration of HGGC API launch call
Queue Start [ns] : Start timestamp of queue wait time, if it exists
Queue Dur [ns] : Duration of queue wait time, if it exists
Kernel Start [ns] : Start timestamp of HGGC kernel
Kernel Dur [ns] : Duration of HGGC kernel
Total Dur [ns] : Duration from API start to kernel end
PID : Process ID that made kernel launch call
TID : Thread ID that made kernel launch call
DevId : HGGC Device ID that executed kernel (which PPU)
API Function : Name of HGGC API call used to launch kernel
GridXYZ : Grid dimensions for kernel launch call
BlockXYZ : Block dimensions for kernel launch call
Kernel Name : Name of HGGC Kernel命令行使用方法
依赖的asys采集选项:--trace hggc
asys stats -r hggc_kern_exec_trace report.asysrep可通过asys stats --help-report hggc_kern_exec_trace查看具体帮助信息,支持的选项列举如下:
base:导出kernel的短名称(仅函数名,不包含参数)。
mangled:导出kernel的mangled名称。
默认导出HGGC Kernel的名称为demangle之后的名称。
报告结果示例如下:
Row#,API Start (ns),API Dur (ns),Queue Start (ns),Queue Dur (ns),Kernel Start (ns),Kernel Dur (ns),Total Dur (ns),PID,TID,DevId,API Function,GridXYZ,BlockXYZ,Kernel Name,
1,504935256,20348911,525284167,21237024,526172280,357034784,378271808,631660,631660,0,"hggcLaunchKernel","2 1 1","512 1 1","pcclKernel_AllReduce_RING_LL_Sum_int8_t(pcclWorkElem)",
2,845563829,20332834,865896663,20934656,866498485,17898735,38833391,631660,631660,1,"hggcLaunchKernel","2 1 1","512 1 1","pcclKernel_AllReduce_RING_LL_Sum_int8_t(pcclWorkElem)",
3,884469702,40488,884510190,627234,885096936,16944871,17572105,631660,631660,0,"hggcLaunchKernel","2 1 1","512 1 1","pcclKernel_AllReduce_RING_LL_Sum_int8_t(pcclWorkElem)",
...GUI使用指南
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
表格右键菜单功能
支持在Timeline View中高亮或缩放至所选HGGC API。
支持在Timeline View中高亮或缩放至所选的Device Activity。
饼图统计:对所有kernel/进程/设备的kernel执行耗时进行汇总。
2.3.5 HGGC Kernel Grid Block汇总
统计asysrep报告中HGGC kernel grid block等信息,输出每kernel名称,每grid size,每block size的统计信息。
依赖的asys采集选项:--trace hgtx,hggc
统计规则
统计方式:
将
相同kernel名称且相同grid size且相同block size的Kernel执行信息进行汇总:Kernel执行时间,出现次数等。若使能
hgtx-name选项,kernel名称包含拼接的HGTX range名称。
统计结果组织如下:每kernel名称,每grid size,每block size导出一行数据,结果按照Total Time列降序输出。
hggc_ppu_kern_gb_sum表格列说明如下:
注意“Time”列是根据“Total Time”列的总和计算得出的,表示该kernel占所有列出kernels执行时间的百分比,而不是根据应用执行时间得到的百分比。
Row# : Row number of the kernel summary
Time [%] : Percentage of 'Total Time'
Total Time [ns] : Total time used by all executions of this kernel
Instances : Number of calls to this kernel
Avg [ns] : Average execution time of this kernel
Med [ns] : Median execution time of this kernel
Min [ns] : Smallest execution time of this kernel
Max [ns] : Largest execution time of this kernel
StdDev [ns] : Standard deviation of the time of this kernel
GridXYZ : Grid dimensions for kernel launch call
BlockXYZ : Block dimensions for kernel launch call
Name : Name of the kernel命令行使用方法
asys stats -r hggc_ppu_kern_gb_sum report.asysrep可通过asys stats --help-report hggc_ppu_kern_gb_sum查看具体帮助信息,支持的选项列举如下:
hgtx-name:kernel名字前通过
/拼接最接近kernel launch的HGTX range名称。base:使用kernel的短名称(仅函数名,不包含参数)进行统计和输出。
mangled:使用kernel的mangled名称进行统计和输出。
device:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。
报告结果示例如下:
Row#,Time (%),Total Time (ns),Instances,Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),GridXYZ,BlockXYZ,Name,
1,6.7,16337781,65,251350,260801,115520,277681,39767,"960 1 64","256 1 1","[prof_range]: iter 9/_ZN5acdnn4cuda9transposeILNS0_8LoopModeE0ELi32ELi8ELb0ELb0EN7",
2,3.1,7415267,20,370763,370601,366482,374162,1936,"2048 1 1","512 1 1","[prof_range]: iter 8/_ZL35batch_norm_bwd_single_vector_accessILb0EN5acdnn16identity",
3,3.0,7348069,20,367403,366401,361281,375921,3885,"122880 1 1","128 1 1","_ZN2at6native29vectorized_elementwise_kernelILi4EZZZNS0_12",GUI使用指南
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Add HGTX name as a prefix:使能名字前拼接最接近kernel launch的HGTX名称,通过
/间隔。默认不勾选。
饼图统计:对所有kernel的执行耗时进行汇总。
2.3.6 HGGC Kernel Grid Block跟踪
导出asysrep报告中的HGGC kernel执行的跟踪数据,以及grid size / block size等信息,根据执行的开始时间升序输出。
统计规则
导出结果组织如下:每Kernel执行信息导出一行数据,根据本kernel的执行起始时间升序输出。
hggc_ppu_kern_gb_trace表格列说明如下:
Row# : Row number of the kernel trace
Start [ns] : Timestamp of start time
Duration [ns] : Length of event
PID : Process identifier
Device ID : PPU device identifier
Context ID : Context identifier
Stream ID : Stream identifier
GridXYZ : Grid dimensions for kernel launch call
BlockXYZ : Block dimensions for kernel launch call
Name : Name of the kernel命令行使用方法
依赖的asys采集选项:--trace hgtx,hggc
asys stats -r hggc_ppu_kern_gb_trace report.asysrep可通过asys stats --help-report hggc_ppu_kern_gb_trace查看具体帮助信息,支持的选项列举如下:
hgtx-name:kernel名字前通过
/拼接最接近kernel launch的HGTX range名称。base:使用kernel的短名称(仅函数名,不包含参数)进行统计和输出。
mangled:使用kernel的mangled名称进行统计和输出。
报告结果示例如下:
Row#,Start (ns),Duration (ns),PID,Device ID,Context ID,Stream ID,GridXYZ,BlockXYZ,Name,
1,970508,6240,104699,0,1,1,"3 1 1","128 1 1","[prof_range]: iter 5/unrolled_elementwise_kernel",
2,1014188,44480,104699,0,1,1,"15360 1 1","128 1 1","[prof_range]: iter 5/unrolled_elementwise_kernel",
3,1158469,98480,104699,0,1,1,"960 1 64","256 1 1","[prof_range]: iter 5/transpose",
4,1257269,1880,104699,0,1,1,"1 1 32","256 1 1","[prof_range]: iter 5/transpose",GUI使用指南
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
Add HGTX name as a prefix:使能名字前拼接最接近kernel launch的HGTX名称,通过
/间隔。默认不勾选。
表格右键菜单功能
支持在Timeline View中高亮或缩放至所选的Device Activity。
饼图统计:对所有kernel/进程/设备的kernel执行耗时进行汇总。
2.3.7 HGGC PPU kernel汇总
汇总asysrep报告中HGGC kernel的耗时,按照HGGC kernel总耗时降序输出。
依赖的asys采集选项:--trace hggc
统计规则
按照每HGGC kernel名称进行统计,HGGC kernel名称取决于base / mangled选项是否设置,默认为demangle后kernel名称(包含函数参数列表),按照HGGC kernel总耗时降序输出。
hggc_ppu_kern_sum表格列说明如下:
注意“Time”列是根据“Total Time”列的总和计算得出的,表示该kernel占所有列出kernels执行时间的百分比,而不是根据应用执行时间得到的百分比。
Row# : Row number of the kernel summary
Time [%] : Percentage of 'Total Time'
Total Time [ns] : Total time used by all executions of this kernel
Instances : Number of calls to this kernel
Avg [ns] : Average execution time of this kernel
Med [ns] : Median execution time of this kernel
Min [ns] : Smallest execution time of this kernel
Max [ns] : Largest execution time of this kernel
StdDev [ns] : Standard deviation of the time of this kernel
Name : Name of the kernel命令行使用方法
asys stats -r hggc_ppu_kern_sum report.asysrep可通过asys stats --help-report hggc_ppu_kern_sum查看具体帮助信息,支持的选项列举如下:
rows=<limit>:限制输出结果的条数。
hgtx-name:kernel名字前通过/拼接最接近kernel launch的HGTX range名称。
base:使用kernel的短名称(仅函数名,不包含参数)进行统计和输出。
mangled:使用kernel的mangled名称进行统计和输出。
device:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。
报告结果示例如下:
Row#,Time (%),Total Time (ns),Instances,Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),Name,
1,81.6,826473830,28,29516922,17075623,16812011,357034784,64193935,"_Z39pcclKernel_AllReduce_RING_LL_Sum_int8_t12ncclWorkElem",
2,13.9,141273640,4,35318410,34326818,31248932,41371071,4288359,"_Z9deltaKernIaLi256EEvPvS0_mPd",
3,2.3,23263744,4,5815936,5866699,4743763,6786583,1087875,"_Z14InitDataKernelIaEvPT_mii",
4,2.2,22033972,4,5508493,5461251,4528464,6583005,1031905,"_Z20InitDataReduceKernelIaXadL_Z9ncclOpSumIaET_S1_S1_EEEvPS1_mmii",GUI使用指南
通过选中行来统计求列和
统计结果表格中的“Time”和“Total Time”列支持对选中行数据自动求和,统计结果显示在表头的第二行中。当没有行被选中时,对该列的所有行进行统计求和。
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
饼图统计:对所有kernel的kernel执行耗时进行汇总。
2.3.8 HGGC PPU跟踪
导出asysrep报告中的PPU执行HGGC Kernel / Memcpy / Memset的跟踪数据,根据执行的开始时间升序输出。
统计规则
导出结果组织如下:每Kernel / Memcpy / Memset执行信息导出一行数据,根据执行的开始时间升序输出。
由于导出结果的列包含Kernel / Memcpy / Memset的信息,对于导出的每一行数据,不适用的单元格被标记为无效值-。
hggc_ppu_trace表格列说明如下:
Row# : Row number of the PPU trace
Start [ns] : Timestamp of start time
Duration [ns] : Length of event
CorrId : Correlation ID
GrdX : Grid X values
GrdY : Grid Y values
GrdZ : Grid Z values
BlkX : Block X values
BlkY : Block Y values
BlkZ : Block Z values
Reg/Trd : Registers per thread
StcSMem [bytes] : Size of Static Shared Memory
DymSMem [bytes] : Size of Dynamic Shared Memory
Bytes [bytes] : Size of memory operation
Throughput [B/s] : Memory throughput
SrcMemKd : Memcpy source memory kind or memset memory kind
DstMemKd : Memcpy destination memory kind
Device : PPU device name and ID
Ctx : Context ID
Strm : Stream ID
Name : Trace event name命令行使用方法
依赖的asys采集选项:--trace hggc
asys stats -r hggc_ppu_trace report.asysrep可通过asys stats --help-report hggc_ppu_trace查看具体帮助信息,支持的选项列举如下:
hgtx-name:kernel名字前通过/拼接最接近kernel launch的HGTX range名称。
base:导出kernel的短名称(仅函数名,不包含参数)。
mangled:导出kernel的mangled名称。
默认导出HGGC Kernel的名称为demangle之后的名称。
报告结果示例如下,不适用的单元格被标记为无效值-:
Row#,Start (ns),Duration (ns),CorrId,GrdX,GrdY,GrdZ,BlkX,BlkY,BlkZ,Reg/Trd,StcSMem (bytes),DymSMem (bytes),Bytes (bytes),Throughput (B/s),SrcMemKd,DstMemKd,Device,Ctx,Strm,Name,
1,193282492,3009,5,"-","-","-","-","-","-","-","-","-",256,85078016,"Device","-","",1,1,"Memset",
2,193329286,1332,6,"-","-","-","-","-","-","-","-","-",256,192192000,"Pageable","Device","",1,1,"Memcpy HtoD (device)",
3,193380562,3415,7,"-","-","-","-","-","-","-","-","-",256,74963200,"Pageable","Device","",1,1,"Memcpy HtoD (device)",
4,231829389,4562345,8,64,1,1,1,1,1,32,0,0,"-","-","-","-","",1,1,"add(int*, int*, int*)",GUI使用指南
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
表格右键菜单功能
支持在Timeline View中高亮或缩放至所选kernel或内存操作。
饼图统计:对所有PPU事件/设备的执行耗时进行汇总。
2.3.9 HGTX关联kernel汇总
统计asysrep报告中HGTX range和关联的HGGC Kernel跟踪数据,输出每HGTX range名称,每Kernel名称的统计信息。
依赖的asys采集选项:--trace hgtx,hggc
统计规则
判断HGTX range和HGGC kernel的原则为:HGTX range持续时间范围内,相同线程的HGGC API触发的HGGC kernel,认为和此HGTX range关联。
统计方式:
对每进程、每线程,将相同
HGTX range名称且相同Kernel名称的Kernel执行信息进行汇总:Kernel执行时间、同名HGTX出现次数、同名Kernel出现次数等。
统计结果组织如下:每线程,每HGTX range名称,每HGGC kernel名称导出一行数据,若选项standalone使能,未关联HGTX range的HGGC kernel所在行的HGTX相关信息将标记为无效符号-。统计结果排序方式如下:
按照HGTX range名称、进程ID和线程ID升序排列。
相同线程相同HGTX range名称的Kernel按照Total Time列降序排列。
hgtx_kern_sum表格列说明如下:
Row# : Row number of the HGTX range kernel summary
HGTX Range : Name of the range
Style : Range style; Start/End or Push/Pop
PID : Process ID for this set of ranges and kernels
TID : Thread ID for this set of ranges and kernels
HGTX Inst : Number of HGTX range instances
Kern Inst : Number of HGGC kernel instances
Total Time [ns] : Total time used by all kernel instances of this range
Avg [ns] : Average execution time of this kernel
Med [ns] : Median execution time of this kernel
Min [ns] : Smallest execution time of this kernel
Max [ns] : Largest execution time of this kernel
StdDev [ns] : Standard deviation of the time of this kernel
Kernel Name : Name of the kernel命令行使用方法
asys stats -r hgtx_kern_sum report.asysrep可通过asys stats --help-report hgtx_kern_sum查看具体帮助信息,支持的选项列举如下:
base:导出kernel的短名称(仅函数名,不包含参数)。
mangled:导出kernel的mangled名称。
standalone:导出结果包含未关联任何HGTX range的HGGC kernel。
device:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。no-graph-mapping:导出结果不包含通过HGGC graph node映射的HGTX range信息。
range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。
报告结果示例如下:
Row#,HGTX Range,Style,PID,TID,HGTX Inst,Kern Inst,Total Time (ns),Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),Kernel Name,
1,"DoProcess","PushPop",3588556,3588556,2,2,8036961,4018480,4018480,3474616,4562345,543864,"add(int*, int*, int*)",
2,"Loop1","PushPop",3588556,3588556,1,1,4562345,4562345,4562345,4562345,4562345,0,"add(int*, int*, int*)",
3,"Loop2","PushPop",3588556,3588556,1,1,3474616,3474616,3474616,3474616,3474616,0,"add(int*, int*, int*)",
4,"profile","PushPop",3588556,3588556,1,2,8036961,4018480,4018480,3474616,4562345,543864,"add(int*, int*, int*)",GUI使用指南
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
Include Standalone Kernel:是否导出未匹配到任何HGTX的kernel信息,此类kernel导出的HGTX相关信息为非法值。默认不导出。
HGTX graph node mapping:是否投影HGGC graph capture阶段HGTX到PPU侧(通过在HGTX range范围内创建的HGGC graph node建立与PPU侧到关联)。默认值为“Yes”。
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
饼图统计:对所有HGTX Range/进程/kernel name的kernel执行耗时进行汇总。
2.3.10 HGTX关联kernel跟踪
建立关联HGTX和HGGC kernel的关联关系,并按照每HGTX range,每HGGC kernel级别导出关联关系。
统计规则
判断HGTX range和HGGC kernel的原则为:HGTX range持续时间范围内,相同线程的HGGC API触发的HGGC kernel,认为和此HGTX range关联。
导出结果组织如下:每HGTX range,每HGGC kernel导出一行数据,若选项standalone使能,未关联HGTX range的HGGC kernel行中的HGTX range信息将标记为无效符号-。
导出顺序:
HGGC kernel按照PPU开始执行时间升序排序。
相同HGGC kernel关联的各个HGTX range行按照HGTX range的开始时间升序排序。
hgtx_kern_trace表格列说明如下:
API Start和API duration列对于HGTX通过HGGC graph node关联kernel的场景输出为无效值。
Row# : Row number of the HGTX range kernel trace
Range name : Name of the HGTX range
Style : Range style; Start/End or Push/Pop
PID : Process identifier
TID : Thread identifier
Device ID : PPU device identifier
Context ID : Context identifier
Stream ID : Stream identifier
HGTX range ID : HGTX range identifier
Kernel exec ID : Kernel execution identifier
Kernel Start [ns] : Start timestamp of HGGC kernel
Kernel duration [ns] : Duration of HGGC kernel
API Start [ns] : Start timestamp of API call
API duration [ns] : Duration of API call
GridXYZ : Grid dimensions for kernel launch call
BlockXYZ : Block dimensions for kernel launch call
Correlation ID : Correlation identifier
Graph ID : HGGC graph identifier
Graph Node ID : HGGC graph node identifier
Kernel Name : Name of the kernel
Mangled Name : Mangled name of the kernel命令行使用方法
依赖的asys采集选项:--trace hgtx,hggc
asys stats -r hgtx_kern_trace report.asysrep可通过asys stats --help-report hgtx_kern_trace查看具体帮助信息,支持的选项列举如下:
base:导出kernel的短名称(仅函数名,不包含参数)。
mangled:导出kernel的mangled名称。
standalone:导出结果包含未关联任何HGTX range的HGGC kernel。
no-graph-mapping:导出结果不包含通过HGGC graph node映射的HGTX range信息。
range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。
报告结果示例如下:
Row#,Range Name,Style,PID,TID,Device ID,Context ID,Stream ID,HGTX Range ID,Kernel Exec ID,Kernel Start (ns),Kernel Duration (ns),API Start (ns),API Duration (ns),GridXYZ,BlockXYZ,Correlation ID,Graph ID,Graph Node ID,Kernel Name,Mangled Name,
1,"profile","PushPop",4010376,4010376,0,1,1,6,23,85579190,11136752,80913269,4025776,"64 1 1","1 1 1",8,"-","-","add(int*, int*, int*)","_Z3addPiS_S_",
2,"Loop1","PushPop",4010376,4010376,0,1,1,7,23,85579190,11136752,80913269,4025776,"64 1 1","1 1 1",8,"-","-","add(int*, int*, int*)","_Z3addPiS_S_",
3,"DoProcess","PushPop",4010376,4010376,0,1,1,8,23,85579190,11136752,80913269,4025776,"64 1 1","1 1 1",8,"-","-","add(int*, int*, int*)","_Z3addPiS_S_",
...GUI使用指南
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
HGTX graph node mapping:是否投影HGGC graph capture阶段HGTX到PPU侧(通过在HGTX range范围内创建的HGGC graph node建立与PPU侧到关联)。默认值为“Yes”。
Include Standalone Kernel:是否导出未匹配到任何HGTX的kernel信息,此类kernel导出的HGTX相关信息为非法值。默认不导出。
表格右键菜单功能
支持在Timeline View中高亮或缩放至所选的HGTX Range。
支持在Timeline View中高亮或缩放至所选的Device Activity。
饼图统计:对所有HGTX Range/kernel name/进程/设备的kernel执行耗时进行汇总。
