
在ComfyUI中进行AI绘图和视频生成时,为提升模型推理效率,可以安装并使用ComfyUI-deepgpu加速插件,该插件能显著缩短生成时间,最高可将性能提升5倍。
ComfyUI-deepgpu插件介绍
ComfyUI-deepgpu是一款免费插件,将阿里云DeepGPU推理加速技术以插件的形式集成至ComfyUI,提升在阿里云服务器上运行 ComfyUI工作流时的模型推理速度。该插件优势如下:
较高的性能提升:DeepGPU能够有效降低模型的推理时间。
较好的兼容与叠加能力:DeepGPU 可与
fp8、sage-attention、TeaCache或WaveSpeed等其他流行的开源优化技术同时使用,可在享有社区最新成果的同时,获得额外的性能增益。便捷的动态部署:与一些需要预先编译模型的优化方案不同,DeepGPU无需预编译,即时启用加速,并且在工作流中切换不同的图像或视频尺寸时,不会产生额外开销。
适用范围
支持的模型 | 推荐GPU型号 |
|
其他GPU型号同样支持,但性能提升幅度可能不及推荐型号。 |
使用限制
运行环境要求:ComfyUI必须部署在阿里云的云服务实例上,仅阿里云上的云服务实例可使用DeepGPU的加速能力。
插件兼容性:本插件兼容ComfyUI官方工作流及大多数第三方节点。但暂不支持由
WanVideoWrapper插件提供的工作流。
安装插件
安装基础依赖。
Ubuntu
apt-get install which curl iputils-ping -yAlibaba Cloud Linux 3
yum install -y which curl iputils安装PyTorch依赖(推荐
2.8.0版本)。# 安装 PyTorch 及其相关组件 pip3 install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0安装
deepgpu-torch依赖。pip3 install deepgpu-torch==0.1.15+torch2.8.0cu128 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/deepytorch/index.html如果PyTorch版本不是2.8,请从官方源中选择与当前PyTorch版本相匹配的软件包进行安装。
下载并安装插件。
# 1. 切换到ComfyUI的自定义节点目录,使用时请替换为实际路径 cd ~/ComfyUI/custom_nodes/ # 2. 下载插件压缩包并解压 wget https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/nodes/20251013/ComfyUI-deepgpu.tar.gz tar zxf ComfyUI-deepgpu.tar.gz # 3. 安装插件的Python依赖 pip3 install deepgpu-comfyui==1.3.3 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/index.html重启ComfyUI服务。
使用插件
