本文基于Alpaca提供了一套LLaMA-7B模型在阿里云ECS上进行指令微调的训练方案,最终可以获得性能更贴近具体使用场景的语言模型。
背景信息
LLaMA(Large Language Model Meta AI )是Meta AI在2023年2月发布的开放使用预训练语言模型(Large Language Model, LLM),其参数量包含7B到65B的集合,并仅使用完全公开的数据集进行训练。LLaMA的训练原理是将一系列单词作为“输入”并预测下一个单词以递归生成文本。
LLM具有建模大量词语之间联系的能力,但是为了让其强大的建模能力向下游具体任务输出,需要进行指令微调,根据大量不同指令对模型部分权重进行更新,使模型更善于遵循指令。指令微调中的指令简单直观地描述了任务,具体的指令格式如下:
{
"instruction": "Given the following input, find the missing number",
"input": "10, 12, 14, __, 18",
"output": "16"
}Alpaca是一个由LLaMA-7B模型进行指令微调得到的模型,其训练过程中采用的通过指令对LLaMA-7B模型进行小规模权重更新的方式,实现了模型性能和训练时间的平衡。
本文基于Alpaca提供了一套LLaMA-7B模型,基于Deepytorch Training进行指令微调训练,并使用Deepytorch加速训练。Deepytorch Training面向传统AI和生成式AI场景,提供了训练加速能力。通过整合分布式通信和计算图编译的性能优化,在保障精度的前提下实现端到端训练性能的显著提升,为您带来更低的成本和更敏捷的迭代。同时Deepytorch Training具有无感适配和充分兼容开源生态等特点,使AI研发人员可以轻松将该加速器集成到业务代码中,享受训练加速效果。
阿里云不对第三方模型“llama-7b-hf”的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。
您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
操作步骤
准备工作
操作前,请先在合适的地域和可用区下创建VPC和交换机。
本文使用ecs.gn7i-c32g1.32xlarge规格的ECS实例进行训练,仅部分地域可用区支持该实例规格,具体请参见ECS实例规格可购买地域。
创建ECS实例
控制台方式
