本文介绍如何使用DCDN边缘函数来优化前端网页HTML结构,进而减轻源站压力,降低客户回源流量成本,提升用户访问体验。
背景信息
边缘函数(EdgeRoutine,简称ER)是运行在DCDN边缘节点上的一种Serverless计算服务,您可上传自行编写的JavaScript代码来实现丰富的功能。一经部署,便可在全球3200+边缘节点上运行。当用户请求加速域名时,可直接触发ER的执行,随后继续执行DCDN的配置并回源;也可由ER完全接管用户请求,经过处理后直接返回结果给用户。
Web前端页面的修改是其主要应用场景之一,Web站点通常由三个重要部分组成:HTML文件,Javascript文件,CSS文件。通常网站开发完成后,网站服务端会动态输出HTML文件,该文件中包含了网页展示的HTML结构及JavaScript、CSS资源的获取地址。而通常这种HTML结构还需要根据用户的实际需求来进行不同的内容拼接和网页渲染,以返回给用户最合适的HTML文件。
方案优势
在DCDN的配置下,我们可以将Web前端页面所需的静态资源部署在边缘节点上,并在ER上编写JS代码来根据用户实际需求进行不同的前端页面渲染,这样的方案有以下优势:
减轻了源站服务器的压力,减少了回源请求次数和流量带宽,降低了企业流量成本。
减少了客户端性能的消耗,优化了用户的访问体验,提升了用户的访问速度。
应用场景
对于网站的JavaScript、CSS文件,一旦开发完成,那么在下一个版本上线前,这些文件是不会随着访问设备、时间等因素的变化而变化的。在版本发布后,任意一次用户请求所需要访问的内容均相同,因此便可将这些静态资源部署在边缘存储上。
对于网站的HTML文件,则需要根据用户业务的实际需求进行动态生成。常见场景如下:
根据用户请求设备的差异,生成不同的网页结构,例如PC端和移动端的网页布局差异很大。
根据用户请求的参数不同,生成不同的网站内容,例如请求参数的limit字段可用于控制内容条数。
场景一:根据用户请求设备的差异返回不同的网页结构
您目前有一个网站,并且同时支持PC端与移动端访问。那么不同设备的用户所需要返回的网页HTML结构必然存在着较大差异,需要加以区分。
传统方案
