当您在Zeppelin里完成作业开发后,您就可以通过Airflow定期调度作业。本文为您介绍如何使用Airflow调度作业。
背景信息
- Note级别调度
一个Note可以作为Airflow的一个单独Task来调度,多个Note可以组合成一个复杂的DAG。
- Paragraph级别调度
一个段落(Paragraph)可以作为Airflow的一个单独Task来调度,多个Paragraph可以组合成一个复杂的DAG。
- task_id:必填参数,需要保证在DAG范围内唯一。
- conn_id:必填参数,默认值为zeppelin_default,表示连接的Zeppelin的地址信息。
- note_id:必填参数,您要运行的Note的ID。
您可以在Note页面右上角找到这个Note的ID。
- paragraph_id:可选参数,当您运行整个Note时,不需要指定paragraph_id。当您运行单个Paragraph时,需要指定paragraph_id。
您可以在Paragraph页面右上角找到这个Paragraph的ID。
- params:可选参数,当您的Note或Paragraph需要传递参数时,需要指定params参数。
- 通过Jinja Templating传递参数。
Jinja Templating详情,请参见Concepts。
- 通过宏的方式来传递参数。
常用的变量可以通过宏的方式来传递参数,例如,本文示例中的
{{ ds }}就是传递执行日期,关于Airflow支持的宏,请参见Macros reference。
- Note级别调度
本示例总共有3个Task,分别为:
- 生成数据:对应示例中的raw_data_task。
- 把CSV格式转为Parquet格式:对应示例中的spark_etl_task。
- 查询Parquet表:对应示例中的spark_query_task。
每个Task都写在单独的Note里,因此您只需要在每个ZeppelinOperator里指定note_id。from airflow import DAG from airflow.providers.apache.zeppelin.operators.zeppelin_operator import ZeppelinOperator from airflow.utils.dates import days_ago default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': days_ago(10), 