本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
公共镜像可能存在一些已知的安全漏洞或配置问题。通过查看公共镜像的已知问题,可以帮助您了解这些问题的潜在安全风险,并采取相应的措施来快速定位和解决问题。
Windows操作系统已知问题
Linux操作系统已知问题
CentOS问题
Debian问题
Fedora CoreOS问题
OpenSUSE问题
Red Hat Enterprise Linux问题
SUSE Linux Enterprise Server问题
其他问题
Windows操作系统已知问题
Windows系统在512 MB内存规格上部分功能异常
问题描述
Windows Server Version 2004 数据中心版 64位中文版(不含图形化桌面)系统在内存为512 MB的实例规格上使用时,出现创建实例时设置的密码不生效,运行时无法修改密码、执行命令失败等问题。
问题原因
未开启页面文件导致虚拟内存无法分配,从而在执行程序时概率性出现异常。
解决方案
此类规格由于内存太小导致无法挂载PE,又因为实例创建时设置的密码不生效而导致无法正常登录,所以只能借助云助手来设置页面文件。
您可以通过以下方式使用云助手来执行命令。
通过会话管理器免密登录实例执行命令。具体操作,请参见通过会话管理连接实例。
通过云助手发送命令。具体操作,请参见发送远程命令。
通过以下命令开启页面文件自动管理。
Wmic ComputerSystem set AutomaticManagedPagefile=True说明该命令在执行时会概率性失败,请您多尝试几次直至命令执行成功。
您也可以通过
Wmic ComputerSystem get AutomaticManagedPagefile命令查询页面文件是否开启成功。如果显示如下回显信息,表示开启成功。AutomaticManagedPagefile TRUE
重启实例使配置生效。
Windows Server 2016运行软件安装包没有反应
问题描述
Windows Server 2016在系统内部运行下载的软件安装包时,没有任何反应。
问题原因
出于安全考虑,Windows系统会在启动过程中的sysprep阶段开启一个ProtectYourPC安全配置,此配置会使系统启动后携带SmartScreen系统进程,主要用于保护您免受恶意网站和不安全下载的侵害。
当您尝试从Internet下载或运行软件包时,软件包会带有Web网络标志,会触发系统的SmartScreen进程,SmartScreen识别到该软件来源于互联网,且可能缺乏足够的信誉信息因此会被拦截。
解决方案
您可以通过以下任意一种方式来解决:
解除软件包锁定
在软件包的属性中选中解除锁定。
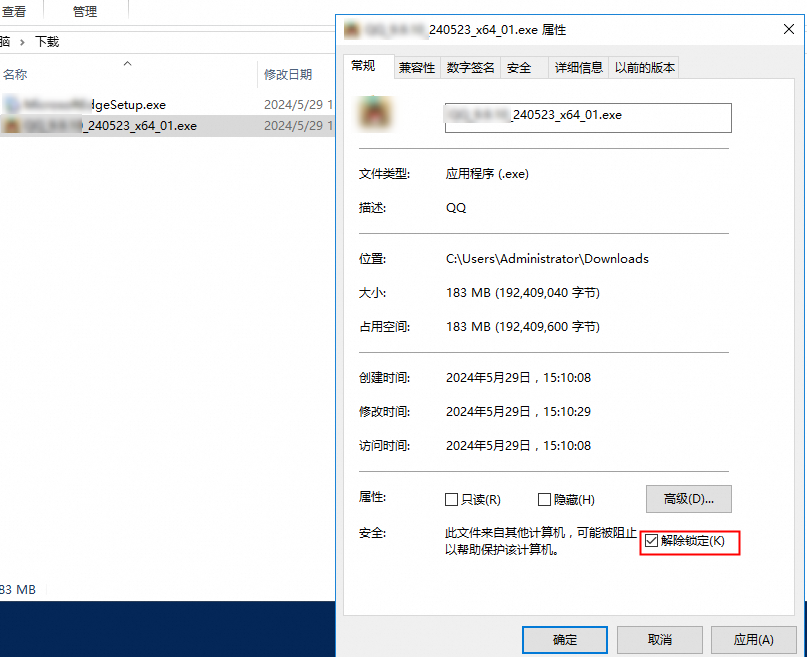
再次运行软件包。
关闭SmartScreen筛选器
进入
C:\Windows\System32目录。双击打开
SmartScreenSettings.exe文件。在Windows SmartScreen对话框中选择不执行任何操作(关闭Windows SmartScreen筛选器),然后单击确定。
再次运行软件包。
修改组策略配置
打开运行窗口,输入
gpedit.msc。在本地组策略编辑器中,依次选择计算机配置 > Windows设置 > 安全设置 > 本地策略 > 安全选项。
找到用户帐户控制:用于内置管理员帐户的管理员批准模式选项,然后单击右键选择属性。
在本地安全设置页签选择已启用选项,然后单击确定。
重启系统使配置生效。
再次运行软件包。
Windows Server 2022安装KB5034439补丁失败问题
问题描述
在Windows Server 2022系统上安装KB5034439失败。
问题原因
KB5034439是微软官方2024年01月恢复环境的更新,如果您配置使用的更新源是微软官方的Windows Update(镜像默认使用阿里云的WSUS更新服务器,不会更新到这个补丁)进行更新时会搜索安装到这个补丁,会出现安装失败的情况。这种现象符合预期,不影响正常使用。更多信息,请参见微软官方文档KB5034439: Windows Recovery Environment update for Windows Server 2022: January 9, 2024。
2022年06月补丁导致Windows服务器网卡NAT、RRAS异常等问题
问题描述:根据微软官方2022年06月23日的公告,Windows终端在安装微软官方2022年06月的安全补丁后,会出现网络接口上启用了NAT、RRAS服务器可能会失去连接、连接到服务器的设备也可能无法连接到Internet等风险。
影响范围:
Windows Server 2022
Windows Server 2019
Windows Server 2016
Windows Server 2012 R2
Windows Server 2012
Windows Server 2012 R2和Windows Server 2012版本检查系统更新时,请务必选择①处的检查更新。①处连接的更新源为阿里云内部的Windows WSUS更新服务器,②处连接的更新源为微软官方的Internet Windows Update服务器。因为在特殊情况下,安全更新可能会带来潜在问题,为了预防发生此类情况,我们会检查收到的微软Windows安全更新,将通过检查的更新发布到内部WSUS更新服务器中。
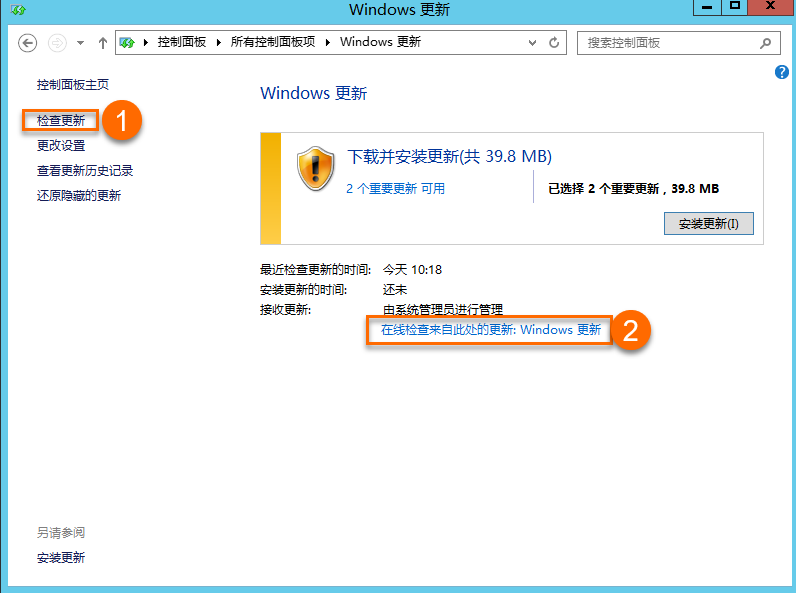
解决方案:阿里云官方提供的WSUS服务中,已经将相关问题补丁剔除。为了确保您的操作系统不会受到相关影响,请您在Windows终端中检测是否已经安装了相关问题补丁。检测补丁的CMD命令如下,您需要根据不同的Windows Server版本运行匹配的检测命令。
