数据传输服务DTS(Data Transmission Service)支持将自建SQL Server同步至云原生数据仓库AnalyticDB PostgreSQL,实现增量数据的实时同步。
前提条件
-
自建SQL Server数据库版本为2008、2008 R2、2012、2014、2016、2017或2019版本。
说明如果是SQL Server AlwaysOn High Availability Group,需要使用强同步模式。
-
自建SQL Server数据库中待同步的表需具备主键或者唯一性非空索引以确保同步过程中的幂等性。
-
云原生数据仓库AnalyticDB PostgreSQL实例的存储空间须大于自建SQL Server数据库占用的存储空间。
注意事项
DTS在执行全量数据初始化时将占用源库和目标库一定的读写资源,可能会导致数据库的负载上升,在数据库性能较差、规格较低或业务量较大的情况下(例如源库有大量慢SQL、存在无主键表或目标库存在死锁等),可能会加重数据库压力,甚至导致数据库服务不可用。因此您需要在执行数据同步前评估源库和目标库的性能,同时建议您在业务低峰期执行数据同步(例如源库和目标库的CPU负载在30%以下)。
-
选择同步对象时支持的粒度为表(不支持AO表),支持修改列的映射关系。若使用列映射时为非全表同步或者源与目标表结构不一致,则目标端比源端缺少的列的数据将会丢失。
-
为保障数据同步的正常运行,请勿对源库频繁执行备份,同时建议日志保留3天以上,避免日志截断后无法获取日志。
-
为保证数据同步延迟显示的准确性,DTS会在自建SQL Server数据库中新增一张心跳表,表名格式为
待同步表名_dts_mysql_heartbeat。
费用说明
| 同步类型 | 链路配置费用 |
| 库表结构同步和全量数据同步 | 不收费。 |
| 增量数据同步 | 收费,详情请参见计费概述。 |
功能限制
-
不支持assemblies、service broker、全文索引、全文目录、分布式schema、分布式函数、CLR存储过程、CLR标量函数、CLR表值函数、内部表、系统、聚合函数的结构同步。
-
不支持同步数据类型为TIMESTAMP、CURSOR、ROWVERSION、HIERARCHYID、SQL_VARIANT、SPATIAL GEOMETRY、SPATIAL GEOGRAPHY、TABLE的数据。
-
不支持同步含有计算列的表。
支持同步的SQL操作
-
DML操作:INSERT、UPDATE、DELETE
-
DDL操作:ADD COLUMN
说明不支持迁移事务性的DDL操作。
数据库账号的权限要求
|
数据库 |
所需权限 |
账号创建及授权方法 |
|
自建SQL Server实例 |
sysadmin |
|
|
云原生数据仓库AnalyticDB PostgreSQL实例 |
说明
您也可以使用云原生数据仓库AnalyticDB PostgreSQL实例的初始账号。 |
准备工作
在正式配置数据同步任务之前,需要在自建SQL Server数据库上进行日志配置并创建聚集索引。
如果有多个数据库需要同步,您需要重复执行准备工作中的步骤1到步骤4。
-
在自建SQL Server数据库中执行如下命令,将待同步的数据库恢复模式修改为完整模式。也可通过SSMS客户端修改,具体请参见修改数据库的recovery mode。
