
您可以借助Paimon快速地在HDFS或者OSS上构建自己的数据湖存储服务,然后通过Spark计算引擎实现数据湖的分析。本文为您介绍在EMR中如何通过Spark SQL读取和写入Paimon中的数据。
前提条件
已创建选择了Spark和Paimon的DataLake或Custom类型的集群,创建集群详情请参见创建集群。
使用限制
EMR-3.46.0及后续版本、EMR-5.12.0及后续版本的集群,支持Spark SQL对Paimon进行读写操作。
仅Spark3的Spark SQL可以通过Catalog读写Paimon中的数据。
操作步骤
步骤一:配置Catalog
Spark可以通过Catalog读写Paimon表,其中Catalog包括Paimon Catalog和spark_catalog两种类型。您可以根据具体场景进行选择。
Paimon Catalog:用于管理Paimon格式的元数据,只能用于查询和写入Paimon表。
spark_catalog:Spark默认内置Catalog,通常用于管理Spark SQL内部表的元数据,可以用于查询和写入Paimon表或者非Paimon表。
使用Paimon Catalog
您可以将元数据保存在文件系统(如HDFS)或对象存储(如OSS)中,也可以将元数据同步到DLF和Hive中,方便其他服务访问Paimon。
存储的根路径由spark.sql.catalog.paimon.warehouse参数指定。如果根路径不存在,将会自动创建该路径;如果根路径存在,您可以通过该Catalog访问路径中已有的表。
通过SSH方式连接集群的Master节点,具体操作请参见登录集群Master节点。
根据元数据类型选择要配置的Catalog。执行对应的命令,启动Spark SQL。
配置Filesystem Catalog
Filesystem Catalog会将元数据保存在文件系统或对象存储中。
spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \ --conf spark.sql.catalog.paimon.metastore=filesystem \ --conf spark.sql.catalog.paimon.warehouse=oss://<yourBucketName>/warehouse \ --conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions说明spark.sql.catalog.paimon:定义了名为paimon的Catalog。spark.sql.catalog.paimon.metastore:指定Catalog使用的元数据存储类型。设置为filesystem意味着元数据存储在本地文件系统。spark.sql.catalog.paimon.warehouse:配置数据仓库的实际位置,请根据实际情况修改。其中<yourBucketName>为OSS的存储空间,创建操作请参见创建存储空间。
配置DLF Catalog
DLF Catalog会将元数据同步到DLF中。
重要创建集群时,元数据必须是DLF统一元数据。
spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \ --conf spark.sql.catalog.paimon.metastore=dlf \ --conf spark.sql.catalog.paimon.warehouse=oss://<yourBucketName>/warehouse \ --conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions说明spark.sql.catalog.paimon:定义了名为paimon的Catalog。spark.sql.catalog.paimon.metastore:指定Catalog使用的元数据存储类型。设置为dlf意味着将数据同步到DLF(Data Lake Formation)中。spark.sql.catalog.paimon.warehouse:配置数据仓库的实际位置,请根据实际情况修改。其中<yourBucketName>为OSS的存储空间,创建操作请参见创建存储空间。
配置Hive Catalog
Hive Catalog会同步元数据到Hive MetaStore中。在Hive Catalog中创建的表可以直接在Hive中查询。Hive查询Paimon,详情请参见Paimon与Hive集成。
spark-sql --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \ --conf spark.sql.catalog.paimon.metastore=hive \ --conf spark.sql.catalog.paimon.uri=thrift://master-1-1:9083 \ --conf spark.sql.catalog.paimon.warehouse=oss://<yourBucketName>/warehouse \ --conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions说明spark.sql.catalog.paimon:定义了名为paimon的Catalog。spark.sql.catalog.paimon.metastore:指定Catalog使用的元数据存储类型。设置为hive意味着将元数据同步到Hive Metastore中。spark.sql.catalog.paimon.uri:为Hive MetaStore Service的地址和端口。参数值为thrift://master-1-1:9083,这意味着Spark SQL将连接到这个运行在master-1-1主机上、监听9083端口的Hive Metastore服务以获取元数据信息。spark.sql.catalog.paimon.warehouse:配置数据仓库的实际位置,请根据实际情况修改。其中<yourBucketName>为OSS的存储空间,创建操作请参见创建存储空间。