Windows Server 2012 R2: wmic qfe get hotfixid | find "5014738" Windows Server 2019: wmic qfe get hotfixid | find "5014692" Windows Server 2016: wmic qfe get hotfixid | find "5014702" Windows Server 2012: wmic qfe get hotfixid | find "5014747" Windows Server 2022: wmic qfe get hotfixid | find "5014678"如果检测结果中显示您已经安装了问题补丁,并且您的Windows服务器出现网卡NAT、RRAS异常等问题。建议您卸载相关问题补丁,以恢复终端至正常状态。卸载补丁的CMD命令如下,您需要根据不同的Windows Server版本运行匹配的卸载命令。
Windows Server 2012 R2: wusa /uninstall /kb:5014738 Windows Server 2019: wusa /uninstall /kb:5014692 Windows Server 2016: wusa /uninstall /kb:5014702 Windows Server 2012: wusa /uninstall /kb:5014747 Windows Server 2022: wusa /uninstall /kb:5014678说明关于该问题的进一步更新以及操作指导,请以微软官方说明为准。更多信息,请参见RRAS Servers can lose connectivity if NAT is enabled on the public interface。
2022年01月补丁导致Windows域控服务器异常问题
问题描述:根据微软官方2022年01月13日的公告,Windows终端在安装微软官方2022年01月的安全补丁后,会出现域控服务器无法重启(或无限重启)问题、Hyper-V中的虚拟机(VM)可能无法启动、IPSec VPN连接可能失败等风险。
影响范围:
Windows Server 2022
Windows Server, version 20H2
Windows Server 2019
Windows Server 2016
Windows Server 2012 R2
Windows Server 2012
Windows Server 2012 R2和Windows Server 2012版本检查系统更新时,请务必选择①处的检查更新。①处连接的更新源为阿里云内部的Windows WSUS更新服务器,②处连接的更新源为微软官方的Internet Windows Update服务器。因为在特殊情况下,安全更新可能会带来潜在问题,为了预防发生此类情况,我们会检查收到的微软Windows安全更新,将通过检查的更新发布到内部WSUS更新服务器中。
解决方案:阿里云官方提供的WSUS服务中,已经将相关问题补丁剔除。为了确保您的操作系统不会受到相关影响,请您在Windows终端中检测是否已经安装了相关问题补丁。检测补丁的CMD命令如下,您需要根据不同的Windows Server版本运行匹配的检测命令。
Windows Server 2012 R2: wmic qfe get hotfixid | find "5009624" Windows Server 2019: wmic qfe get hotfixid | find "5009557" Windows Server 2016: wmic qfe get hotfixid | find "5009546" Windows Server 2012: wmic qfe get hotfixid | find "5009586" Windows Server 2022: wmic qfe get hotfixid | find "5009555"如果检测结果中显示您已经安装了问题补丁,并且您的Windows终端出现域控服务器无法使用或者虚拟机无法启动的问题。建议您卸载相关问题补丁,以恢复终端至正常状态。卸载补丁的CMD命令如下,您需要根据不同的Windows Server版本运行匹配的卸载命令。
Windows Server 2012 R2: wusa /uninstall /kb:5009624 Windows Server 2019: wusa /uninstall /kb:5009557 Windows Server 2016: wusa /uninstall /kb:5009546 Windows Server 2012: wusa /uninstall /kb:5009586 Windows Server 2022: wusa /uninstall /kb:5009555说明关于该问题的进一步更新以及操作指导,请以微软官方说明为准。更多信息,请参见RRAS Servers can lose connectivity if NAT is enabled on the public interface。
经典网络中Windows Server 2022镜像的实例无法自动激活问题
目前经典网络类型的Windows Server 2022镜像的实例无法实现自动激活,您需要按照如下操作完成激活。
远程登录Windows实例。
具体操作,请参见通过密码或密钥认证登录Windows实例。
在Windows Server桌面,单击,输入cmd,然后按回车键后进入命令行窗口。
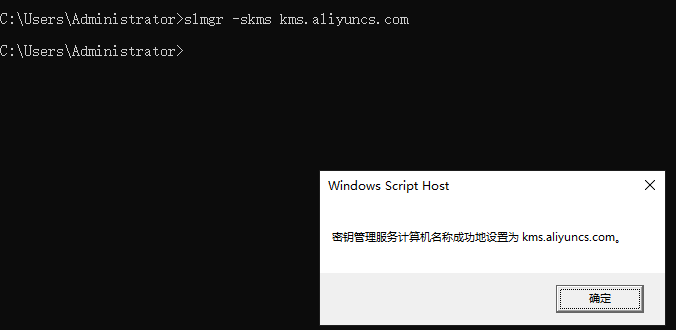
