本文介绍如何在基于Intel® TDX (Trust Domain Extensions)技术的阿里云g8i通用型实例(简称TDX实例)中部署检索增强生成(Retrieval Augment Generation,RAG)方案。
背景信息
检索增强生成(Retrieval Augment Generation,RAG)是当前业界流行的AI应用框架,其利用专有知识库中的私有知识数据,在大模型的帮助下,对用户问题做出精确回答。广泛应用于企业级知识库、在线知识问答、智能助手等场景。然而,如何在云上构建一个安全可信的环境来保护专有数据的安全和隐私,是当前面临的一个挑战。
阿里云g8i通用型实例基于Intel® TDX技术(简称TDX实例),构建了基于硬件级别的更高安全等级的可信机密环境,保障租户系统级数据运行时的机密性与完整性。
本实践基于阿里云TDX实例,提供了一套端到端安全部署RAG(基于Haystack软件栈)在线问答系统的参考实现,保证用户数据在各个阶段的隐私和安全。您可以通过本文获取以下信息:
加深对阿里云服务器TDX加密技术的理解。
了解基于TDX加密技术实现的端到端的全数据生命周期安全方案。
获取云服务器TDX的参考框架和脚本,轻松上手使用。
架构说明
RAG利用预训练的大型语言模型,将提取到的知识片段融入回答生成的过程中,以丰富回答的内容和准确性。在知识提取的环节,凭借词向量的相似度来识别与用户问题最佳匹配的知识内容。而在回答生成的阶段,直接向语言模型注入这些精选的知识,以引导其生成更加符合实际语境的回答。
检索增强生成主要分为三部分:
文档处理:用户将上传的文档进行加密保护,在TDX实例中解密、分割和向量化,最后写入数据库。
检索:检索模型从数据库的大量文本中检索与问题相关的文档或段落,并依照相关性进行排名。
生成:大语言模型根据提示词和检索到的文档生成响应。
传统RAG架构方案
传统模式下,RAG框架存在多种安全威胁,包括落盘数据、前端查询数据、数据库、大语言模型等的安全威胁。构建和部署的RAG框架如下图所示。

基于TDX环境部署的RAG架构方案
采用TDX实例部署的RAG框架如下图:

方案构成
该架构主要分为云上部署和在线问答两部分,云上部署主要分为以下两部分。
服务部署方(Service deployer)在阿里云TDX实例中部署RAG服务,主要包括文档分割模块、向量数据库模块、排序模块、大语言模型模块、前端模块。
文档分割模块:对上传文档进行文本提取和分割等操作。
向量数据库模块:将文档分割模块生成的格式化数据向量化并存储在数据库中,在该框架中采用Faiss + MySQL的方式实现。
排序模块:将向量化之后的用户问题和向量数据库中的数据进行比较,输出匹配度高的文本信息给大模型。
大语言模型模块:利用排序模块输出的文本信息,并结合特定提示词,给出用户最终的回答。
前端模块:用于向用户提供Q&A交互界面,接收用户的提问,并将大语言模型模块生成的回答反馈给用户。
服务部署方将待分析的文档上传至数据库。
方案优势
该方案能够解决传统RAG架构中提到的安全威胁,包括:
构建了基于TDX RA-TLS的通信方案,在前端和后端之间建立了远程认证,以保护用户请求信息。
将RAG运行在Trust Domain VM中,保护了运行时安全。
数据可以存储在机密数据库中,提供了全密态数据保护。
通过LUKS实现数据落盘保护,保护了上传的文档数据及大语言模型的存储安全。
方案安全保护
本方案主要在以下三个方面提供数据安全和隐私保护:
内存加密:RAG前端和后端服务均运行在内存加密的TD环境中,防止恶意参与方窃取TD环境中程序运行时的信息。
RA-TLS通信:当RAG框架中的所有Docker镜像不在同一台TDX实例中部署时,可以采用RA-TLS(Remote Attestation-TLS)通信方案来验证远端通信节点的身份,并保证网络传输过程中的数据安全。有关RA-TLS的详细信息,请参见RA-TLS Enhanced gRPC。
LUKS加密和OSS服务:通过使用LUKS加密技术和OSS服务,保护数据库中的数据落盘,有效防止恶意参与方在数据落盘之后通过磁盘窃取模型信息。
操作步骤
步骤一:创建TDX实例
前往实例创建页。
按照界面提示完成参数配置,创建一台ECS实例。
需要注意的参数如下,其他参数的配置,请参见自定义购买实例。
实例:为了保证模型运行的稳定,实例规格至少需要选择ecs.g8i.4xlarge(64 GiB内存)。
镜像:选择Alibaba Cloud Linux 3.2104 LTS 64位 UEFI版镜像,并选中机密虚拟机复选框。
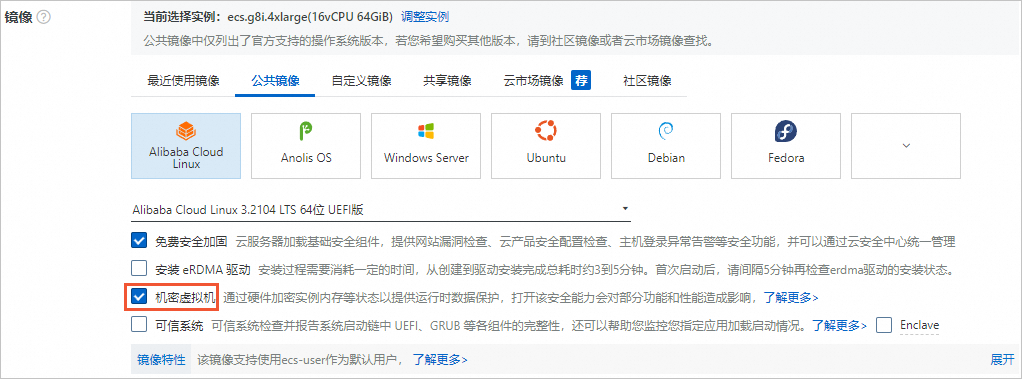
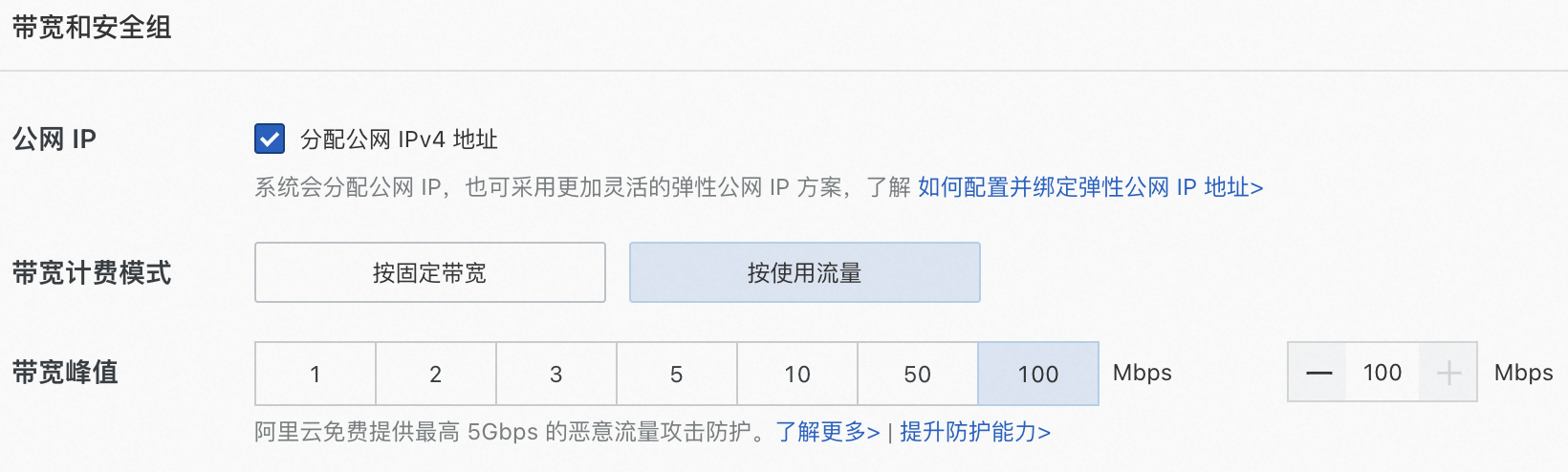
公网IP:选中分配公网IPv4地址,带宽计费模式选择按使用流量,带宽峰值设置为100 Mbps。以加快模型下载速度。
数据盘:建议数据盘设置为100 GiB。
安全组:开通22、80、8502端口。
安装Python 3.8。
系统自带的Python版本为3.6,不满足当前实践的最低版本要求,因此需要安装Python 3.8。
安装Python 3.8软件包。
sudo yum install -y python38设置Python 3.8为默认版本。
sudo update-alternatives --config python运行过程中,请输入
4,选择Python 3.8为默认版本。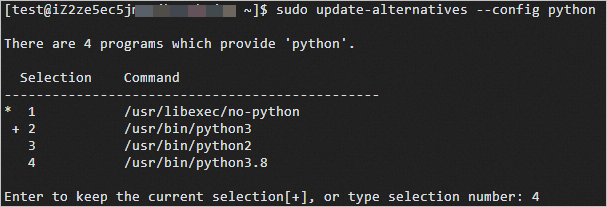
更新Python对应的pip版本。
sudo python -m ensurepip --upgrade sudo python -m pip install --upgrade pip
步骤二:部署Docker镜像
在已创建的TDX实例中安装Docker。
具体操作,请参见在Alibaba Cloud Linux 3中安装Docker。
下载CCZoo到ECS实例中。
CCZoo基于Intel TEE(SGX&TDX)技术,提供了不同场景下各种典型端到端安全解决方案的参考案例,增加用户在机密计算方案实现上的开发体验,并引导用户结合参考案例快速设计自己特定的机密计算解决方案。
说明<workdir>请替换为实际的工作目录,本文以/home/ecs-user为例。cd <workdir> git clone https://github.com/intel/confidential-computing-zoo.git下载或编译Docker镜像。
说明下载或编译Docker镜像时间较长,请耐心等待。
从Docker Hub中下载Docker镜像。
sudo docker pull intelcczoo/tdx-rag:backend sudo docker pull intelcczoo/tdx-rag:frontend编译Docker镜像。
cd confidential-computing-zoo/cczoo/rag ./build-images.sh
步骤三:创建加密分区
