使用vllm或sglang推理框架,在阿里云GPU实例上快速部署双机Qwen3-235B-A22B模型,并启用eRDMA加速。
费用说明
如果您按照ecs.ebmgn8v.48xlarge规格完成部署(大约需要50分钟)操作及体验,且时间不超过2小时,预计费用570元左右。实际情况中可能会因您操作过程中实际使用的流量差异,导致费用有所变化,请以控制台显示的实际报价以及最终账单为准。
操作步骤
步骤一:部署资源
为云服务器ECS实例构建云上的私有网络。
登录专有网络管理控制台,单击创建专有网络。
在创建专有网络页面,配置1个专有网络和1台交换机。
配置项
说明
示例值
VPC名称
名称长度为2-128个字符,以字母或中文开头,可包含数字、下划线(_)和连字符(-)。
VPC_QW
地域
选择计划创建云资源的地域。
华东1(杭州)
IPv4网段
在创建VPC时,须按照无类域间路由块(CIDR block)的格式为专有网络划分私网网段。
192.168.0.0/16
交换机名称
名称长度为2-128个字符,以字母或中文开头,可包含数字、下划线(_)和连字符(-)。
vsw_001
可用区
选择可用区时,优先考虑较新的可用区。较新的可用区通常拥有更充足的资源,并能优先获得新的实例规格。
杭州 可用区K
IPv4网段
虚拟交换机需要一个IPv4网段。
192.168.0.0/24
创建安全组用于控制云资源的入站和出站网络流量。
前往ECS控制台-安全组。
在页面左侧顶部,选择目标资源所在的资源组和地域。

单击创建安全组。
配置项
说明
示例值
安全组名称
设置安全组的名称。
SecurityGroup_1
网络
选择之前规划的专有网络VPC。
VPC_QW
规则配置
添加一条入站规则,放行
3000端口的流量,并移除其他所有默认规则。3000
创建两台GPU实例并正确安装驱动,未提及配置项均使用默认配置即可。
前往ECS控制台-自定义购买。
创建GPU实例,创建过程中需注意以下配置项,未说明的参数,可使用默认值。
配置项
说明
示例值
付费类型
付费类型影响实例的计费和收费规则。ECS 计费的详细信息请参见计费方式概述。
按量付费
地域
实例所在地域。
华东1(杭州)
网络及可用区
选择专有网络VPC和交换机。
VPC_QW、vsw_001
实例
ECS的实例规格及内核、vCPU 数量。关于 ECS选型的最佳实践请参见实例规格选型指导。
ecs.ebmgn8v.48xlarge
镜像
ECS的装机盘,为ECS实例提供操作系统、预装软件等。
在公共镜像中选择 Alibaba Cloud Linux
镜像的版本。
Alibaba Cloud Linux 3.2104 LTS 64位
安装 GPU 驱动。
勾选安装GPU驱动,在下拉列表中选择:
CUDA 版本 12.8.1/Driver 版本 570.133.20/CUDNN 版本 9.8.0.87
系统盘类型
硬盘类型。
ESSD 云盘
系统盘容量
硬盘容量。
100 GiB
数据盘
用于存放模型。
单击添加数据盘,容量填写500GiB,勾选随实例释放。
公网 IP
用于访问外网和提供企业门户网站服务。
选中分配公网 IPv4 地址
安全组
使用之前创建的安全组。选择已有安全组。
SecurityGroup_1
管理设置
选择设置自定义密码,方便后续登录机器安装服务环境。
自定义密码
步骤二:准备环境
在进行模型部署之前,需要先准备好运行环境,确保GPU资源能够被正确调用,并且通过Docker和 NVIDIA容器工具包实现环境的隔离和一致性。
