
本文介绍两表并集算子的使用方法及注意事项。
用途
两表并集算子可以将两张数据表按照设置的合并条件求取并集。
适用场景
计算链路 | 计算引擎 | 是否支持 |
离线 | MaxCompute | 是 |
Hive | 是 | |
HiveStorage | 是 | |
RDS/MySQL | 是 | |
Spark | 是 |
使用说明
来源节点
两表并集算子必须指定两个来源节点(又称为输入节点,每个来源节点可视为一张表),以求取这两个来源节点的并集。
合并条件
可以分别指定两个来源节点的1个或者多个字段作为合并条件的字段。合并的结果中将包含这两个来源节点中的指定合并字段的所有记录,示意图如下所示。
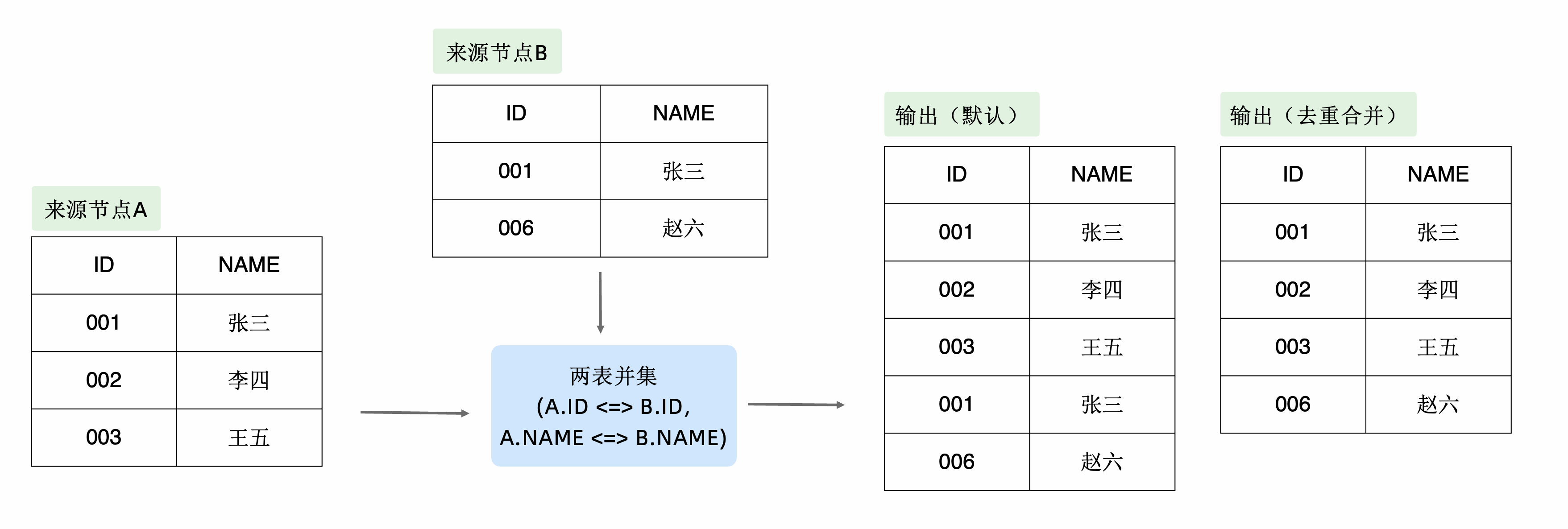
示例如下所示,假设两个输入节点分别为A和B,设置两个合并条件为"A.ID <=> B.ID"、 "A.NAME <=> B.NAME",则并集运算结果、去重合并后的并集运算结果如下图右侧所示。
快速合并
系统提供快速填充合并条件的辅助工具,点击快速合并按钮后,系统自动将两个输入节点相同的字段作为合并字段填写到合并字段中。
输出字段
合并条件中的字段列表将自动作为当前节点的输出字段,输出到下游节点。
去重合并
两表并集算子默认不做去重合并,输出的数据包含来源节点的所有记录。勾选去重合并后,节点的输出数据将会过滤重复的记录。去重合并的效果示例参考合并条件中的示意图。
该文章对您有帮助吗?