use master; GO ALTER DATABASE <database_name> SET RECOVERY FULL WITH ROLLBACK IMMEDIATE; GO参数说明:
<database_name>:待同步的数据库名。
示例:
use master; GO ALTER DATABASE mytestdata SET RECOVERY FULL WITH ROLLBACK IMMEDIATE; GO -
执行如下命令,将待同步的数据库进行逻辑备份。如您已进行过逻辑备份,可跳过本步骤。
BACKUP DATABASE <database_name> TO DISK='<physical_backup_device_name>'; GO参数说明:
-
<database_name>:待同步的数据库名。
-
<physical_backup_device_name>:指定备份文件存储的路径和文件名。
示例:
BACKUP DATABASE mytestdata TO DISK='D:\backup\dbdata.bak'; GO -
-
执行如下命令,将待同步的数据库日志进行备份。
BACKUP LOG <database_name> to DISK='<physical_backup_device_name>' WITH init; GO参数说明:
-
<database_name>:待同步的数据库名。
-
<physical_backup_device_name>:指定备份文件存储的路径和文件名。
示例:
BACKUP LOG mytestdata TO DISK='D:\backup\dblog.bak' WITH init; GO -
-
为待同步的表创建聚集索引,详情请参见创建聚集索引。
操作步骤
-
购买数据同步作业,详情请参见购买流程。
说明购买时,选择源实例为SQLServer,目标实例为AnalyticDB for PostgreSQL,并选择同步拓扑为单向同步。
-
登录数据传输控制台。
-
在左侧导航栏,单击数据同步。
-
在同步作业列表页面顶部,选择同步的目标实例所属地域。
-
定位至已购买的数据同步实例,单击配置同步链路。
-
配置同步作业的源实例及目标实例信息。
类别
配置
说明
无
同步作业名称
DTS会自动生成一个同步作业名称,建议配置具有业务意义的名称(无唯一性要求),便于后续识别。
源实例信息
实例类型
根据源库的部署位置进行选择,本文以ECS上的自建数据库为例介绍配置流程。
说明当自建数据库为其他实例类型时,您还需要执行相应的准备工作,详情请参见准备工作概览。
实例地区
购买数据同步实例时选择的源实例地域信息,不可变更。
ECS实例ID
选择源库所属的ECS实例ID。
数据库类型
固定为SQLServer。
端口
填入自建数据库的服务端口,默认为3306。
数据库账号
填入源库的数据库账号。权限要求请参见数据库账号的权限要求。
数据库密码
填入该数据库账号的密码。
连接方式
根据需求选择非加密连接或SSL安全连接。
目标实例信息
实例类型
选择为AnalyticDB for PostgreSQL。
实例地区
购买数据同步实例时选择的目标实例地域信息,不可变更。