运行以下命令,配置KMS(Key Management Service)域名。
slmgr -skms kms.aliyuncs.com系统显示类似如下,表示配置成功,然后单击确定。
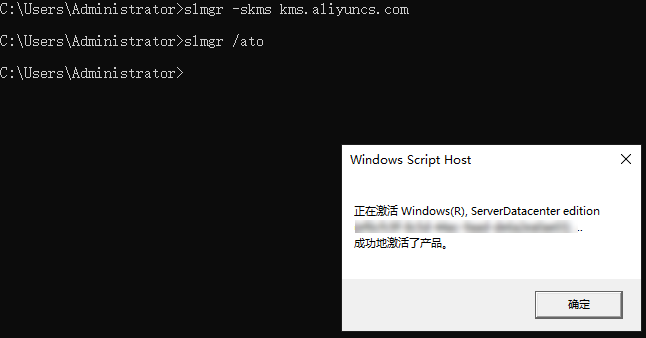
运行以下命令,激活KMS服务。
slmgr /ato系统显示类似如下,表示激活成功,然后单击确定。
Windows Server 2012 R2安装.NET 3.5失败的问题
问题描述:Windows Server 2012 R2系统使用以下版本的镜像默认已安装2023年06月补丁KB5027141、7月补丁KB5028872、8月份补丁KB5028970或者9月份补丁KB5029915,再安装.NET 3.5会出现失败的情况。
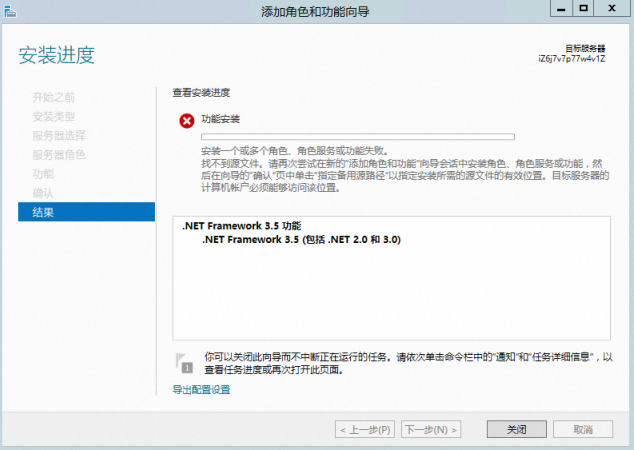
解决方案:
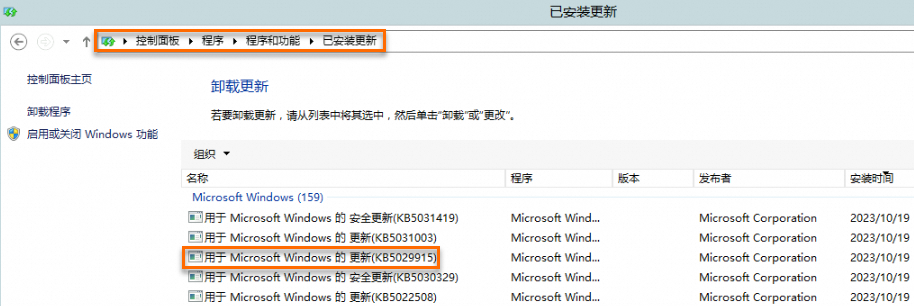
在控制面板找到KB5027141、KB5028872、KB5028970或者KB5029915补丁,单击右键选择卸载,手动卸载补丁。例如在如下图所示的路径下,卸载KB5029915补丁。
重启ECS实例。
具体操作,请参见重启实例。
通过以下任意一种方式,安装.NET Framework 3.5。
服务器管理器UI界面安装
在服务管理器中单击添加角色和功能。
按照向导默认配置进行操作,在功能栏中选中.NET Framework 3.5功能。
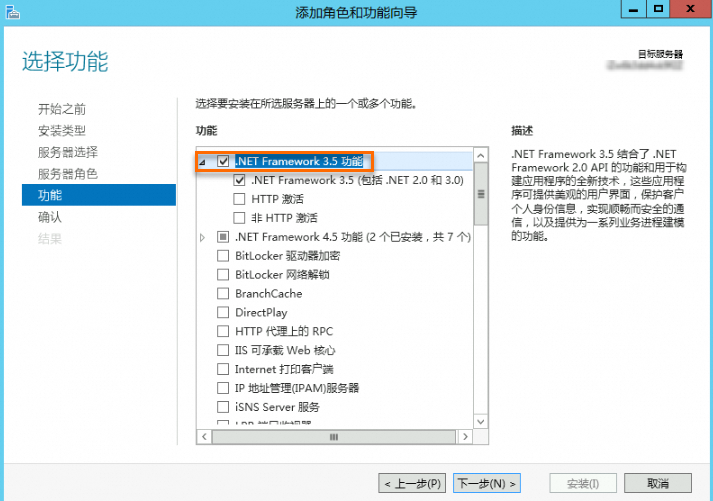
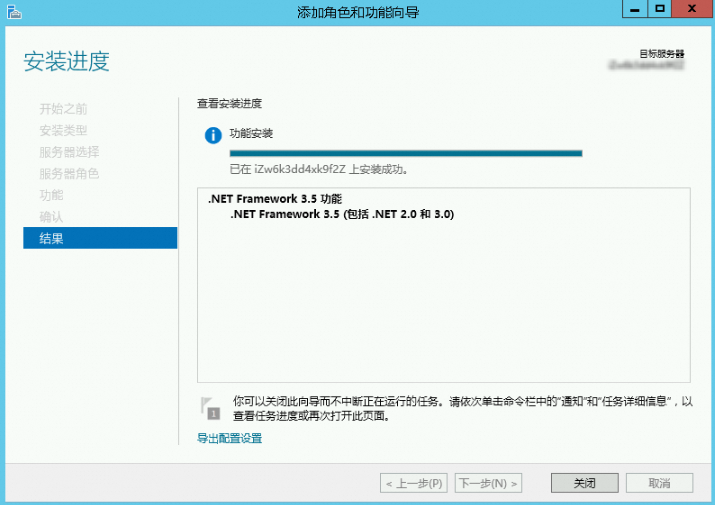
继续按照向导确认结果,直至安装完成。
执行PowerShell命令安装
您可以运行以下任意一条命令:
Dism /Online /Enable-Feature /FeatureName:NetFX3 /All
Install-WindowsFeature -Name NET-Framework-Features
Linux操作系统已知问题
CentOS问题
CentOS 8.0公共镜像命名问题
问题描述:使用centos_8_0_x64_20G_alibase_20200218.vhd公共镜像创建了CentOS系统实例,远程连接实例后检查系统版本,您发现实际为CentOS 8.1。
testuser@ecshost:~$ lsb_release -a LSB Version: :core-4.1-amd64:core-4.1-noarch Distributor ID: CentOS Description: CentOS Linux release 8.1.1911 (Core) Release: 8.1.1911 Codename: Core问题原因:该镜像出现在公共镜像列表中,已更新最新社区更新包,同时也升级了版本到8.1,所以实际版本是8.1。
涉及镜像ID:centos_8_0_x64_20G_alibase_20200218.vhd。
修复方案:如果您需要使用CentOS 8.0的系统版本,可以通过RunInstances等接口,设置
ImageId=centos_8_0_x64_20G_alibase_20191225.vhd创建ECS实例。
CentOS 7部分镜像ID变更可能引发的问题说明
问题描述:部分CentOS 7公共镜像更新了镜像ID,可能会影响到您自动化运维过程中获取镜像ID的策略。
涉及镜像:CentOS 7.5、CentOS 7.6
原因分析:CentOS 7.5和CentOS 7.6公共镜像在最新版本中使用的镜像ID格式为
%OS类型%_%大版本号%_%小版本号%_%特殊字段%_alibase_%日期%.%格式%。例如,CentOS 7.5的镜像ID前缀由原centos_7_05_64更新为centos_7_5_x64。您需要根据镜像ID的变更自行调整可能受影响的自动化运维策略。关于镜像ID的更多信息,请参见2023年。
CentOS 7重启系统后主机名大写字母被修改
问题描述:第一次重启ECS实例后,部分CentOS 7实例的主机名(hostname)存在大写字母变成小写字母的现象,如下表所示。
实例hostname示例
第一次重启后示例
后续是否保持小写不变
iZm5e1qe*****sxx1ps5zX
izm5e1qe*****sxx1ps5zx
是
ZZHost
zzhost
是
NetworkNode
networknode
是
涉及镜像:以下CentOS公共镜像,和基于以下公共镜像创建的自定义镜像。
centos_7_2_64_40G_base_20170222.vhd
centos_7_3_64_40G_base_20170322.vhd
centos_7_03_64_40G_alibase_20170503.vhd
centos_7_03_64_40G_alibase_20170523.vhd
centos_7_03_64_40G_alibase_20170625.vhd
centos_7_03_64_40G_alibase_20170710.vhd
centos_7_02_64_20G_alibase_20170818.vhd
centos_7_03_64_20G_alibase_20170818.vhd
centos_7_04_64_20G_alibase_201701015.vhd
涉及Hostname类型:如果您的应用有hostname大小写敏感现象,重启实例后会影响业务。您可根据下面的修复方案修复以下类型的hostname。
hostname类型
是否受影响
何时受影响
是否继续阅读文档
在控制台或通过API创建实例时,hostname中有大写字母
是
第一次重启实例
是