要使本插件生效,需将ApplyDeepyTorchToModel节点添加到工作流中。该节点接收一个模型对象(MODEL),对其应用DeepGPU的优化策略,然后输出一个优化后的模型对象。
节点在工作流中的位置
为确保优化生效,ApplyDeepyTorchToModel 节点应遵循一个核心原则:将其放置在整个工作流最后一个对模型进行处理或加载的节点之后,但需在采样器(KSampler)之前。
例如在示例工作流中,ApplyDeepyTorchToModel在Load Diffusion Model节点之后

节点参数说明
删除或禁用ApplyDeepyTorchToModel节点,需重启ComfyUI服务才能生效。参数 | 用途 | 默认值 | 说明 |
| 是否启用DeepGPU优化 |
| 设置为 |
| 是否使用动态尺寸优化 |
| 保持默认的 |
| Attention模块优化策略 |
| 保持默认的 |
| 运算精度优化 |
| 保持默认的 |
典型应用场景与工作流示例
本章节提供了多个即刻可用的工作流(Workflow)示例,覆盖主流模型,并展示了如何将DeepGPU与社区热门插件协同使用。
可下载对应示例的.json 文件,并将其拖拽到ComfyUI界面中直接加载使用。场景一:加速FLUX.1模型
基础加速:在
Load Diffusion Model后直接接入ApplyDeepyTorchToModel。
叠加LoRA:在最后一个
LoraLoaderModelOnly节点后接入ApplyDeepyTorchToModel。
叠加TeaCache插件:在
TeaCache节点后接入ApplyDeepyTorchToModel。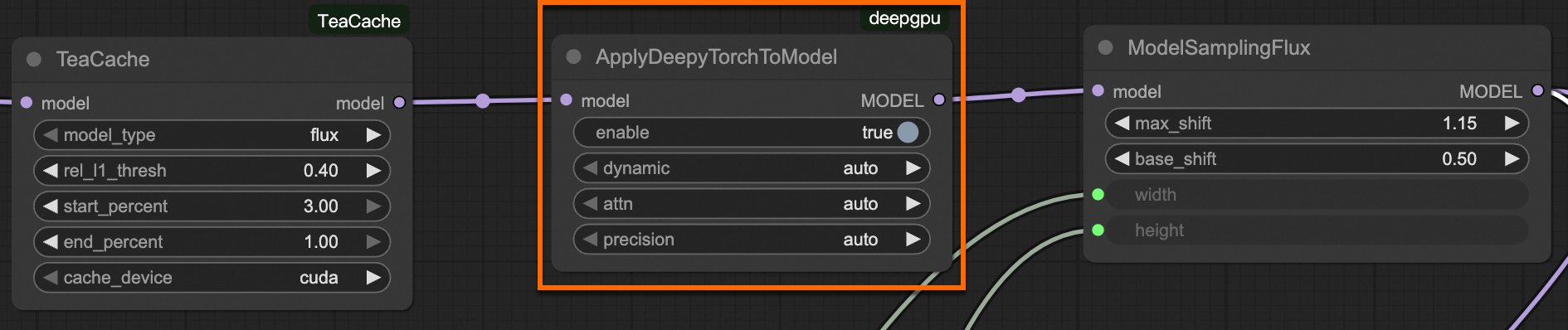
叠加PuLID插件:在
Apply PuLID Flux节点后接入ApplyDeepyTorchToModel。
叠加WaveSpped插件:在
Apply First Block Cache节点后接入ApplyDeepyTorchToModel。
场景二:加速Wan2.1视频生成
基础加速:在
Load Diffusion Model节点后接入ApplyDeepyTorchToModel。
叠加TeaCache插件:在
TeaCache节点后接入ApplyDeepyTorchToModel。
场景三:加速Wan2.2视频生成
基础加速:在处理模型的最后一个节点后、送入
KSampler之前,接入ApplyDeepyTorchToModel。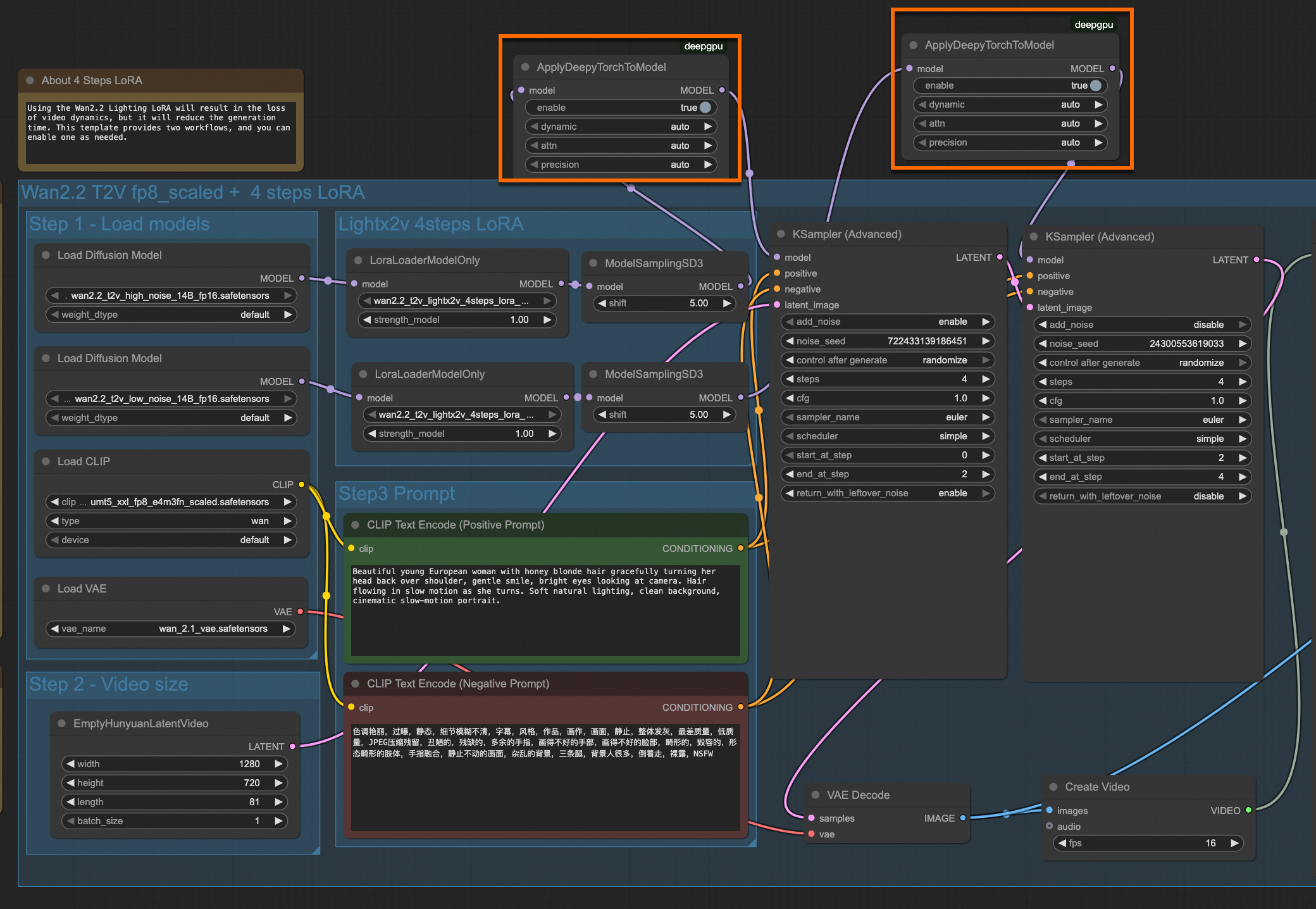
性能数据
以下测试数据基于阿里云服务器实例,在不同GPU型号及分辨率设置下,DeepGPU插件对模型推理带来的性能提升。
FLUX.1 图像生成模型
基础加速性能
测试条件:flux1-dev 模型,迭代步数 20 steps