传统方案是在网站服务端根据请求头中的User-Agent信息判断用户设备,再根据用户设备渲染成不同的网页HTML结构,最后返回给客户端。其优势在于可根据业务逻辑灵活控制输出内容。但其缺点是会造成回源流量的大幅增加,且一旦用户请求激增时,服务端压力会骤然上升,进而导致大量待处理请求堆积,甚至出现服务不可用的情况。
优化方案
我们可以尝试用边缘函数(ER)来优化当前方案,在ER代码环境中提前判断用户的请求设备,控制返回的HTML。主要过程为:若DCDN缓存中包含对应设备的HTML,则直接返回给用户。若不存在,则将用户请求转发至源站,源站经过处理后将对应的HTML返回到ER,ER再将其返回给用户,并将其缓存到边缘节点上以供用户下一次请求时使用。

ER代码
// 使用请求中的User-Agent来解析用户请求设备
const getPlatform = (request) => {
const userAgentString = request.headers.get('user-agent') || '';
const mobile = /Android|iPhone|iPad/i.test(userAgentString);
const PC = /Window|Mac/i.test(userAgentString);
if (mobile) {
return 'mobile';
} else if (PC) {
return 'PC';
} else {
return 'unknown';
}
};
// 包含请求及后续操作所有信息的ctx构建函数
const createCtx = (event) => {
const ctx = {
// 创建一个去掉查询参数的新URL
remoteUrl: new URL(event.request.url),
// 将用户请求设备信息写入到ctx中
remoteInfo: getPlatform(event.request),
request: event.request.clone(),
response: null,
};
return ctx;
};
// CacheKey获取函数
const getCacheKey = (ctx) => {
const { remoteUrl, remoteInfo } = ctx;