使用spark_catalog
通过SSH方式连接集群的Master节点,具体操作请参见登录集群Master节点。
执行下面的命令配置Catalog,启动Spark SQL。
spark-sql --conf spark.sql.catalog.spark_catalog=org.apache.paimon.spark.SparkGenericCatalog \ --conf spark.sql.extensions=org.apache.paimon.spark.extensions.PaimonSparkSessionExtensions说明spark.sql.catalog.spark_catalog:定义了名为spark_catalog的Catalog。spark_catalog中用来存储的根路径由
spark.sql.warehouse.dir参数指定,一般不需要修改。
步骤二:读写Paimon表
执行以下Spark SQL语句,在Catalog中创建一张表,并读写表中的数据。
使用Paimon Catalog
访问Paimon表需要使用paimon.<db_name>.<tbl_name>,其中<db_name>为数据库的名字,<tbl_name>为表的名字。
-- 创建数据库
CREATE DATABASE IF NOT EXISTS paimon.ss_paimon_db;
-- 创建Paimon表
CREATE TABLE paimon.ss_paimon_db.paimon_tbl (id INT, name STRING) USING paimon;
-- 写入Paimon表
INSERT INTO paimon.ss_paimon_db.paimon_tbl VALUES (1, "apple"), (2, "banana"), (3, "cherry");
-- 查询写入结果
SELECT * FROM paimon.ss_paimon_db.paimon_tbl ORDER BY id;
-- 删除数据库
DROP DATABASE paimon.ss_paimon_db CASCADE;配置Hive Catalog后,创建数据库时报metastore: Failed to connect to the MetaStore Server错误,说明Hive MetaStore服务没有启动,需要执行以下命令启动。启动成功后,再执行配置Hive Catalog的命令。
hive --service metastore &如果您创建集群时元数据选择DLF统一元数据,建议将元数据同步到DLF,配置DLF Catalog。
使用spark_catalog
无论是访问Paimon表还是非Paimon表,都可以使用spark_catalog.<db_name>.<tbl_name>。由于spark_catalog是Spark默认内置Catalog,因此可以忽略不写,直接通过<db_name>.<tbl_name>访问表。其中<db_name>为数据库的名字,<tbl_name>为表的名字。
-- 创建数据库
CREATE DATABASE IF NOT EXISTS ss_paimon_db;
CREATE DATABASE IF NOT EXISTS ss_parquet_db;
-- 创建Paimon表和Parquet表
CREATE TABLE ss_paimon_db.paimon_tbl (id INT, name STRING) USING paimon;
CREATE TABLE ss_parquet_db.parquet_tbl USING parquet AS SELECT 3, "cherry";
-- 写入Paimon表
INSERT INTO ss_paimon_db.paimon_tbl VALUES (1, "apple"), (2, "banana");
INSERT INTO ss_paimon_db.paimon_tbl SELECT * FROM ss_parquet_db.parquet_tbl;
-- 查询写入结果
SELECT * FROM ss_paimon_db.paimon_tbl ORDER BY id;
-- 删除数据库
DROP DATABASE ss_paimon_db CASCADE;
DROP DATABASE ss_parquet_db CASCADE;查询结果如下。
1 apple
2 banana
3 cherry 常见问题
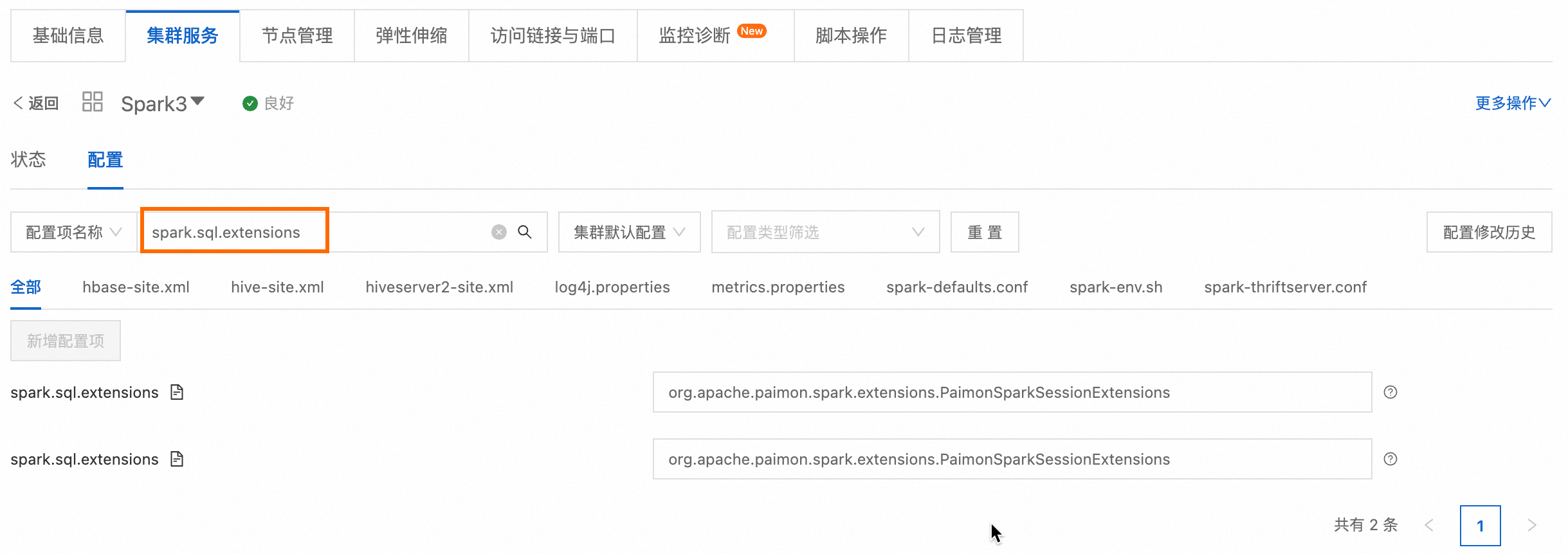
会自动增加。集群添加Paimon组件后,您可以通过以下操作查看配置信息。
进入目标集群的集群服务页签。
查看Spark服务的配置信息。
单击Spark服务右侧的配置。
在配置项名称输入框搜索spark.sql.extensions,可以查看到配置信息。
相关文档
更多Paimon相关用法和配置,请参见Paimon官方文档。