
Apache Flume是一个分布式、可靠和高可用的系统,可以从大量不同的数据源有效地收集、聚合和移动日志数据,从而集中式的存储数据。
使用场景
Flume使用最多的场景是日志收集,也可以通过定制Source来传输其他不同类型的数据。
Flume最终会将数据落地到实时计算平台(例如Flink、Spark Streaming和Storm)、离线计算平台上(例如MR、Hive和Presto),也可仅落地到数据存储系统中(例如HDFS、OSS、Kafka和Elasticsearch),为后续分析数据和清洗数据做准备。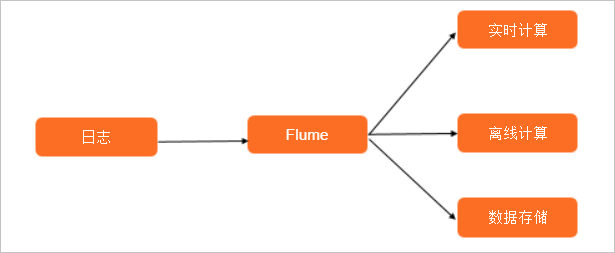
架构
Flume Agent是一个Flume的实例,本质是一个JVM进程,控制Event数据流从生产者传输到消费者。一个Flume Agent由Source、Channel、Sink组成。其中,Source和Channel可以是一对多的关系,Channel和Sink也可以是一对多的关系。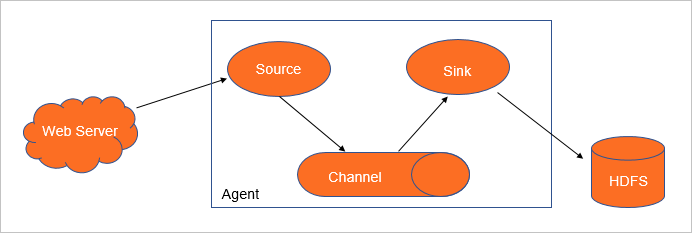
基本概念
名称 | 描述 |
Event | 是数据流通过Flume Agent的基本单位。Event由一个可选的Header字典和一个装载数据的字节数组组成。 示例如下。 |
Source | 是数据源收集器,从外部数据源收集数据,并批量发送到一个或多个Channel中。 常见Source如下:
|
Channel | 是Source和Sink之间的缓冲队列。 常见Channel如下:
|
Sink | 从Channel中获取Event,并将以事务的形式Commit到外部存储中。一旦事务Commit成功,该Event会从Channel中移除。 常见Sink如下:
|