执行以下脚本会在您的实例上安装Docker和NVIDIA容器工具包,当输出日志
安装完成表示成功安装。由于需要下载网络资源,安装脚本需要3-10分钟左右,请您耐心等待。
# 脚本支持Alibaba Cloud Linux、CentOS curl -fsSL https://help-static-aliyun-doc.aliyuncs.com/qwen3/install-script/install-docker.sh | bash初始化数据盘,并将数据盘挂载到
/mnt目录。执行
lsblk命令,查看数据盘的信息。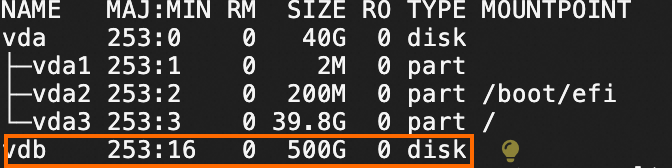
执行以下命令,创建并挂载文件系统至
/mnt目录下。sudo mkfs.ext4 /dev/vdb sudo mount /dev/vdb /mnt执行
lsblk命令,查看数据盘已挂载至/mnt目录下。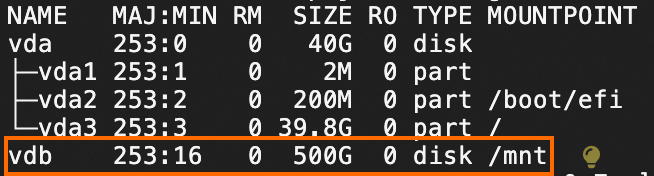
步骤三:下载模型
执行以下脚本通过ossutil下载模型文件(存储在/mnt/Qwen3-235B-A22B目录下),当输出日志
Qwen3-235B-A22B downloads successfully!表示模型下载成功。说明由于模型较大,下载时间为15-20分钟左右,请您耐心等待。
模型下载是通过ossutil并使用
cp命令在内网环境执行下载,以起到下载加速的目的,如果您的ECS在非杭州地域,执行下载脚本会出现网络连接错误,您也可以通过ModelScope的模型库下载Qwen3-235B-A22B。
curl -fsSL https://help-static-aliyun-doc.aliyuncs.com/qwen3/install-script/235b-a22b-0522/download.sh | bash
步骤四:部署模型
第一次启动容器时需要下载推理服务镜像,耗时约10至15分钟,请您耐心等待。
启动容器
vllm
# 定义模型名称。 MODEL_NAME="Qwen3-235B-A22B" # 设置本地存储路径。 LOCAL_SAVE_PATH="/mnt/Qwen3-235B-A22B" # 确保当前用户对该目录有读写权限,根据实际情况调整权限 sudo chmod ugo+rw ${LOCAL_SAVE_PATH} # 启动Docker容器 docker run -t -d \ --name="vllm-test" \ --ipc=host \ --cap-add=SYS_PTRACE \ --network=host \ --gpus all \ --privileged \ --ulimit memlock=-1 \ --ulimit stack=67108864 \ -v /mnt:/mnt \ -e NCCL_SOCKET_IFNAME=eth0,eth1 \ -e NCCL_IB_DISABLE=0 \ -e GLOO_SOCKET_IFNAME=eth0 \ egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/vllm:0.8.5-pytorch2.6-cu124-20250429sglang
# 定义模型名称。 MODEL_NAME="Qwen3-235B-A22B" # 设置本地存储路径。 