在控制台或通过API创建实例时,hostname中全是小写字母
否
不适用
否
hostname中有大写字母,您登录实例后自行修改了hostname
否
不适用
是
修复方案:如果重启实例后需要保留带大写字母的hostname时,可按如下步骤操作。
远程连接实例。
具体操作,请参见连接实例概述。
查看现有的hostname。
[testuser@izbp193*****3i161uynzzx ~]# hostname izbp193*****3i161uynzzx运行以下命令固化hostname。
hostnamectl set-hostname --static iZbp193*****3i161uynzzX运行以下命令查看更新后的hostname。
[testuser@izbp193*****3i161uynzzx ~]# hostname iZbp193*****3i161uynzzX
下一步:如果您使用的是自定义镜像,请更新cloud-init软件至最新版本后,再次创建自定义镜像。避免使用存在该问题的自定义镜像创建新实例后发生同样的问题。更多信息,请参见安装cloud-init和使用实例创建自定义镜像。
CentOS 6.8装有NFS Client的实例异常崩溃的问题
问题描述:加载了NFS客户端(NFS Client)的CentOS 6.8实例出现超长等待状态,只能通过重启实例解决该问题。
问题原因:在2.6.32-696~2.6.32-696.10的内核版本上使用NFS服务时,如果通信延迟出现毛刺(glitch,电子脉冲),内核nfsclient会主动断开TCP连接。若NFS服务端(Server)响应慢,nfsclient发起的连接可能会卡顿在FIN_WAIT2状态。正常情况下,FIN_WAIT2状态的连接默认在一分钟后超时并被回收,nfsclient可以发起重连。但是,由于此类内核版本的TCP实现有缺陷,FIN_WAIT2状态的连接永远不会超时,因此nfsclient的TCP连接永远无法关闭,无法发起新的连接,造成用户请求卡死(hang死),永远无法恢复,只能通过重启ECS实例进行修复。
涉及镜像ID:centos_6_08_32_40G_alibase_20170710.vhd和centos_6_08_64_20G_alibase_20170824.vhd。
修复方案:您可以运行yum update命令升级系统内核至2.6.32-696.11及以上版本。
重要操作实例时,请确保您已经提前创建了快照备份数据。具体操作,请参见创建快照。
Debian问题
Debian 9.6经典网络配置问题
问题描述:无法Ping通使用Debian 9公共镜像创建的经典网络类型实例。
问题原因:因为Debian系统默认禁用了systemd-networkd服务,经典网络类型实例无法通过DHCP(Dynamic Host Configuration Protocol)模式自动分配IP。
涉及镜像ID:debian_9_06_64_20G_alibase_20181212.vhd。
修复方案:您需要依次运行下列命令解决该问题。
systemctl enable systemd-networkdsystemctl start systemd-networkd
Fedora CoreOS问题
通过Fedora CoreOS自定义镜像创建的ECS实例中主机名不生效问题
问题描述:当您选择Fedora CoreOS镜像创建了一台ECS实例A,通过实例A创建了一个自定义镜像,然后通过该自定义镜像新建了一台ECS实例B时,您为实例B设置的主机名不生效(登录实例B查看实例B的主机名与实例A的主机名相同)。
例如,您有一台Fedora CoreOS操作系统的ECS实例(
实例A),主机名为test001,然后您使用该实例对应的自定义镜像新建了一台ECS实例(实例B),并且在创建实例的过程中,将实例B的主机名设置为了test002。当您成功创建并远程连接实例B后,实例B的主机名仍然为test001。问题原因:阿里云公共镜像提供的Fedora CoreOS镜像采用操作系统官方的Ignition服务进行实例初始化配置。Ignition服务是指Fedora CoreOS与Red Hat Enterprise Linux CoreOS在系统启动时进入initramfs期间用来操作磁盘的程序。ECS实例在首次启动时,Ignition中的
coreos-ignition-firstboot-complete.service会根据/boot/ignition.firstboot文件(该文件为空文件)是否存在,判断是否进行实例的初始化配置。如果文件存在,则进行初始化配置(其中包括配置主机名),并删除/boot/ignition.firstboot文件。由于创建Fedora CoreOS实例后至少启动了一次,则对应自定义镜像中的/boot/ignition.firstboot文件已被删除。当您使用该自定义镜像新建ECS实例时,实例首次启动并不会进行初始化配置,对应的主机名称也不会发生变化。
修复方案:
说明为确保实例中数据安全,建议您在操作前先为实例创建快照。如果实例发生数据异常,可通过快照将云盘回滚至正常状态。具体操作,请参见创建快照。
当您基于Fedora CoreOS实例创建自定义镜像前,先使用
root权限(管理员权限)在/boot目录下创建/ignition.firstboot文件。命令行操作说明如下:以读写方式重新挂载/boot。
sudo mount /boot -o rw,remount创建/ignition.firstboot文件。
sudo touch /boot/ignition.firstboot以只读方式重新挂载/boot。
sudo mount /boot -o ro,remount
关于Ignition相关的配置说明,请参见Ignition配置说明参考。