const cacheUrl = new URL(`http://www.origin-server.com${remoteUrl.pathname}${remoteInfo}`);
return cacheUrl.toString();
};
// 根据用户请求设备返回不同的HTML
async function handle(event) {
const ctx = createCtx(event);
let { response } = ctx;
const cacheKey = getCacheKey(ctx);
const cacheResponse = await cache.get(cacheKey);
if (cacheResponse) {
// 命中缓存
console.log('Catch Response!');
response = cacheResponse;
} else {
// 若缓存中未包含用户请求的内容,则回源站获取HTML
console.log('No Catch Response!');
response = await fetch('http://www.origin-server.com', {
headers: ctx.request.headers,
});
// 将用户请求设备及其对应的源站响应存放到缓存中,以便下一次取用
await cache.put(cacheKey, response);
}
// 返回用户请求回浏览器
return new Response(response);
}
// 注册浏览器请求fetch事件监听函数
addEventListener('fetch', (event) => {
event.respondWith(handle(event));
});
首先定义一个getPlatform函数根据用户请求头中的User-Agent来判断用户设备是PC端还是移动端。
创建一个包含用户请求、用户访问URL、用户设备等信息的ctx函数以便后续使用。
根据源站信息、访问域名、用户设备信息构建一个CacheKey获取函数。
设置一个响应函数,根据用户请求设备返回不同的HTML。若命中缓存,则直接返回响应;若未命中,则回源站获取相应HTML内容,并根据CacheKey将返回内容缓存在边缘节点上,以便下一次取用。
