
本文以EMR Kafka 2.4.1版本为例,介绍Kafka磁盘写满时的运维操作。
业务场景
Kafka将日志数据存储到磁盘中,当磁盘写满时,相应磁盘上的Kafka日志目录会出现offline问题。此时,该磁盘上的分区副本不可读写,降低了分区的可用性与容错能力,同时由于leader迁移到其他Broker,增加了其他Broker的负载。因此,当磁盘出现写满情况时,应及时处理。
磁盘写满运维概述
本文从磁盘写满监控和磁盘写满恢复角度来介绍磁盘写满运维策略。
磁盘写满监控
Kafka服务层面:可以在云监控系统中设置EMR Kafka集群的OfflineLogDirectoryCount指标告警,及时发现日志目录offline的情况。
磁盘写满恢复
从排查问题角度来看,当Kafka出现log directory offline时,需要尽快定位是否是由于日志目录所在磁盘写满导致的。
- 磁盘扩容:通过扩容云盘的方式来增加磁盘容量,适用于Broker挂载云盘的场景,详情请参见磁盘扩容方式恢复。
- 节点内分区迁移:将写满磁盘中的分区迁移到本节点的其他磁盘,适用于本Broker节点内磁盘使用率不均衡的场景,详情请参见节点内分区迁移方式恢复。
- 数据清理:清理写满磁盘的日志数据,适用于旧数据可以删除的场景,详情请参见数据清理方式恢复。
磁盘扩容方式恢复
方案描述
磁盘扩容方式是指当Broker磁盘空间被写满时,通过扩容磁盘存储的方式来满足磁盘需求。其优点在于操作简单、风险小、能够快速解决磁盘空间不足的问题。
适用场景
适用于Broker挂载云盘的场景。
操作步骤
在EMR控制台扩容Broker节点的数据盘,详情请参见扩容磁盘。
节点内分区迁移方式恢复
方案描述
当Broker磁盘容量被写满时,对应的log directory被offline,无法使用kafka-reassign-partitions.sh工具迁移分区。此时,可以通过ECS实例层面的操作,将分区副本数据挪到当前Broker的其他磁盘并修改相应Kafka数据目录元数据的方式来解决故障盘空间不足的问题。
适用场景
故障磁盘所在Broker使用容量不均衡、存在空间使用率较低的磁盘。
注意事项
- 该方法只能进行节点内部磁盘迁移。
- 分区迁移有可能导致磁盘的IO热点,进而影响集群的性能。需要评估每次迁移数据的大小、迁移时长对业务的影响程度。
- 由于该方法是非标操作,请在相应的Kafka版本测试后再用于生产集群。
操作步骤
当磁盘写满时,由于log directory已经offline了,所以不能用kafka-reassign-partitions.sh工具进行分区迁移。本文通过非标方式直接移动文件、修改Kafka相关元数据的方式来迁移分区。
- 创建测试Topic。
- 以SSH方式登录到源Kafka集群的Master节点,详情请参见登录集群。
- 执行以下命令,创建测试Topic,分区副本分布在Broker 0,1节点。
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --replica-assignment 0:1 --create您可以通过以下命令查看Topic详情。kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --describe返回如下信息,此时Broker 0是在Isr列表中的。Topic: test-topic PartitionCount: 1 ReplicationFactor: 2 Configs: Topic: test-topic Partition: 0 Leader: 0 Replicas: 0,1 Isr: 0,1
- 执行以下命令,模拟数据写入。
kafka-producer-perf-test.sh --topic test-topic --record-size 1000 --num-records 600000000 --print-metrics --throughput 10240 --producer-props linger.ms=0 bootstrap.servers=core-1-1:9092 - 修改Broker 0分区对应的日志目录权限。
- 在Master节点上切换到emr-user账号。
su emr-user - 免密码登录到对应的Core节点。
ssh core-1-1 - 通过sudo获得root权限。
sudo su - root - 执行以下命令,查找分区所在磁盘。
sudo find / -name test-topic-0返回信息如下,则表示分区在/mnt/disk4/kafka/log目录下。/mnt/disk4/kafka/log/test-topic-0 - 执行以下命令,将Broker 0分区对应的日志目录权限设置成000。
sudo chmod 000 /mnt/disk4/kafka/log - 执行以下命令,查看test-topic的状态。
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --describe返回信息如下,可以看到Broker 0已经不在Isr列表中了。Topic: test-topic PartitionCount: 1 ReplicationFactor: 2 Configs: Topic: test-topic Partition: 0 Leader: 1 Replicas: 0,1 Isr: 1
- 在Master节点上切换到emr-user账号。
- 停止Broker 0节点。
在EMR控制台停止Broker 0的Kafka服务。
- 执行以下命令,将Broker 0的test-topic的分区移动到本节点的其他磁盘。
mv /mnt/disk4/kafka/log/test-topic-0 /mnt/disk1/kafka/log/ - 修改文件。
根据源目录/mnt/disk4/kafka/log和目标目录/mnt/disk1/kafka/log的元数据文件。需要修改的文件包括replication-offset-checkpoint和recovery-point-offset-checkpoint。
- 修改replication-offset-checkpoint文件,将test-topic相关的条目从原日志目录下的replication-offset-checkpoint文件挪到目标日志目录的replication-offset-checkpoint中,并修改该文件条目的数量。
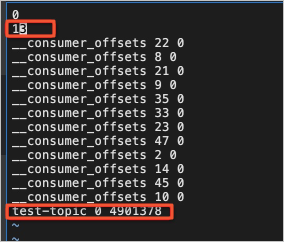
- 修改recovery-point-offset-checkpoint文件,将test-topic相关的条目从原日志目录下的recovery-point-offset-checkpoint文件挪到目标日志目录的recovery-point-offset-checkpoint中,并修改该文件条目的数量。
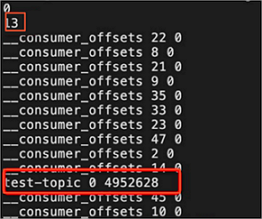
- 修改replication-offset-checkpoint文件,将test-topic相关的条目从原日志目录下的replication-offset-checkpoint文件挪到目标日志目录的replication-offset-checkpoint中,并修改该文件条目的数量。
- 执行以下命令,将源broker 0的日志目录权限设置成正确的权限。
sudo chmod 755 /mnt/disk4/kafka/log - 启动Broker 0节点。
在EMR控制台启动Broker 0的Kafka服务。
- 执行以下命令,观察集群的状态是正常的。
kafka-topics.sh --bootstrap-server core-1-1:9092 --topic test-topic --describe
数据清理方式恢复
方案描述
数据清理是指当磁盘被写满时,将业务日志数据(非Kafka内部Topic数据)按照从旧到新的方式删除,直到释放出足够的空间。
适用场景
写满磁盘存在允许删除的业务数据。
如果不改变数据的存储时长,数据有可能又被快速的写满。因此,通常适用于因特殊情况而导致的数据突增的场景。
注意事项
不能删除Kafka内部的Topic数据,即不能删除以下划线(_)开头命名的Topic。
操作步骤
- 登录到相应的机器上。
- 找到写满的磁盘,删除掉不需要的业务数据。数据清理原则:
- 不可直接删除Kafka的数据目录,避免造成不必要的数据丢失。
- 找到占用空间较多或者明确不需要的Topic,选择其中某些Partition,从最早的日志数据开始删除。删除segment及相应地index和timeindex文件。不要清理内置的Topic,例如__consumer_offsets和_schema等。
- 重启磁盘被写满的相应的Broker节点,使日志目录online。