GPU型号 | 推理精度 | 分辨率(WxH) | 原生耗时(torch 2.8) | DeepGPU耗时 | 性能提升 |
L20 | default (bf16) | 1024 * 1024 | 16.40s | 12.47s | 31.5% |
1280 * 720 | 14.61s | 11.28s | 29.5% | ||
fp8_e4m3fn_fast | 1024 * 1024 | 12.24s | 7.78s | 57.3% | |
1280 * 720 | 10.81s | 6.90s | 56.7% | ||
G49E | default (bf16) | 1024 * 1024 | 11.99s | 6.05s | 98.2% |
1280 * 720 | 10.44s | 5.24s | 99.2% | ||
fp8_e4m3fn_fast | 1024 * 1024 | 9.09s | 3.92s | 131.9% | |
1280 * 720 | 7.79s | 3.47s | 124.5% | ||
G59 | default (bf16) | 1024 * 1024 | 8.34s | 4.56s | 82.9% |
1280 * 720 | 8.05s | 4.1s | 96.3% |
极致加速性能(叠加优化)
测试条件:flux1-dev模型,叠加 fp8 + sage-attention + TeaCache + DeepGPU。测试工作流
GPU型号 | 分辨率 | 初始性能 (bf16) | 叠加优化后耗时 | 综合加速比 |
G49E | 1024x1024 | 11.99s | 2.33s | 5倍 |
Qwen-Image 图像生成模型
测试条件:qwen_image_fp8_e4m3fn模型,迭代步数 20 steps
GPU型号 | 分辨率(WxH) | 原生耗时 (torch 2.8) | DeepGPU 耗时 | 性能提升 |
G49E | 1328 * 1328 | 45.16s | 31.18s | 44.8% |
1024 * 1024 | 25.52s | 19.60s | 30.2% |
Wan 2.1视频生成模型
基础加速性能
测试条件:迭代步数 20 steps
模型规格 | GPU型号 | 推理精度 | 分辨率(WxH) | 帧数(L) | 原生耗时(torch 2.8) | DeepGPU 耗时 | 性能提升 |
wan2.1_Fun_InP_1.3B_bf16 | G49E | default (fp16) | 512 * 512 | 65 | 40.3s | 18.5s | 117.8% |
wan2.1_t2v_14B_fp16 | G49E | default (fp16) | 1280 * 720 | 81 | 1787s | 759s | 135.4% |
832 * 480 | 81 | 496s | 225s | 120.4% |
极致加速性能(叠加优化)