注册一个回调函数用以监听fetch事件,即处理用户的访问请求。
cache.get()函数可能无法返回刚刚put的对象,这是由于缓存的LRU算法,Cache不保证一定可以取到。
调试过程
我们在演示过程中,将阿里云函数计算的HTTP触发器作为源站,并在DCDN边缘函数控制台上调试ER代码。
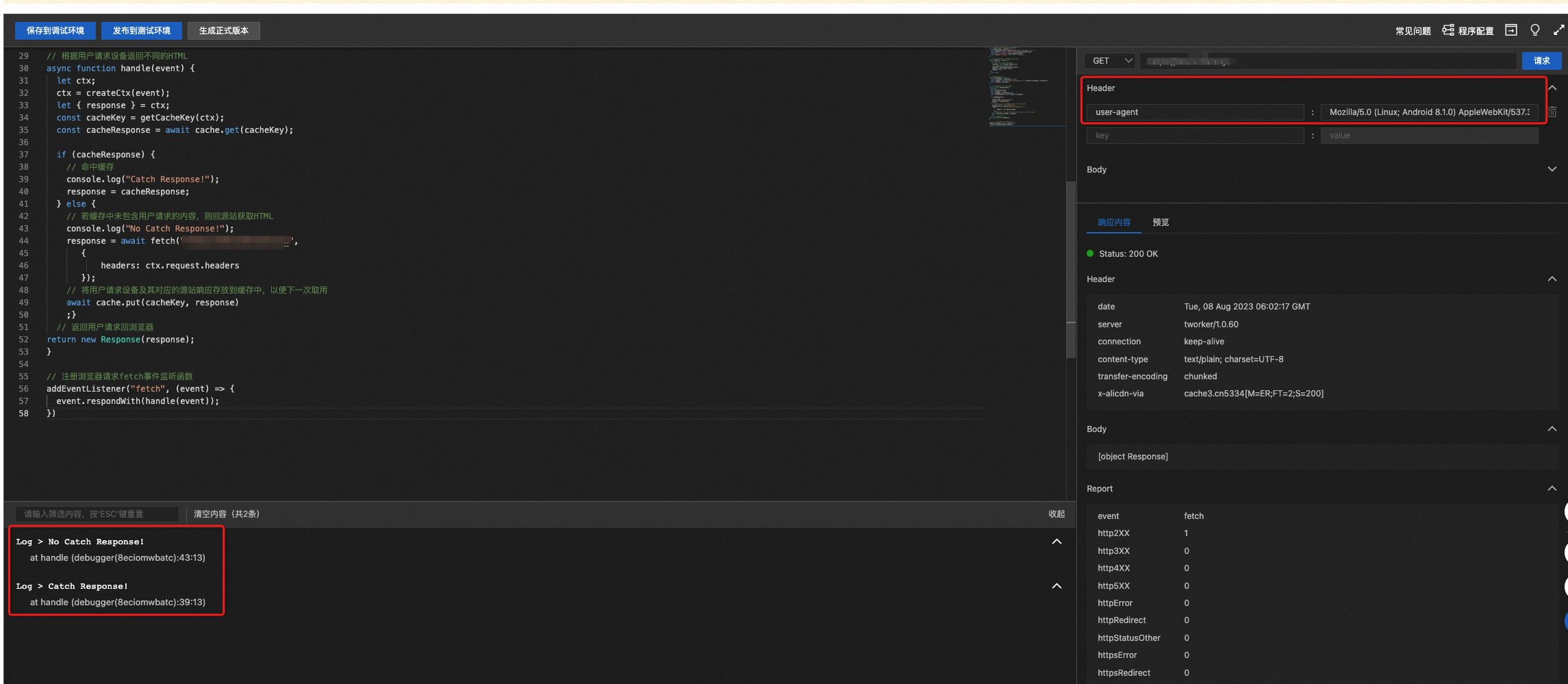
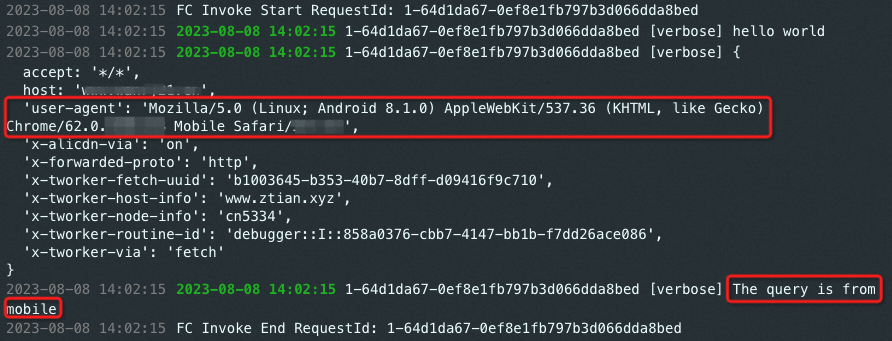
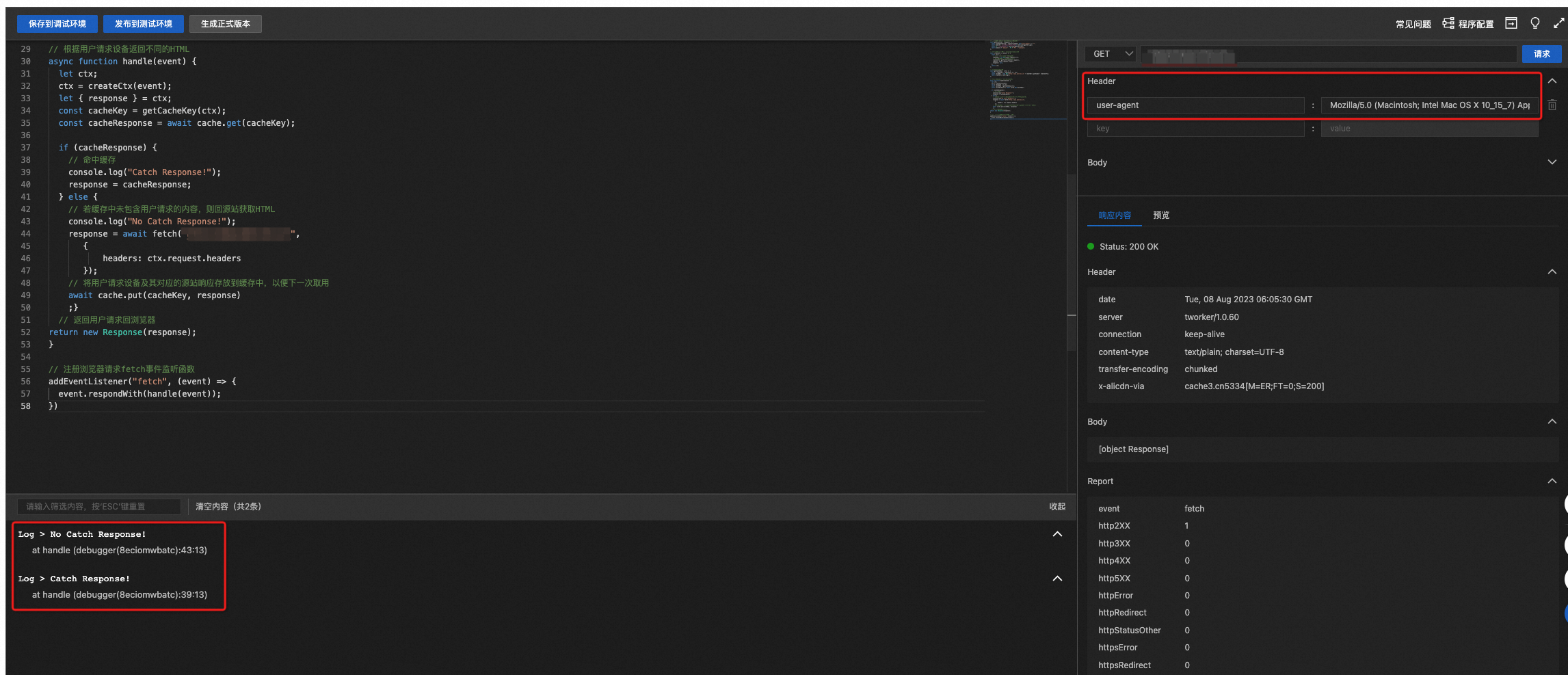
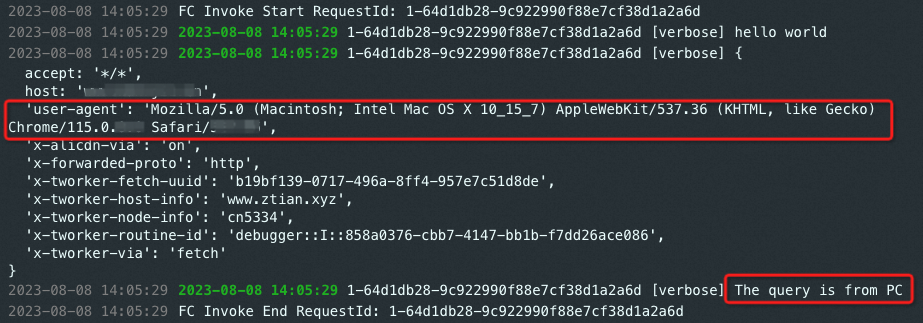
当第一次以
user-agent=Mozilla/5.0 (Linux; Android 8.1.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.XXXX.XX Mobile Safari/537.XX请求网站内容时,在ER控制台上会打印"No Cache Response",并回函数计算源站获取内容,此时在函数计算实时日志中也能探测到查询请求。当再次请求时,会在ER控制台上打印“Cache Response!”,并从缓存中读取内容返回,此时在函数计算实时日志中没有探测到查询请求。
配置
user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.XX Safari/537.XX进行再一次尝试,可以得到类似的结果。
场景二:根据用户请求参数的限制返回不同的网站内容
目前有一个网站,其网页内容是本年度Top100文章列表,访问量非常大且需按天更新列表。并且该网页支持用户自行设定需要查看的Top文章数目,例如若用户携带的请求头中limit=10,则需要返回给用户前10篇访问最多的文章。
传统方案
传统方案是在网站服务端根据请求的limit参数,动态查询数据库并将查询的结果渲染到HTML结构中,最后返回给客户端。优点是可以根据用户请求实时查询数据库内容并返回,但其缺点同样也是需要不断回源获取内容,并在服务端完成页面的渲染,这样会给服务端带来很大的压力。且一旦请求量激增,源站承受不住压力很可能会崩溃。