OpenSUSE问题
OpenSUSE 15内核升级可能导致启动hang的问题
问题描述:OpenSUSE内核版本升级到
4.12.14-lp151.28.52-default后,实例可能在某些CPU规格上启动hang,现已知的CPU规格为Intel® Xeon® CPU E5-2682 v4 @ 2.50GHz。对应的calltrace调试结果如下:[ 0.901281] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 0.901281] CR2: ffffc90000d68000 CR3: 000000000200a001 CR4: 00000000003606e0 [ 0.901281] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 0.901281] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 [ 0.901281] Call Trace: [ 0.901281] cpuidle_enter_state+0x6f/0x2e0 [ 0.901281] do_idle+0x183/0x1e0 [ 0.901281] cpu_startup_entry+0x5d/0x60 [ 0.901281] start_secondary+0x1b0/0x200 [ 0.901281] secondary_startup_64+0xa5/0xb0 [ 0.901281] Code: 6c 01 00 0f ae 38 0f ae f0 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 90 31 d2 65 48 8b 34 25 40 6c 01 00 48 89 d1 48 89 f0 <0f> 01 c8 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 ** **问题原因:新内核版本与CPU Microcode不兼容,更多信息,请参见启动hang问题。
涉及镜像:opensuse_15_1_x64_20G_alibase_20200520.vhd。
修复方案:在/boot/grub2/grub.cfg文件中,以
linux开头一行中增加内核参数idle=nomwait。文件修改的示例内容如下:menuentry 'openSUSE Leap 15.1' --class opensuse --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-20f5f35a-fbab-4c9c-8532-bb6c66ce****' { load_video set gfxpayload=keep insmod gzio insmod part_msdos insmod ext2 set root='hd0,msdos1' if [ x$feature_platform_search_hint = xy ]; then search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' 20f5f35a-fbab-4c9c-8532-bb6c66ce**** else search --no-floppy --fs-uuid --set=root 20f5f35a-fbab-4c9c-8532-bb6c66ce**** fi echo 'Loading Linux 4.12.14-lp151.28.52-default ...' linux /boot/vmlinuz-4.12.14-lp151.28.52-default root=UUID=20f5f35a-fbab-4c9c-8532-bb6c66ce**** net.ifnames=0 console=tty0 console=ttyS0,115200n8 splash=silent mitigations=auto quiet idle=nomwait echo 'Loading initial ramdisk ...' initrd /boot/initrd-4.12.14-lp151.28.52-default }
Red Hat Enterprise Linux问题
Red Hat Enterprise Linux 8 64位通过yum update命令更新内核版本不生效问题
问题描述:在Red Hat Enterprise Linux 8 64位操作系统的ECS实例中,运行yum update更新内核版本并重启实例后,发现内核版本仍为旧的内核版本。
问题原因:RHEL 8 64位操作系统中存储GRUB2环境变量的文件/boot/grub2/grubenv大小异常,该文件大小不是标准的1024字节,从而导致更新内核版本失败。
修复方案:您需要在更新内核版本后,将新的内核版本设置为默认启动版本。完整的操作说明如下所述:
运行以下命令,更新内核版本。
yum update kernel -y运行以下命令,获取当前操作系统的内核启动参数。
grub2-editenv list | grep kernelopts运行以下命令,备份旧的/grubenv文件。
mv /boot/grub2/grubenv /home/grubenv.bak运行以下命令,生成一个新的/grubenv文件。
grub2-editenv /boot/grub2/grubenv create运行以下命令,把新的内核版本设置为默认启动版本。
本示例中,更新后的新内核版本以