创建加密分区。
创建加密目录来存储模型文件及文档数。
cd confidential-computing-zoo/cczoo/rag/luks_tools sudo yum install -y cryptsetup VFS_SIZE=30G VIRTUAL_FS=/home/vfs sudo ./create_encrypted_vfs.sh ${VFS_SIZE} ${VIRTUAL_FS}出现
Are you sure? (Type 'yes' in capital letters):时,请输入YES。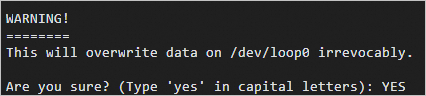
出现
Enter passphrase for /home/vfs:时,请输入加密分区的密码。
加密分区创建完成后,会输出循环设备号,如下图的
/dev/loop1。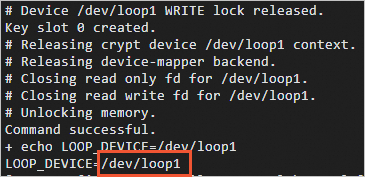
创建LOOP_DEVICE环境变量来绑定循环设备。
<the binded loop device>请替换成上一步获取的循环设备号。export LOOP_DEVICE=<the binded loop device>将块循环设备格式化为ext4。
创建
/home/encrypted_storage并为当前用户(以ecs-user为例)添加权限。sudo mkdir /home/encrypted_storage sudo chown -R ecs-user:ecs-user /home/encrypted_storage/将块循环设备格式化为ext4。
./mount_encrypted_vfs.sh ${LOOP_DEVICE} format出现
Enter passphrase for /home/vfs:时,请输入步骤1.b中设置的密码。
出现如下图所示时,说明块循环设备已格式化完成。
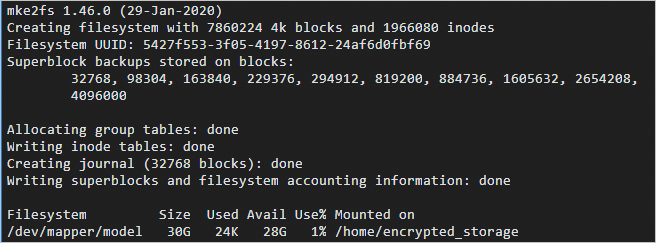
步骤四:下载数据与后端模型
阿里云不对第三方模型的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。
您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
默认情况下,数据与后端模型说明如下:
文档数据:
<workdir>/confidential-computing-zoo/cczoo/rag/data/data.txt中的示例内容。后端LLM:Llama-2-7b-chat-hf。
排序模型:ms-marco-MiniLM-L-12-v2。
encoder模型:dpr-ctx_encoder-single-nq-base和dpr-question_encoder-single-nq-base。
本步骤介绍从魔搭社区及Hugging Face镜像网站下载所需模型的步骤如下。如果您想使用其它模型,也可以参考以下步骤。
您也可以从OSS服务中获取自己已经上传的模型或数据,更多信息,请参见从OSS中下载文件到本地。
ossutil64 cp oss://<your dir>/<your file or your data> /home/encrypted_storage切换到
/home/encrypted_storage目录。cd /home/encrypted_storage安装modelscope运行库并设置环境变量。