2.3.11 HGTX向PPU投影汇总
将asysrep报告中的CPU侧HGTX range向PPU侧投影,输出HGTX range在PPU侧实际活跃时间的统计信息。
依赖的asys采集选项:--trace hgtx,hggc
统计规则
判断HGTX range和HGGC kernel的原则为:HGTX range持续时间范围内,相同线程的HGGC API触发的HGGC kernel,认为和此HGTX range关联。
CPU侧HGTX range向PPU侧投影的方式为:HGTX range在PPU侧的活跃时间,从本HGTX关联的最早的PPU活动开始,到最晚的PPU活动结束。PPU活动包括:HGGC Kernel / memcpy / memset 相关执行信息。
统计方式:
将
相同HGTX range且相同Style的HGTX range信息进行汇总,如CPU侧时长,PPU侧投影时长等。相同的HGTX range在PPU侧的总的活跃时间
Proj Active Time计算方式为:指定的时间点存在一个或者更多HGTX range投影,则记为活跃时间。如果多个HGTX range的投影在时间上重叠,重叠的部分不会被多次计入活跃时间。相同的HGTX range投影的PPU侧占比
In-Use计算方式为:Proj Active Time/PPU侧统计时间范围,其中PPU侧统计时间范围计算方式取决于range-mode选项。
统计结果组织如下:按照In-Use降序排列,按照HGTX Range名称升序排列。
hgtx_ppu_proj_sum表格列说明如下:
Row# : Row number of the HGTX PPU projection summary
Range : Name of the HGTX range
Style : Range style; Start/End or Push/Pop
In-Use [%] : Percentage of projected active time to time range
Proj Active Time [ns] : Total projected time excluding overlapping for this range name
Total Proj Time [ns] : Total projected time used by all instances of this range name
Total Range Time [ns] : Total original HGTX range time used by all instances of this range name
Range Instances : Number of instances of this range
Proj Avg [ns] : Average projected time for this range
Proj Med [ns] : Median projected time for this range
Proj Min [ns] : Minimum projected time for this range
Proj Max [ns] : Maximum projected time for this range
Proj StdDev [ns] : Standard deviation of projected times for this range
Total PPU Ops : Total number of PPU operations
Avg PPU Ops : Average number of PPU operations
Avg Range Lvl : Average range stack depth
Avg Num Child : Average number of children ranges命令行使用方法
asys stats -r hgtx_ppu_proj_sum report.asysrep可通过asys stats --help-report hgtx_ppu_proj_sum查看具体帮助信息,支持的选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过/分割。若不指定,默认统计所有PPU device。range-mode=<mode>:PPU侧统计时间范围的选择模式,支持active和full模式。active:默认模式,时间范围从第一个PPU活动开始,到最后一个PPU活动结束截止。
full:时间范围选取为用户指定的统计时间范围,若没有指定统计时间范围,则统计报告整体的时间范围。
range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX range。no-graph-mapping:导出结果不包含通过HGGC graph node映射的HGTX range信息。
GUI使用指南
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Time Range Mode:设置统计时间范围的模式:
PPU Active Time Range:默认模式,时间范围从第一个PPU活动开始,到最后一个PPU活动结束截止。Filtered Time Range:时间范围选取为用户指定的统计时间范围,若没有指定统计时间范围,则统计报告整体的时间范围。
HGTX graph node mapping:是否投影HGGC graph capture阶段HGTX到PPU侧(通过在HGTX range范围内创建的HGGC graph node建立与PPU侧到关联)。默认值为“Yes”。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置。
饼图统计:对CPU侧所有HGTX Range的在PPU侧的投影活动时间进行汇总。可以直观地查看各HGTX Range投影至PPU侧后的运行耗时占比。
2.3.12 HGTX向PPU投影跟踪
将asysrep报告中的CPU侧HGTX range向PPU侧投影,以展示CPU侧HGTX range在PPU侧实际活跃的时间,并导出HGTX的堆栈信息。
依赖的asys采集选项:--trace hgtx,hggc
统计规则
判断HGTX range和HGGC kernel的原则为:HGTX range持续时间范围内,相同线程的HGGC API触发的HGGC kernel,认为和此HGTX range关联。
CPU侧HGTX range向PPU侧投影的方式为:HGTX range在PPU侧的活跃时间,从本HGTX关联的最早的PPU活动开始,到最晚的PPU活动结束。PPU活动包括:HGGC Kernel / memcpy / memset 相关执行信息。
HGTX range在PPU侧的活跃时间PPU Active Time计算方式为:指定的时间点存在一个或者多个PPU侧活动,则记为活跃时间。若多个PPU侧活动在时间上重叠,重叠的部分不会被多次计入活跃时间。
导出结果组织如下:每HGTX range导出一行数据,结果按照Projected Start升序输出。
hgtx_ppu_proj_trace表格列说明如下:
Row# : Row number of the HGTX PPU projection trace
Name : Name of the HGTX range
Projected Start [ns] : Projected range start timestamp
Projected Duration [ns] : Projected range duration
PPU Active Time [ns] : Total PPU active time excluding overlapping for this range
Orig Start [ns] : Original HGTX range start timestamp
Orig Duration [ns] : Original HGTX range duration
Style : Range style; Start/End or Push/Pop
PID : Process identifier
TID : Thread identifier
NumPPUOps : Number of enclosed PPU operations
Lvl : Stack level, starts at 0
NumChild : Number of children ranges
RangeId : Arbitrary ID for range
ParentId : Range ID of the enclosing range
RangeStack : Range IDs that make up the push/pop stack命令行使用方法
asys stats -r hgtx_ppu_proj_trace report.asysrep可通过asys stats --help-report hgtx_ppu_proj_trace查看具体帮助信息,支持的选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX range。no-graph-mapping:导出结果不包含通过HGGC graph node映射的HGTX range信息。
报告结果示例如下:
Row#,Name,Projected Start (ns),Projected Duration (ns),PPU Active Time (ns),Orig Start (ns),Orig Duration (ns),Style,PID,TID,NumPPUOps,Lvl,NumChild,RangeId,ParentId,RangeStack,
1,"profile",777876074,53206947,21448563,776113485,56055065,"PushPop",295684,295684,50,0,10,6,"-",":6",
2,"Loop1",777876074,14961664,10470590,776142784,28572367,"PushPop",295684,295684,5,1,1,7,6,":6:7",
3,"DoProcess",777876074,14961664,10470590,776146124,27485685,"PushPop",295684,295684,5,2,0,8,7,":6:7:8",
...GUI使用指南
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
HGTX graph node mapping:是否投影HGGC graph capture阶段HGTX到PPU侧(通过在HGTX range范围内创建的HGGC graph node建立与PPU侧到关联)。默认值为“Yes”。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置
表格右键菜单功能
支持在Timeline View中高亮或缩放至所选的HGTX Range。
支持在Timeline View中高亮或缩放至所选的Device Activity。
饼图统计:对CPU侧所有HGTX Range以range name或进程进行分类,在PPU侧的投影活动时间进行汇总。可以直观地查看各HGTX Range或进程投影至PPU侧后的运行耗时占比。
2.3.13 HGTX range汇总
汇总asysrep报告中HGTX range的耗时,按照range总耗时降序输出。
依赖的asys采集选项:--trace hgtx
统计规则
按照每HGTX range domain和名称级别进行统计,累加相同domain和名称的HGTX range的耗时时间,若HGTX range包含domain,输出的HGTX range名称格式为domain:range,按照range总耗时降序输出。
若通过process/thread选项指定统计范围,线程匹配thread过滤条件或者所属进程匹配process过滤条件,均参与统计。
hgtx_sum表格列说明如下:
注意“Time”列是根据“Total Time”列的总和计算得出的,表示该range占所有列出ranges执行时间的百分比,而不是根据应用执行时间得到的百分比。
Row# : Row number of the HGTX range summary
Time [%] : Percentage of 'Total Time'
Total Time [ns] : Total time used by all instances of this range
Instances : Number of instances of this range
Avg [ns] : Average execution time of this range
Med [ns] : Median execution time of this range
Min [ns] : Smallest execution time of this range
Max [ns] : Largest execution time of this range
StdDev [ns] : Standard deviation of the time of this range
Style : Range style; Start/End or Push/Pop
Range : Name of the range命令行使用方法
asys stats -r hgtx_sum report.asysrep可通过asys stats --help-report hgtx_sum查看具体帮助信息。支持的选项列举如下:
rows=<limit>:限制输出的HGTX range的条数。process=<pid_list>:指定统计的进程的PID列表,多个PID之间通过/分割。若不指定,默认统计所有进程。thread=<tid_list>:指定统计的线程的TID列表,多个TID之间通过/分割。若不指定,默认统计所有线程。
报告结果示例如下:
Row#,Time (%),Total Time (ns),Instances,Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),Style,Range,
1,25.7,181837947,1,181837947,181837947,181837947,181837947,0,"PushPop","[prof_range]: iter 6",
2,25.1,177622641,1,177622641,177622641,177622641,177622641,0,"PushPop","[prof_range]: iter 9",
3,25.1,177254919,1,177254919,177254919,177254919,177254919,0,"PushPop","[prof_range]: iter 7",
4,24.1,170843422,1,170843422,170843422,170843422,170843422,0,"PushPop","[prof_range]: iter 8",
...GUI使用指南
规则设置(Settings)
Processes:指定统计的进程。默认为“All”,统计所有进程。
Maximum number of results:展示结果的最大行数。默认为-1,表示无上限。
饼图统计:对所有HGTX Range的总耗时进行汇总。可以直观地查看各HGTX Range的耗时占比。
2.3.14 OSRT API汇总
汇总asysrep报告中操作系统API(OS runtime API)的耗时,按照API总耗时降序输出。
依赖的asys采集选项:--trace osrt
统计规则
按照每OSRT API名称级别进行统计,累加相同名称API的耗时时间,按照API总耗时降序输出。
osrt_sum表格列说明如下:
注意“Time”列是根据“Total Time”列的总和计算得出的,表示该函数占所有列出函数执行时间的百分比,而不是根据应用执行时间得到的百分比。
Row# : Row number of the OS runtime summary
Time [%] : Percentage of 'Total Time'
Total Time [ns] : Total time used by all executions of this function
Num Calls : Number of calls to this function
Avg [ns] : Average execution time of this function
Med [ns] : Median execution time of this function
Min [ns] : Smallest execution time of this function
Max [ns] : Largest execution time of this function
StdDev [ns] : Standard deviation of the time of this function
Name : Name of the function命令行使用方法
asys stats -r osrt_sum report.asysrep可通过asys stats --help-report osrt_sum查看具体帮助信息。
报告结果示例如下:
Row#,Time (%),Total Time (ns),Num Calls,Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),Name,
1,85.6,8901500720,255,34907845,4994783,1095,348667026,63811239,"pthread_cond_wait",
2,6.9,721563692,1105,652998,1055069,52083,1072141,485233,"nanosleep",
3,6.7,700892565,7,100127509,100123388,100121020,100143853,8411,"poll",
...GUI使用指南
规则设置(Settings)
该规则没有可以配置的设置选项。
饼图统计:对所有OSRT API的总耗时进行汇总。可以直观地查看各OSRT API的耗时占比。
2.3.15 PCCL传输各阶段汇总
分析和汇总asysrep报告中PCCL传输各阶段耗时,按照阶段总耗时降序输出。
依赖的asys采集选项:--trace pccl
统计规则
按照每线程、每channel、每方向、每传输阶段,统计传输阶段的耗时(平均值、最大值、最小值等)、出现次数等指标,按照传输阶段总耗时降序输出。
pccl_stage_sum表格列说明如下:
Row# : Row number of the stage summary
PID : Process identifier
Device ID : PPU device identifier
TID : Thread identifier
Channel ID : PCCL channel identifier
Channel Type : PCCL channel type
Name : Stage name
Total Time [ns] : Stage total time
Instances : Number of this stage
Avg [ns] : Average of stage duration
Med [ns] : Median of stage duration
Min [ns] : Minimum of stage duration
Max [ns] : Maximum of stage duration
Stdev [ns] : Standard deviation of stage duration命令行使用方法
asys stats --report pccl_stage_sum report.asysrep可通过asys stats --help-report pccl_stage_sum查看具体帮助信息。
报告结果示例如下:
Row#,PID,Device ID,TID,Channel ID,Channel Type,Name,Total Time,Instances,Avg,Med,Min,Max,Stdev,
1,631660,0,631712,1,RX,RecvWait,305528068,24,12730336,13761981,9669723,18509164,2407844,
2,631660,1,631711,1,TX,GPUWait,299988851,24,12499535,12786840,9625474,16580086,2217489,
3,631660,0,631712,1,TX,GPUWait,297674072,24,12403086,12579239,9570100,17151019,2208876,
...GUI使用指南
规则设置(Settings)
该规则没有可以配置的设置选项。
饼图统计:对所有PCCL stage/进程/设备的PCCL stage总耗时进行汇总。可以直观地查看在不同统计维度下PCCL stage总的耗时占比。
2.3.16 HGGC PPU memory数据量汇总
汇总asysrep报告中HGGC PPU memory操作(memcpy / memset)的数据量 ,按照memory操作数据量总和降序输出。
依赖的asys采集选项:--trace hggc
统计规则
按照每memory操作类型,统计本类型操作数据量,按照操作数据量总和降序输出。
memcpy根据拷贝的类型进行区分,如
[HGGC memcpy Host-to-Device]/[HGGC memcpy Device-to-Host]
hggc_ppu_mem_size_sum表格列说明如下:
Row# : Row number of the memory summary
Total [bytes] : Total memory utilized by this operation
Count : Number of executions of this operation
Avg [bytes] : Average memory size of this operation
Med [bytes] : Median memory size of this operation
Min [bytes] : Smallest memory size of this operation
Max [bytes] : Largest memory size of this operation
StdDev [bytes] : Standard deviation of the memory size of this operation
Operation : Name of the memory operation命令行使用方法
asys stats --report hggc_ppu_mem_size_sum report.asysrep可通过asys stats --help-report hggc_ppu_mem_size_sum查看具体帮助信息。
报告结果示例如下:
Row#,Total (bytes),Count,Avg (bytes),Med (bytes),Min (bytes),Max (bytes),StdDev (bytes),Operation,
1,9896352144,564,17546723,1024,12,556254464,74087070,"[HGGC memset]",
2,536876208,342,1569813,16,4,67108864,10157989,"[HGGC memcpy Host-to-Device]",
3,156,44,3,1,1,16,4,"[HGGC memcpy Device-to-Host]",
4,64,12,5,4,4,8,1,"[HGGC memcpy Device-to-Device]",GUI使用指南
规则设置(Settings)
该规则没有可以配置的设置选项。
饼图统计:对所有Memory operation的memory操作数据量进行汇总。可以直观地查看各个Memory operation的memory操作数据量的对比情况。
2.3.17 HGGC PPU memory耗时汇总
汇总asysrep报告中HGGC PPU memory操作(memcpy / memset)的耗时 ,按照memory操作耗时总时长降序输出。
依赖的asys采集选项:--trace hggc
统计规则
按照每memory操作类型,统计本类型操作耗时,按照操作耗时总时长降序输出。
memcpy根据拷贝的类型进行区分,如
[HGGC memcpy Host-to-Device]/[HGGC memcpy Device-to-Host]。
hggc_ppu_mem_time_sum表格列说明如下:
注意“Time”列是根据“Total Time”列的总和计算得出的,表示该memory操作类型占所有列出的memory操作耗时总时长的百分比,而不是根据应用执行时间得到的百分比。
Row# : Row number of the memory summary
Time [%] : Percentage of 'Total Time'
Total Time [ns] : Total time used by all executions of this operation
Count : Number of operations to this type
Avg [ns] : Average execution time of this operation
Med [ns] : Median execution time of this operation
Min [ns] : Smallest execution time of this operation
Max [ns] : Largest execution time of this operation
StdDev [ns] : Standard deviation of the time of this operation
Operation : Name of the memory operation命令行使用方法
asys stats --report hggc_ppu_mem_time_sum report.asysrep可通过asys stats --help-report hggc_ppu_mem_time_sum查看具体帮助信息。
报告结果示例如下:
Row#,Time (%),Total Time (ns),Count,Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),Operation,
1,69.3,19697314,342,57594,1240,1080,2413129,364424,"[HGGC memcpy Host-to-Device]",
2,30.6,8687991,564,15404,720,120,496801,67433,"[HGGC memset]",
3,0.1,20920,44,475,400,320,960,165,"[HGGC memcpy Device-to-Host]",
4,0.1,15600,12,1300,1240,920,1800,293,"[HGGC memcpy Device-to-Device]",GUI使用指南
规则设置(Settings)
该规则没有可以配置的设置选项。
饼图统计:对所有Memory operation的耗时进行汇总。可以直观地查看各个Memory operation的耗时占比。
2.3.18 PCCL不同步跟踪
将asysrep报告中的PCCL kernel根据通信进行分组,计算每组通信的PCCL kernel之间执行时间不同步的占比,并导出最晚开始执行的PCCL kernel的信息。
依赖的asys采集选项:
--trace hggc
统计规则
将执行时间上存在重叠的PCCL kernel分入一个通信组,对每个通信组的所有kernel计算如下时间:
重叠时间:本通信组内所有PCCL kernel重叠的时间。持续时间:从本通信组第一个kernel开始执行到最后一个kernel停止执行的时间。
不同步比例计算方式为:(持续时间 - 重叠时间) / 持续时间。每通信组输出一行跟踪数据,结果按照不同步占比降序输出。
pccl_desync_trace表格列说明如下:
Row# : Row number of PCCL communication trace
Start [ns] : Start time of PCCL communication
Duration [ns] : Eclapsed duration of PCCL communication
Overlap [ns] : Overlapping duration of all PCCL kernel
Desync Rate [%] : Desynchronization rate of PCCL communication
Last Process : Last kernel process ID in this PCCL communication
Last Device : Last kernel device ID in this PCCL communication
Last Kernel : Last kernel ID in this PCCL communication
Max Duration [ns] : Longest kernel duration in this PCCL communication
Min Duration [ns] : Shortest kernel duration in this PCCL communication
Avg Duration [ns] : Average kernel duration in this PCCL communication
Instances : Number of kernel in this PCCL communication
Kernel Name : Name of the PCCL kernel命令行使用方法
asys stats -r pccl_desync_trace report.asysrep可通过asys stats --help-report pccl_desync_trace查看具体帮助信息,支持的选项列举如下:
hgtx-name:kernel名字前通过
/拼接最接近kernel launch的HGTX range名称。base:使用kernel的短名称(仅函数名,不包含参数)进行统计和输出。
mangled:使用kernel的mangled名称进行统计和输出。
device:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。
报告结果示例如下:
Row#,Start (ns),Duration (ns),Overlap (ns),Desync Rate (%),Last Process,Last Device,Last Kernel,Max Duration (ns),Min Duration (ns),Avg Duration (ns),Instances,Kernel Name,
1,113393971366,699213,15256,97.8,1142413,0,38654,697883,15400,538712,8,"pcclKernel_AllReduce_RING_LL_Sum_uint8_t(ncclWorkElem)",
2,113395036610,267497,12450,95.3,1142419,6,38798,266721,14040,191886,8,"pcclKernel_AllReduce_RING_LL_Sum_uint8_t(ncclWorkElem)",
...GUI使用指南
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Add HGTX name as a prefix:使能名字前拼接最接近kernel launch的HGTX名称,通过
/间隔。默认不勾选。
表格右键菜单功能
支持在Timeline View中高亮或缩放至所选追踪的最后一个不同步的PCCL Kernel。
饼图统计:对PCCL不同步情况出现时,最慢的进程/设备进行汇总。可以直观地查看哪个进程/设备上最容易出现PCCL执行时间最晚导致PCCL不同步情况出现。
2.3.19 PCCL不同步汇总
将asysrep报告中的PCCL kernel根据通信进行分组,计算每组通信的PCCL kernel之间执行时间不同步的占比,输出同名PCCL kernel通信组的不同步占比的统计结果。
依赖的asys采集选项:--trace hggc
统计规则
将执行时间上存在重叠的PCCL kernel分入一个通信组,对每个通信组的所有kernel计算如下时间:
重叠时间:本通信组内所有PCCL kernel重叠的时间。持续时间:从本通信组第一个kernel开始执行到最后一个kernel停止执行的时间。
不同步比例计算方式为:(持续时间 - 重叠时间) / 持续时间。
Desync P90列的计算方法为:将相同kernel名称的通信组统计结果根据不同步率升序排列,获取第90百分位的不同步率,本数值表示大部分PCCL通信不同步率优于此结果。
按照每kernel名称统计通信组的耗时和不同步占比,按照通信组的耗时汇总降序输出。
pccl_desync_summary表格列说明如下:
注意“Time”列是根据“Total Duration”列的总和计算得出的,表示该PCCL kernel所在通信组耗时占所有列出的通信组耗时总时长的百分比,而不是根据应用执行时间得到的百分比。
Row# : Row number of PCCL communication summary
Time [%] : Percentage of 'Total Duration'
Count : Number of communication of this PCCL kernel
Desync Avg [%] : Average desynchronization rate of this PCCL kernel
Desync Med [%] : Median desynchronization rate of this PCCL kernel
Desync Min [%] : Smallest desynchronization rate of this PCCL kernel
Desync Max [%] : Largest desynchronization rate of this PCCL kernel
Desync StdDev [%] : Standard deviation of desynchronization rate of this PCCL kernel
Total Duration [ns] : Total eclapsed duration of all communication of this PCCL kernel
Total Overlap [ns] : Total overlap duration of all communication of this PCCL kernel
Kernel Name : Name of the PCCL kernel命令行使用方法
asys stats -r pccl_desync_summary report.asysrep可通过asys stats --help-report pccl_desync_summary查看具体帮助信息,支持的选项列举如下:
hgtx-name:kernel名字前通过
/拼接最接近kernel launch的HGTX range名称。base:使用kernel的短名称(仅函数名,不包含参数)进行统计和输出。
mangled:使用kernel的mangled名称进行统计和输出。
device:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。
报告结果示例如下:
Row#,Time (%),Count,Desync Avg (%),Desync Med (%),Desync Min (%),Desync Max (%),Desync StdDev (%),Total Duration (ns),Total Overlap (ns),Kernel Name,
1,95.4,4,98.3,98.9,95.3,100.0,1.9,931583768,60421,"pcclKernel_AllReduce_RING_LL_Sum_uint8_t(ncclWorkElem)",
2,4.6,1,100.0,100.0,100.0,100.0,0.0,44549251,17168,"pcclKernel_AllReduce_RING_LL_Sum_double(ncclWorkElem)",GUI使用指南
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Add HGTX name as a prefix:使能名字前拼接最接近kernel launch的HGTX名称,通过
/间隔。默认不勾选。
饼图统计:对所有PCCL kernel通信组的总耗时进行汇总。
2.3.20 设备属性信息
将asysrep报告中的PPU设备属性信息导出,输出PPU设备的基础参数信息,按照设备索引升序输出。
依赖的asys采集选项:--trace hggc
统计规则
将PPU设备的各项参数信息,按照设备索引升序输出,每个PPU设备为表格的一行信息。
ppu_device_attribute表格列说明如下,
注意
CU Clock和Memory Clock为设备支持的最高频率,并非PPU设备的实时频率信息:
Row# : Row number of device attribute
Device ID : PPU device identifier
Device Name : PPU device name
PCI Bus ID : PCI bus identifier
Host Name : Host Name
UUID : PPU device universally unique identifier
Compute Capability Major : Compute capability major version
Compute Capability Minor : Compute capability minor version
CE Number : Compute engine number
CU Number : Compute unit number
Total Memory [bytes] : Total device memory size
CU Clock [Hz] : Compute unit clock frequency
Memory Clock [Hz] : Memory clock frequency命令行使用方法
asys stats -r ppu_device_attribute report.asysrep报告结果示例如下:
Row#,Device ID,Device Name,PCI Bus ID,Host Name,UUID,Compute Capability Major,Compute Capability Minor,CE Number,CU Number,Total Memory (bytes),CU Clock (Hz),Memory Clock (Hz),
1,0,"PPU-ZW810E","00000001:C9:00.0","na131t-swu141.eng.t-head.cn","-",8,0,16,64,103079215104,1700000000,1800000000,
2,1,"PPU-ZW810E","00000001:C8:00.0","na131t-swu141.eng.t-head.cn","-",8,0,16,64,103079215104,1700000000,1800000000,
...2.3.21 PPU算子汇总
将asysrep报告中的PPU算子按照类型和参数取值进行分组,汇总每组PPU算子在PPU上的执行时间,并估算每组PPU算子的PPU硬件利用率。
依赖的asys采集选项:
--trace hggc,hgtx
Tips:在采集asysrep报告前,建议使能PPU算子HGTX range标注相关功能:
执行
export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能基础框架PPU算子HGTX range标注功能asys添加选项
--pytorch autograd-shapes-hgtx,使能pytorch算子HGTX range标注功能
统计规则
PPU算子的执行时间统计方式为:
每个PPU算子在PPU侧的执行时间为:本算子关联的PPU侧第一个活动开始,到最后一个活动结束的持续时间
PPU算子的PPU活跃时间PPU Active Time计算方式为:
指定的时间点存在一个或者多个本PPU算子关联的PPU活动,则记为活跃时间。如果多个PPU活动在时间上重叠,重叠的部分不会被多次计入活跃时间
PPU算子的执行信息汇总时,若两个PPU算子之间大部分参数相同,仅少量对应能影响较小的参数差异,默认会忽略参数差异,按照相同的PPU算子合并汇总。
若算子类型指定了others类型,未关联到PPU算子的kernel也参与统计,根据kernel名称进行汇总。
汇总结果组织如下:每PPU算子参数组合(默认忽略性能影响较小的参数差异),汇总每个算子的执行时间信息,结果按照Total Time列降序输出。
PPU计算能力利用率估算的计算方法为:
本算子计算量/ (PPU计算每秒峰值能力*算子平均执行时间)
HBM load和store利用率估算的计算方法为:
本算子的数据量/ (HBM每秒峰值吞吐能力*算子平均执行时间)
ppu_op_sum表格列说明如下:
注意“Percent”列是根据“Total Time”列的总和计算得出的,表示该PPU算子总耗时占所有列出的算子耗时总时长的百分比,而不是根据应用执行时间得到的百分比。
Row# : Row number of the PPU operator summary
OP type : PPU operator type
Total Time [ns] : Total time used by all kernel instances of this operator
Percent [%] : Percentage of 'Total Time'
Instances : Number of this operator
Avg [ns] : Average execution time of this operator
Med [ns] : Median execution time of this operator
Min [ns] : Smallest execution time of this operator
Max [ns] : Largest execution time of this operator
PPU Active Time [ns] : Total PPU active time excluding overlapping for this operator
Active Percent [%] : Percentage of active time to total duration time
StdDev [ns] : Standard deviation of the time of this operator
Compute Util [%] : Utilization ratio of PPU compute capability
HBM Load Util [%] : Utilization ratio of PPU HBM load bandwidth
HBM Store Util [%] : Utilization ratio of PPU HBM store bandwidth
OP Name : Name of the PPU operator命令行使用方法
asys stats -r ppu_op_sum report.asysrep可通过asys stats --help-report ppu_op_sum查看具体帮助信息,支持的选项列举如下:
rows=<limit>:限制输出结果的条数device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过/分割。若不指定,默认统计所有PPU devicerange-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX rangerange-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX rangeop=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果中体现order-by=<order_type>:指定输出结果排序方式,默认按照算子时间占比排序no-graph-mapping:若指定,不再映射HGGC graph创建阶段的HGTX到HGGC graph执行阶段no-merge-flash-attention-prefill-decode-operator:若指定,不再匹配和合并prefill和decode的flash attention算子no-merge-flash-attention-parameter:若指定,不再忽略flash attention算子对性能影响较小的参数差异no-merge-communication-parameter:若指定,不再忽略通信算子对性能影响较小的参数差异no-merge-moe-parameter:若指定,不再忽略MoE算子对性能影响较小的参数差异no-merge-pytorch-parameter:若指定,不再忽略pytorch算子对性能影响较小的参数差异no-merge-gemm-parameter:若指定,不再忽略GEMM算子对性能影响较小的参数差异
可通过--ppu-op-config选项自定义算子识别规则,可指定正则表达式通过匹配HGTX range名称或者kernel名称识别指定算子类型,格式为算子类型=匹配类型:过滤规则,可多次通过--ppu-op-config选项创建多个算子识别规则,例如:
--ppu-op-config GEMM=kernel:gemv --ppu-op-config Pytorch=hgtx:aten--ppu-op-config GEMM=kernel:gemv:匹配kernel名称包含gemv关键字的kernel,分类到GEMM算子类型--ppu-op-config Pytorch=hgtx:aten:匹配HGTX range名称包含aten关键字,HGTX range关联的PPU活动分类到Pytorch算子类型
报告结果示例如下:
Row#,OP Type,Total Time (ns),Percent (%),Instances,Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),PPU Active Time (ns),Active Percent (%),Compute Util (%),HBM Load Util (%),HBM Store Util (%),OP Name,
1,"MoE",1714874135,51.1,3020,567839,564123,1280,668923,21134,1711260616,99.8,8.6,"-",0.1,"MoE:M_72_E8_H6144_In8192_topk2",
2,"PCCL",146435489,4.4,6088,24053,20080,16240,6148511,86558,146435489,100.0,"-","-","-","AllReduce, p:0, c:442368, d:9, r:0, w:4, h:c70515c91cef61c7, t:1, b:0x119e800000/0x119e8d8000",
3,"GEMM",79589151,2.4,3022,26336,26240,25200,31761,720,78991428,99.2,15.4,33.3,0.0,"ACBLAS:GemmEx,t,n,2048,72,6144,6144,6144,2048,1,0,1,DEFAULT,BF16,ACBLAS_GEMM_DEFAULT_TENSOR_OP,32F,EPILOGUE_DEFAULT",
...GUI使用指南
通过选中行来统计求列和
统计结果表格中的“Total Time”和“Percent”列支持对选中行数据自动求和,统计结果显示在表头的第二行中。当没有行被选中时,对该列的所有行进行统计求和。
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Merge operator parameters:忽略对算子对性能影响较小的参数差异,将其合并统计。默认对所有类型的算子都启用。
HGTX graph node mapping:是否投影HGGC graph capture阶段HGTX到PPU侧(通过在HGTX range范围内创建的HGGC graph node建立与PPU侧到关联)。默认值为“Yes”。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置
Show top N results:展示前N条结果,默认为“-1”,即不限制展示结果条数。
Parse from:选择解析算子的来源,所有ppu活动都只能通过使能的算子解析来源尝试进行解析,若解析成功则会纳入算子统计的结果中。默认值为“ALL”,从所有支持的解析来源对ppu活动进行解析,此项不能为空。
Custom operator parse config:自定义算子解析规则,使能后可以自行添加算子解析规则,通过kernel名或HGTX名+正则表达式匹配,解析出自定义的算子类型。该自定义解析规则优先级高于上面的“Parse from”选项。默认为空。
饼图统计:对算子类型(OP Type)或算子名称(OP Name)的总耗时进行统计。可以直观地查看各个算子类型或具体算子的耗时占比。
2.3.22 MoE算子汇总
将asysrep报告中的MoE算子按照类型和参数取值进行分组,汇总每组MoE算子在PPU上的执行时间,并估算每组MoE算子GEMM运算的PPU硬件利用率。
依赖的asys采集选项:--trace hggc,hgtx
Tips:在采集asysrep报告前,需要执行export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能PPU算子HGTX range标注功能。
统计规则
MoE算子的执行时间统计方式为:
每个MoE算子在PPU侧的执行时间为:本算子关联的PPU侧kernel的执行时间累加。
统计每个MoE算子的第一个和第二个GEMM算子的执行时间。
MoE算子的执行信息汇总时,若两个MoE算子之间大部分参数相同,仅有少量影响较小的参数差异,默认会忽略参数差异,按照相同的MoE算子合并汇总。
汇总结果组织如下:每MoE算子参数组合(默认忽略性能影响较小的参数差异),汇总每个算子的执行时间信息,结果按照Total Time列降序输出。
GEMM算子的PPU计算能力利用率估算的计算方法为,第一个和第二个GEMM算子的利用率单独计算:
本GEMM算子计算量/ (PPU计算每秒峰值能力*GEMM kernel平均执行时间)
GEMM算子的HBM load和store利用率估算的计算方法为:
本GEMM算子的数据量/ (HBM每秒峰值吞吐能力*GEMM kernel平均执行时间)
moe_op_sum表格说明如下:
注意“Percent”列是根据“Total Time”列的总和计算得出的,表示该MoE算子总耗时占所有列出的算子耗时总时长的百分比,而不是根据应用执行时间得到的百分比。
Row# : Row number of the MoE operator summary
Total Time [ns] : Total time used by all kernel instances of this operator
Percent [%] : Percentage of 'Total Time'
GEMM1 Total Time [ns] : Total time used by GEMM 1 kernel
GEMM2 Total Time [ns] : Total time used by GEMM 2 kernel
Instances : Number of this MoE operator
Avg [ns] : Average execution time of this operator's kernel
Med [ns] : Median execution time of this operator's kernel
Min [ns] : Smallest execution time of this operator's kernel
Max [ns] : Largest execution time of this operator's kernel
StdDev [ns] : Standard deviation of the time of this operator's kernel
GEMM1 Compute Util [%] : GEMM 1 utilization ratio of PPU compute capability
GEMM2 Compute Util [%] : GEMM 2 utilization ratio of PPU compute capability
GEMM1 HBM Load Util [%] : GEMM 1 Utilization ratio of PPU HBM load bandwidth
GEMM1 HBM Store Util [%] : GEMM 1 Utilization ratio of PPU HBM Store bandwidth
GEMM2 HBM Load Util [%] : GEMM 2 Utilization ratio of PPU HBM load bandwidth
GEMM2 HBM Store Util [%] : GEMM 2 Utilization ratio of PPU HBM Store bandwidth
OP Name : Name of the MoE operator命令行使用方法
asys stats -r moe_op_sum report.asysrep可通过asys stats --help-report moe_op_sum查看具体帮助信息,支持的选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX range。no-graph-mapping:若指定,不再映射HGGC graph创建阶段的HGTX到HGGC graph执行阶段。no-merge-moe-parameter:若指定,不再忽略MoE算子对性能影响较小的参数差异。
报告结果示例如下:
Row#,Total Time (ns),Percent (%),GEMM1 Total Time (ns),GEMM2 Total Time (ns),Instances,Avg (ns),Med (ns),Min (ns),Max (ns),StdDev (ns),GEMM1 Compute Util (%),GEMM2 Compute Util (%),GEMM1 HBM Load Util (%),GEMM1 HBM Store Util (%),GEMM2 HBM Load Util (%),GEMM2 HBM Store Util (%),OP Name,
1,4400578,0.2,2199129,1617367,6,733429,732642,729163,739724,3299,43.2,29.4,30.2,0.1,20.1,0.9,"MoE:M_876_E_128_H_4096_In_384_topk_8_topkids[136,0,25,167,68,17,3,5...]_unique_102",
2,4377299,0.2,2218248,1581567,6,729549,729244,726804,734042,2398,42.8,30.0,29.9,0.1,20.6,0.9,"MoE:M_876_E_128_H_4096_In_384_topk_8_topkids[0,28,0,17,24,81,10,143,...]_unique_102",
...GUI使用指南
通过选中行来统计求列和
统计结果表格中的“Total Time”和“Percent”列支持对选中行数据自动求和,统计结果显示在表头的第二行中。当没有行被选中时,对该列的所有行进行统计求和。
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
HGTX graph node mapping:是否投影HGGC graph capture阶段HGTX到PPU侧(通过在HGTX range范围内创建的HGGC graph node建立与PPU侧到关联)。默认值为“Yes”。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置
Merge MoE parameters:忽略对MoE算子对性能影响较小的参数差异,将其合并统计,默认使能。
饼图统计:对算子名称(OP Name)的总耗时进行统计。可以直观地查看各个算子的耗时占比。
2.3.23 PCCL算子汇总
将asysrep报告中的PCCL算子按照类型和参数取值进行分组,汇总每组PCCL通信在各个PPU设备的通信时间,计算每组PCCL通信的PPU通信带宽。
依赖的asys采集选项:--trace hggc,hgtx
统计规则
PCCL算子的合并规则为:
相同通信组、相同的PCCL算子类型(如AllReduce)、相同数据量的多个PPU设备的算子合并计算。
PCCL算子类型分为如下两类:
collective类型,如AllReduce、Broadcast。
point to point类型,如Send、Recv。
对于collective类型的PCCL算子,统计规则如下:
对于每次PCCL算子通信,将参与通信的PPU设备中执行时间最短的PCCL kernel的执行时间,作为本次通信的传输时间
Trans Time,所有参与通信的PPU设备的传输时间的累加,作为统计结果的Trans Time的取值。统计结果的
Instances列表示PCCL算子通信发生的次数,对于PCCL算子通信涉及多个PPU设备的场景,多个PPU设备不会导致Instances累加多次。对于每次PCCL算子通信,将每个PPU设备传输数据量进行累加,作为统计结果的
Trans Size的取值。
对于point to point类型的PCCL算子,统计规则如下:
每次PCCL算子通信的kernel执行时间即认为是算子的传输时间,作为统计结果的
Trans Time的取值。PCCL算子通信的kernel执行次数,作为统计结果的
Instances的取值。
输出结果按照Trans Time降序输出。
pccl_op_sum表格说明如下:
Trans Time列表示本组PCCL通信的实际传输耗时,去除由于多个PPU设备不同步导致的等待时间。Instances列表示本算子对应的每组PCCL通信发生的次数,例如对于AllReduce算子,所有PPU完成一次AllReduce操作,本列取值+1。Device Mask列表示本算子涉及的PPU设备的bitmap,每个bit表示参与的PPU设备索引。
Row# : Row number of the PCCL operator summary
Trans Time [ns] : Transmission time used by all kernel instances of this operator
Trans Percent [%] : Percentage of actual transmission time relative to 'Total Time'
Total Time [ns] : Total time used by all kernel instances of this operator
Instances : Number of grouped transmission of this PCCL operator
Device Mask : PPU device mask of this PCCL operator
Trans Size [bytes] : Total transmission data size of this operator
Trans Bandwidth [B/s] : Transmission bandwidth
OP Name : Name of the PCCL operator命令行使用方法
asys stats -r pccl_op_sum report.asysrep可通过asys stats --help-report pccl_op_sum查看具体帮助信息,支持的选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。no-graph-mapping:若指定,不再映射HGGC graph创建阶段的HGTX到HGGC graph执行阶段。
报告结果示例如下:
Row#,Trans Time (ns),Trans Percent (%),Total Time (ns),Instances,Device Mask,Trans Size (bytes),Trans Bandwidth (B/s),OP Name,
1,3899723152,94.0,4149397116,461,"0xF",464057794560,118997625337,"AllReduce, p:0, c:83886080, d:9, r:1, w:4, h:9da3d23b9ccef54c, t:1, b:0x301a000000/0x302d000000",
2,999480648,98.1,1018779730,129,"0xF",118878474240,118940246094,"AllReduce, p:0, c:76794880, d:9, r:1, w:4, h:9da3d23b9ccef54c, t:1, b:0x301a000000/0x3023279800",
3,100490800,68.8,146110859,1419,"0xF",1394933760,13881208628,"AllReduce, p:0, c:81920, d:9, r:1, w:4, h:9da3d23b9ccef54c, t:1, b:0x573c00000/0x573c28000",
...GUI使用指南
通过选中行来统计求列和
统计结果表格中的“Trans Time”、“Total Time”和“Trans Size”列支持对选中行数据自动求和,统计结果显示在表头的第二行中。当没有行被选中时,对该列的所有行进行统计求和。
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
HGTX graph node mapping:是否投影HGGC graph capture阶段HGTX到PPU侧(通过在HGTX range范围内创建的HGGC graph node建立与PPU侧到关联)。默认值为“Yes”。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置。
饼图统计:对算子名称(OP Name)的传输耗时(Trans Time)进行统计。可以直观地查看各个算子的传输耗时占比。
2.3.24 PPU metric跟踪
将asysrep报告中的PPU metrics sampling跟踪数据导出,输出每PPU设备每metric名称每次采样的结果。
依赖的asys采集选项:--ppu-metrics-device all
统计规则
导出结果组织如下:每PPU设备、每PPU metric名称、每采样时间导出一行数据,按照采样时间升序输出。
ppu_metric_trace表格列说明如下:
Row# : Row number of the PPU metric trace
Device ID : PPU device identifier
Start [ns] : Timestamp when metric sample begin
Duration [ns] : Length of metric sample
Name : PPU metric name
Value : PPU metric value
Unit : PPU metric unit命令行使用方法
asys stats -r ppu_metric_trace report.asysrep可通过asys stats --help-report ppu_metric_trace查看具体帮助信息,支持的选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过/分割。若不指定,默认统计所有PPU device。metrics=<regex_filter>:指定参与统计的PPU metrics过滤正则表达式。若不指定,默认统计所有PPU metrics。
报告结果示例如下:
Row#,Device ID,Start (ns),Duration (ns),Name,Value,Unit,
1,0,201274082,1089858,"ce__cycles_elapsed.avg.per_second",1600518599.7,"cycle/second",
2,0,201274082,1089858,"ce__cycles_active.avg.pct_of_peak_sustained_elapsed",98.7,"%",
...