/boot/vmlinuz-4.18.0-305.19.1.el8_4.x86_64为例。grubby --set-default /boot/vmlinuz-4.18.0-305.19.1.el8_4.x86_64运行以下命令,设置内核启动参数。
其中,参数
- set kernelopts需要手动设置,取值为步骤2中获取到的当前操作系统内核启动参数信息。grub2-editenv - set kernelopts="root=UUID=0dd6268d-9bde-40e1-b010-0d3574b4**** ro crashkernel=auto net.ifnames=0 vga=792 console=tty0 console=ttyS0,115200n8 noibrs nosmt"运行以下命令,重启ECS实例至新的内核版本。
reboot警告重启实例会造成您的实例停止工作,可能导致业务中断,建议您在非业务高峰期时执行该操作。
SUSE Linux Enterprise Server问题
SUSE Linux Enterprise Server SMT Server连接失败问题
问题描述:您购买并使用阿里云付费镜像SUSE Linux Enterprise Server或SUSE Linux Enterprise Server for SAP时,会遇到SMT Server连接超时或异常的情况。当您尝试下载或更新组件时,返回类似于如下所示的报错信息:
Registration server returned 'This server could not verify that you are authorized to access this service.' (500)
Problem retrieving the respository index file for service 'SMT-http_mirrors_cloud_aliyuncs_com' location ****
涉及镜像:SUSE Linux Enterprise Server、SUSE Linux Enterprise Server for SAP
解决方案:您需要重新注册并激活SMT服务。
依次运行以下命令,重新注册并激活SMT服务。
SUSEConnect -d SUSEConnect --cleanup systemctl restart guestregister运行以下命令,验证SMT服务的激活状态。
SUSEConnect -s命令行返回示例如下,表示成功激活SMT服务。
[{"identifier":"SLES_SAP","version":"12.5","arch":"x86_64","status":"Registered"}]
SUSE Linux Enterprise Server 12 SP5 内核升级可能导致启动hang的问题
问题描述:SLES(SUSE Linux Enterprise Server)12 SP5之前的内核版本在升级至SLES 12 SP5,或SLES 12 SP5内部内核版本升级后,实例可能在某些CPU规格上启动hang。现已知的CPU规格为
Intel® Xeon® CPU E5-2682 v4 @ 2.50GHz与Intel® Xeon® CPU E7-8880 v4 @ 2.20GHz。对应的calltrace调试结果如下:[ 0.901281] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033 [ 0.901281] CR2: ffffc90000d68000 CR3: 000000000200a001 CR4: 00000000003606e0 [ 0.901281] DR0: 0000000000000000 DR1: 0000000000000000 DR2: 0000000000000000 [ 0.901281] DR3: 0000000000000000 DR6: 00000000fffe0ff0 DR7: 0000000000000400 [ 0.901281] Call Trace: [ 0.901281] cpuidle_enter_state+0x6f/0x2e0 [ 0.901281] do_idle+0x183/0x1e0 [ 0.901281] cpu_startup_entry+0x5d/0x60 [ 0.901281] start_secondary+0x1b0/0x200 [ 0.901281] secondary_startup_64+0xa5/0xb0 [ 0.901281] Code: 6c 01 00 0f ae 38 0f ae f0 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 90 31 d2 65 48 8b 34 25 40 6c 01 00 48 89 d1 48 89 f0 <0f> 01 c8 0f 1f 84 00 00 00 00 00 0f 1f 84 00 00 00 00 00 ** **问题原因:新内核版本与CPU Microcode不兼容。
修复方案:在