前往实例创建页。
按照向导完成参数配置,创建一台ECS实例。
需要注意的参数如下。更多信息,请参见自定义购买实例。
实例:规格选择ecs.gn7i-c32g1.32xlarge(包含4卡NVIDIA A10 GPU)。
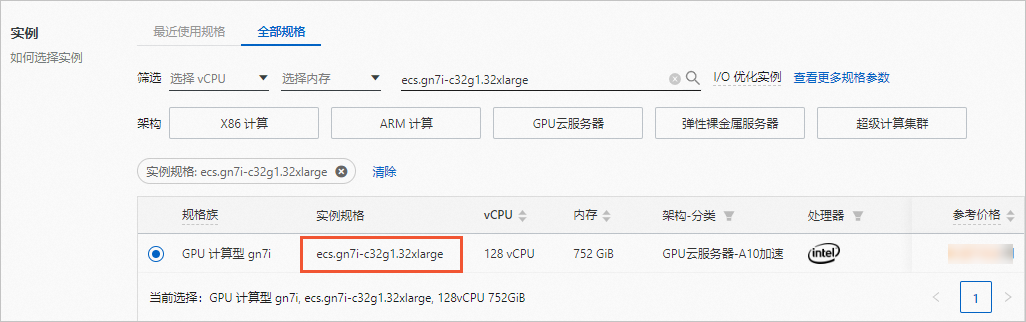
镜像:使用云市场镜像,名称为aiacc-train-solution,该镜像已部署好训练所需环境。您可以直接通过名称搜索该镜像,版本可选择最新版本。
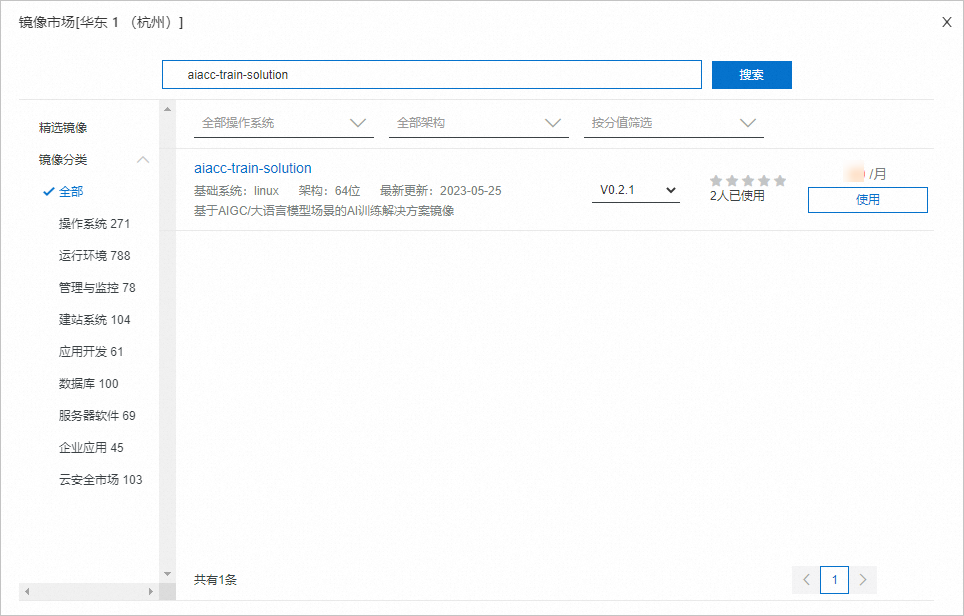
公网IP:选中分配公网IPv4地址,按需选择计费模式和带宽。本文使用按流量计费,带宽峰值为5 Mbps。
添加安全组规则。
在ECS实例所需安全组的入方向添加一条规则,开放7860端口,用于访问WebUI。具体操作,请参见添加安全组规则。
以下示例表示向所有网段开放7860端口,开放后所有公网IP均可访问您的WebUI。您可以根据需要将授权对象设置为特定网段,仅允许部分IP地址访问WebUI。

使用Workbench连接实例。
如果使用示例的云市场镜像进行测试,由于环境安装在
/root目录下,连接实例时需使用root用户。关于如何连接ECS实例,请参见使用Workbench工具以SSH协议登录Linux实例。
FastGPU方式
FastGPU方式仅支持在Linux系统或macOS系统中使用。如果您使用Windows系统,请采用控制台方式。
安装FastGPU软件包并配置环境变量。
安装FastGPU软件包。
pip3 install --force-reinstall https://ali-perseus-release.oss-cn-huhehaote.aliyuncs.com/fastgpu/fastgpu-1.1.5-py3-none-any.whl配置环境变量。
配置环境变量前,请获取阿里云账号AccessKey(AccessKey ID和AccessKey Secret),以及您希望创建ECS实例的地域等信息。关于如何获取AccessKey,请参见创建AccessKey。
export ALIYUN_ACCESS_KEY_ID=**** #填入您的AccessKey ID export ALIYUN_ACCESS_KEY_SECRET=**** #填入您的AccessKey Secret export ALIYUN_DEFAULT_REGION=cn-beijing #填入您希望使用的地域(Region)