实例ID
选择目标云原生数据仓库AnalyticDB PostgreSQL实例ID。
数据库名称
填入同步目标表所属的数据库名称。
数据库账号
填入云原生数据仓库AnalyticDB PostgreSQL的数据库账号。权限要求请参见数据库账号的权限要求。
数据库密码
填入该数据库账号对应的密码。
单击页面右下角的授权白名单并进入下一步。
如果源或目标数据库是阿里云数据库实例(例如RDS MySQL、云数据库MongoDB版等),DTS会自动将对应地区DTS服务的IP地址添加到阿里云数据库实例的白名单中;如果源或目标数据库是ECS上的自建数据库,DTS会自动将对应地区DTS服务的IP地址添加到ECS的安全规则中,您还需确保自建数据库没有限制ECS的访问(若数据库是集群部署在多个ECS实例,您需要手动将DTS服务对应地区的IP地址添加到其余每个ECS的安全规则中);如果源或目标数据库是IDC自建数据库或其他云数据库,则需要您手动添加对应地区DTS服务的IP地址,以允许来自DTS服务器的访问。DTS服务的IP地址,请参见DTS服务器的IP地址段。
警告DTS自动添加或您手动添加DTS服务的公网IP地址段可能会存在安全风险,一旦使用本产品代表您已理解和确认其中可能存在的安全风险,并且需要您做好基本的安全防护,包括但不限于加强账号密码强度防范、限制各网段开放的端口号、内部各API使用鉴权方式通信、定期检查并限制不需要的网段,或者使用通过内网(专线/VPN网关/智能网关)的方式接入。
-
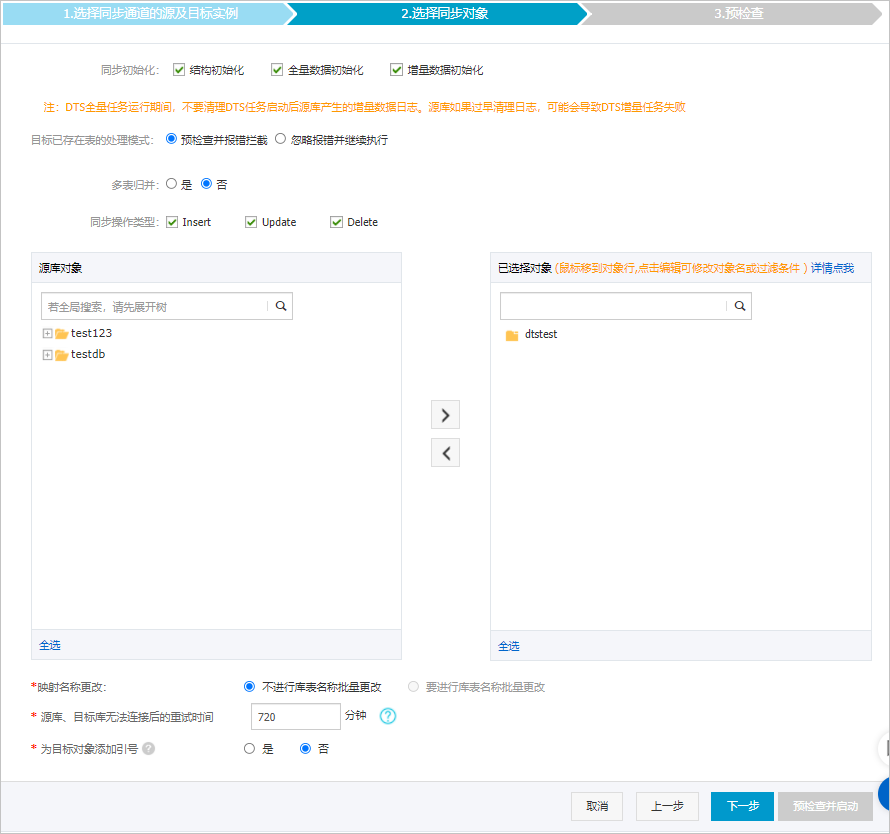
配置同步策略和同步对象。
配置
说明
同步初始化
默认选中结构初始化、全量数据初始化和增量数据初始化。预检查完成后,DTS会将源实例中待同步对象的结构和存量数据同步至目标在目标库,作为后续增量同步数据的基线数据。
目标已存在表的处理模式
-
预检查并报错拦截:检查目标数据库中是否有同名的表。如果目标数据库中没有同名的表,则通过该检查项目;如果目标数据库中有同名的表,则在预检查阶段提示错误,数据同步作业不会被启动。
说明如果目标库中同名的表不能删除或重命名,您可以更改该表在目标库中的名称,详情请参见设置同步对象在目标实例中的名称。
-
忽略报错并继续执行:跳过目标数据库中是否有同名表的检查项。
警告选择为忽略报错并继续执行,可能导致数据不一致,给业务带来风险,例如:
-
表结构一致的情况下,在目标库遇到与源库主键的值相同的记录,则会保留目标集群中的该条记录,即源库中的该条记录不会同步至目标数据库中。
-
表结构不一致的情况下,可能会导致无法初始化数据、只能同步部分列的数据或同步失败。
-
多表归并
-
选择为是:通常在OLTP场景中,为提高业务表响应速度,通常会做分库分表处理。而在云原生数据仓库AnalyticDB PostgreSQL中单个数据表可存储海量数据,使用单表查询更加便捷。此类场景中,您可以借助DTS的多表归并功能将源库中多个表结构相同的表(即各分表)同步至云原生数据仓库AnalyticDB PostgreSQL中的同一个表中。
说明-
选择源库的多个表后,您需要通过对象名映射功能,将其改为云原生数据仓库AnalyticDB PostgreSQL中的同一个表名。关于对象名映射功能的介绍,请参见设置同步对象在目标实例中的名称。
