
读API
更新时间:
复制为 MD 格式
本文介绍读API算子的使用方式和注意事项。
用途
读API算子可以访问用户指定的接口并解析返回值,产生一张临时表,供后续节点进一步加工处理。
适用场景
计算链路 | 计算引擎 | 是否支持 |
离线 | ALL | 是 |
实时 | Blink | 否 |
在线 | 内置 | 否 |
使用说明
前置条件
用户通过数据中心->API接入页面,将需要访问的API接口注册到系统上。
请求配置
请求头/请求体
请求头/请求体参数是在API接入时设置的,在读API算子中,用户可以通过表达式框配置每个参数对应的逻辑。
返回值映射
通过设置“数组提取”来指定需要提取的数组在JSON对象中的路径,并通过表格指定对应的列名。
说明
从返回值中提取的数据必须是数组类型。
以下是返回值和映射关系配置的示例:
{
"code":"SUCCESS",
"data":{
"pageSize": 20,
"pageNum": 1,
"list":[ // 需要提取的数组
{
"name": {
"firstName": "Alice",
"lastName": "Brown"
},
"age": 22,
"email": "alice@example.com"
},
{
"name": {
"firstName": "Bob",
"lastName": "Miller"
},
"age": 19,
"email": "bob@example.com"
}
]
}
}
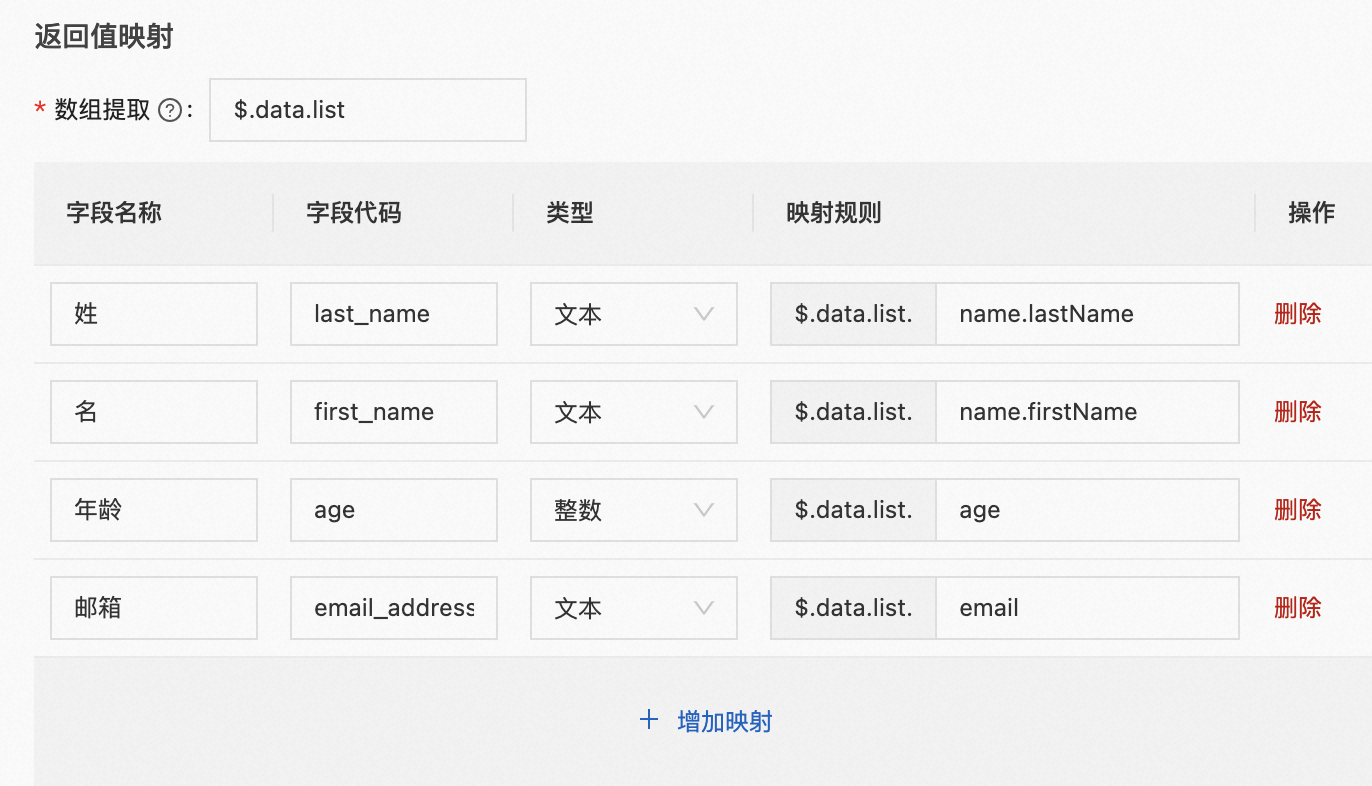
生成的数据结果如下:
last_name | first_name | age | email_address |
Brown | Alice | 22 | alice@example.com |
Miller | Bob | 19 | bob@example.com |
注意事项
读API算子会运行在Zerg Standalone容器中,因此运行时您需要指定一个Zerg Standalone引擎。
读API算子运行超时时间为10分钟,请确保接口返回的数据量在合理范围。
仅支持访问content type为以下类型的外部接口:
application/json
application/x-www-form-urlencoded
text/plain
数据的写入操作和用户指定的计算引擎、临时存储关系如下表:
计算引擎 | 临时存储 | 执行写入操作 |
Spark | Hive Storage | Spark |
Spark | MySQL | MySQL |
MySQL | - | MySQL |
MaxCompute | - | MaxCompute |
Hive | - | Hive |
Postgres | - | Postgres |
ADB PG | - | ADB PG |
该文章对您有帮助吗?