创建一台ECS实例。
命令示例如下,表示创建一台名为aiacc_solution的ECS实例,实例规格为ecs.gn7i-c32g1.32xlarge,镜像类型为aiacc_train_solution。
fastgpu create --name aiacc_solution -i ecs.gn7i-c32g1.32xlarge --machines 1 --image_type aiacc_train_solution添加安全组规则。
添加本机公网IP的22端口到默认安全组中。
fastgpu addip -a开放7860端口,用于访问WebUI。
以下命令示例表示向所有网段开放7860端口,开放后所有公网IP均可访问您的WebUI。您可以根据需要将
0.0.0.0/0改为特定网段,仅允许部分IP地址访问WebUI。fastgpu addip {aiacc_solution} 0.0.0.0/0 7860
通过SSH连接ECS实例。
您可以通过
fastgpu ssh {instance_name}命令连接ECS实例。示例如下:fastgpu ssh aiacc_solution
更多关于FastGPU的命令,请参见命令行使用说明。
启动训练
下载tmux并创建一个tmux session。
yum install tmux tmux说明训练耗时较长,建议在tmux session中启动训练,以免ECS断开连接导致训练中断。
进入Conda环境。
conda activate llama_train获取llama-7b-hf预训练权重。
下载llama-7b权重。
cd /root/LLaMA git lfs install git clone https://huggingface.co/decapoda-research/llama-7b-hf修复官方代码Bug。
sed -i "s/LLaMATokenizer/LlamaTokenizer/1" ./llama-7b-hf/tokenizer_config.json
创建并设置DeepSpeed配置文件。