/boot/grub2/grub.cfg文件中,以linux开头一行中增加内核参数idle=nomwait。文件修改的示例内容如下:menuentry 'SLES 12-SP5' --class sles --class gnu-linux --class gnu --class os $menuentry_id_option 'gnulinux-simple-fd7bda55-42d3-4fe9-a2b0-45efdced****' { load_video set gfxpayload=keep insmod gzio insmod part_msdos insmod ext2 set root='hd0,msdos1' if [ x$feature_platform_search_hint = xy ]; then search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' fd7bda55-42d3-4fe9-a2b0-45efdced**** else search --no-floppy --fs-uuid --set=root fd7bda55-42d3-4fe9-a2b0-45efdced**** fi echo 'Loading Linux 4.12.14-122.26-default ...' linux /boot/vmlinuz-4.12.14-122.26-default root=UUID=fd7bda55-42d3-4fe9-a2b0-45efdced**** net.ifnames=0 console=tty0 console=ttyS0,115200n8 mitigations=auto splash=silent quiet showopts idle=nomwait echo 'Loading initial ramdisk ...' initrd /boot/initrd-4.12.14-122.26-default }
其他问题
部分高版本内核系统在部分实例规格上启动时可能出现Call Trace
问题描述:部分高版本内核系统(例如
4.18.0-240.1.1.el8_3.x86_64内核版本的RHEL 8.3、CentOS 8.3系统等),在部分实例规格(例如ecs.i2.4xlarge)上启动时可能出现如下所示的Call Trace:Dec 28 17:43:45 localhost SELinux: Initializing. Dec 28 17:43:45 localhost kernel: Dentry cache hash table entries: 8388608 (order: 14, 67108864 bytes) Dec 28 17:43:45 localhost kernel: Inode-cache hash table entries: 4194304 (order: 13, 33554432 bytes) Dec 28 17:43:45 localhost kernel: Mount-cache hash table entries: 131072 (order: 8, 1048576 bytes) Dec 28 17:43:45 localhost kernel: Mountpoint-cache hash table entries: 131072 (order: 8, 1048576 bytes) Dec 28 17:43:45 localhost kernel: unchecked MSR access error: WRMSR to 0x3a (tried to write 0x000000000000****) at rIP: 0xffffffff8f26**** (native_write_msr+0x4/0x20) Dec 28 17:43:45 localhost kernel: Call Trace: Dec 28 17:43:45 localhost kernel: init_ia32_feat_ctl+0x73/0x28b Dec 28 17:43:45 localhost kernel: init_intel+0xdf/0x400 Dec 28 17:43:45 localhost kernel: identify_cpu+0x1f1/0x510 Dec 28 17:43:45 localhost kernel: identify_boot_cpu+0xc/0x77 Dec 28 17:43:45 localhost kernel: check_bugs+0x28/0xa9a Dec 28 17:43:45 localhost kernel: ? __slab_alloc+0x29/0x30 Dec 28 17:43:45 localhost kernel: ? kmem_cache_alloc+0x1aa/0x1b0 Dec 28 17:43:45 localhost kernel: start_kernel+0x4fa/0x53e Dec 28 17:43:45 localhost kernel: secondary_startup_64+0xb7/0xc0 Dec 28 17:43:45 localhost kernel: Last level iTLB entries: 4KB 64, 2MB 8, 4MB 8 Dec 28 17:43:45 localhost kernel: Last level dTLB entries: 4KB 64, 2MB 0, 4MB 0, 1GB 4 Dec 28 17:43:45 localhost kernel: FEATURE SPEC_CTRL Present Dec 28 17:43:45 localhost kernel: FEATURE IBPB_SUPPORT Present问题原因:这部分内核版本社区更新合入了尝试Write MSR的PATCH,但部分实例规格(例如ecs.i2.4xlarge)由于虚拟化版本不支持Write MSR,导致出现该Call Trace。
修复方案:该Call Trace不影响系统正常使用及稳定性,您可以忽略该报错。
高主频通用型实例规格族hfg6与部分Linux内核版本存在兼容性问题导致panic
