
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
Kafka是应用较为广泛的分布式、高吞吐量、高可扩展性消息队列服务,普遍用于日志收集、监控数据聚合、流式数据处理、在线和离线分析等大数据领域,是大数据生态中不可或缺的产品之一。通过数据传输服务DTS(Data Transmission Service),您可以将ECS上的自建MySQL数据同步至自建Kafka集群,扩展消息处理能力。
前提条件
- Kafka集群的版本为0.10.1.0~2.7.0版本。
- 已创建RDS MySQL实例,详情请参见快速创建RDS MySQL实例。
注意事项
DTS在执行全量数据初始化时将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升,在数据库性能较差、规格较低或业务量较大的情况下(例如源库有大量慢SQL、存在无主键表或目标库存在死锁等),可能会加重数据库压力,甚至导致数据库服务不可用。因此您需要在执行数据同步前评估源库和目标库的性能,同时建议您在业务低峰期执行数据同步(例如源库和目标库的CPU负载在30%以下)。
- 如果源数据库没有主键或唯一约束,且所有字段没有唯一性,可能会导致目标数据库中出现重复数据。
费用说明
| 同步类型 | 链路配置费用 |
| 库表结构同步和全量数据同步 | 不收费。 |
| 增量数据同步 | 收费,详情请参见计费概述。 |
功能限制
- 同步对象仅支持数据表,不支持非数据表的对象。
- 不支持自动调整同步对象,如果对同步对象中的数据表进行重命名操作,且重命名后的名称不在同步对象中,那么这部分数据将不再同步到目标Kafka集群中。如需将修改后的数据表继续数据同步至目标Kafka集群中,您需要进行修改同步对象操作,详情请参见新增同步对象。
支持的同步架构
- 1对1单向同步
- 1对多单向同步
- 多对1单向同步
- 级联单向同步
准备工作
在正式配置数据同步作业之前,您需要为自建MySQL创建账号并设置binlog。
操作步骤
- 购买数据同步作业,详情请参见购买流程。说明 购买时,选择源实例为MySQL,目标实例为Kafka,选择同步拓扑为单向同步。
- 登录数据传输控制台。说明 若数据传输控制台自动跳转至数据管理DMS控制台,您可以在右下角的
 中单击
