
JindoTable通过Native Engine,支持对Spark、Hive或Presto上ORC或Parquet格式文件进行加速。本文为您介绍如何开启native查询加速,以提升Spark、Hive和Presto的性能。
前提条件
已创建集群,且ORC或Parquet文件已存放至JindoFS或OSS,创建集群详情,请参见创建集群。
使用限制
-
不支持对Binary类型文件进行加速。
-
不支持分区列的值存储在文件中的分区表。
-
不支持EMR-5.X系列及后续版本的E-MapReduce集群。
-
不支持代码spark.read.schema(userDefinedSchema)。
-
支持Date类型区间为1400-01-01到9999-12-31。
-
同一个表中查询列不支持区分大小写。例如,NAME和name两个列在同一个表中无法使用查询加速。
-
Spark、Hive和Presto服务支持的引擎和存储格式如下所示。
引擎
ORC
Parquet
Spark2
支持
支持
Spark3
支持
支持
Presto
支持
支持
Hive2
不支持
支持
Hive3
不支持
支持
-
Spark、Hive和Presto服务支持的引擎和存储文件系统如下所示。
引擎
OSS
JFS
HDFS
Spark2
支持
支持
支持
Presto
支持
支持
支持
Hive2
支持
支持
不支持
Hive3
支持
支持
不支持
提升Spark性能
-
开启JindoTable ORC或Parquet加速。
说明-
因为查询加速使用的是堆外内存,所以在Spark任务中建议添加配置
--conf spark.executor.memoryOverhead=4g,提高Spark申请额外资源用来进行加速。 -
Spark读取ORC或Parquet时,需要使用DataFrame API或者Spark-SQL。
-
全局设置
-
进入详情页面。
-
在顶部菜单栏处,根据实际情况选择地域和资源组。
-
单击上方的集群管理页签。
-
在集群管理页面,单击相应集群所在行的详情。
-
修改配置。
-
在左侧导航栏,选择。
-
在Spark服务页面,单击配置页签。
-
在搜索区域,搜索参数spark.sql.extensions,修改参数值为io.delta.sql.DeltaSparkSessionExtension,com.aliyun.emr.sql.JindoTableExtension。
-
-
保存配置。
-
单击保存。
-
在确认修改对话框中,输入执行原因,单击确定。
-
-
重启ThriftServer。
-
在右上角选择。
-
在执行集群操作对话框中,输入执行原因,单击确定。
-
在确认对话框中,单击确定。
-
-
-
Job级别设置
使用spark-shell或者spark-sql时,可以添加Spark的启动参数。
--conf spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension,com.aliyun.emr.sql.JindoTableExtension作业详情请参见Spark Shell作业配置或Spark SQL作业配置。
-
-
检查开启情况。
-
登录Spark History Server UI页面。
-
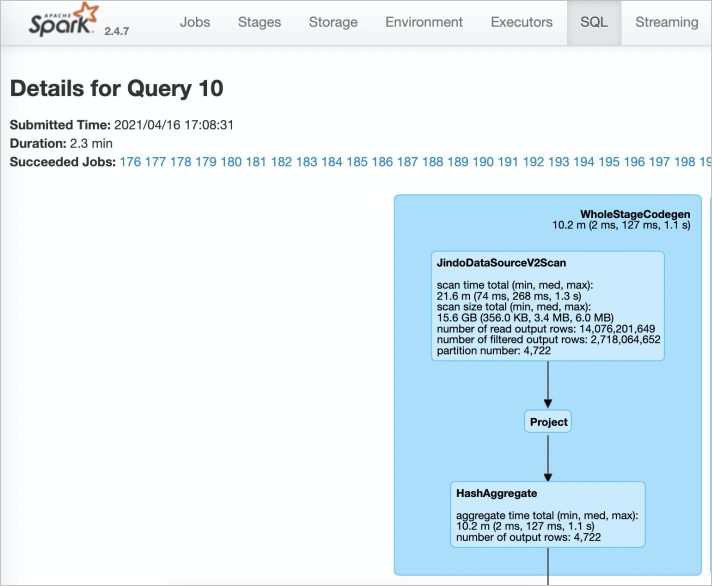
在Spark的SQL页面,查看执行任务。
当出现JindoDataSourceV2Scan时,表示开启成功。否则,请排查步骤1中的操作。
-
提升Presto性能
Presto查询并发较高,且查询加速使用堆外内存,因此使用查询加速时内存配置必须大于10 GB。
因为Presto已经内置JindoTable native加速的catalog: hive-acc,所以您可以直接使用catalog: hive-acc来启用查询加速。
示例如下。
presto --server emr-header-1:9090 --catalog hive-acc --schema default目前使用Presto查询加速功能时,暂不支持读取复杂的数据类型,例如Map、Struct或Array。
提升Hive性能
如果您对作业稳定性要求较高时,建议不要开启native查询加速。
您可以通过以下两种方式提升Hive性能:
-
控制台方式
在控制台Hive服务的配置页面,搜索并修改自定义参数hive.jindotable.native.enabled为true,保存配置后,重启服务使配置生效,此方式适用于Hive on MR和Hive on Tez。

-
命令行方式
您可以直接在命令行中设置
hive.jindotable.native.enabled为true来启用查询加速。因为EMR-3.35.0及后续版本已经内置JindoTable Parquet加速的插件,所以您可以直接设置该参数。set hive.jindotable.native.enabled=true;
目前使用Hive查询加速功能时,暂不支持读取复杂的数据类型,例如Map、Struct或Array。