cd LLaMA/stanford_alpacacat << EOF | sudo tee ds_config.json { "zero_optimization": { "stage": 3, "contiguous_gradients": true, "stage3_max_live_parameters": 0, "stage3_max_reuse_distance": 0, "stage3_prefetch_bucket_size": 0, "stage3_param_persistence_threshold": 1e2, "reduce_bucket_size": 1e2, "sub_group_size": 1e8, "offload_optimizer": { "device": "cpu", "pin_memory": true }, "offload_param": { "device": "cpu", "pin_memory": true }, "stage3_gather_16bit_weights_on_model_save": true }, "communication":{ "prescale_gradients": true }, "fp16": { "enabled": true, "auto_cast": false, "loss_scale": 0, "initial_scale_power": 32, "loss_scale_window": 1000, "hysteresis": 2, "min_loss_scale": 1 }, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false, "zero_force_ds_cpu_optimizer": false } EOF(可选)如果使用多台ECS实例进行训练,需配置hostfile。
本文使用一台ECS实例进行训练,可跳过此步骤。
如下示例表示配置两台ECS实例(GPU总数为8)时,需要填入每台ECS实例的内网IP和slots,其中slots表示进程数(即GPU数量)。
cat > hostfile <<EOF {private_ip1} slots=4 {private_ip2} slots=4 EOF启动训练。
启动训练的命令脚本如下,alpaca_data.json为指令数据集文件,
$MASTER_PORT请替换为2000-65535之间的随机端口号。