问题描述:目前Linux社区的部分系统,例如CentOS 8、SUSE Linux Enterprise Server 15 SP2、OpenSUSE 15.2等系统。在高主频通用型实例规格族hfg6的实例中升级新版本内核可能出现内核错误(Kernel panic)。calltrace调试示例如下:
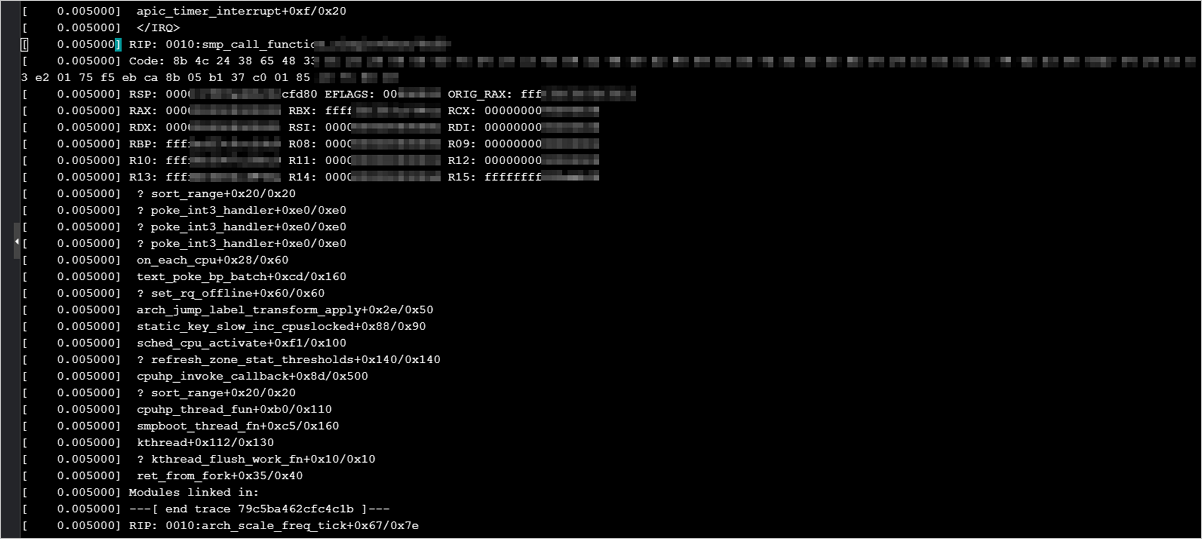
问题原因:高主频通用型实例规格族hfg6与部分Linux内核版本存在兼容性问题。
修复方案:
SUSE Linux Enterprise Server 15 SP2和OpenSUSE 15.2系统目前最新版内核已经修复。变更提交(commit)内容如下,如果您升级的最新版内核包含此内容,则已兼容实例规格族hfg6。
commit 1e33d5975b49472e286bd7002ad0f689af33fab8 Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:51:09 2020 +0200 x86, sched: Bail out of frequency invariance if turbo_freq/base_freq gives 0 (bsc#1176925). suse-commit: a66109f44265ff3f3278fb34646152bc2b3224a5 commit dafb858aa4c0e6b0ce6a7ebec5e206f4b3cfc11c Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:16:50 2020 +0200 x86, sched: Bail out of frequency invariance if turbo frequency is unknown (bsc#1176925). suse-commit: 53cd83ab2b10e7a524cb5a287cd61f38ce06aab7 commit 22d60a7b159c7851c33c45ada126be8139d68b87 Author: Giovanni Gherdovich <ggherdovich@suse.cz> Date: Thu Sep 24 16:10:30 2020 +0200 x86, sched: check for counters overflow in frequency invariant accounting (bsc#1176925).CentOS 8系统如果使用命令yum update升级到最新内核版本
kernel-4.18.0-240及以上,在高主频通用型实例规格族hfg6的实例中,可能出现Kernel panic。如果发生该问题,请回退至上一个内核版本。
pip操作时的超时问题
问题描述:pip请求偶有超时或失败现象。
涉及镜像:CentOS、Debian、Ubuntu、SUSE、OpenSUSE、Alibaba Cloud Linux。
原因分析:阿里云提供了以下三个pip源地址。其中,默认访问地址为mirrors.aliyun.com,访问该地址的实例需能访问公网。当您的实例未分配公网IP时,会出现pip请求超时故障。
(默认)公网:mirrors.aliyun.com
专有网络VPC内网:mirrors.cloud.aliyuncs.com
经典网络内网:mirrors.aliyuncs.com
修复方案:您可采用以下任一方法解决该问题。
方法一
为您的实例分配公网IP,即为实例绑定一个弹性公网IP(EIP)。具体操作,请参见将EIP绑定至ECS实例。
包年包月实例还可通过升降配重新分配公网IP。具体操作,请参见包年包月实例升配规格。
方法二
一旦出现pip响应延迟的情况,您可在ECS实例中运行脚本fix_pypi.sh,然后再重试pip操作。具体步骤如下:
远程连接实例。
具体操作,请参见使用VNC登录实例。
运行以下命令获取脚本文件。
wget http://image-offline.oss-cn-hangzhou.aliyuncs.com/fix/fix_pypi.sh运行脚本。
专有网络VPC实例:运行命令
bash fix_pypi.sh "mirrors.cloud.aliyuncs.com"。经典网络实例:运行命令
bash fix_pypi.sh "mirrors.aliyuncs.com"。
重试pip操作。
fix_pypi.sh脚本内容如下:
#!/bin/bash function config_pip() { pypi_source=$1 if [[ ! -f ~/.pydistutils.cfg ]]; then cat > ~/.pydistutils.cfg << EOF [easy_install] index-url=http://$pypi_source/pypi/simple/ EOF else sed -i "s#index-url.*#index-url=http://$pypi_source/pypi/simple/#" ~/.pydistutils.cfg fi if [[ ! -f ~/.pip/pip.conf ]]; then mkdir -p ~/.pip cat > ~/.pip/pip.conf << EOF [global] index-url=http://$pypi_source/pypi/simple/ [install] trusted-host=$pypi_source EOF else sed -i "s#index-url.*#index-url=http://$pypi_source/pypi/simple/#" ~/.pip/pip.conf sed -i "s#trusted-host.*#trusted-host=$pypi_source#" ~/.pip/pip.conf fi } config_pip $1