优化方案
我们可以将本年度Top100文章列表提前预热到DCDN边缘节点上,并且每天零点将最新的Top100文章列表进行更新。随后便可在ER上根据用户请求的limit参数控制返回的内容条数,大幅降低回源请求数,减少回源流量带宽成本。

ER代码
// 包含请求及后续操作所有信息的ctx构建函数
const createCtx = (event) => {
const ctx = {
// 创建一个去掉查询参数的新URL
remoteUrl: new URL(event.request.url),
request: event.request.clone(),
response: null,
};
return ctx;
};
// CacheKey获取函数
const getCacheKey = (ctx) => {
const { remoteUrl } = ctx;
const cacheUrl = new URL(`http://www.origin-server.com${remoteUrl.pathname}`);
return cacheUrl.toString();
};
async function handle(event) {
const ctx = createCtx(event);
let { response, request } = ctx;
const cacheKey = getCacheKey(ctx);
let cacheResponse = await cache.get(cacheKey);
if (cacheResponse) {
// 命中缓存
console.log('Catch Response!');
response = cacheResponse;
} else {
// 若缓存中未包含用户请求的内容,则回源站获取HTML
console.log('No Catch Response!');
response = await fetch('http://www.origin-server.com');
// 将响应复制一份以放进缓存
const response_new = response.clone();