deepspeed --master_port=$MASTER_PORT --hostfile hostfile \ train.py \ --model_name_or_path ../llama-7b-hf \ --data_path ./alpaca_data.json \ --output_dir ./output \ --report_to none \ --num_train_epochs 1 \ --per_device_train_batch_size 2 \ --per_device_eval_batch_size 2 \ --gradient_accumulation_steps 8 \ --evaluation_strategy "no" \ --save_strategy "steps" \ --save_steps 400 \ --save_total_limit 2 \ --learning_rate 2e-5 \ --weight_decay 0. \ --warmup_ratio 0.03 \ --lr_scheduler_type "cosine" \ --logging_steps 1 \ --deepspeed ./ds_config.json \ --tf32 False \ --bf16 False \ --fp16启动训练后预期返回如下:
 说明
说明训练完成大概需要7小时左右,在tmux session中进行训练的过程中,如果断开了ECS连接,重新登录ECS实例后执行
tmux attach命令即可恢复tmux session,查看训练进度。
效果展示
查看WebUI推理效果
查看原生预训练模型的推理效果。
进入Conda环境。
conda activate llama_train使用原生checkpoint文件进行推理。
cd /root/LLaMA/text-generation-webui ln -s /root/LLaMA/llama-7b-hf ./models/llama-7b-hf启动WebUI服务。
python /root/LLaMA/text-generation-webui/server.py --model llama-7b-hf --listen预期返回:

打开本地浏览器,访问ECS实例的公网IP地址加7860端口,如
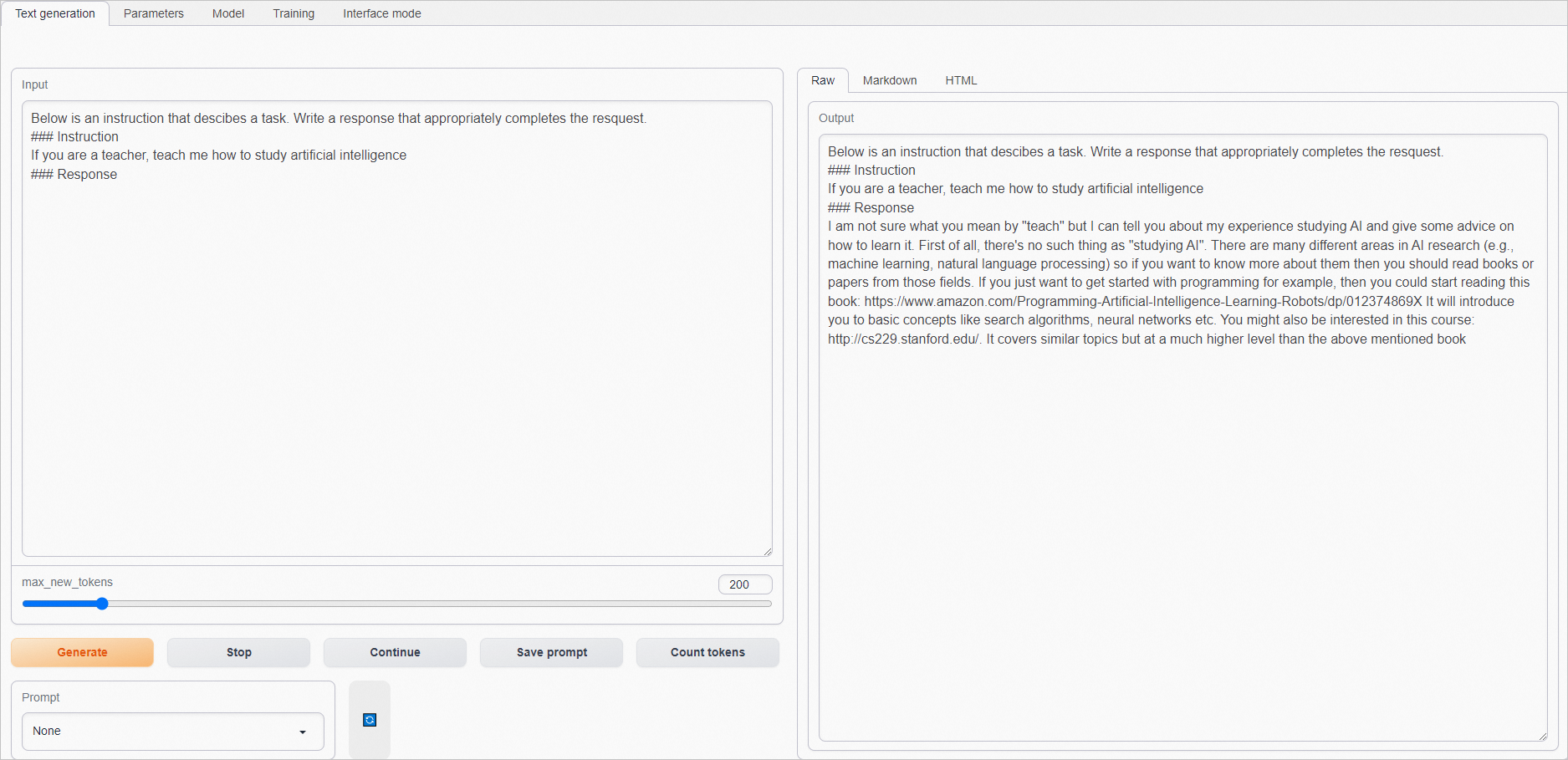
101.200.XX.XX:7860。在Input框中输入问题(建议输入英语),单击Generate,在Output框获取结果。
原生的预训练模型不能很好理解指令。示例如下:
等待训练完成后,查看指令微调后模型的推理效果。
重新连接ECS实例。
进入Conda环境。