-
您需要在云原生数据仓库AnalyticDB PostgreSQL的同步目标表中增加
__dts_data_source列(类型为text)来存储数据来源。DTS将以<dts数据同步实例ID>:<源数据库名>.<源Schema名>.<源表名>的格式写入列值用于区分表的来源,例如dts********:dtstestdata.testschema.customer1。 -
多表归并功能基于任务级别,即不支持基于表级别执行多表归并。如果需要让部分表执行多表归并,另一部分不执行多表归并,您需要创建两个数据同步作业。
-
-
选择为否:默认选项。
同步操作类型
根据业务选中需要同步的操作类型,默认情况下都处于选中状态。
选择同步对象
在源库对象框中单击待迁移的对象,然后单击
 图标将其移动至已选择对象框。
图标将其移动至已选择对象框。本场景为异构数据库间同步,因此同步对象选择的粒度为表,且其他对象(如视图、触发器、存储过程)不会被同步至目标库。
说明-
默认情况下,同步对象的名称保持不变。如果您需要同步对象在目标实例上名称不同,请使用对象名映射功能,详情请参见设置同步对象在目标实例中的名称。
-
如果配置多表归并为是,在选择源库的多个表后,您需要通过对象名映射功能,将其改为云原生数据仓库AnalyticDB PostgreSQL中的同一个表名。
为目标对象添加引号
选择是否需要为目标对象名添加引号。如果选择为是,且存在下述情况,DTS在结构初始化阶段和增量数据迁移阶段会为目标对象添加单引号或双引号:
-
源库所属的业务环境对大小写敏感且大小写混用。
-
源表名不是以字母开头,且包含字母、数字或特殊字符以外的字符。
说明特殊字符仅支持下划线(_),井号(#)和美元符号($)。
-
待迁移的Schema、表或列名称是目标库的关键字、保留字或非法字符。
说明如果选择添加引号,在数据同步完成后,您需使用带引号的目标对象名进行查询。
映射名称更改
如需更改同步对象在目标实例中的名称,请使用对象名映射功能,详情请参见库表列映射。
源、目标库无法连接重试时间
当源、目标库无法连接时,DTS默认重试720分钟(即12小时),您也可以自定义重试时间。如果DTS在设置的时间内重新连接上源、目标库,同步任务将自动恢复。否则,同步任务将失败。
说明由于连接重试期间,DTS将收取任务运行费用,建议您根据业务需要自定义重试时间,或者在源和目标库实例释放后尽快释放DTS实例。
-
-
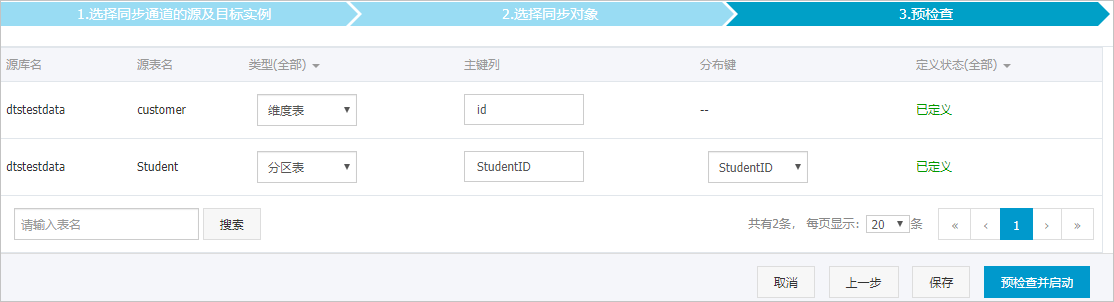
设置待同步的表在云原生数据仓库AnalyticDB PostgreSQL中表类型、主键列和分布键信息。
上述配置完成后,单击页面右下角的预检查并启动。
说明在同步作业正式启动之前,会先进行预检查。只有预检查通过后,才能成功启动同步作业。
如果预检查失败,单击具体检查项后的
 ,查看失败详情。
,查看失败详情。您可以根据提示修复后重新进行预检查。
如无需修复告警检测项,您也可以选择确认屏蔽、忽略告警项并重新进行预检查,跳过告警检测项重新进行预检查。
-
在预检查对话框中显示预检查通过后,关闭预检查对话框,同步作业将正式开始。
-
等待同步作业的链路初始化完成,直至处于同步中状态。
您可以在数据同步页面,查看数据同步作业的状态。