16,1,201285295,1100045,"ce__cycles_elapsed.avg.per_second",199990000.4,"cycle/second",
17,1,201285295,1100045,"ce__cycles_active.avg.pct_of_peak_sustained_elapsed",0.0,"%",
18,1,201285295,1100045,"gd__dispatch_count.avg.pct_of_peak_sustained_elapsed",0.0,"%",
...GUI使用指南
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的metric sampling数据,此项不能为空。
Metric Name Filter:对结果中的PPU metric name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有metrics。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置。
2.3.25 HGTX push pop range跟踪
将asysrep报告中的push pop类型的HGTX range跟踪数据导出,输出HGTX range堆栈信息和父子关系信息。
依赖的asys采集选项:--trace hgtx
统计规则
HGTX domain push pop range和非domain类型的push pop range均参与统计,HGTX range的堆栈信息取决于HGTX range开始时本线程的HGTX range堆栈状态。
对于每个HGTX range,统计结果中的child range指堆栈中本HGTX range嵌套的次级HGTX range,不包含更深层级嵌套的HGTX range。
导出结果组织如下:每HGTX range跟踪输出一行数据,按照HGTX range开始时间升序输出。
hgtx_pushpop_trace表格列说明如下:
Row# : Row number of the HGTX range trace
Start [ns] : Range start timestamp
End [ns] : Range end timestamp
Duration [ns] : Range duration
DurChild [ns] : Duration of all child ranges
DurNonChild [ns] : Duration of this range minus child ranges
Name : Name of the HGTX range
PID : Process ID
TID : Thread ID
Lvl : Stack level, starts at 0
NumChild : Number of children ranges
RangeId : Arbitrary ID for range
ParentId : Range ID of the enclosing range
RangeStack : Range IDs that make up the push/pop stack
NameTree : Range name prefixed with level indicator命令行使用方法
asys stats -r hgtx_pushpop_trace report.asysrep可通过asys stats --help-report hgtx_pushpop_trace查看具体帮助信息,支持的选项列举如下:
range=<regex_filter>:指定参与统计的HGTX range过滤正则表达式。若不指定,默认统计所有HGTX range。
报告结果示例如下:
Row#,Start (ns),End (ns),Duration (ns),DurChild (ns),DurNonChild (ns),Name,PID,TID,Lvl,NumChild,RangeId,ParentId,RangeStack,NameTree,
1,173403462,309023366,135619904,0,135619904,"profile",3730996,3730996,0,0,6,"-",":6","profile",
2,173765782,298721096,124955314,112237187,12718127,"Loop1",3730996,3731078,0,1,7,"-",":7","Loop1",
3,173985240,264616466,90631226,78300490,12330736,"Loop1",3730996,3731079,0,1,9,"-",":9","Loop1",
4,174054855,298794768,124739913,109974015,14765898,"Loop1",3730996,3731080,0,1,11,"-",":11","Loop1",
5,185211331,263511821,78300490,0,78300490,"DoProcess",3730996,3731079,1,0,13,9,":9:13","-DoProcess",
...GUI使用指南
规则设置(Settings)
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置。
饼图统计:对各HGTX Range的时长(Duration)进行统计。
2.3.26 PPU算子跟踪
识别asysrep报告中的PPU算子,导出每个PPU算子关联的每个PPU活动跟踪。
依赖的asys采集选项:
--trace hggc,hgtx
Tips:在采集asysrep报告前,建议使能PPU算子HGTX range标注相关功能:
执行
export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能基础框架PPU算子HGTX range标注功能asys添加选项
--pytorch autograd-shapes-hgtx,使能pytorch算子HGTX range标注功能
统计规则
PPU算子的执行时间统计方式为:
每个PPU算子在PPU侧的执行时间为:本算子关联的PPU侧第一个活动开始,到最后一个活动结束的持续时间
跟踪导出结果组织如下:每PPU算子、每PPU活动输出一行数据,按照PPU算子开始时间升序排列,相同PPU算子内的PPU活动按照活动起始时间升序排列。
ppu_op_trace表格列说明如下:
Row# : Row number of the PCCL operator trace
OP Type : PPU operator type
Start [ns] : Start timestamp of PPU operator
Duration [ns] : Duration of PPU operator
PID : Process identifier
Device ID : PPU device identifie
Context ID : Context identifier
Stream ID : Stream identifier
PPU Active Time [ns] : PPU active time excluding overlapping for this operator
Active Percent [%] : Percentage of active time to duration time
OP Name : Name of the PPU operator命令行使用方法
asys stats -r ppu_op_trace report.asysrep可通过asys stats --help-report ppu_op_trace查看具体帮助信息,支持的选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。op=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过
/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果中体现。no-merge-flash-attention-prefill-decode-operator:若指定,不再匹配和合并prefill和decode的flash attention算子。
可通过--ppu-op-config选项自定义算子识别规则,可指定正则表达式通过匹配HGTX range名称或者kernel名称识别指定算子类型,格式为算子类型=匹配类型:过滤规则,可多次通过--ppu-op-config选项创建多个算子识别规则,例如:
--ppu-op-config GEMM=kernel:gemv --ppu-op-config Pytorch=hgtx:aten--ppu-op-config GEMM=kernel:gemv:匹配kernel名称包含gemv关键字的kernel,分类到GEMM算子类型。--ppu-op-config Pytorch=hgtx:aten:匹配HGTX range名称包含aten关键字,HGTX range关联的PPU活动分类到Pytorch算子类型。
报告结果示例如下:
Row#,OP Type,OP Name,OP Start (ns),OP Duration (ns),OP ID,Activity ID,PID,Device ID,Context ID,Stream ID,Activity Start (ns),Activity Duration (ns),Activity Name,
1,"PCCL","AllReduce, p:0, c:442368, d:9, r:2, w:4, h:c70515c91cef61c7, t:1, b:0x119e800000/0x119e8d8000",136493999,16760,429199,535257,3790741,2,1,1,136493999,16760,"void pcclKernel_twoShotAllReduceKernel<__ppu_bfloat16, 4, 0, 0, 1, 1>(twoShotDevParams)",
2,"GEMM","ACBLAS:GemmEx,t,n,2048,72,6144,6144,6144,2048,1,0,1,DEFAULT,BF16,ACBLAS_GEMM_DEFAULT_TENSOR_OP,32F,EPILOGUE_DEFAULT",136513799,30320,429204,535262,3790741,2,1,1,136513799,26520,"gemm_ktype0_aiu1_mtype1_dtypeBF16xBF16xFP32xBF16xBF16_tile128x256x64x64x64x2_layout0x1x0x0_align1x1x8x8_splitk2_fusion0_prefetch0_fp32tc0_ptrhost1_schedule0",
...GUI使用指南
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置。
Parse from:选择解析算子的来源,所有ppu活动都只能通过使能的算子解析来源尝试进行解析,若解析成功则会纳入算子统计的结果中。默认值为“ALL”,从所有支持的解析来源对ppu活动进行解析,此项不能为空。
Custom operator parse config:自定义算子解析规则,使能后可以自行添加算子解析规则,通过kernel名或HGTX名+正则表达式匹配,解析出自定义的算子类型。该自定义解析规则优先级高于上面的“Parse from”选项。默认为空。
Merge flash attention prefill decode operators:将flash attention算子中的prefill和decode视作一个算子合并统计。
饼图统计:对算子类型(OP Type)或算子名称(OP Name)的总耗时进行统计。可以直观地查看各个算子类型或具体算子的耗时占比。
2.3.27 PPU算子类型汇总
识别asysrep报告中的PPU算子,按照算子类型分组,汇总每种算子类型的所有算子在PPU上的执行时间,并输出每种算子类型的热点算子信息。
依赖的asys采集选项:
--trace hggc,hgtx
Tips:在采集asysrep报告前,建议使能PPU算子HGTX range标注相关功能:
执行
export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能基础框架PPU算子HGTX range标注功能。asys添加选项
--pytorch autograd-shapes-hgtx,使能pytorch算子HGTX range标注功能。
统计规则
PPU算子的执行时间统计方式为:
每个PPU算子在PPU侧的执行时间为:本算子关联的PPU侧第一个活动开始,到最后一个活动结束的持续时间。
PPU算子的PPU活跃时间PPU Active Time计算方式为:
指定的时间点存在一个或者多个本PPU算子关联的PPU活动,则记为活跃时间。如果多个PPU活动在时间上重叠,重叠的部分不会被多次计入活跃时间。
汇总结果组织如下:
每PPU算子类型,汇总每个算子的执行时间信息,结果按照Total Time降序排列。
每PPU算子类型内,对每种算子参数组合的执行时间汇总,挑选汇总执行时间最长的算子参数组合,作为热点算子。
固定生成
Summary类型的汇总行,汇总所有PPU算子类型的执行时间信息,挑选汇总执行时间最长的算子参数组合,作为汇总行的热点算子。
ppu_op_type_sum表格列说明如下:
OP Type列为Summary的行固定为汇总行,汇总所有PPU算子类型的执行时间信息。
Row# : Row number of the PPU operator type summary
OP Type : PPU operator type
Percent [%] : Percentage of 'Total Time'
Avg [ns] : Average duration of this operator type
Total Time [ns] : Total duration used by all instances of this operator type
Instances : Number of this PPU operator type
PPU Active Time [ns] : Total PPU active time excluding overlapping for this operator type
Active Percent [%] : Percentage of active time to total duration time
Top OP Percent [%] : Percentage of top PPU operator of 'Total Time'
Top OP Name : Name of the top PPU operator of this type命令行使用方法
asys stats -r ppu_op_type_sum report.asysrep可通过asys stats --help-report ppu_op_type_sum查看具体帮助信息,支持的选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。op=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过
/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果中体现。no-graph-mapping:若指定,不再映射HGGC graph创建阶段的HGTX到HGGC graph执行阶段。
no-merge-flash-attention-prefill-decode-operator:若指定,不再匹配和合并prefill和decode的flash attention算子。
no-merge-flash-attention-parameter:若指定,不再忽略flash attention算子对性能影响较小的参数差异。
no-merge-communication-parameter:若指定,不再忽略通信算子对性能影响较小的参数差异。
no-merge-moe-parameter:若指定,不再忽略MoE算子对性能影响较小的参数差异。
no-merge-pytorch-parameter:若指定,不再忽略pytorch算子对性能影响较小的参数差异。
no-merge-gemm-parameter:若指定,不再忽略GEMM算子对性能影响较小的参数差异。
可通过--ppu-op-config选项自定义算子识别规则,可指定正则表达式通过匹配HGTX range名称或者kernel名称识别指定算子类型,格式为算子类型=匹配类型:过滤规则,可多次通过--ppu-op-config选项创建多个算子识别规则,例如:
--ppu-op-config GEMM=kernel:gemv --ppu-op-config Pytorch=hgtx:aten--ppu-op-config GEMM=kernel:gemv:匹配kernel名称包含gemv关键字的kernel,分类到GEMM算子类型。--ppu-op-config Pytorch=hgtx:aten:匹配HGTX range名称包含aten关键字,HGTX range关联的PPU活动分类到Pytorch算子类型。
报告结果示例如下:
Row#,OP Type,Percent (%),Avg (ns),Total Time (ns),Instances,PPU Active Time (ns),Active Percent (%),Top OP Percent (%),Top OP Name,
1,"Summary",100.0,49885,3354637726,67247,3348054119,99.8,51.1,"MoE:M_72_E8_H6144_In8192_topk2",
2,"MoE",63.6,293641,2133601622,7266,2129239591,99.8,51.1,"MoE:M_72_E8_H6144_In8192_topk2",
3,"PCCL",8.2,37031,273847048,7395,273847048,100.0,4.4,"AllReduce, p:0, c:442368, d:9, r:2, w:4, h:c70515c91cef61c7, t:1, b:0x119e800000/0x119e8d8000",
...GUI使用指南
通过选中行来统计求列和
统计结果表格中的“Total Time”,“Total”,“Instances”和“PPU Active Time”列均支持对选中行数据自动求和,统计结果显示在表头的第二行中。类型为“Summary”的行不参与列的求和统计。当没有行被选中时,对该列的所有行进行统计求和。
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Merge operator parameters:忽略对算子对性能影响较小的参数差异,将其合并统计。默认对所有类型的算子都启用。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置。
Parse from:选择解析算子的来源,所有ppu活动都只能通过使能的算子解析来源尝试进行解析,若解析成功则会纳入算子统计的结果中。默认值为“ALL”,从所有支持的解析来源对ppu活动进行解析,此项不能为空。
Custom operator parse config:自定义算子解析规则,使能后可以自行添加算子解析规则,通过kernel名或HGTX名+正则表达式匹配,解析出自定义的算子类型。该自定义解析规则优先级高于上面的“Parse from”选项。默认为空。
饼图统计:对算子类型(OP Type)的总耗时进行统计。可以直观地查看各个算子类型的耗时占比。
2.3.28 PPU算子kernel性能分解
识别asysrep报告中的PPU算子,根据算子的种类和嵌套关系,将算子分为框架层、加速库层和kernel层三个层级,汇总每种算子在PPU上的执行时间,将性能数据逐级分解到kernel层,输出嵌套的算子逐层细化的性能分解信息。
依赖的asys采集选项:
--trace hggc,hgtx
Tips:在采集asysrep报告前,建议使能PPU算子HGTX range标注相关功能:
执行
export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能基础框架PPU算子HGTX range标注功能。asys添加选项
--pytorch autograd-shapes-hgtx,使能pytorch算子HGTX range标注功能。
统计规则
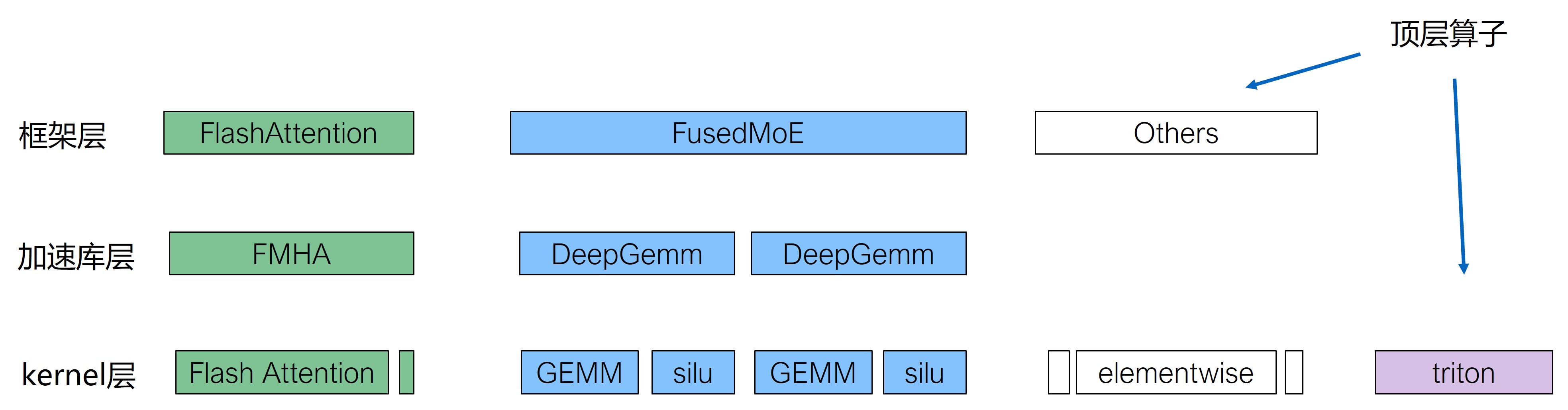
根据HGTX标记和kernel名称识别各个层级的算子,根据算子在PPU上的投影时间范围确定算子之间的嵌套关系。
PPU算子被分为框架层、加速库层和kernel层三个层级,部分层级可能不存在PPU算子信息。以自顶向下的顺序查看算子的嵌套关系,处于嵌套顶层的算子(无论其归属哪个层级)为顶层算子。
PPU算子汇总的Total Time的计算方式为:
所有
顶层算子的执行时间的累加。
每种PPU算子的时间占比的计算方式为:
累加本PPU算子的执行时间,得到
执行时间汇总。计算
执行时间汇总/Total Time,得到本PPU算子的时间占比。
父一级PPU算子范围内,未存在子一级PPU算子的时间范围(PPU设备空闲),被标记为Idle。各个层级中缺失的父一级PPU算子被标记为Native。
汇总结果组织如下:
每框架层算子、每加速库层算子、每kernel层算子,按照逐层的时间占比降序排列。
ppu_op_kernel_breakdown表格列说明如下:
Row# : Row number of the PPU operator kernel breakdown
OP Type : PPU operator type
Framework OP : Name of the framework layer operator
Framework Time [%] : Framework operator time percentage of 'Total Time'
Framework Avg [ns] : Average duration of this framework operator
Framework Instances : Number of this framework operator
Library OP : Name of the compute library layer operator