中单击 ,返回至旧版数据传输控制台。
,返回至旧版数据传输控制台。 在左侧导航栏,单击数据同步。
在同步作业列表页面顶部,选择同步的目标实例所属地域。
定位至已购买的数据同步实例,单击配置同步链路。
- 配置同步通道的源实例及目标实例信息。
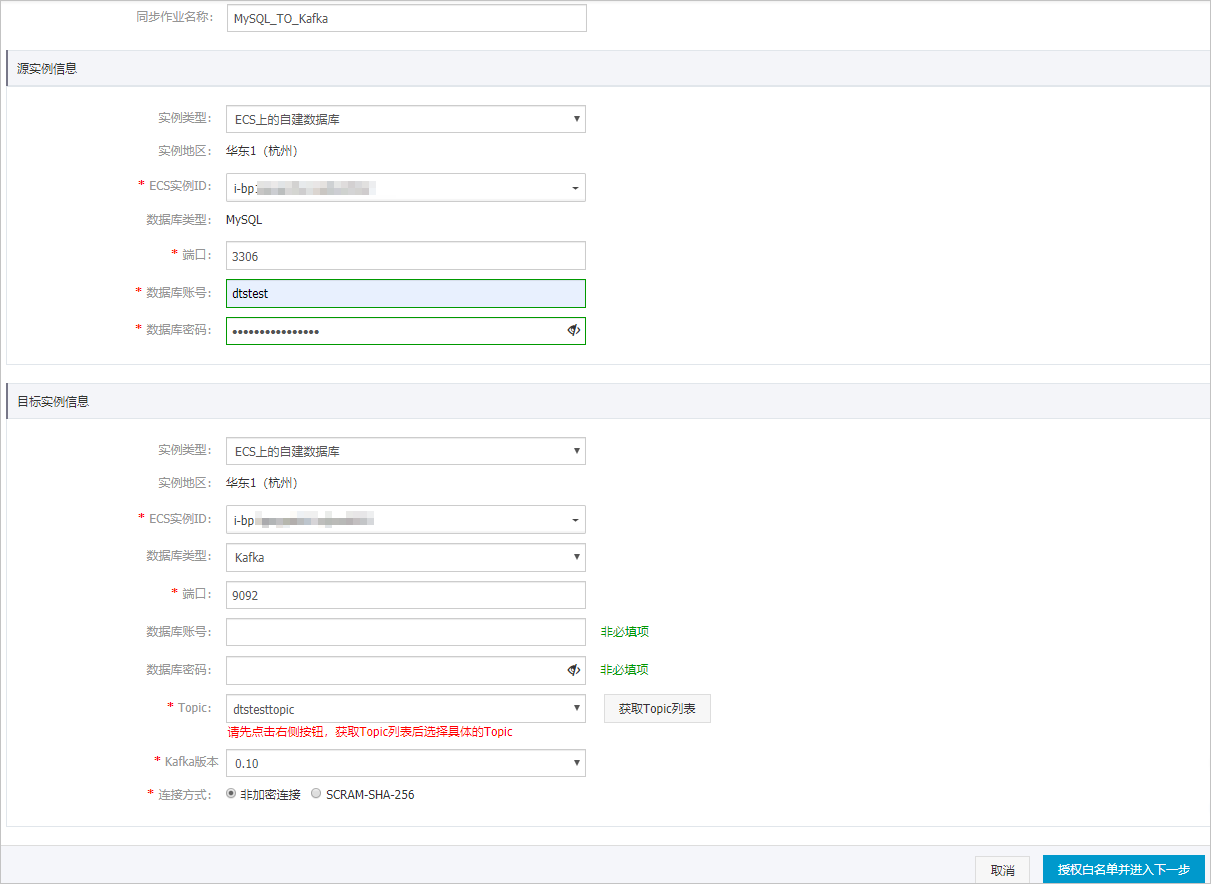
类别 配置 说明 无 同步作业名称 DTS会自动生成一个同步作业名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。 源实例信息 实例类型 选择ECS上的自建数据库。 实例地区 购买数据同步实例时选择的源实例地域,不可变更。 ECS实例ID 选择作为同步数据源的ECS实例ID。 数据库类型 固定为MySQL,不可变更。 端口 填入自建数据库服务端口,默认为3306。 数据库账号 填入自建MySQL的数据库账号,需要具备REPLICATION CLIENT、REPLICATION SLAVE、SHOW VIEW和所有同步对象的SELECT权限。 数据库密码 填入该数据库账号对应的密码。 目标实例信息 实例类型 根据Kafka集群的部署位置选择,本文以ECS上的自建数据库为例介绍配置流程。 说明 当选择为其他实例类型时,您还需要执行相应的准备工作,详情请参见准备工作概览。实例地区 购买数据同步实例时选择的目标实例地域,不可变更。 ECS实例ID 选择部署了Kafka集群的ECS实例ID。 数据库类型 选择为Kafka。 端口 Kafka集群对外提供服务的端口,默认为9092。 数据库账号 填入Kafka集群的用户名,如Kafka集群未开启验证可不填写。 数据库密码 填入Kafka集群用户名对应的密码,如Kafka集群未开启验证可不填写。 Topic 单击右侧的获取Topic列表,然后在下拉框中选择具体的Topic名称。 Kafka版本 根据目标Kafka集群版本,选择对应的版本信息。 连接方式 根据业务及安全需求,选择非加密连接或SCRAM-SHA-256。 单击页面右下角的授权白名单并进入下一步。