// 将用户请求的内容响应存放到缓存中,以便下一次取用
await cache.put(cacheKey, response_new);
}
// 获取用户请求中的limit参数以控制词条数目
const limit = parseInt(request.headers.get('limit'));
let result = await response.json();
for (var i = limit + 1; i <= 100; ++i) {
var temp = ['TopItem_', String(i)].join('');
delete result.body[temp];
}
// 在控制台打印结果
console.log(result.body);
// 返回用户请求回浏览器
return new Response(JSON.stringify(result.body));
}
// 注册浏览器请求fetch事件监听函数
addEventListener('fetch', event => {
event.respondWith(handle(event));
});
创建一个包含用户请求、用户访问URL、用户设备等信息的ctx函数以便后续使用。
根据源站信息、访问域名、用户设备信息构建一个CacheKey获取函数。
设置一个响应函数,根据用户请求携带的
limit参数控制返回内容的条数。无论是否命中缓存,我们首先得到的是Top100词条内容,接着我们可以根据limit参数删去多余的词条内容,并将其封装成新的json内容返回给用户。注册一个回调函数用以监听fetch事件,即处理用户的访问请求。
调试过程
在调试过程中,我们同样将函数计算的HTTP触发器作为源站,并在DCDN边缘函数控制台上调试ER代码。
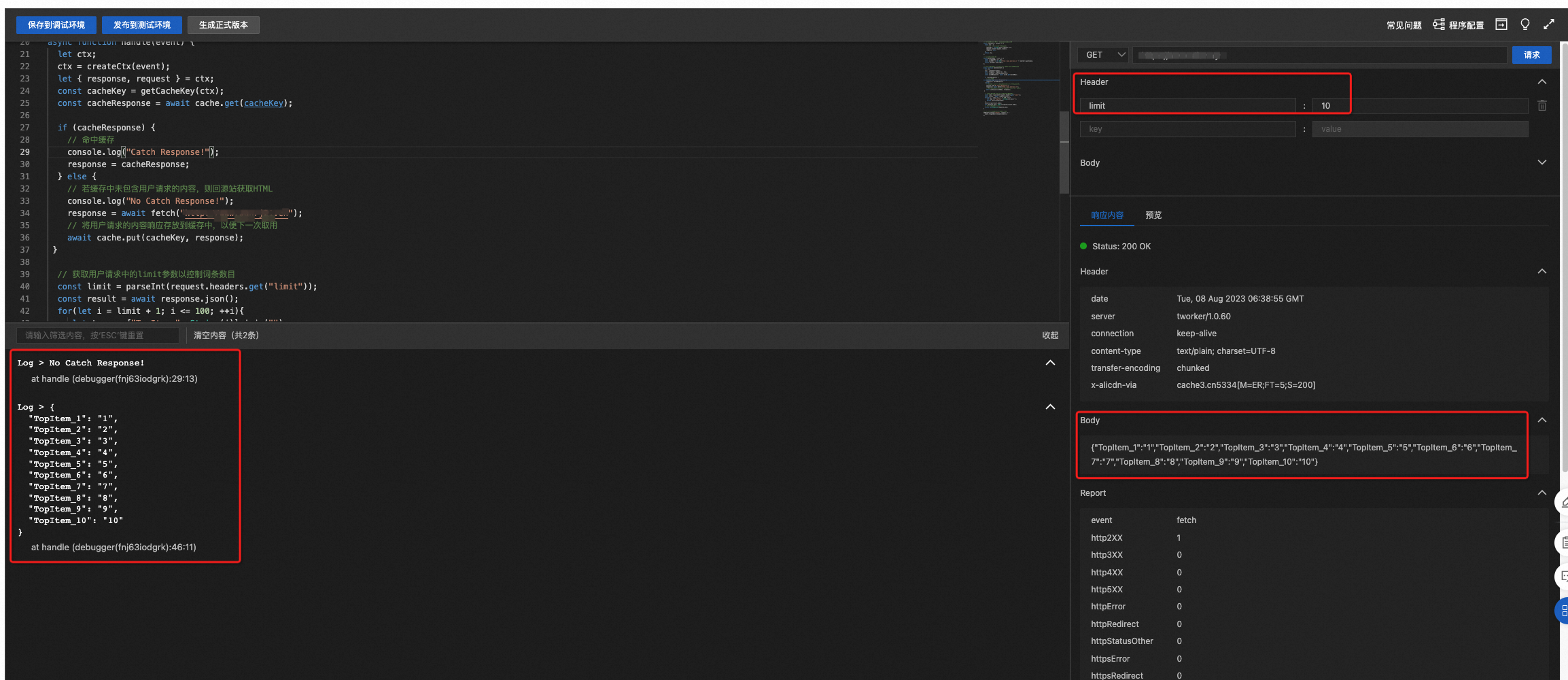
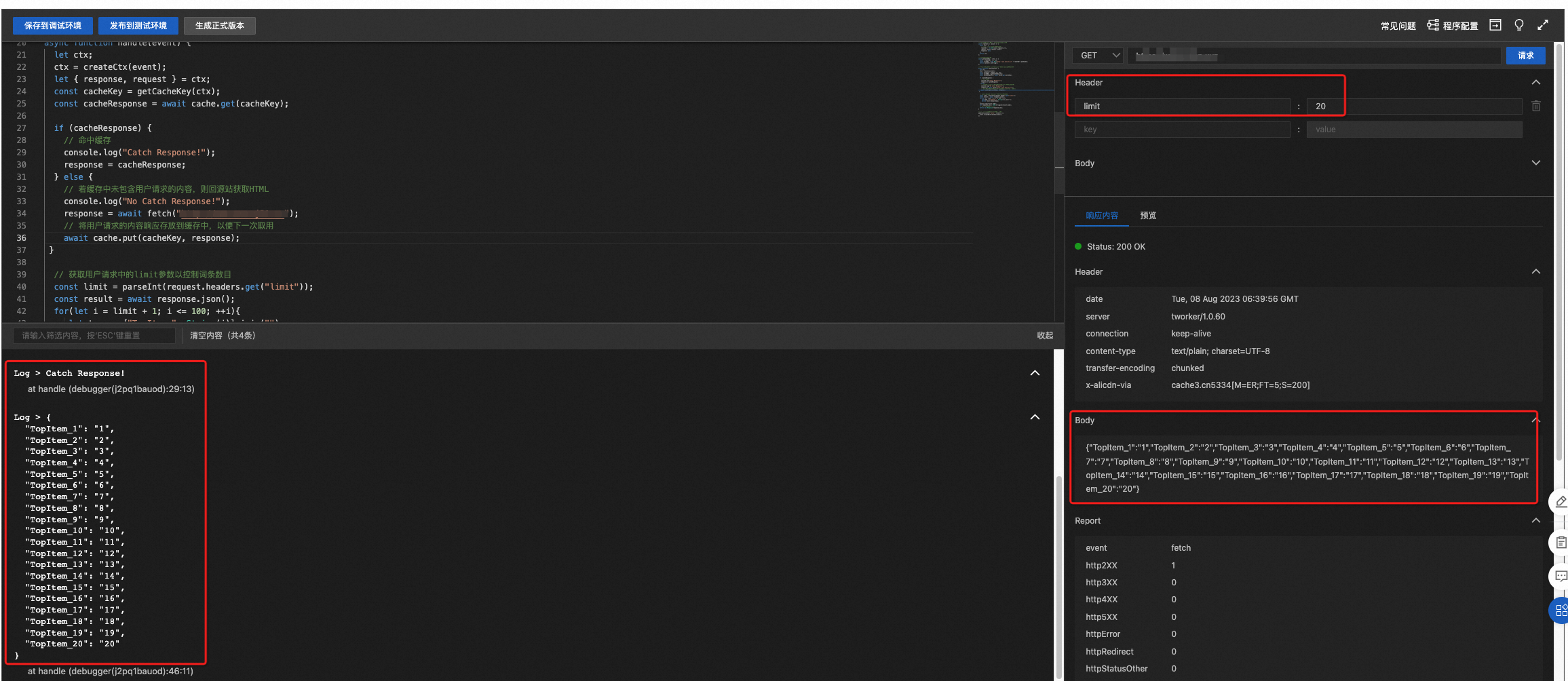
当第一次访问时未命中缓存,需要回源站拉取内容,并在控制台上打印出前10(
limit=10)个词条内容,并可以在body中看到返回的词条内容。当第二次访问时命中缓存,则直接返回前20(
limit=20)个词条内容。