Library Time [%] : Library operator time percentage of 'Total Time'
Library Avg [ns] : Average duration of this library operator
Library Instances : Number of this library operator
Kernel Name : Name of the HGGC kernel
Kernel Time [%] : HGGC kernel time percentage of 'Total Time'
Kernel Avg [ns] : Average duration of this kernel
Kernel Instances : Number of this kernel命令行使用方法
asys stats -r ppu_op_kernel_breakdown report.asysrep可通过asys stats --help-report ppu_op_kernel_breakdown查看具体帮助信息,支持的选项列举如下:
rows=<limit>:限制输出结果的条数,部分占比较小的算子将会被忽略。
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。base:使用kernel的短名称(仅函数名,不包含参数)进行统计和输出。
mangled:使用kernel的mangled名称进行统计和输出。
op=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过
/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果中体现。order-by=<order_type>:指定输出结果排序方式,默认按照算子时间占比排序。
no-merge-flash-attention-prefill-decode-operator:若指定,不再匹配和合并prefill和decode的flash attention算子。
no-merge-flash-attention-parameter:若指定,不再忽略flash attention算子对性能影响较小的参数差异。
no-merge-communication-parameter:若指定,不再忽略通信算子对性能影响较小的参数差异。
no-merge-moe-parameter:若指定,不再忽略MoE算子对性能影响较小的参数差异。
no-merge-pytorch-parameter:若指定,不再忽略pytorch算子对性能影响较小的参数差异。
no-merge-gemm-parameter:若指定,不再忽略GEMM算子对性能影响较小的参数差异。
可通过--ppu-op-config选项自定义算子识别规则,通过HGTX range名称匹配到的自定义算子将作为框架层算子统计,通过kernel名称匹配到的自定义算子将作为kernel层算子统计。
报告结果示例如下:
Row#,OP Type,Framework OP,Framework Time (%),Library OP,Library Time (%),Kernel Name,Kernel Time (%),Avg (ns),Instances,
1,"MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"DeepGemm:GroupedNoPad,data_type:bf16,groups:128,m:64,n:768,k:2048,gpu:0",23.3,"void deep_gemm::batched_gemvt_kernel<__nv_bfloat16, __nv_bfloat16, float, int4, int4, 256, 32, 2, 2, 2>(deep_gemm::GemvtArgs)",23.3,55495,28128,
2,"MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"DeepGemm:GroupedNoPad,data_type:bf16,groups:128,m:64,n:2048,k:384,gpu:0",13.0,"void deep_gemm::batched_gemvt_kernel<__nv_bfloat16, __nv_bfloat16, float, int4, int4, 256, 8, 4, 1, 1>(deep_gemm::GemvtArgs)",13.0,30975,28128,
3,"MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"Native",7.3,"_fwd_kernel_ep_gather",2.3,17378,28128,
4,"MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"Native",7.3,"_fwd_kernel_ep_scatter_2_optimal",1.1,17378,28128,
...Tips:建议使用选项--format xlsx输出电子表格,统计结果更加易读。
2.3.29 PPU算子性能分解
识别asysrep报告中的PPU算子,根据算子的种类和嵌套关系,将算子分为框架层、加速库层和kernel层三个层级,将性能数据逐级分解到加速库层,输出加速库层级的性能分解信息和设备利用率信息。
依赖的asys采集选项:
--trace hggc,hgtx
Tips:在采集asysrep报告前,建议使能PPU算子HGTX range标注相关功能:
执行
export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能基础框架PPU算子HGTX range标注功能。asys添加选项
--pytorch autograd-shapes-hgtx,使能pytorch算子HGTX range标注功能。
统计规则
根据HGTX标记和kernel名称识别各个层级的算子,根据算子在PPU上的投影时间范围确定算子之间的嵌套关系。
PPU算子被分为框架层、加速库层和kernel层三个层级,部分层级可能不存在PPU算子信息。以自顶向下的顺序查看算子的嵌套关系,处于嵌套顶层的算子(无论其归属哪个层级)为顶层算子。
PPU算子汇总的Total Time的计算方式为:
所有
顶层算子的执行时间的累加
每种PPU算子的时间占比的计算方式为:
累加本PPU算子的执行时间,得到
执行时间汇总。计算
执行时间汇总/Total Time,得到本PPU算子的时间占比。
父一级PPU算子范围内,未存在子一级PPU算子的时间范围(PPU设备空闲),被标记为Idle。各个层级中缺失的父一级PPU算子被标记为Native。
汇总结果组织如下:
每框架层算子、每加速库层算子,按照逐层的时间占比降序排列。
ppu_op_breakdown表格列说明如下:
Row# : Row number of the PPU operator breakdown
OP Type : PPU operator type
Framework OP : Name of the framework layer operator
Framework Time [%] : Framework operator time percentage of 'Total Time'
Framework Avg [ns] : Average duration of this framework operator
Framework Instances : Number of this framework operator
Library OP : Name of the compute library layer operator
Library Time [%] : Library operator time percentage of 'Total Time'
Library Avg [ns] : Average duration of this library operator
Library Instances : Number of this library operator
Compute Util [%] : Utilization ratio of PPU compute capability
HBM Load Util [%] : Utilization ratio of PPU HBM load bandwidth
HBM Store Util [%] : Utilization ratio of PPU HBM store bandwidth命令行使用方法
asys stats -r ppu_op_breakdown report.asysrep可通过asys stats --help-report ppu_op_breakdown查看具体帮助信息,支持的选项列举如下:
rows=<limit>:限制输出结果的条数,部分占比较小的算子将会被忽略。
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。op=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过
/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果中体现。order-by=<order_type>:指定输出结果排序方式,默认按照算子时间占比排序。
no-merge-flash-attention-prefill-decode-operator:若指定,不再匹配和合并prefill和decode的flash attention算子。
no-merge-flash-attention-parameter:若指定,不再忽略flash attention算子对性能影响较小的参数差异。
no-merge-communication-parameter:若指定,不再忽略通信算子对性能影响较小的参数差异。
no-merge-moe-parameter:若指定,不再忽略MoE算子对性能影响较小的参数差异。
no-merge-pytorch-parameter:若指定,不再忽略pytorch算子对性能影响较小的参数差异。
no-merge-gemm-parameter:若指定,不再忽略GEMM算子对性能影响较小的参数差异。
可通过--ppu-op-config选项自定义算子识别规则,通过HGTX range名称匹配到的自定义算子将作为框架层算子统计,通过kernel名称匹配到的自定义算子将作为kernel层算子统计。
报告结果示例如下(部分列未展示):
Row#,OP Type,Framework OP,Framework Time (%),Library OP,Library Time (%),Library Avg (ns),Library Instances,Compute Util (%),HBM Load Util (%),HBM Store Util (%),
1,"MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"DeepGemm:GroupedNoPad,data_type:bf16,groups:128,m:64,n:768,k:2048,gpu:0",23.3,55495,28128,2.6,262.6,0.0,
2,"MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"DeepGemm:GroupedNoPad,data_type:bf16,groups:128,m:64,n:2048,k:384,gpu:0",13.0,30975,28128,2.3,235.1,0.0,
3,"MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"Native",7.3,2482,196896,"-","-","-",
4,"MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"Idle",0.7,1681,28128,"-","-","-",
...2.3.30 PPU算子单元测试(实验特性)
将asysrep报告中的PPU算子按照类型和参数取值进行分组和分组,对汇总结果的每种PPU算子生成单元测试代码。
依赖的asys采集选项:
--trace hggc,hgtx--pytorch=dispatch-function
注意:--pytorch=dispatch-function选项为实验特性,使能此选项可能导致应用崩溃或者应用行为异常。
统计规则
PPU算子的执行时间统计方式为:
每个PPU算子在PPU侧的执行时间为:本算子关联的PPU侧第一个活动开始,到最后一个活动结束的持续时间。
PPU算子的执行信息汇总时,若两个PPU算子之间大部分参数相同,仅少量对应能影响较小的参数差异,默认会忽略参数差异,按照相同的PPU算子合并汇总。
汇总结果组织如下:每PPU算子参数组合(默认忽略性能影响较小的参数差异),汇总每个算子的执行时间信息,结果按照Total Time列降序逐个生成单元测试代码。
注意:部分算子不支持生成单元测试代码,所有PPU算子汇总的单元测试名称在报告尾部列出。
命令行使用方法
asys stats -r ppu_op_unit_test report.asysrep可通过asys stats --help-report ppu_op_unit_test查看具体帮助信息,支持的部分选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。op=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过
/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果。no-merge-pytorch-parameter:若指定,不再忽略pytorch算子对性能影响较小的参数差异。
运行生成的单元测试示例如下,默认运行所有的单元测试各一次,可通过选项控制运行的用例和次数:
python report_ppu_op_unit_test.py --top 3 --warm-up 5 --repeat 5--top 3:运行总耗时占比前3的算子的测试用例。--warm-up 5:计时之前运行5次。--repeat 5:计时阶段运行5次计算平均耗时。支持
--test选项指定测试用例名称,多个用例名称通过,分隔。
3. 比较两个报告
3.1 从GUI端使用报告比较视图
与统计系统类似,在GUI中,可以通过下方tab中的“Comparison View”切换到报告比较视图。报告比较视图如下所示:
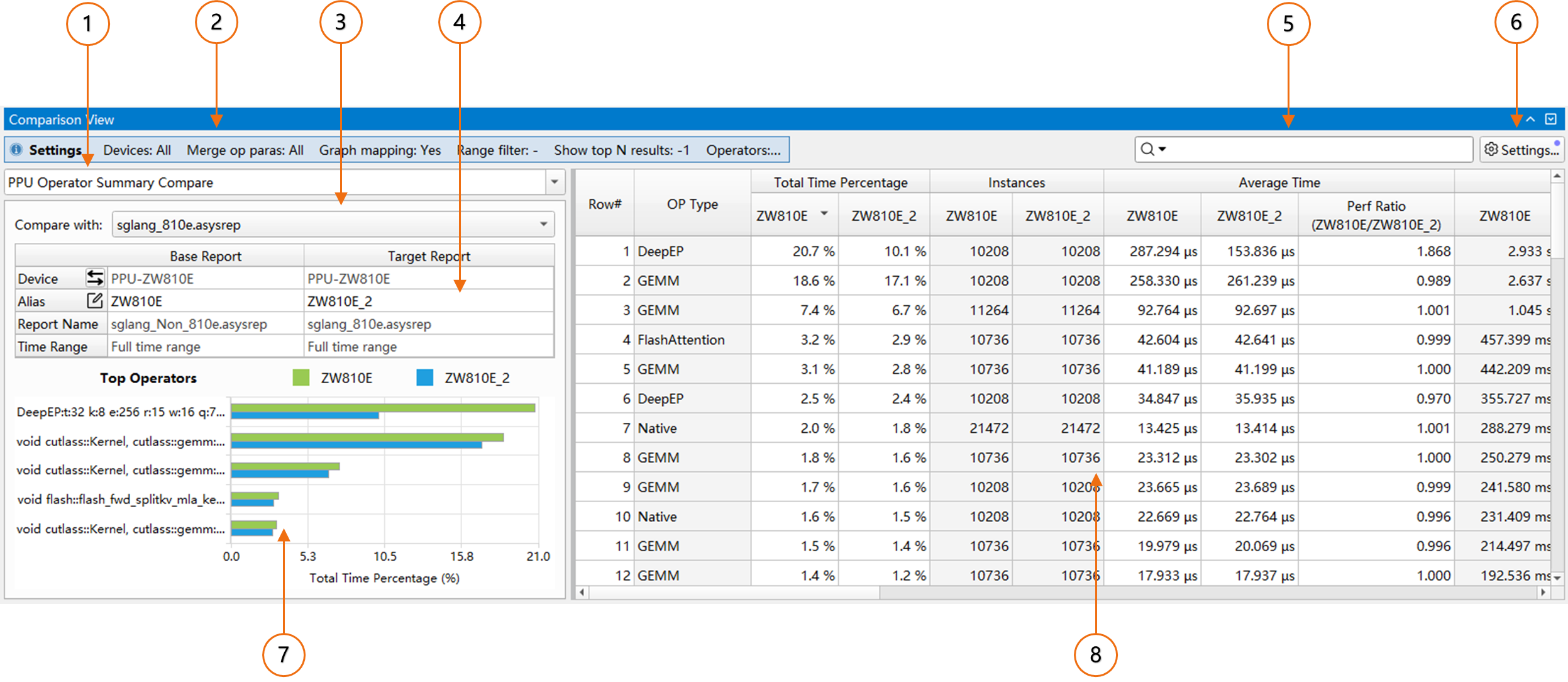
规则列表,可以在此选择统计规则,支持搜索。
当前生效侧参数配置,鼠标悬停时会显示参数的详细信息。
对比报告选择框,在这里选择已经打开的另一个asys报告作为对比的目标报告。
报告对比信息,给出了base和target报告的设备名、别名、报告名、统计区间等信息。同时提供交换base/target报告、更改报告别名的功能。
搜索框,支持搜索和过滤两种模式。
规则参数配置对话框,可以在此改变当前统计规则的配置。
热点柱状图,展示base和target报告的性能热点。
报告对比统计结果表格,显示当前规则的报告对比结果,可以通过右键菜单导出分析结果。
设置统计区间
报告对比功能支持为两个进行对比的报告分别设置参与统计的时间区间,在进行报告对比时只会对选定时间区间内的事件进行统计。打开需要设置统计区间的报告,在Timeline View中按住鼠标左键拖动,在选定的区间内打开右键菜单,点击“Filter and Zoom in”,即可为当前报告设置统计区间。
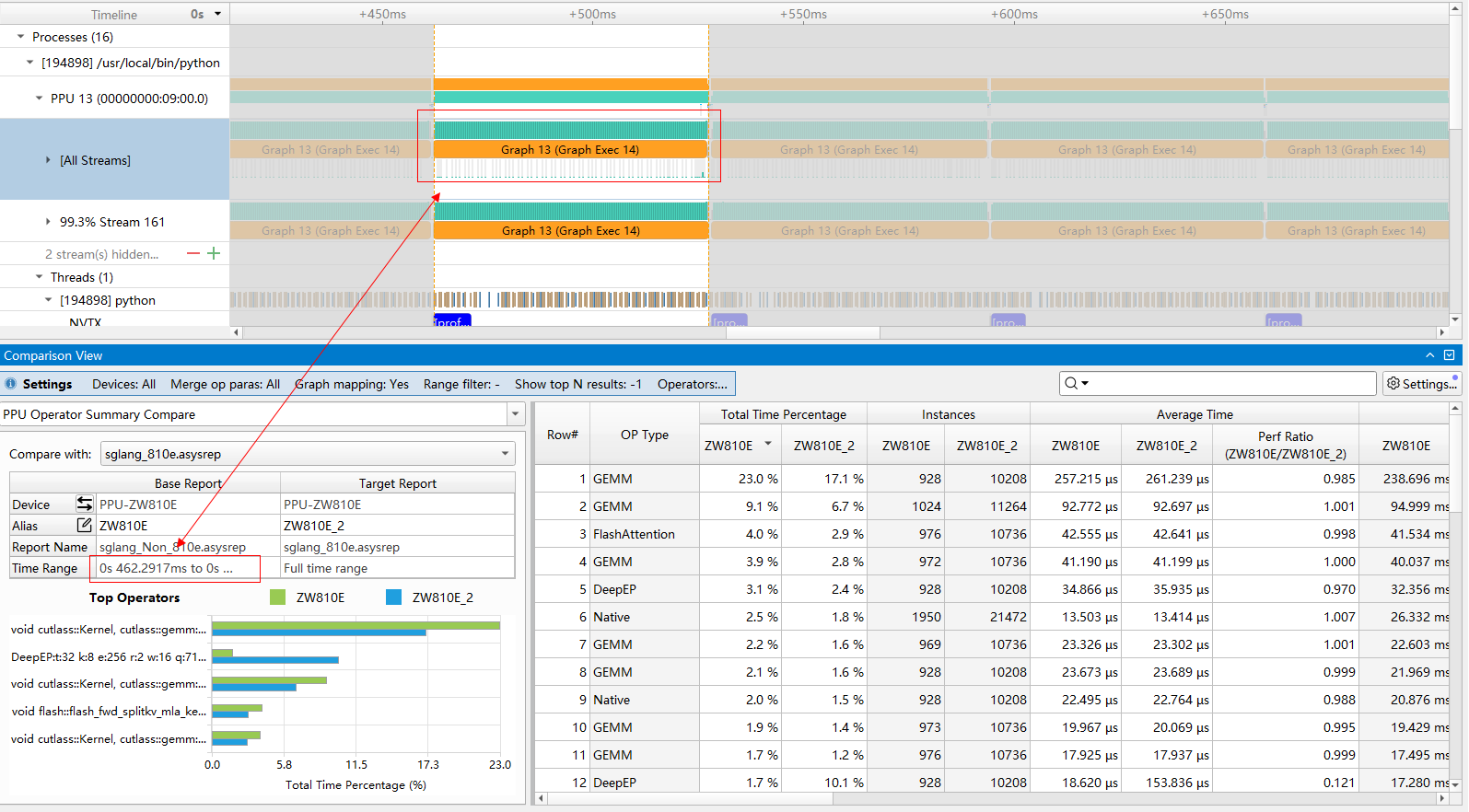
对比报告选择框和对比信息
通过顶部的“Compare with”选择框,可以选择另一个已经打开的asys报告作为target报告,与当前报告进行对比。完成了选择target报告后,下方会显示一个对比信息表格,给出了base报告和target报告的设备名、别名、报告名、统计区间等信息。
在对比信息表格中:
“Device”右侧,有一个交换按钮,点击后base报告和target报告会相互交换。
“Alias”行是可编辑的,双击这一行的单元格,可以为报告起一个别名,这个别名会显示在热点柱状图的图例和右侧对比结果表格的表头中。
“Time Range”表示当前报告的统计区间,默认会统计整个报告的时间区间。可以在对应的报告中选择一个时间区间并“Filter and Zoom in”来应用一个新的统计区间。
热点柱状图
热点柱状图会展示当前报告对比统计结果中,base和target报告中的性能热点,从上到下降序排序。可以通过增加“Comparison View”的高度,使得热点柱状图中显示更多的热点行。
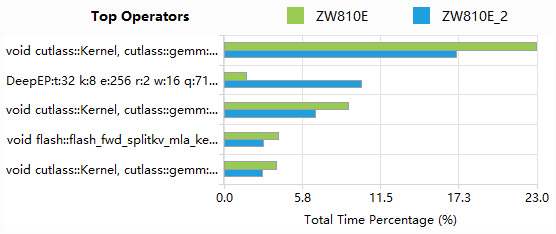
上图中:
图题,表示柱状图展示的热点内容。
图例,用不同颜色区分两个对比的报告,并显示两个报告的别名。
纵轴,如上图展示的是各个热点算子,排序依据是根据算子在两个报告中的占比较大值进行降序排序。点击任意一个数据柱,可以跳转至对比结果表格中的对应行。
横轴,表示评估热点的指标,如上图是根据占报告总时间的比率来排序热点算子。
报告对比统计结果表格
该表格展示了各个性能参数指标在两个对比报告中的数值。
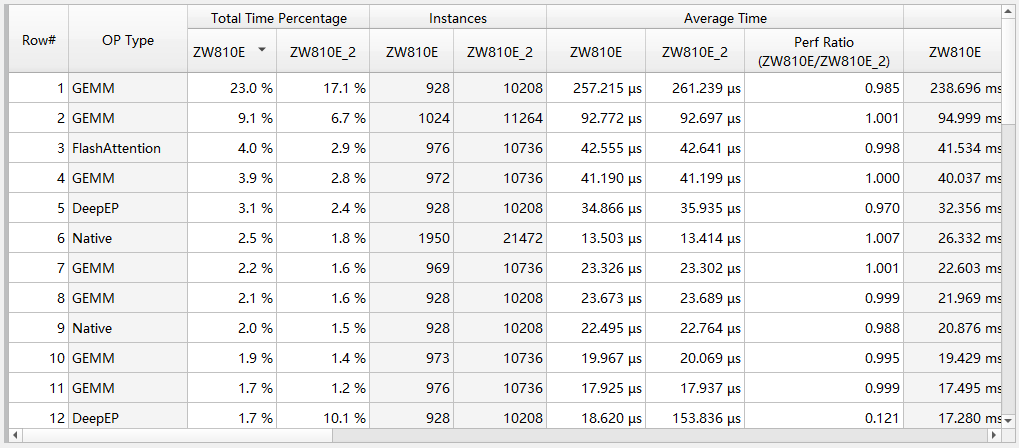
部分性能指标给出了Perf Ratio,表示target报告相比base报告的性能表现,
Perf Ratio > 1.0表示target报告在该性能指标上优于base报告,反之则表示base报告性能更优。部分单元格显示的值为“-”,表示当前列所在的报告没有对应的匹配项。
可以点击任意列的表头对表格进行排序,点击右键可以将整个表格导出为csv文件。
报告对比自定义配置
在右上角的“Settings”按钮中,可以对报告对比进行一些配置,每个对比规则支持的配置项不完全相同。这里列举一些报告对比中比较有用的配置项进行介绍:
自定义算子解析配置
比较系统还支持自定义算子的解析方式,例如添加SpecialGemm算子类型:
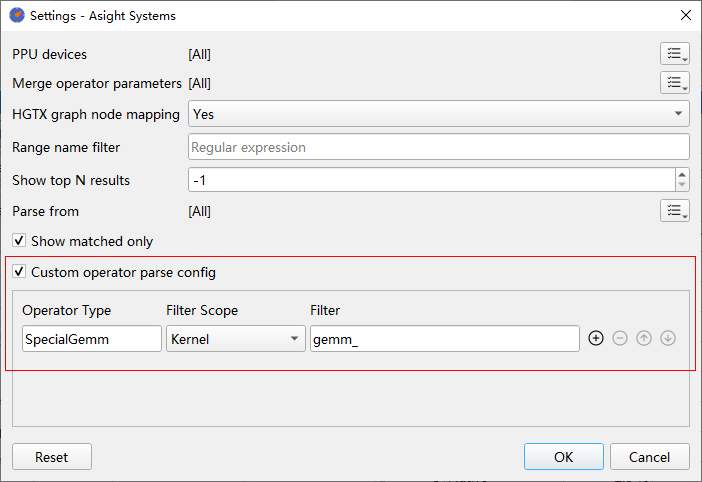
配置完成后,结果如下所示:
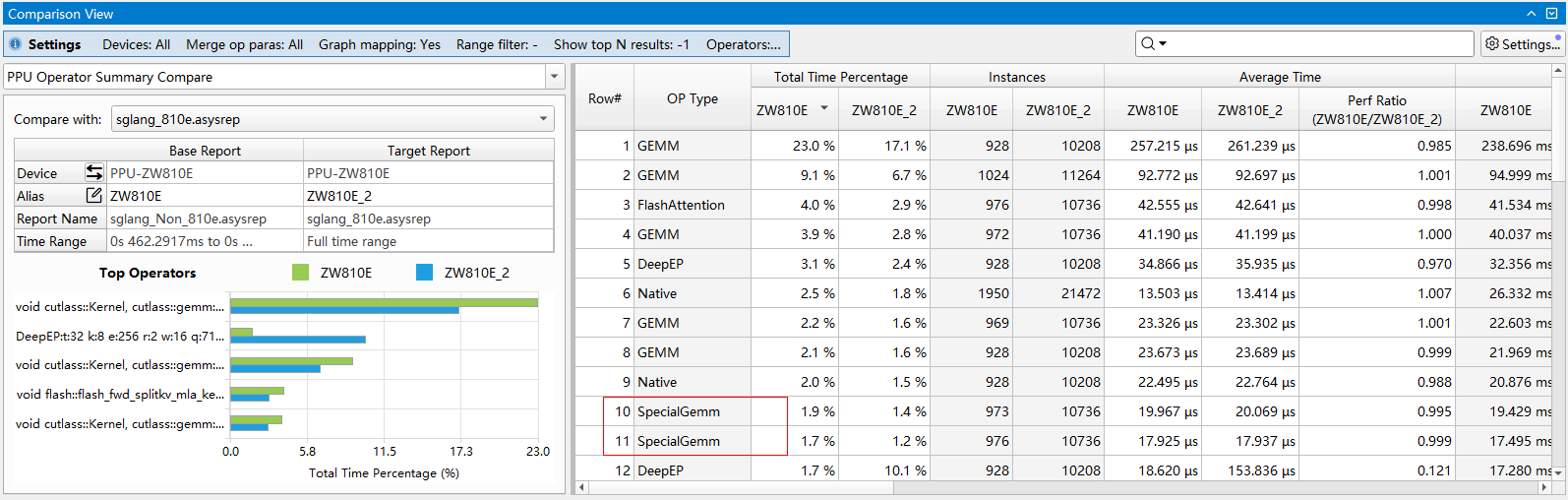
注意:自定义的算子解析优先级高于asys预置的解析。
仅展示有效匹配的结果
在对比结果表格中,有部分行是只有base报告中有,target报告中没有的未成功匹配的结果,如下图方框中所示。若只想看匹配成功的结果,可以勾选“Show matched only”选项,即可过滤掉未成功匹配的结果。
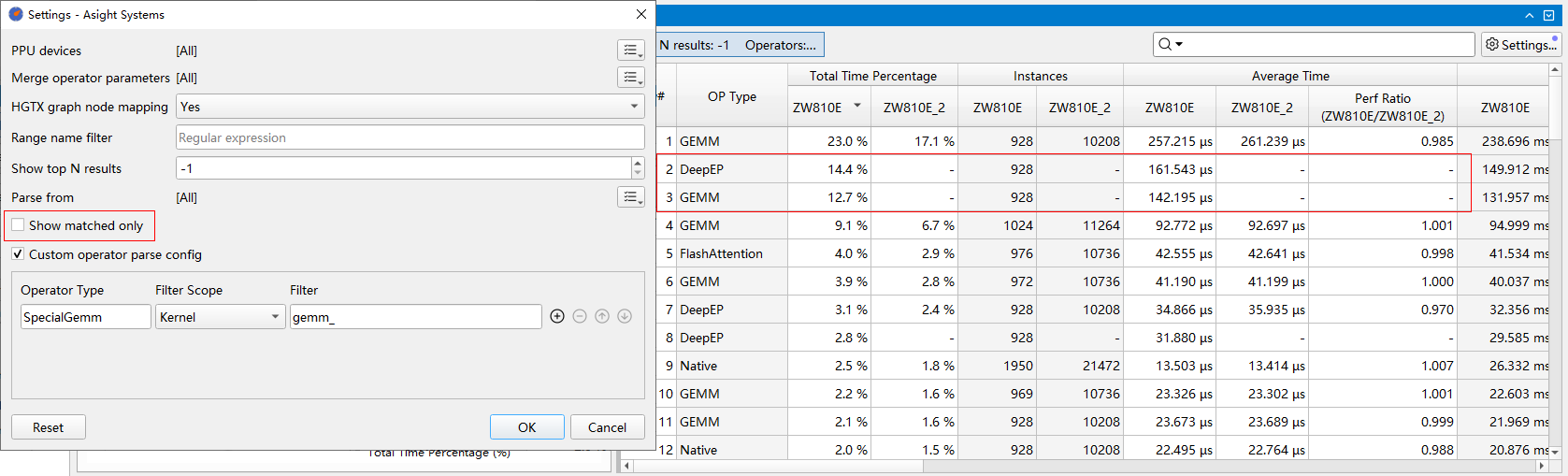
3.2 从命令行端比较报告
可使用asys compare子命令比较两个asysrep报告文件,asys compare子命令是asys stats子命令的简化形式,支持显示简要的比较结果,并输出详细汇总数据到csv文件,使用示例如下:
asys compare -f true report1.asysrep report2.asysrep-f true:允许输出的比较结果文件覆盖已存在的文件。
可执行asys compare -h查看更多帮助信息。
asys compare子命令默认执行的比较规则示例如下:
PPU算子类型汇总比较(ppu_operator_type_summary_compare)
PPU时间利用率比较(ppu_time_util_compare)
PPU算子汇总比较(ppu_operator_summary_compare)
PPU算子kernel性能分解(ppu_operator_kernel_breakdown_compare)
PCCL不同步汇总比较(pccl_desync_summary_compare)
PPU kernel汇总比较(ppu_kernel_summary_compare)
指定统计时间范围
可通过--filter-hgtx选项通过HGTX标注指定统计的时间范围,两个报告中都将使用指定的HGTX确定统计时间范围。
使用--filter-hgtx选项可指定匹配的HGTX range的名称、domain和匹配索引,格式为range_name@domain/index,若匹配的HGTX range不存在domain,则@domain可省略,否则@domain需要指定。
默认asys将使用匹配的第一个HGTX range作为统计的时间范围,此时/index部分可省略,若需要指定匹配索引,则通过/index指定,索引从0开始。
例如:使用名称为self_attention的HGTX range指定统计时间范围,无domain,使用首个匹配的HGTX range的时间范围。
asys compare --filter-hgtx self_attention report1.asysrep report2.asysrep例如:使用名称为pcclGroupEnd的HGTX range指定统计时间范围,domain为NCCL,使用第9个匹配的HGTX range的时间范围(索引为8)。
asys compare --filter-hgtx "pcclGroupEnd@NCCL/8" report1.asysrep report2.asysrep指定报告输出文件
asys compare将输出精简的比较结果到控制台,并输出详细的比较结果到csv文件。
通过--output选项可指定输出文件名称的前缀,指定的名称为文件输出的目录和文件名前缀的组合,格式为<output_dir>/<prefix>。前缀可以为空,路径最后一个/之前的路径被认为是输出目录。若未通过--output指定,asys将会根据asysrep报告文件名和统计报告类型生成文件名称。
例如:指定--output /test/mytest,在目录/test生成各类对比报告,例如mytest_ppu_operator_summary_compare.csv、mytest_ppu_kernel_summary_compare等:
asys compare -f true --output /test/mytest report1.asysrep report2.asysrep-f true:允许输出的比较结果文件覆盖已存在的文件--output /test/mytest:在/test目录生成对比报告,报告文件名称前缀mytest
指定算子识别规则
asys compare的对比结果中包含PPU算子相关对比,通过内置的PPU算子识别规则识别报告中的算子并比较相关性能,可通过--ppu-op-config选项自定义算子识别规则,可指定正则表达式通过匹配HGTX range名称或者kernel名称识别指定算子类型,格式为算子类型=匹配类型:过滤规则,可多次通过--ppu-op-config选项创建多个算子识别规则,例如:
asys compare --ppu-op-config GEMM=kernel:gemv --ppu-op-config Pytorch=hgtx:aten report1.asysrep report2.asysrep--ppu-op-config GEMM=kernel:gemv:匹配kernel名称包含gemv关键字的kernel,分类到GEMM算子类型。--ppu-op-config Pytorch=hgtx:aten:匹配HGTX range名称包含aten关键字,HGTX range关联的PPU活动分类到Pytorch算子类型。
3.3 报告比较规则
PPU kernel汇总比较
比较两个asysrep报告中的PPU kernel汇总结果,匹配和比较两个报告中的PPU kernel耗时差异。
依赖的asys采集选项:
--trace hggc
统计规则
对每个asysrep报告,计算HGGC PPU kernel汇总,按照每HGGC kernel名称进行统计。通过HGGC kernel名称匹配两个asysrep汇总结果的kernel信息,按照每个报告的HGGC kernel总耗时降序输出。HGGC kernel名称取决于base / mangled选项是否设置,默认为demangle后kernel名称(包含函数参数列表)。
ppu_kernel_summary_compare表格列说明如下,比较结果通过/分隔,未匹配的列通过-表示:
Row# : Row number of the compare result
Device Name : PPU Device name
Instances : Number of calls to this kernel
Percent [%] : Percentage of 'Total' time
Avg [ns] : Average execution time of this kernel
Avg Ratio : Target average execution time compared to base
Total [ns] : Total time used by all executions of this kernel
Total Ratio : Target total execution time compared to base
Base Kernel : Name of the kernel in base report
Target Kernel : Name of the kernel in target report命令行使用方法
使用asys stats传入两个asysrep报告进行比较:
asys stats -r ppu_kernel_summary_compare base_report.asysrep target_report.asysrep可通过asys stats --help-report ppu_kernel_summary_compare查看具体帮助信息,支持的选项列举如下:
hgtx-name:kernel名字前通过/拼接最接近kernel launch的HGTX range名称。
base:使用kernel的短名称(仅函数名,不包含参数)进行统计和输出。
mangled:使用kernel的mangled名称进行统计和输出。
device:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。
报告结果示例如下:
Row#,Device Name,Instances,Percent (%),Avg (ns),Avg Ratio,Total (ns),Total Ratio,Base Kernel,Target Kernel,
1,"ZW-M890P / PPU-ZW810E","3781 / 4016","1.9 / 0.4","13806 / 7021",2.0,"52200644 / 28196837",1.9,"void vllm::act_and_mul_kernel<c10::BFloat16, &(c10::BFloat16 vllm::silu_kernel<c10::BFloat16>(c10::BFloat16 const&)), true>(c10::BFloat16*, c10::BFloat16 const*, int)","void vllm::act_and_mul_kernel<c10::BFloat16, &(c10::BFloat16 vllm::silu_kernel<c10::BFloat16>(c10::BFloat16 const&)), true>(c10::BFloat16*, c10::BFloat16 const*, int)",
2,"ZW-M890P / PPU-ZW810E","78 / 83","1.2 / 0.3","425945 / 276146",1.5,"33223717 / 22920188",1.4,"void at::native::(anonymous namespace)::cunn_SoftMaxForward<4, float, float, float, at::native::(anonymous namespace)::SoftMaxForwardEpilogue>(float*, float const*, int)","void at::native::(anonymous namespace)::cunn_SoftMaxForward<4, float, float, float, at::native::(anonymous namespace)::SoftMaxForwardEpilogue>(float*, float const*, int)",
...GUI使用指南
规则设置(Settings)
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)
Mangled:导出kernel的mangled名称
Demangled:导出kernel的demangle之后的名称(默认值)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Show top N results:展示前N条结果,默认为“-1”,即不限制展示结果条数。在报告对比时,会展示两个报告各自的前N条结果。
Add HGTX name as a prefix:使能名字前拼接最接近kernel launch的HGTX名称,通过
/间隔。默认不勾选。Show matched kernels only:使能后仅展示base和target报告中都包含的成功匹配kernels,即会隐藏所有包含无效结果“-”的行。默认不使能。
HGTX向PPU投影汇总比较
比较两个asysrep报告中的HGTX range向PPU侧投影的汇总结果,匹配和比较两个报告中的HGTX range PPU投影汇总的执行时间差异。
依赖的asys采集选项:
--trace hgtx,hggc
统计规则
对每个asysrep报告,计算HGTX向PPU投影汇总,每个HGTX range判断关联的PPU活动的原则为:
CPU侧的HGTX range覆盖了PPU活动对应的HGGC API。
CPU侧的HGTX range覆盖了PPU活动所在HGGC graph node的创建API。
HGTX range在PPU侧的投影时间,从本HGTX关联的最早的PPU活动开始,到最晚的PPU活动结束。
HGTX range在PPU侧的总的活跃时间Proj Active Time计算方式为:指定的时间点存在一个或者更多HGTX range投影,则记为活跃时间。如果多个HGTX range的投影在时间上重叠,重叠的部分不会被多次计入活跃时间。
HGTX range投影的PPU侧占比In-Use计算方式为:Proj Active Time/ PPU侧统计时间范围,其中PPU侧统计时间范围计算方式取决于range-mode选项。
对每个asysrep报告,按照相同HGTX range汇总PPU侧的投影时间信息。通过HGTX range匹配两个asysrep汇总结果的投影信息,按照每个报告的In-Use降序排列。
hgtx_ppu_projection_summary_compare表格列说明如下,比较结果通过/分隔,未匹配的列通过-表示:
Row# : Row number of the compare result
Device Name : PPU Device name
In-Use [%] : Percentage of projected active time to time range
Range Instance : Number of instances of this range
Proj Avg [ns] : Average projected time for this range
Proj Avg Ratio : Target average projected time compared to base
Proj Active Time [ns] : Total projected time excluding overlapping for this range name
Proj Active Ratio : Target total projected time excluding overlapping compared to base
Total Proj Time [ns] : Total projected time used by all instances of this range name
Total Proj Ratio : Target total projected time compared to base
Total Range Time [ns] : Total original HGTX range time used by all instances of this range name
Total Range Ratio : Target total original HGTX range time compared to base
Base Range : Name of the HGTX range in base report
Target Range : Name of the HGTX range in target report命令行使用方法
使用asys stats传入两个asysrep报告进行比较:
asys stats -r hgtx_ppu_projection_summary_compare base_report.asysrep target_report.asysrep可通过asys stats --help-report hgtx_ppu_projection_summary_compare查看具体帮助信息,支持的选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过/分割。若不指定,默认统计所有PPU device。range-mode=<mode>:PPU侧统计时间范围的选择模式,支持active和full模式。active:默认模式,时间范围从第一个PPU活动开始,到最后一个PPU活动结束截止。
full:时间范围选取为用户指定的统计时间范围,若没有指定统计时间范围,则统计报告整体的时间范围。
range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过/分割。若不指定,默认统计所有HGTX range。no-graph-mapping:导出结果不包含通过HGGC graph node映射的HGTX range信息。
报告结果示例如下:
Row#,Device Name,In-Use (%),Range Instance,Proj Avg (ns),Proj Avg Ratio,Proj Active Time (ns),Proj Active Ratio,Total Proj Time (ns),Total Proj Ratio,Total Range Time (ns),Total Range Ratio,Base Range,Target Range,
1,"PPU-ZW810 / PPU-ZW610","24.7 / 19.4","1 / 1","107599873 / 61168391",0.6,"107599873 / 61168391",0.6,"107599873 / 61168391",0.6,"108253331 / 62298650",0.6,"[prof_range]: iter 7","[prof_range]: iter 7",
2,"PPU-ZW810 / PPU-ZW610","3.0 / 4.6","4 / 5","3307076 / 2890162",0.9,"13228306 / 14450814",1.1,"13228306 / 14450814",1.1,"4966272 / 1315786",0.3,"DALI:[DALI][Executor] RunMixed","DALI:[DALI][Executor] RunMixed",
...GUI使用指南
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Time Range Mode:设置统计时间范围的模式:
PPU Active Time Range:默认模式,时间范围从第一个PPU活动开始,到最后一个PPU活动结束截止。Filtered Time Range:时间范围选取为用户指定的统计时间范围,若没有指定统计时间范围,则统计报告整体的时间范围。
HGTX graph node mapping:是否投影HGGC graph capture阶段HGTX到PPU侧(通过在HGTX range范围内创建的HGGC graph node建立与PPU侧到关联)。默认值为“Yes”。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置。
Show matched only:使能后仅展示base和target报告中都包含的成功匹配结果,即会隐藏所有包含无效结果“-”的行。默认不使能。
PPU算子汇总比较
比较两个asysrep报告中的PPU算子汇总结果,匹配和比较两个报告中的PPU算子执行时间差异。
依赖的asys采集选项:
--trace hggc,hgtx
Tips:在采集asysrep报告前,建议使能PPU算子HGTX range标注相关功能:
执行
export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能基础框架PPU算子HGTX range标注功能。asys添加选项
--pytorch autograd-shapes-hgtx,使能pytorch算子HGTX range标注功能。
统计规则
对每个asysrep报告,计算PPU算子汇总,汇总统计PPU算子的执行时间,PPU算子的执行时间统计方式为:
每个PPU算子在PPU侧的执行时间为:本算子关联的PPU侧第一个活动开始,到最后一个活动结束的持续时间。
PPU算子的PPU活跃时间PPU Active Time计算方式为:
指定的时间点存在一个或者多个本PPU算子关联的PPU活动,则记为活跃时间。如果多个PPU活动在时间上重叠,重叠的部分不会被多次计入活跃时间。
PPU算子的执行信息汇总时,若两个PPU算子之间大部分参数相同,仅少量对应能影响较小的参数差异,默认会忽略参数差异,按照相同的PPU算子合并汇总。
通过PPU算子类型和PPU算子参数匹配两个asysrep报告的算子汇总结果,按照每个报告的算子占比降序输出。
ppu_operator_summary_compare表格列说明如下,比较结果通过/分隔,未匹配的列通过-表示:
Row# : Row number of the compare result
Device Name : PPU Device name
OP Type : PPU operator type
Percent [%] : Percentage of 'Total Time'
Instances : Number of this PPU operator
Avg [ns] : Average execution time of this operator's kernel
Avg Ratio : Target average time compared to base
Total [ns] : Total time used by all kernel instances of this operator
Total Ratio : Target total time compared to base
Active [ns] : Total PPU active time excluding overlapping for this operator
Active Ratio : Target active time compared to base
Compute Util [%] : Utilization ratio of PPU compute capability
HBM Load Util [%] : Utilization ratio of PPU HBM load bandwidth
HBM Store Util [%] : Utilization ratio of PPU HBM store bandwidth
Base OP Name : Name of the PPU operator in base report
Target OP Name : Name of the PPU operator in target report命令行使用方法
使用asys stats传入两个asysrep报告进行比较:
asys stats -r ppu_operator_summary_compare base_report.asysrep target_report.asysrep可通过asys stats --help-report ppu_operator_summary_compare查看具体帮助信息,支持的选项列举如下:
top=<limit>:仅比较每个报告top N占比的算子。
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。op=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过
/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果中体现。order-by=<order_type>:指定输出结果排序方式,默认按照算子时间占比排序。
no-graph-mapping:若指定,不再映射HGGC graph创建阶段的HGTX到HGGC graph执行阶段。
no-merge-flash-attention-prefill-decode-operator:若指定,不再匹配和合并prefill和decode的flash attention算子。
no-merge-flash-attention-parameter:若指定,不再忽略flash attention算子对性能影响较小的参数差异。
no-merge-communication-parameter:若指定,不再忽略通信算子对性能影响较小的参数差异。
no-merge-moe-parameter:若指定,不再忽略MoE算子对性能影响较小的参数差异。
no-merge-pytorch-parameter:若指定,不再忽略pytorch算子对性能影响较小的参数差异。
no-merge-gemm-parameter:若指定,不再忽略GEMM算子对性能影响较小的参数差异。
通过--ppu-op-config选项自定义算子识别规则,可指定正则表达式通过匹配HGTX range名称或者kernel名称识别指定算子类型,格式为算子类型=匹配类型:过滤规则,可多次通过--ppu-op-config选项创建多个算子识别规则,例如:
--ppu-op-config GEMM=kernel:gemv --ppu-op-config Pytorch=hgtx:aten--ppu-op-config GEMM=kernel:gemv:匹配kernel名称包含gemv关键字的kernel,分类到GEMM算子类型。--ppu-op-config Pytorch=hgtx:aten:匹配HGTX range名称包含aten关键字,HGTX range关联的PPU活动分类到Pytorch算子类型。
报告结果示例如下:
Row#,Device Name,OP Type,Percent (%),Instances,Avg (ns),Avg Ratio,Total (ns),Total Ratio,Active (ns),Active Ratio,Compute Util (%),HBM Load Util (%),HBM Store Util (%),Base OP Name,Target OP Name,
1,"ZW-M890P / PPU-ZW810E","GEMM","2.1 / 0.5","3396 / 3632","17988 / 9057",2.0,"61089747 / 32897426",1.9,"60114246 / 32328985",1.9,"1.3 / 8.0","2.7 / 5.2","0.0 / 0.0","ACBLAS:GemmEx,t,n,128,192,2048,2048,2048,128,1,0,1,DEFAULT,BF16,ACBLAS_GEMM_DEFAULT_TENSOR_OP,32F,EPILOGUE_DEFAULT","ACBLAS:GemmEx,t,n,128,192,2048,2048,2048,128,1,0,1,DEFAULT,BF16,ACBLAS_GEMM_DEFAULT_TENSOR_OP,32F,EPILOGUE_DEFAULT",
2,"ZW-M890P / PPU-ZW810E","PCCL","1.1 / 0.3","194 / 194","160435 / 109407",1.5,"31124497 / 21225020",1.5,"31124497 / 21225020",1.5,"- / -","- / -","- / -","AllReduce, p:0, c:2347008, d:9, r:1, w:2, h:7dda1c67c65a5e44, t:1, b:0x469000000/0x46947a000","AllReduce, p:0, c:2347008, d:9, r:1, w:2, h:b2268f5abee7947e, t:1, b:0x497800000/0x497c7a000",
...GUI使用指南