LOCAL_SAVE_PATH="/mnt/Qwen3-235B-A22B" # 确保当前用户对该目录有读写权限,根据实际情况调整权限 sudo chmod ugo+rw ${LOCAL_SAVE_PATH} # 启动Docker容器 docker run -t -d \ --name="vllm-test" \ --ipc=host \ --cap-add=SYS_PTRACE \ --network=host \ --gpus all \ --privileged \ --ulimit memlock=-1 \ --ulimit stack=67108864 \ -v /mnt:/mnt \ -e NCCL_SOCKET_IFNAME=eth0,eth1 \ -e NCCL_IB_DISABLE=0 \ -e GLOO_SOCKET_IFNAME=eth0 \ egs-registry.cn-hangzhou.cr.aliyuncs.com/egs/sglang:0.4.6.post1-pytorch2.6-cu124-20250429为容器部署eRDMA驱动程序包。
执行以下命令,进入
vllm-test容器。docker exec -it vllm-test bash部署eRDMA驱动程序包。
如果部署成功可以通过命令
ibv_devinfo查看到eRDMA设备信息。# 添加PGP签名 wget -qO - http://mirrors.cloud.aliyuncs.com/erdma/GPGKEY | sudo gpg --dearmour -o /etc/apt/trusted.gpg.d/erdma.gpg # 添加apt源 echo "deb [ ] http://mirrors.cloud.aliyuncs.com/erdma/apt/ubuntu jammy/erdma main" | sudo tee /etc/apt/sources.list.d/erdma.list # 更新apt源 sudo apt update # 安装用户态驱动 sudo apt install libibverbs1 ibverbs-providers ibverbs-utils librdmacm1 -y
创建集群推理环境。
执行以下命令,进入
vllm-test容器。docker exec -it vllm-test bash作为集群head节点。执行命令。
pip3 install ray ray start --head --dashboard-host 0.0.0.0会出现类似下述回显信息。
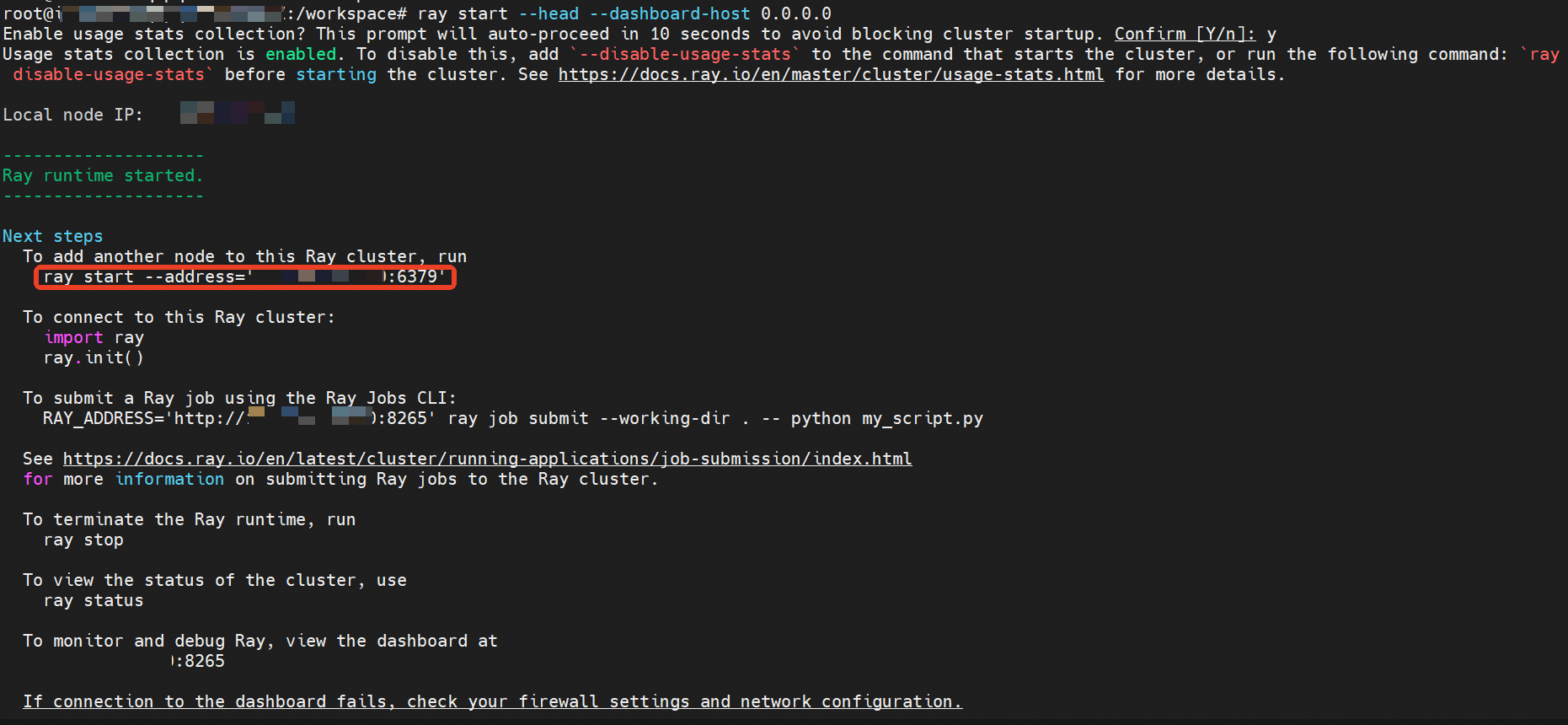
在另一个节点容器中运行上图红框内的命令,以创建Ray集群。随后在集群任一节点上运行
ray status命令,检查集群状态。
在任意节点的容器中运行以下命令,启动
Qwen3-235B-A22B推理服务。将/path/to/model替换为实际的模型路径。# 启动vllm推理服务 vllm serve /path/to/model \ --tensor-parallel-size 8 \ --pipeline-parallel-size 2 \ --trust-remote-code \ --enable-chunked-prefill \ --host 0.0.0.0 # 启动sglang推理服务 # 在node1容器上执行 python3 -m sglang.launch_server --model-path /path/to/model --port 8000 --tp 8 --nnodes 2 --ep 2 --trust-remote-code --host 0.0.0.0 --node-rank 0 --dist-init-addr <node1 ip>:50000