如果源或目标数据库是阿里云数据库实例(例如RDS MySQL、云数据库MongoDB版等),DTS会自动将对应地区DTS服务的IP地址添加到阿里云数据库实例的白名单中;如果源或目标数据库是ECS上的自建数据库,DTS会自动将对应地区DTS服务的IP地址添到ECS的安全规则中,您还需确保自建数据库没有限制ECS的访问(若数据库是集群部署在多个ECS实例,您需要手动将DTS服务对应地区的IP地址添到其余每个ECS的安全规则中);如果源或目标数据库是IDC自建数据库或其他云数据库,则需要您手动添加对应地区DTS服务的IP地址,以允许来自DTS服务器的访问。DTS服务的IP地址,请参见DTS服务器的IP地址段。
警告DTS自动添加或您手动添加DTS服务的公网IP地址段可能会存在安全风险,一旦使用本产品代表您已理解和确认其中可能存在的安全风险,并且需要您做好基本的安全防护,包括但不限于加强账号密码强度防范、限制各网段开放的端口号、内部各API使用鉴权方式通信、定期检查并限制不需要的网段,或者使用通过内网(专线/VPN网关/智能网关)的方式接入。
- 配置同步策略和同步对象信息。
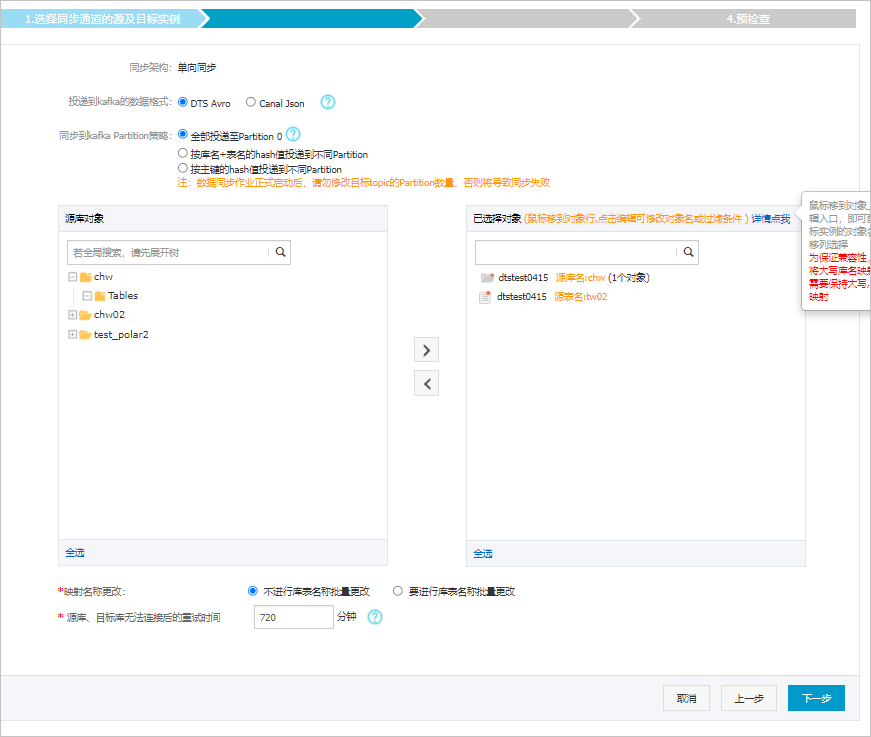
配置 说明 投递到kafka的数据格式 同步到Kafka集群中的数据以avro格式或者Canal Json格式存储,定义详情请参见Kafka集群的数据存储格式。 同步到Kafka Partition策略 根据业务需求选择同步的策略,详细介绍请参见Kafka Partition同步策略说明。 同步对象 在源库对象区域框中,选择需要同步的对象(选择的粒度为表),然后单击  图标将其移动到已选对象区域框中。说明 DTS会自动将表名映射为步骤6选择的Topic名称。如果需要更换同步的目标Topic,请参见步骤9 。
图标将其移动到已选对象区域框中。说明 DTS会自动将表名映射为步骤6选择的Topic名称。如果需要更换同步的目标Topic,请参见步骤9 。映射名称更改 如需更改同步对象在目标实例中的名称,请使用对象名映射功能,详情请参见库表列映射。
源、目标库无法连接重试时间 当源、目标库无法连接时,DTS默认重试720分钟(即12小时),您也可以自定义重试时间。如果DTS在设置的时间内重新连接上源、目标库,同步任务将自动恢复。否则,同步任务将失败。
说明由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
- 可选:在已选择对象区域框中,将鼠标指针放置在目标Topic名上,然后单击Topic名后出现的编辑,在弹出的对话框中设置源表在目标Kafka集群中的Topic名称、Topic的Partition数量、Partition Key等信息。