测试条件:叠加 fp8 + sage-attention + TeaCache(0.26) + DeepGPU
模型规格 | GPU型号 | 分辨率(WxH) | 帧数(L) | 初始性能(fp16) | 叠加优化后耗时 | 综合加速比 |
wan2.1_t2v_14B_fp16 | G49E | 1280 * 720 | 81 | 1787s | 437s | 4 倍 |
Wan2.2 视频生成模型
基础加速性能
测试条件:Wan2.2 14B 模型(wan2.2_t2v_high/low_noise_14B_fp16),迭代步数 4 steps + LoRA
GPU型号 | 推理精度 | 分辨率(WxH) | 帧数(L) | 原生耗时 (torch 2.8) | DeepGPU 耗时 | 性能提升 |
G49E | default (fp16) | 1280 * 720 | 81 | 200.5s | 94.6s | 111.9% |
640 * 640 | 81 | 64.8s | 35.8s | 81.0% | ||
fp8_e4m3fn_fast | 1280 * 720 | 81 | 177.7s | 80.9s | 119.7% |
极致加速性能(叠加优化)
测试条件:Wan2.2 14B 模型(wan2.2_t2v_high/low_noise_14B_fp16),叠加 fp8 + sage-attention + DeepGPU
GPU型号 | 分辨率(WxH) | 帧数(L) | 初始性能 (fp16) | 叠加优化后耗时 | 综合加速比 |
G49E | 1280 * 720 | 81 | 200.5s | 80.9s | 2.5 倍 |
常见问题
安装插件后,ComfyUI启动报错或找不到
ApplyDeepyTorchToModel节点怎么办?请按以下步骤排查
确认重启:确保在安装插件后已完全重启ComfyUI服务。
检查路径:确认
ComfyUI-deepgpu文件夹是否被正确解压到了ComfyUI/custom_nodes/目录下。检查依赖:重新安装
deepgpu-torch和deepgpu-comfyui依赖,检查是否有报错。版本冲突:检查PyTorch版本是否与安装的
deepgpu-torch版本后缀(如+torch2.8.0cu128)严格对应。
使用DeepGPU加速后,生成的图像或视频质量会下降吗?
在默认的
auto配置下,DeepGPU旨在实现无损或体感无损的加速。它会自动选择最优的精度策略,在绝大多数情况下,不会观察到肉眼可见的质量差异。我的GPU型号不在推荐列表里,还能使用吗?
可以。推荐列表是经过深度优化和测试、性能提升最显著的型号。其他 NVIDIA GPU同样可以运行并获得加速效果,只是提升幅度可能会有所不同。
如何更新DeepGPU插件?
访问官方发布渠道获取最新的
.tar.gz压缩包和pip install命令,然后重新安装插件(建议先删除旧的ComfyUI-deepgpu文件夹),即可覆盖并更新到最新版本。