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Merge operator parameters:忽略对算子对性能影响较小的参数差异,将其合并统计。默认对所有类型的算子都启用。
HGTX graph node mapping:是否投影HGGC graph capture阶段HGTX到PPU侧(通过在HGTX range范围内创建的HGGC graph node建立与PPU侧到关联)。默认值为“Yes”。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置。
Show top N results:展示前N条结果,默认为“-1”,即不限制展示结果条数。在报告对比时,会展示两个报告各自的前N条结果。
Parse from:选择解析算子的来源,所有ppu活动都只能通过使能的算子解析来源尝试进行解析,若解析成功则会纳入算子统计的结果中。默认值为“ALL”,从所有支持的解析来源对ppu活动进行解析,此项不能为空。
Show matched only:使能后仅展示base和target报告中都包含的成功匹配结果,即会隐藏所有包含无效结果“-”的行。默认不使能。
Custom operator parse config:自定义算子解析规则,使能后可以自行添加算子解析规则,通过kernel名或HGTX名+正则表达式匹配,解析出自定义的算子类型。该自定义解析规则优先级高于上面的“Parse from”选项。默认为空。
PPU算子类型汇总比较
比较两个asysrep报告中的PPU算子类型汇总结果,匹配和比较两个报告中的PPU算子类型的执行时间差异。
依赖的asys采集选项:
--trace hggc,hgtx
Tips:在采集asysrep报告前,建议使能PPU算子HGTX range标注相关功能:
执行
export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能基础框架PPU算子HGTX range标注功能。asys添加选项
--pytorch autograd-shapes-hgtx,使能pytorch算子HGTX range标注功能。
统计规则
对每个asysrep报告,计算PPU算子类型汇总,汇总统计PPU算子的执行时间,PPU算子的执行时间统计方式为:
每个PPU算子在PPU侧的执行时间为:本算子关联的PPU侧第一个活动开始,到最后一个活动结束的持续时间。
PPU算子的PPU活跃时间PPU Active Time计算方式为:
指定的时间点存在一个或者多个本PPU算子关联的PPU活动,则记为活跃时间。如果多个PPU活动在时间上重叠,重叠的部分不会被多次计入活跃时间。
通过PPU算子类型匹配两个asysrep报告的算子类型汇总结果,按照每个报告的算子类型占比降序排列。固定生成Summary类型的汇总行,汇总比较两个报告所有PPU算子类型的执行时间信息和热点算子。
ppu_operator_type_summary_compare表格列说明如下,比较结果通过/分隔,未匹配的列通过-表示:
Row# : Row number of the compare result
Device Name : PPU Device name
OP Type : PPU operator type
Percent [%] : Percentage of 'Total Time'
Instances : Number of this PPU operator
Avg [ns] : Average duration of this operator type
Avg Ratio : Target average duration compared to base
Total [ns] : Total duration used by all instances of this operator type
Total Ratio : Target total time compared to base
PPU Active Time [ns] : Total PPU active time excluding overlapping for this operator type
Active Time Ratio : Target PPU active time compared to base
Top OP Percent [%] : Percentage of top PPU operator of 'Total Time'
Base Top OP Name : Name of the top PPU operator of this type in base report
Target Top OP Name : Name of the top PPU operator of this type in target report命令行使用方法
使用asys stats传入两个asysrep报告进行比较:
asys stats -r ppu_operator_type_summary_compare base_report.asysrep target_report.asysrep可通过asys stats --help-report ppu_operator_type_summary_compare查看具体帮助信息,支持的选项列举如下:
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。op=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过
/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果中体现。no-graph-mapping:若指定,不再映射HGGC graph创建阶段的HGTX到HGGC graph执行阶段。
no-merge-flash-attention-prefill-decode-operator:若指定,不再匹配和合并prefill和decode的flash attention算子。
no-merge-flash-attention-parameter:若指定,不再忽略flash attention算子对性能影响较小的参数差异。
no-merge-communication-parameter:若指定,不再忽略通信算子对性能影响较小的参数差异。
no-merge-moe-parameter:若指定,不再忽略MoE算子对性能影响较小的参数差异。
no-merge-pytorch-parameter:若指定,不再忽略pytorch算子对性能影响较小的参数差异。
no-merge-gemm-parameter:若指定,不再忽略GEMM算子对性能影响较小的参数差异。
可通过--ppu-op-config选项自定义算子识别规则,可指定正则表达式通过匹配HGTX range名称或者kernel名称识别指定算子类型,格式为算子类型=匹配类型:过滤规则,可多次通过--ppu-op-config选项创建多个算子识别规则,例如:
--ppu-op-config GEMM=kernel:gemv --ppu-op-config Pytorch=hgtx:aten--ppu-op-config GEMM=kernel:gemv:匹配kernel名称包含gemv关键字的kernel,分类到GEMM算子类型。--ppu-op-config Pytorch=hgtx:aten:匹配HGTX range名称包含aten关键字,HGTX range关联的PPU活动分类到Pytorch算子类型。
报告结果示例如下:
Row#,Device Name,OP Type,Percent (%),Instances,Avg (ns),Avg Ratio,Total (ns),Total Ratio,PPU Active Time (ns),Active Time Ratio,Top OP Percent (%),Base Top OP Name,Target Top OP Name,
1,"ZW-M890P / PPU-ZW810E","Summary","100.0 / 100.0","84653 / 106815","33908 / 67216",2.0,"2870439050 / 7179687391",2.5,"2802370718 / 7178423429",2.6,"29.6 / 47.3","MoE:M_192_E128_H2048_In768_topk8","void marlin_moe_wna16::Marlin<__nv_bfloat16, 2814749767172868l, 1125899906909960l, 256, 1, 8, 8, false, 4, 8, false>(int4 const*, int4 const*, int4*, int4*, int4 const*, int4 const*, unsigned short const*, int4 const*, int const*, int const*, int const*, int const*, float const*, int, bool, bool, int, int, int, int, int*, bool, bool, bool, int)",
2,"ZW-M890P / PPU-ZW810E","MoE","41.6 / 65.8","7559 / 20081","157975 / 235204",1.5,"1194135831 / 4723135684",4.0,"1128253823 / 4723135684",4.2,"29.6 / 47.3","MoE:M_192_E128_H2048_In768_topk8","void marlin_moe_wna16::Marlin<__nv_bfloat16, 2814749767172868l, 1125899906909960l, 256, 1, 8, 8, false, 4, 8, false>(int4 const*, int4 const*, int4*, int4*, int4 const*, int4 const*, unsigned short const*, int4 const*, int const*, int const*, int const*, int const*, float const*, int, bool, bool, int, int, int, int, int*, bool, bool, bool, int)",
...GUI使用指南
规则设置(Settings)
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Merge operator parameters:忽略对算子对性能影响较小的参数差异,将其合并统计。默认对所有类型的算子都启用。
Range Name Filter:对结果中的HGTX range name进行过滤,采用(Perl兼容的)正则表达式匹配的方式,默认显示所有HGTX range。带有正则表达式语法检查,当输入的正则表达式语法错误时,出现错误提示并且不允许保存设置。
Parse from:选择解析算子的来源,所有ppu活动都只能通过使能的算子解析来源尝试进行解析,若解析成功则会纳入算子统计的结果中。默认值为“ALL”,从所有支持的解析来源对ppu活动进行解析,此项不能为空。
Show matched only:使能后仅展示base和target报告中都包含的成功匹配结果,即会隐藏所有包含无效结果“-”的行。默认不使能。
Custom operator parse config:自定义算子解析规则,使能后可以自行添加算子解析规则,通过kernel名或HGTX名+正则表达式匹配,解析出自定义的算子类型。该自定义解析规则优先级高于上面的“Parse from”选项。默认为空。
PCCL不同步汇总比较
比较两个asysrep报告中的PCCL不同步汇总结果,匹配和比较两个报告中的PCCL kernel通信组的不同步占比。
依赖的asys采集选项:
--trace hggc
统计规则
对每个asysrep报告,计算PCCL不同步汇总,将执行时间上存在重叠的PCCL kernel分入一个通信组,对每个通信组的所有kernel计算如下时间:
重叠时间:本通信组内所有PCCL kernel重叠的时间。持续时间:从本通信组第一个kernel开始执行到最后一个kernel停止执行的时间。
不同步比例计算方式为:(持续时间 - 重叠时间) / 持续时间。
Desync P90列的计算方法为:将相同kernel名称的通信组统计结果根据不同步率升序排列,获取第90百分位的不同步率,本数值表示大部分PCCL通信不同步率优于此结果。
通过kernel名称匹配两个asysrep报告的汇总结果,按照每个报告的通信组耗时占比降序输出。
pccl_desync_summary_compare表格列说明如下,比较结果通过/分隔,未匹配的列通过-表示:
Row# : Row number of the compare result
Device Name : PPU Device name
Time [%] : Percentage of 'Total Duration'
Count : Number of communication of this PCCL kernel
Desync P90 [%] : 90th percentile desynchronization rate of this PCCL kernel
Desync Avg [%] : Average desynchronization rate of this PCCL kernel
Total Duration [ns] : Total elapsed duration of all communication of this PCCL kernel
Total Overlap [ns] : Total overlap duration of all communication of this PCCL kernel
Base Kernel : Name of the kernel in base report
Target Kernel : Name of the kernel in target report命令行使用方法
使用asys stats传入两个asysrep报告进行比较:
asys stats -r pccl_desync_summary_compare base_report.asysrep target_report.asysrep可通过asys stats --help-report pccl_desync_summary_compare查看具体帮助信息,支持的选项列举如下:
hgtx-name:kernel名字前通过
/拼接最接近kernel launch的HGTX range名称。base:使用kernel的短名称(仅函数名,不包含参数)进行统计和输出。
mangled:使用kernel的mangled名称进行统计和输出。
device:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。
报告结果示例如下:
Row#,Device Name,Time (%),Count,Desync P90 (%),Desync Avg (%),Total Duration (ns),Total Overlap (ns),Base Kernel,Target Kernel,
1,"ZW-M890P / PPU-ZW810E","48.5 / 59.3","3294 / 3592","30.4 / 42.1","14.0 / 21.8","79985018 / 83745513","65187134 / 57385652","void pcclKernel_oneShotAllReduceKernel<__ppu_bfloat16, 2, 0, 1, 1>(oneShotDevParams)","void pcclKernel_oneShotAllReduceKernel<__ppu_bfloat16, 2, 0, 1, 1>(oneShotDevParams)",
2,"ZW-M890P / PPU-ZW810E","42.0 / 29.0","381 / 388","75.0 / 30.5","48.1 / 15.7","69295561 / 40951632","30304259 / 27014248","void pcclKernel_twoShotAllReduceKernel<__ppu_bfloat16, 2, 0, 0, 1, 1>(twoShotDevParams)","void pcclKernel_twoShotAllReduceKernel<__ppu_bfloat16, 2, 0, 0, 1, 1>(twoShotDevParams)",
...GUI使用指南
Kernel Name Mode:Kernel Name的展示模式。包括三种模式:
Base:导出kernel的短名称(仅函数名,不包含参数)。
Mangled:导出kernel的mangled名称。
Demangled:导出kernel的demangle之后的名称(默认值)。
PPU Devices:PPU device过滤器,统计结果按照所选的PPU device进行过滤,默认值为“All”,统计所有PPU devices的数据,此项不能为空。
Add HGTX name as a prefix:使能名字前拼接最接近kernel launch的HGTX名称,通过/间隔。默认不勾选。
Show matched only:使能后仅展示base和target报告中都包含的成功匹配结果,即会隐藏所有包含无效结果“-”的行。默认不使能。
PPU时间利用率比较
比较两个asysrep报告中的PPU时间利用率汇总结果,匹配和比较两个报告中的PPU在时间利用率的差异。
依赖的asys采集选项:
--trace hggc
统计规则
对每个asysrep报告,计算PPU的时间利用率,统计在指定的时间范围内PPU存在操作的时间。
时间范围的选择:
如果选择了“PPU Active Time Range”模式,则统计的时间范围从该设备上的第一个 PPU 操作开始,到该设备上的最后一个 PPU 操作结束。
如果选择了“Filtered Time Range”范围模式,则时间范围与指定的过滤时间范围相同。
请注意,利用率是指“时间”利用率,而不是“资源”利用率,PPU设备在指定时间存在操作,即认为PPU此刻的时间利用率为100%。如果多个操作在同时运行,对应的时间利用率也不会超过100%。
对于每个PPU设备,PPU在时间范围的时间利用率为:繁忙时间/时间段长度。两个报告的统计结果根据PPU设备索引匹配和对比,对比结果按照每个报告的PPU时间利用率降序排列。
ppu_time_util_compare表格列说明如下,比较结果通过/分隔,未匹配的列通过-表示:
Row# : Row number of the compare result
Device Name : PPU Device name
In-Use [%] : Percentage of time the PPU is being used
Duration [ns] : Duration of the time range
PPU Active Time [ns] : PPU active time excluding overlapping
Active Time Ratio : Target PPU active time compared to base
Base Device ID : PPU device identifier in base report
Target Device ID : PPU device identifier in target report命令行使用方法
使用asys stats传入两个asysrep报告进行比较:
asys stats -r ppu_time_util_compare base_report.asysrep target_report.asysrep可通过asys stats --help-report ppu_time_util_compare查看具体帮助信息,支持的选项列举如下:
range-mode=<mode>:统计时间范围的选择模式,支持active和full模式:active:默认模式,时间范围从第一个PPU活动开始,到最后一个PPU活动结束截止。full:时间范围选取为用户指定的统计时间范围,若没有指定统计时间范围,则统计报告整体的时间范围。
报告结果示例如下:
Row#,Device Name,In-Use (%),Duration (ns),PPU Active Time (ns),Base Device ID,Target Device ID,
1,"ZW-M890P / PPU-ZW810E","77.1 / 91.3","1781485096 / 3874625379","1373679518 / 3538770219",1,1,
2,"ZW-M890P / PPU-ZW810E","76.2 / 91.2","1885995849 / 4001152909","1437072950 / 3650124332",0,0,GUI使用指南
Time Range Mode:设置统计时间范围的模式:
PPU Active Time Range:默认模式,时间范围从第一个PPU活动开始,到最后一个PPU活动结束截止。
Filtered Time Range:时间范围选取为用户指定的统计时间范围,若没有指定统计时间范围,则统计报告整体的时间范围。
Show matched only:使能后仅展示base和target报告中都包含的成功匹配结果,即会隐藏所有包含无效结果“-”的行。默认不使能。
PPU算子kernel性能分解比较
比较两个asysrep报告中的PPU算子和kernel性能分解结果,匹配和比较两个报告中的性能分解kernel层的差异。
依赖的asys采集选项:
--trace hggc,hgtx
Tips:在采集asysrep报告前,建议使能PPU算子HGTX range标注相关功能:
执行
export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能基础框架PPU算子HGTX range标注功能。asys添加选项
--pytorch autograd-shapes-hgtx,使能pytorch算子HGTX range标注功能。
统计规则
对每个asysrep报告,计算PPU算子kernel性能分解,识别asysrep报告中的PPU算子,根据算子的种类和嵌套关系,将算子分为框架层、加速库层和kernel层三个层级,获取嵌套的算子逐层细化的性能分解信息。
父一级PPU算子范围内,未存在子一级PPU算子的时间范围(PPU设备空闲),被标记为Idle。各个层级中缺失的父一级PPU算子被标记为Native。
