
本文简要介绍数据探索中算子的相关概念,要了解算子的详细信息,请访问对应算子章节。
什么是算子
算子是一种独立、可复用的逻辑表达,能够通过组合的方式实现更高维度的业务逻辑。行为和输入输出是所有算子都有的属性,描述了算子可以做什么及相应的接口。对于不可解释算子(如图像识别),仅需定义行为和输入输出即可;对于可解释算子(如算术运算、条件判断等),则需要定义表达式以及表达式之间的关系。
数据探索的算子分为三大类:
脚本算子:由程序语言编写,通常不具备可解释性,例如一个Jar包、一个算法镜像等。
连接器:关联现实世界中的某种资源,例如读取MaxCompute表等。
抽象算子:使用了表达式规范和关系描述符的可解释算子。
表达式
根据FEEL (Friendly Enough Expression Language,一种DMN规范定义的表达式语言)的定义,表达式可以分为一元表达式(Unary-tests,布尔表达式)和普通表达式(General expression,可以返回不同类型的表达式)。数据探索结构化的引入了这两种表达式并在算子层面定义不同的关系,以此构成了一切可解释算子。
以下是表达式和关系的表现形式示例:
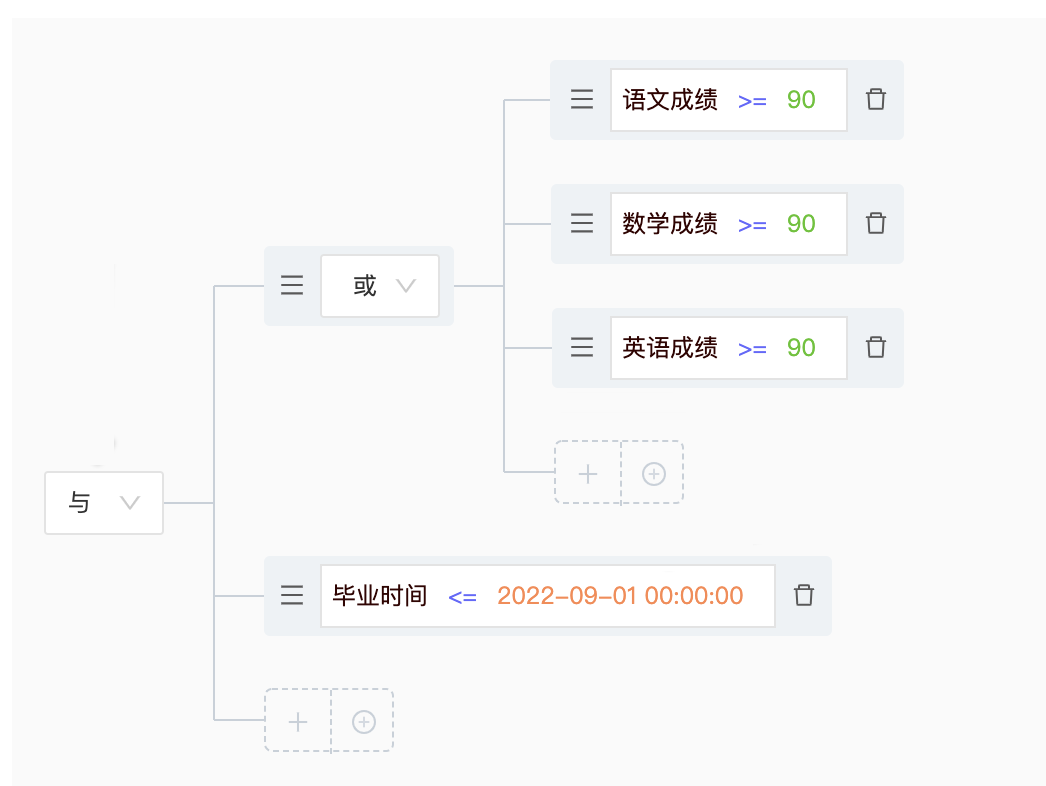
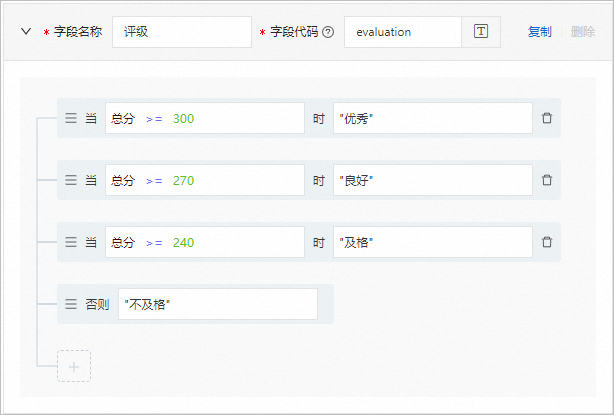
函数
在表达式内部,数据探索构建了完整的函数体系,用户可以将所需的函数以拖拉的方式引入到表达式框内,实现复杂逻辑的表达。引入函数的原因主要有:
表达式可以实现+、-、*、/,以及=、!=等比较符,但不能进行更为复杂的数学、时间、字符串运算。
函数可以响应业务上对逻辑封装的诉求,例如从身份证中提取生日、性别等。
跨引擎
由表达式、函数组成的算子具备跨引擎能力,可以适配到离线、在线、实时引擎上运行。详细信息可以访问各个算子的适用场景章节。
计算资源
计算资源是指带有存储、计算能力的数据处理引擎,通常指MaxCompute等。数据探索将业务模型转换为可执行代码下发到计算资源上以完成数据处理任务。
注册计算资源时,需要用户提供连接信息,不同的计算资源需要提供的连接信息会有不同。
不同的业务场景下可供使用的计算资源会有区别,数据探索支持的计算资源有:
计算资源 | 版本要求 | 备注 |
MySQL | >=5.6.10 | - |
Hive | >=2.3.3 | - |
MaxCompute | ALL | - |
Spark Standalone | spark 3.x | |
Spark on yarn | hadoop 3.x | spark client: 3.2.1 |
Hive Storage | >=2.3.3 | |
AnalyticDB PostgreSQL(ADB PG) | ALL |