pip install modelscope export MODELSCOPE_CACHE=/home/encrypted_storage下载Llama-2-7b-chat-hf模型。
python3.8 -c "from modelscope import snapshot_download; model_dir = snapshot_download('shakechen/Llama-2-7b-chat-hf')" mv shakechen/Llama-2-7b-chat-hf Llama-2-7b-chat-hf安装huggingface_hub运行库并设置环境变量。
pip install -U huggingface_hub export HF_ENDPOINT=https://hf-mirror.com下载预训练模型(排序模型和encoder模型)。
huggingface-cli download --resume-download --local-dir-use-symlinks False cross-encoder/ms-marco-MiniLM-L-12-v2 --local-dir ms-marco-MiniLM-L-12-v2 huggingface-cli download --resume-download --local-dir-use-symlinks False facebook/dpr-ctx_encoder-single-nq-base --local-dir dpr-ctx_encoder-single-nq-base huggingface-cli download --resume-download --local-dir-use-symlinks False facebook/dpr-question_encoder-single-nq-base --local-dir dpr-question_encoder-single-nq-base
步骤五:启动RAG服务
切换到rag目录。
cd <workdir>/confidential-computing-zoo/cczoo/rag启动数据库服务容器。
sudo ./run.sh db回显类似如下所示时,表示数据库服务容器已启动。
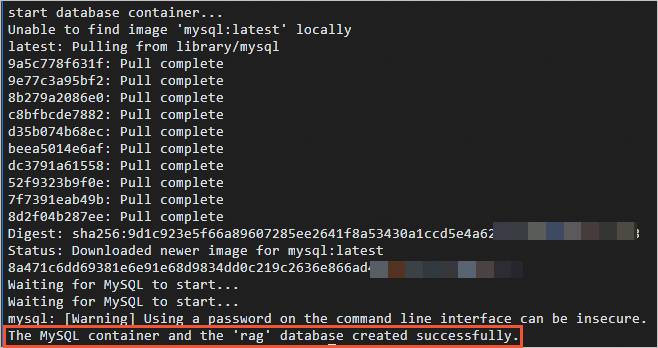
启动后端服务容器。
sudo ./run.sh backend在脚本执行过程中,
data.txt中的内容会被分割,并存放到数据库中,并需要根据提示分别输入数据库IP地址(本机公网IP地址)、数据库账号(默认为root)、数据库密码(默认为123456)。如果需要对数据库中的敏感数据进行加密,请参见阿里云全密态数据库概述。
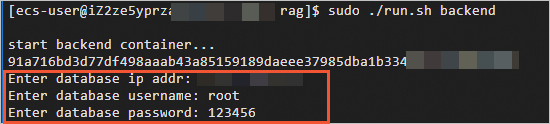
出现类似如下图所示时,表示后端服务容器已启动。

新创建一个会话终端,启动前端服务容器。
cd <workdir>/confidential-computing-zoo/cczoo/rag sudo ./run.sh frontend前端服务容器启动成功后,可以看到类似以下内容的消息。
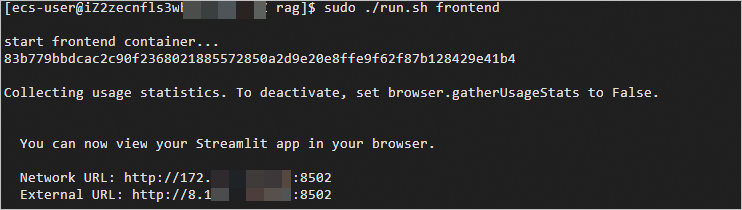
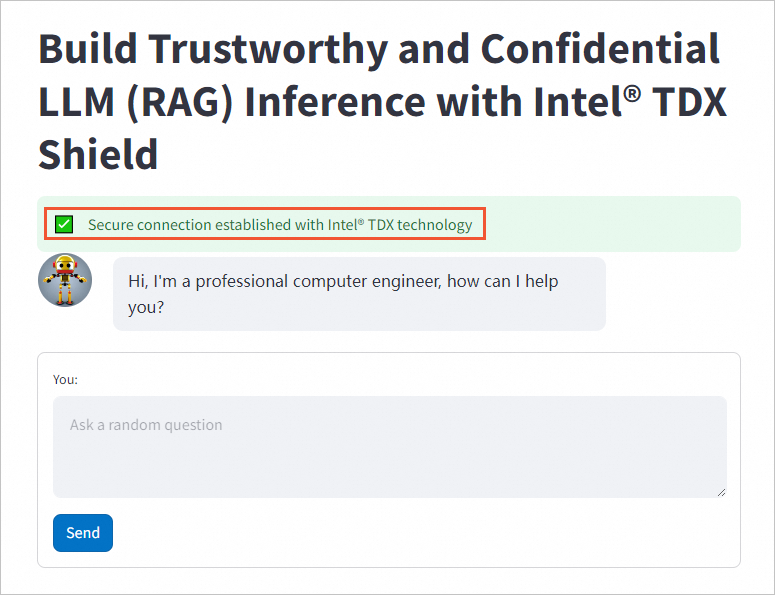
在本地浏览器中输入External URL,即可进行AI对话。
绿色提示框表示前端和后端之间建立了安全连接。关于RAG框架的定制化修改及问题,请参见Haystack。