通过三个层级的PPU算子参数匹配两个asysrep报告的kernel层性能分解数据,并比较kernel层的性能数据。输出结果按照每个报告中的每级算子的占比降序排列。
ppu_operator_kernel_breakdown_compare表格列说明如下,比较结果通过/分隔,未匹配的列通过-表示:
Row# : Row number of the compare result
Device Name : PPU Device name
OP Type : PPU operator type
Base Framework OP : Name of the framework layer operator in base report
Base Framework Time [%] : Framework operator time percentage of 'Total Time' in base report
Base Framework Avg [ns] : Average duration of this framework operator in base report
Base Framework Instances : Number of this framework operator in base report
Base Library OP : Name of the compute library layer operator in base report
Base Library Time [%] : Library operator time percentage of 'Total Time' in base report
Base Library Avg [ns] : Average duration of this library operator in base report
Base Library Instances : Number of this library operator in base report
Base Kernel : Name of the HGGC kernel in base report
Base Kernel Time [%] : HGGC kernel time percentage of 'Total Time' in base report
Base Kernel Avg [ns] : Average duration of this kernel in base report
Base Kernel Instances : Number of this kernel in base report
Target Framework OP : Name of the framework layer operator in target report
Target Framework Time [%] : Framework operator time percentage of 'Total Time' in target report
Target Framework Avg [ns] : Average duration of this framework operator in target report
Target Framework Instances : Number of this framework operator in target report
Target Library OP : Name of the compute library layer operator in target report
Target Library Time [%] : Library operator time percentage of 'Total Time' in target report
Target Library Avg [ns] : Average duration of this library operator in target report
Target Library Instances : Number of this library operator in target report
Target Kernel : Name of the HGGC kernel in target report
Target Kernel Time [%] : HGGC kernel time percentage of 'Total Time' in target report
Target Kernel Avg [ns] : Average duration of this kernel in target report
Target Kernel Instances : Number of this kernel in target report
Avg Ratio : Target kernel average time compared to base命令行使用方法
使用asys stats传入两个asysrep报告进行比较:
asys stats -r ppu_operator_kernel_breakdown_compare base_report.asysrep target_report.asysrep可通过asys stats --help-report ppu_operator_kernel_breakdown_compare查看具体帮助信息,支持的选项列举如下:
top=<limit>:仅比较每个报告top N占比的kernel层算子,部分占比较小的算子将会被忽略。
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。base:使用kernel的短名称(仅函数名,不包含参数)进行统计和输出。
mangled:使用kernel的mangled名称进行统计和输出。
op=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过
/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果中体现。order-by=<order_type>:指定输出结果排序方式,默认按照算子时间占比排序。
no-merge-flash-attention-prefill-decode-operator:若指定,不再匹配和合并prefill和decode的flash attention算子。
no-merge-flash-attention-parameter:若指定,不再忽略flash attention算子对性能影响较小的参数差异。
no-merge-communication-parameter:若指定,不再忽略通信算子对性能影响较小的参数差异。
no-merge-moe-parameter:若指定,不再忽略MoE算子对性能影响较小的参数差异。
no-merge-pytorch-parameter:若指定,不再忽略pytorch算子对性能影响较小的参数差异。
no-merge-gemm-parameter:若指定,不再忽略GEMM算子对性能影响较小的参数差异。
可通过--ppu-op-config选项自定义算子识别规则,通过HGTX range名称匹配到的自定义算子将作为框架层算子统计,通过kernel名称匹配到的自定义算子将作为kernel层算子统计。
报告结果示例如下(部分列未展示):
Row#,Device Name,OP Type,Base Framework OP,Base Framework Time (%),Base Library OP,Base Library Time (%),Base Kernel,Base Kernel Time (%),Base Kernel Avg (ns),Base Kernel Instances,Target Framework OP,Target Framework Time (%),Target Library OP,Target Library Time (%),Target Kernel,Target Kernel Time (%),Target Kernel Avg (ns),Target Kernel Instances,Avg Ratio,
1,"PPU-ZW810E / NVIDIA H20-3e","PCCL","sglang::outplace_all_reduce, op_id = 2174848, sizes = [[948, 2048], [], []], input_op_ids = [(2174845,0), (0,-1), (0,-1)]",0.6,"Native",0.6,"void sglang::cross_device_reduce_1stage<__nv_bfloat16, 2>(sglang::RankData*, sglang::RankSignals, sglang::Signal*, __nv_bfloat16*, int, int)",0.6,201675,194,"sglang::outplace_all_reduce, op_id = 1814850, sizes = [[948, 2048], [], []], input_op_ids = [(1814847,0), (0,-1), (0,-1)]",0.9,"Native",0.8,"void sglang::cross_device_reduce_1stage<__nv_bfloat16, 2>(sglang::RankData*, sglang::RankSignals, sglang::Signal*, __nv_bfloat16*, int, int)",0.8,190988,194,0.9,
2,"PPU-ZW810E / NVIDIA H20-3e","MoE","D_MoE,M_4_E_128_H_2048_In_768_topk_8",0.4,"Native",0.1,"_fwd_kernel_ep_scatter_1",0.0,16955,288,"D_MoE,M_4_E_128_H_2048_In_768_topk_8",1.0,"Native",1.0,"-","-","-","-","-",
3,"PPU-ZW810E / NVIDIA H20-3e","MoE","D_MoE,M_4_E_128_H_2048_In_768_topk_8",0.4,"Native",0.1,"void at::native::vectorized_elementwise_kernel<4, at::native::FillFunctor<int>, std::array<char*, 1ul> >(int, at::native::FillFunctor<int>, std::array<char*, 1ul>)",0.0,16955,288,"D_MoE,M_4_E_128_H_2048_In_768_topk_8",1.0,"Native",1.0,"-","-","-","-","-",
...Tips:建议使用选项--format xlsx输出电子表格,统计结果更加易读。
PPU算子性能分解比较
比较两个asysrep报告中的PPU算子性能分解结果,匹配和比较两个报告中的性能分解加速库层的差异。
依赖的asys采集选项:
--trace hggc,hgtx
Tips:在采集asysrep报告前,建议使能PPU算子HGTX range标注相关功能:
执行
export PPU_LIB_PERF_INSTRUMENT=1配置环境变量,使能基础框架PPU算子HGTX range标注功能。asys添加选项
--pytorch autograd-shapes-hgtx,使能pytorch算子HGTX range标注功能。
统计规则
对每个asysrep报告,计算PPU算子性能分解,识别asysrep报告中的PPU算子,根据算子的种类和嵌套关系,将算子分为框架层、加速库层和kernel层三个层级,获取加速库层的性能分解信息和硬件利用率信息。
父一级PPU算子范围内,未存在子一级PPU算子的时间范围(PPU设备空闲),被标记为Idle。各个层级中缺失的父一级PPU算子被标记为Native。
通过框架层和加速库层的PPU算子参数匹配两个asysrep报告的加速库层性能分解数据,并比较差异。输出结果按照每个报告中的每级算子的占比降序排列。
ppu_operator_breakdown_compare表格列说明如下,比较结果通过/分隔,未匹配的列通过-表示:
Row# : Row number of the compare result
Device Name : PPU Device name
OP Type : PPU operator type
Base Framework OP : Name of the framework layer operator in base report
Base Framework Time [%] : Framework operator time percentage of 'Total Time' in base report
Base Framework Avg [ns] : Average duration of this framework operator in base report
Base Framework Instances : Number of this framework operator in base report
Base Library OP : Name of the compute library layer operator in base report
Base Library Time [%] : Library operator time percentage of 'Total Time' in base report
Base Library Avg [ns] : Average duration of this library operator in base report
Base Library Instances : Number of this library operator in base report
Base Compute Util [%] : Utilization ratio of PPU compute capability in base report
Base HBM Load Util [%] : Utilization ratio of PPU HBM load bandwidth in base report
Base HBM Store Util [%] : Utilization ratio of PPU HBM store bandwidth in base report
Target Framework OP : Name of the framework layer operator in target report
Target Framework Time [%] : Framework operator time percentage of 'Total Time' in target report
Target Framework Avg [ns] : Average duration of this framework operator in target report
Target Framework Instances : Number of this framework operator in target report
Target Library OP : Name of the compute library layer operator in target report
Target Library Time [%] : Library operator time percentage of 'Total Time' in target report
Target Library Avg [ns] : Average duration of this library operator in target report
Target Library Instances : Number of this library operator in target report
Target Compute Util [%] : Utilization ratio of PPU compute capability in target report
Target HBM Load Util [%] : Utilization ratio of PPU HBM load bandwidth in target report
Target HBM Store Util [%] : Utilization ratio of PPU HBM store bandwidth in target report
Avg Ratio : Target average time compared to base命令行使用方法
使用asys stats传入两个asysrep报告进行比较:
asys stats -r ppu_operator_breakdown_compare base_report.asysrep target_report.asysrep可通过asys stats --help-report ppu_operator_breakdown_compare查看具体帮助信息,支持的选项列举如下:
top=<limit>:仅比较每个报告top N占比的加速库层算子,部分占比较小的算子将会被忽略。
device=<device_list>:指定统计的PPU device ID列表,多个PPU device ID之间通过
/分割。若不指定,默认统计所有PPU device。range-include=<regex_list>:指定参与统计的HGTX range过滤正则表达式白名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。range-exclude=<regex_list>:指定参与统计的HGTX range过滤正则表达式黑名单,多个正则表达式之间通过
/分割。若不指定,默认统计所有HGTX range。op=<operator_filter>:指定参与统计的PPU算子类型列表,多个PPU算子类型之间通过
/分割。若不指定,默认统计所有支持的PPU算子类型。若指定others类型,未关联到PPU算子的kernel也将在统计结果中体现。order-by=<order_type>:指定输出结果排序方式,默认按照算子时间占比排序。
no-merge-flash-attention-prefill-decode-operator:若指定,不再匹配和合并prefill和decode的flash attention算子。
no-merge-flash-attention-parameter:若指定,不再忽略flash attention算子对性能影响较小的参数差异。
no-merge-communication-parameter:若指定,不再忽略通信算子对性能影响较小的参数差异。
no-merge-moe-parameter:若指定,不再忽略MoE算子对性能影响较小的参数差异。
no-merge-pytorch-parameter:若指定,不再忽略pytorch算子对性能影响较小的参数差异。
no-merge-gemm-parameter:若指定,不再忽略GEMM算子对性能影响较小的参数差异。
可通过--ppu-op-config选项自定义算子识别规则,通过HGTX range名称匹配到的自定义算子将作为框架层算子统计,通过kernel名称匹配到的自定义算子将作为kernel层算子统计。
报告结果示例如下(部分列未展示):
Row#,Device Name,OP Type,Base Framework OP,Base Framework Time (%),Base Library OP,Base Library Time (%),Base Library Avg (ns),Base Library Instances,Base Compute Util (%),Base HBM Load Util (%),Base HBM Store Util (%),Target Framework OP,Target Framework Time (%),Target Library OP,Target Library Time (%),Target Library Avg (ns),Target Library Instances,Target Compute Util (%),Target HBM Load Util (%),Target HBM Store Util (%),Avg Ratio,
1,"PPU-ZW810E / NVIDIA H20-3e","MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"DeepGemm:GroupedNoPad,data_type:bf16,groups:128,m:64,n:768,k:2048,gpu:0",23.3,55495,28128,2.6,262.6,0.0,"D_MoE,M_8_E_128_H_2048_In_768_topk_8",41.9,"-","-","-","-","-","-","-","-",
2,"PPU-ZW810E / NVIDIA H20-3e","MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"DeepGemm:GroupedNoPad,data_type:bf16,groups:128,m:64,n:2048,k:384,gpu:0",13.0,30975,28128,2.3,235.1,0.0,"D_MoE,M_8_E_128_H_2048_In_768_topk_8",41.9,"-","-","-","-","-","-","-","-",
3,"PPU-ZW810E / NVIDIA H20-3e","MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"Native",7.3,2482,196896,"-","-","-","D_MoE,M_8_E_128_H_2048_In_768_topk_8",41.9,"Native",40.7,11049,165526,"-","-","-",4.5,
4,"PPU-ZW810E / NVIDIA H20-3e","MoE","D_MoE,M_8_E_128_H_2048_In_768_topk_8",44.3,"Idle",0.7,1681,28128,"-","-","-","D_MoE,M_8_E_128_H_2048_In_768_topk_8",41.9,"Idle",1.2,1992,27647,"-","-","-",1.2,
...