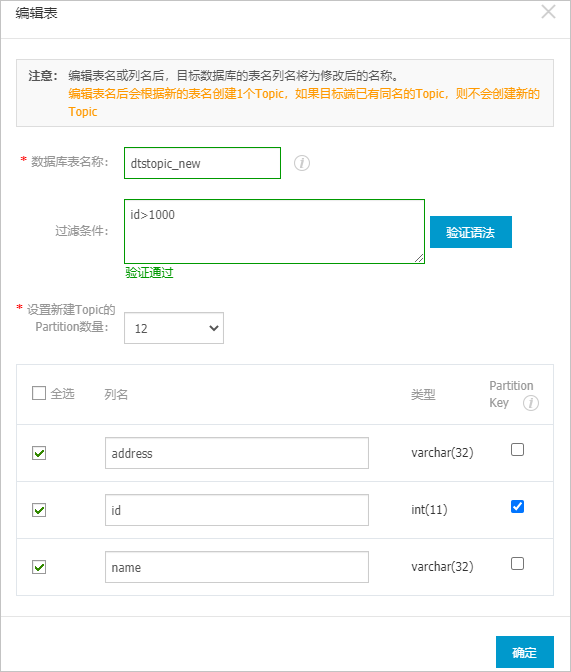
配置 说明 数据库表名称 设置源表同步到的目标Topic名称。 说明 如果设置的Topic名称在目标Kafka集群中不存在,您还需要设置该Topic的Partition数量。过滤条件 - 过滤条件支持标准的SQL WHERE语句(仅支持
=、!=、<和>操作符),只有满足WHERE条件的数据才会被同步到目标Topic。本案例填入id>1000。 - 过滤条件中如需使用引号,请使用单引号('),例如
address in('hangzhou','shanghai')。
设置新Topic的Partition数量 在下拉列表中,选择新Topic的Partition数量。 说明 只有当设置的目标Topic名称在目标Kafka集群中不存在时,您才需要配置本参数。设置Partition Key 当您在步骤8中选择同步策略为按主键的hash值投递到不同Partition时,您可以配置本参数,指定单个或多个列作为Partition Key来计算Hash值,DTS将根据计算得到的Hash值将不同的行投递到目标Topic的各Partition中。 - 过滤条件支持标准的SQL WHERE语句(仅支持
- 上述配置完成后单击页面右下角的下一步。
- 配置同步初始化的高级配置信息。

配置 说明 同步初始化 默认选择结构初始化和全量数据初始化,DTS会在增量数据同步之前,将源库中待同步对象的结构和存量数据,同步到目标库。 过滤选项 默认选择忽略增量同步阶段的 DDL,即增量同步阶段源库执行的DDL操作不会被DTS同步至目标库。 上述配置完成后,单击页面右下角的预检查并启动。
说明在同步作业正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动同步作业。
如果预检查失败,单击具体检查项后的
 ,查看失败详情。
,查看失败详情。您可以根据提示修复后重新进行预检查。
如无需修复告警检测项,您也可以选择确认屏蔽、忽略告警项并重新进行预检查,跳过告警检测项重新进行预检查。
- 在预检查对话框中显示预检查通过后,关闭预检查对话框,数据同步作业正式开始。您可以在数据同步页面,查看数据同步状态。