'email_on_failure': False, 'email_on_retry': False, 'retries': 0 } with DAG(dag_id='zeppelin_etl_note_dag', max_active_runs=5, start_date=days_ago(200), schedule_interval='0 0 * * *', tags=['emr_studio_example']) as dag: raw_data_task = ZeppelinOperator( task_id='raw_data_task', conn_id='zeppelin_default', note_id='2FZWJTTPS', parameters= {'dt' : '2021-01-01'} ) spark_etl_task = ZeppelinOperator( task_id='spark_etl_task', conn_id='zeppelin_default', note_id='2FX3GJW67', parameters= {'dt' : '2021-01-01'} ) spark_query_task = ZeppelinOperator( task_id='spark_query_task', conn_id='zeppelin_default', note_id='2FZ8H4JPV', parameters= {'dt' : '2021-01-01'} ) raw_data_task >> spark_etl_task >> spark_query_task - Paragraph级别调度
本示例总共有4个Task,分别为:
- 生成数据:对应示例中的raw_data_task。
- Load csv数据到Hive表:对应示例中的csv_data_task。
- 把CSV格式转为Parquet格式:对应示例中的parquet_data_task。
- 查询Parquet表:对应示例中的query_ta。
每个Task都是一个Paragraph,因此您需要指定note_id和paragraph_id。本示例中还指定了参数params,把当前执行时间传递进去,用到了宏{{ ds }}来表示运行时间YYYY-MM-DD。