步骤四:推理测试验证
等待推理服务初始化完成。然后打开一个新终端,运行以下命令发送推理请求。命令的输出即为模型返回的结果。将
/path/to/model替换为容器内Qwen3-235B-A22B模型的存放路径。curl http://localhost:8000/v1/chat/completions \ -H "Content-Type:application/json" \ -d '{ "model":"/path/to/model", "messages":[{"role": "user", "content": "写一首20字的月亮诗"}], "stream":false}'进行模型性能评估。
在容器中克隆
ShareGPT_V3_unfiltered_cleaned_split数据集仓库。git lfs clone https://www.modelscope.cn/datasets/gliang1001/ShareGPT_V3_unfiltered_cleaned_split.git在容器终端运行命令,测试vllm/sglang serving模式的性能。将
/path/to/model替换为 Qwen3-235B-A22B模型在容器内的存储目录。将/path/to/ShareGPT_V3_unfiltered_cleaned_split.json替换为评估数据集的本地路径。vllm
# 启用vllm serving模式性能评估 # 获取vllm源码 git lfs clone https://github.com/vllm-project/vllm.git -b v0.8.5 python3 ./vllm/benchmarks/benchmark_serving.py \ --backend vllm \ --model /path/to/model \ --dataset-name random \ --random-output-len 4096 \ --random-input-len 512 \ --num-prompts 10 \ --max-concurrency 1 \ --dataset-path /path/to/ShareGPT_V3_unfiltered_cleaned_split/ShareGPT_V3_unfiltered_cleaned_split.jsonsglang
# 启用sglang serving模式性能评估 python3 -m sglang.bench_serving \ --backend sglang \ --model /path/to/model \ --port 8000 \ --dataset-name random \ --request-rate 8 \ --random-input 1024 \ --random-output 128 \ --random-range-ratio 1.0 \ --dataset-path /path/to/ShareGPT_V3_unfiltered_cleaned_split/ShareGPT_V3_unfiltered_cleaned_split.json
资源释放
在本文中,您创建了多个云资源。测试完方案后,您可以参考以下规则处理对应产品的实例,避免继续产生费用。