conda activate llama_train使用训练完成的checkpoint文件进行推理。
cd /root/LLaMA/text-generation-webui ln -s /root/LLaMA/stanford_alpaca/output/checkpoint-800 ./models/llama-7b-hf-800启动WebUI服务。
python /root/LLaMA/text-generation-webui/server.py --model llama-7b-hf-800 --listen预期返回:

打开本地浏览器,访问ECS实例的公网IP地址加7860端口,如
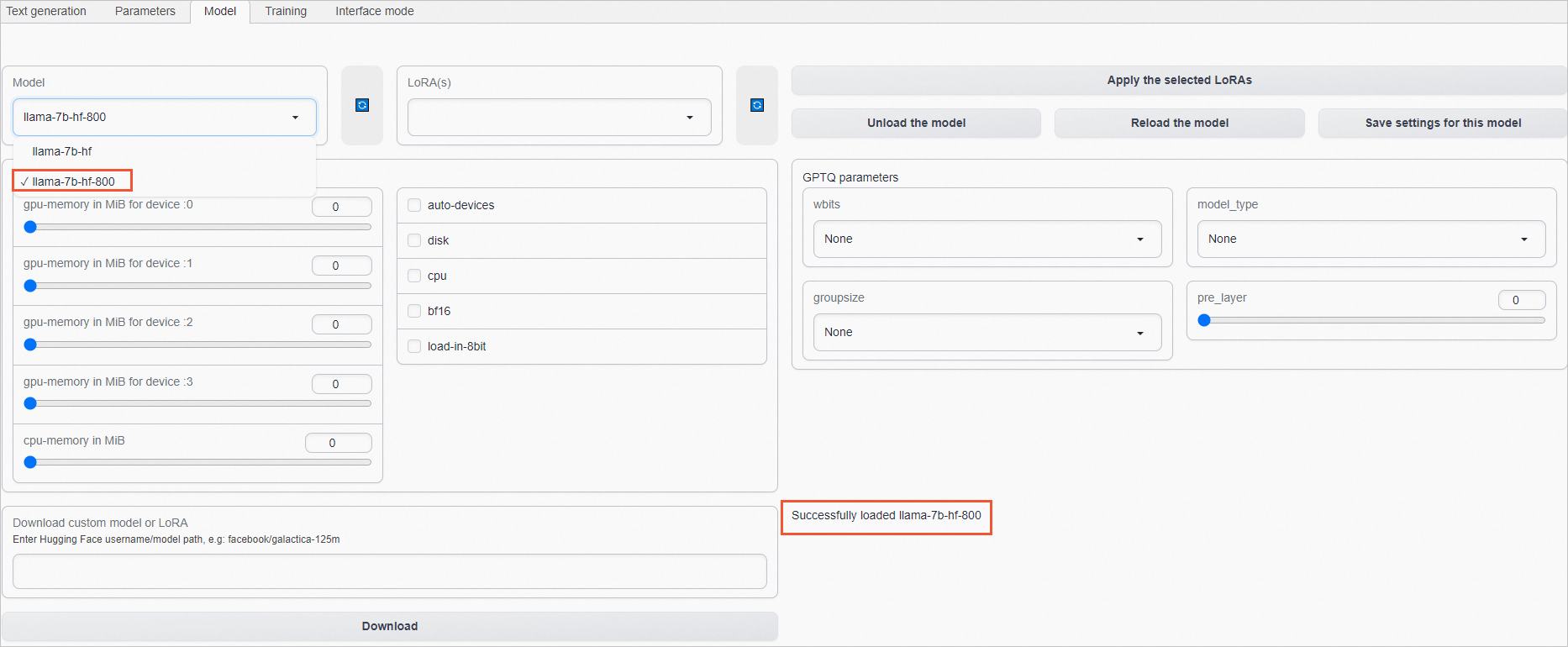
101.200.XX.XX:7860。单击Model页签,在Model模型列表中,选择指令微调后模型(如本文的llama-7b-hf-800)。
当页面右下角显示Successfully loaded llama-7b-hf-800时,说明该模型已加载完成。
说明llama-7b-hf-***后面的数字代表微调的step数,一般情况下,选择微调step数越大的模型,效果越好。
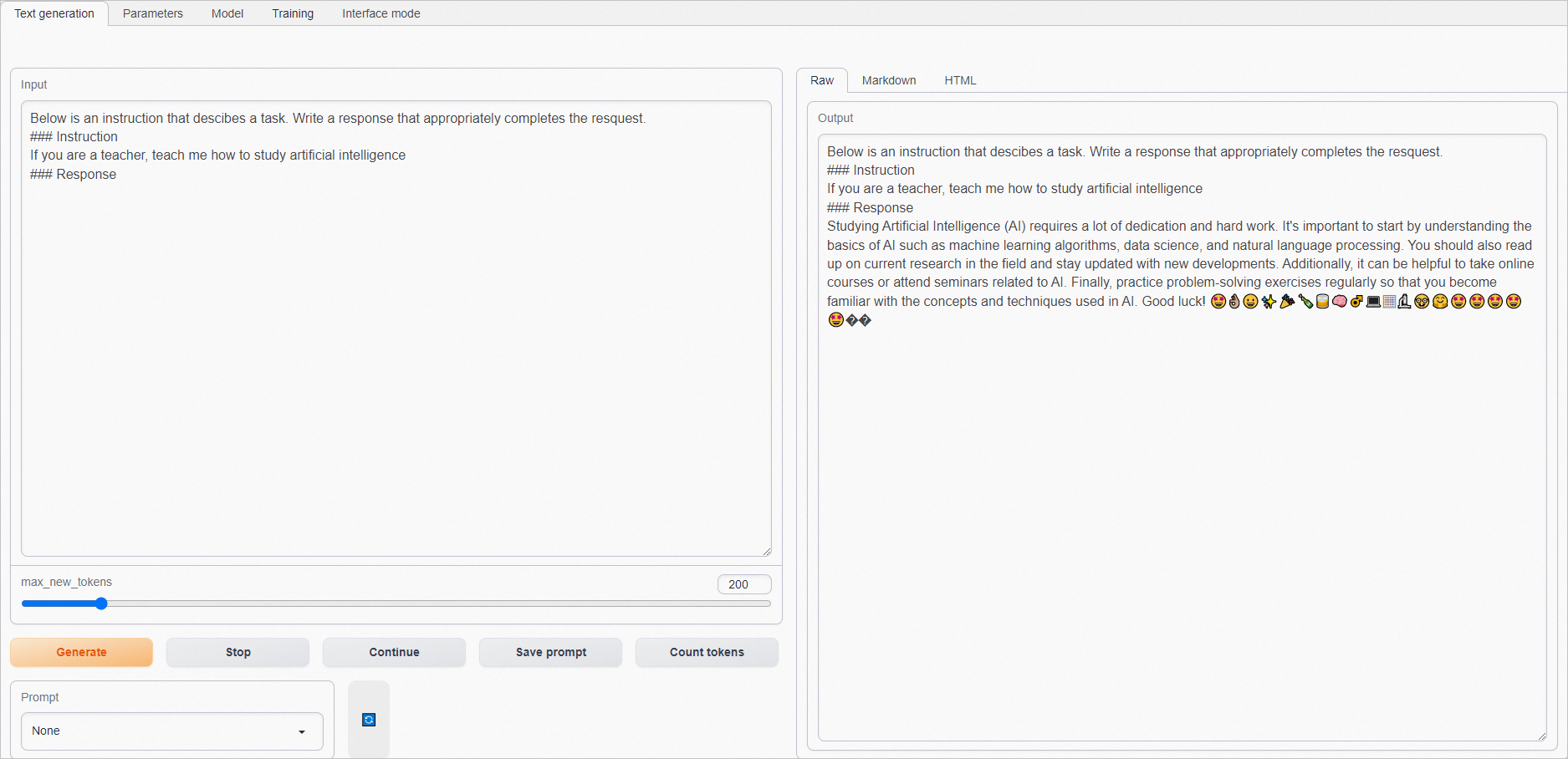
在Input框中输入问题(建议输入英语),单击Generate,在Output框获取结果。
指令微调后的模型能更好地理解指令,并生成更合理的答案。示例如下:
查看Deepytorch加速效果
以下是使用2台ecs.gn7i-c32g1.32xlarge规格的ECS实例(2*4 NVIDIA A10 GPU),基于DeepSpeed进行训练时,是否启动Deepytorch的性能对比。s/it代表训练每个iteration的时间,时间越短代表训练速度越快。由下图可以看出启动Deepytorch后相比原生DeepSpeed提速35%左右。
训练完成后,您可以在/root/LLaMA/stanford_alpaca/wandb/latest-run/files/output.log文件中了解性能。
使用DeepSpeed进行训练

使用DeepSpeed+Deepytorch Training进行训练

了解更多AIGC实践和GPU优惠
活动入口:立即开启AIGC之旅

反馈与建议
如果您在使用教程或实践过程中有任何问题或建议,可以加入客户钉钉群(钉钉群号:28335015590)与我们的工程师在线交流,将有专人跟进您的问题和建议。