from airflow import DAG from airflow.utils.dates import days_ago from airflow.providers.apache.zeppelin.operators.zeppelin_operator import ZeppelinOperator default_args = { 'owner': 'airflow', 'depends_on_past': False, 'start_date': days_ago(10), 'email_on_failure': False, 'email_on_retry': False, 'retries': 0 } with DAG(dag_id='zeppelin_etl_paragraph_dag', max_active_runs=5, schedule_interval='0 0 * * *', default_args=default_args, tags=['emr_studio_example']) as dag: execution_date = "{{ ds }}" raw_data_task = ZeppelinOperator( task_id='raw_data_task', conn_id='zeppelin_default', note_id='2FXADMCY9', paragraph_id='paragraph_1613703810025_1489985581', parameters= {'dt' : execution_date} ) csv_data_task = ZeppelinOperator( task_id='csv_data_task', conn_id='zeppelin_default', note_id='2FXADMCY9', paragraph_id='paragraph_1613705325984_828524031', parameters= {'dt' : execution_date} ) parquet_data_task = ZeppelinOperator( task_id='parquet_data_task', conn_id='zeppelin_default', note_id='2FXADMCY9', paragraph_id='paragraph_1613709950691_1420422787', parameters= {'dt' : execution_date} ) query_task = ZeppelinOperator( task_id='query_task', conn_id='zeppelin_default', note_id='2FXADMCY9', paragraph_id='paragraph_1613703819960_454383326', parameters= {'dt' : execution_date} ) raw_data_task >> csv_data_task >> parquet_data_task >> query_task
操作流程
步骤一:编写Airflow DAG脚本
EMR Studio集群暂不支持在线编写Airflow DAG脚本,您需要在本地编写Airflow DAG脚本。在Airflow里构建DAG的详情,请参见Airflow官网。
EMR Studio集群新增了ZeppelinOperator,您可以使用ZeppelinOperator调用Zeppelin Notebook。使用ZeppelinOperator可以最大程度地保证开发环境和生产环境的一致性,避免由于开发阶段和生产阶段环境不一致导致的问题。ZeppelinOperator使用的详细信息请参见背景信息。
步骤二:上传Airflow DAG脚本
本文通过OSS控制台上传Airflow DAG脚本。上传Airflow DAG脚本的路径为您创建集群时指定的OSS路径。
步骤三:启用DAG脚本
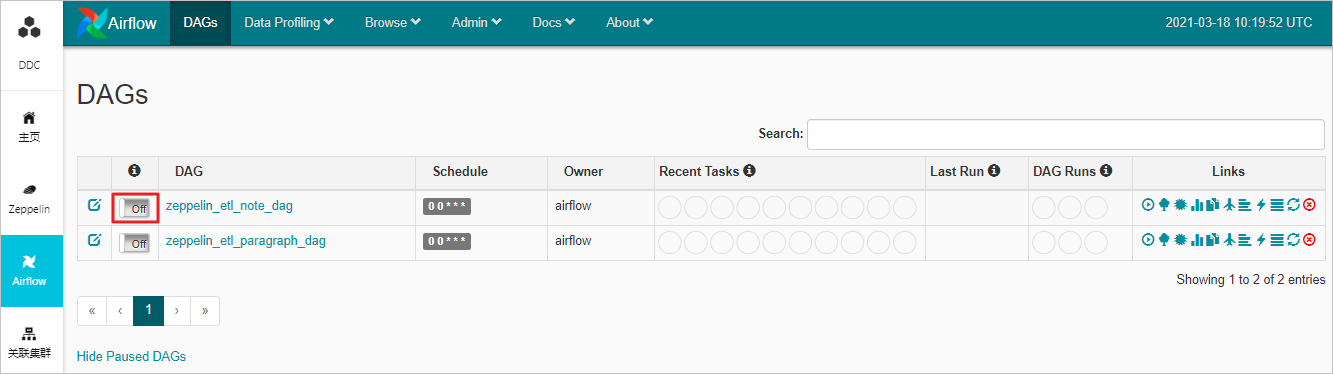
步骤四:查看DAG运行状态
- 在Tree View页面,您可以查看对应DAG运行调度任务的详细信息。
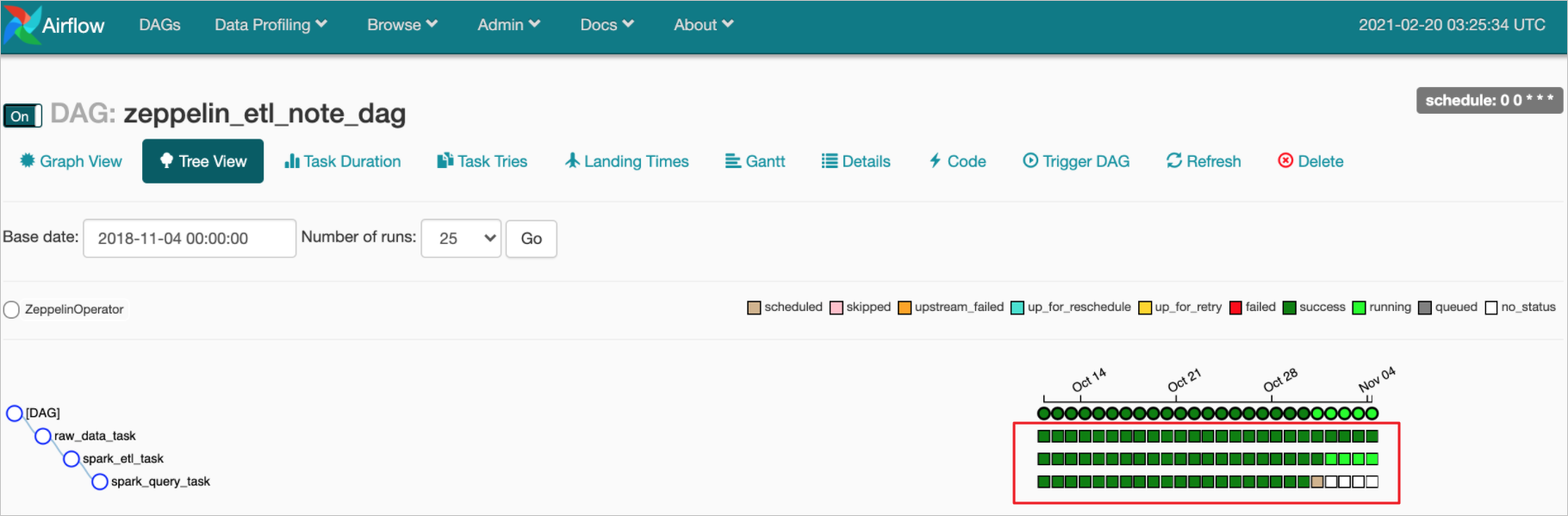 任务状态如下表所示。
任务状态如下表所示。状态 描述 scheduled 已开始调度 skipped 跳过本次调度 upstream_failed 上游任务失败 up_for_reschedule 已重新调度 up_for_retry 重试 failed 调度失败 success 调度成功 running 调度正在运行中 queued 加入调度队列 no_status 没有状态 - 在Tree View页面,单击
 图标。弹出相应Task的对话框。
图标。弹出相应Task的对话框。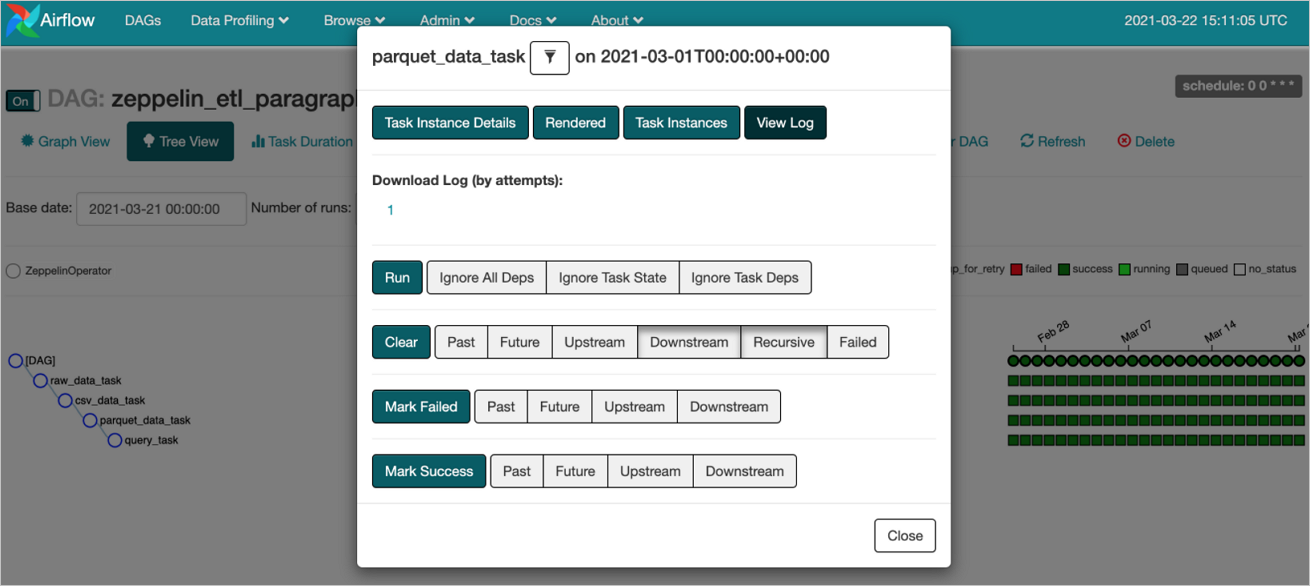
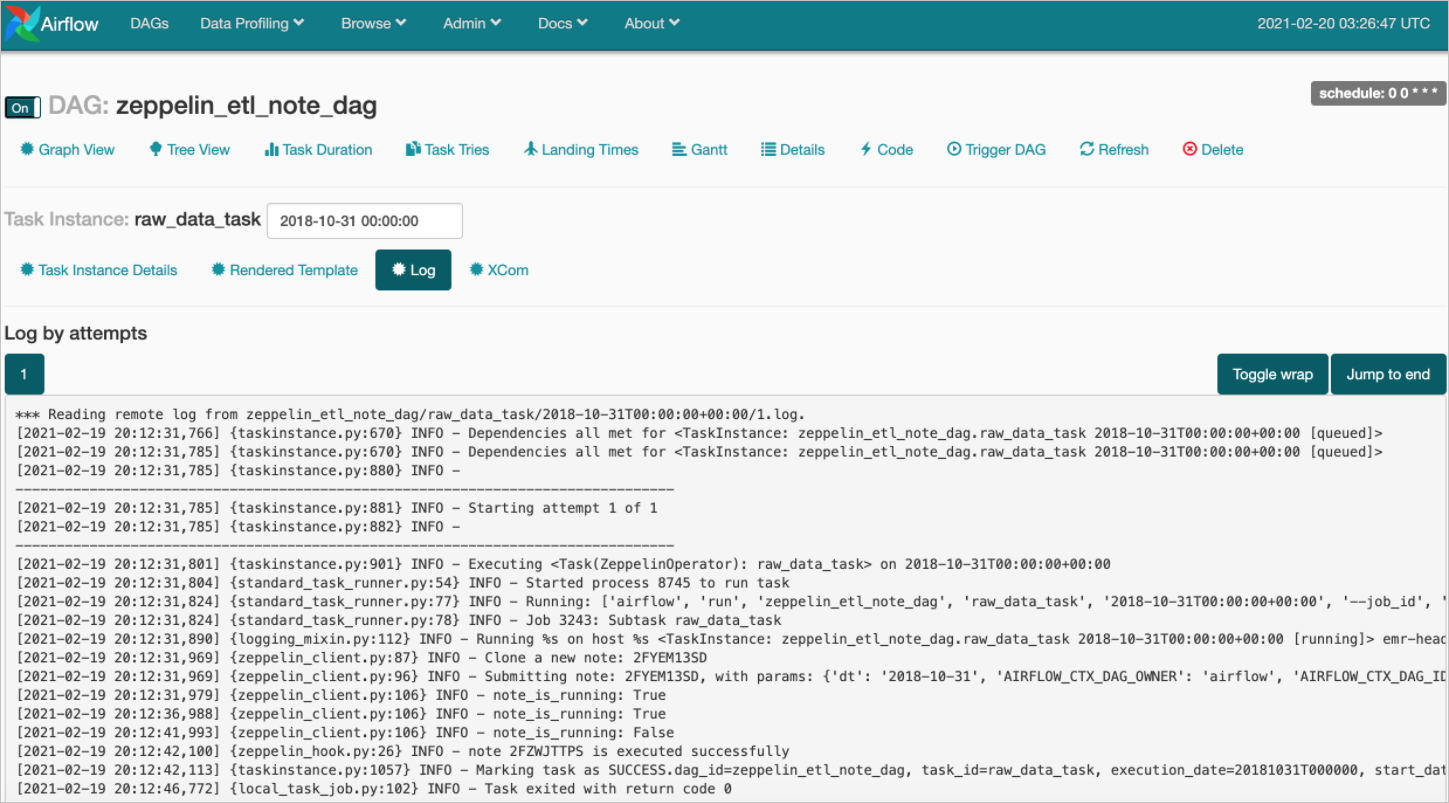
- 单击Task对话框中的View log。即可查看Task详情的运行情况。详细信息如下图所示。