
当您在使用Presto或Trino集群,不知道如何选择机型或如何配置内存时,可参考本文进行选择或配置。本文为您介绍如何根据业务需求,选择合适规格和内存的Trino集群。
Trino集群选型建议
从Trino概述中可知,Trino由一个Coordinator节点和多个Worker节点组成。在EMR集群中,默认情况下Trino的Coordinator会部署在Master节点上,Worker会部署在Core或Task节点上。目前Trino原生还不支持高可用,即无论是否购买高可用集群,Trino Coordinator均只会部署在一台Master节点上。尽管如此,一台Coordinator也足以支持数以百计的Worker节点的调度。
在创建EMR集群时,选择Trino本身及要用到的数据湖组件,即可创建Trino集群。在创建时,选型建议如下:
如果选择对等配置,即购买相同配置的Master节点与Core节点,Worker数量建议为5~20台(也可以更多)。
Worker数量较少时,Master节点的配置可以降低到Core节点的一半。但Master节点的配置尤其是CPU核数尽量不要显著低于Core节点,防止影响性能和稳定性。
集群规模较大时,建议优先考虑增加Worker数量,而非提高单个节点配置。
如果出现内存不足等情况,可以使用EMR的弹性伸缩能力,对节点进行扩充,集群负载降低时可以再缩容,详细信息请参见弹性伸缩概述。
如果您的集群不准备进行混合部署,而是仅使用Trino服务,建议在创建集群时取消选择HDFS、Hive等组件,仅选择Trino本身及要用到的数据湖组件,以强化弹性能力,减少资源占用。
Trino进行运算时会同时消耗CPU与内存。CPU直接决定查询速度,内存容量决定一个查询能否成功跑出结果,对查询速度也稍有影响。您可以根据SQL的具体情况以及业务的实际需要购买相应的集群。如果没有特殊需求,通用型实例即可满足日常使用。如下就是一个较为均衡的Trino集群:
节点种类与数量 | 单台实例CPU核数 | 单台实例内存大小 |
1 Master | 16核 | 64 GB |
5 Core | 16核 | 64 GB |
Trino内存配置建议
内存不足是导致Trino查询任务失败的主要原因。与Trino内存相关参数主要有(单位为GB、MB等):
query.max-memory-per-node
query.max-memory
query.max-total-memory-per-node(已在社区369版本移除,DataLake集群的Trino均不包含此配置)
query.max-total-memory
memory.heap-headroom-per-node
您可以通过以下方式修改这些参数:
修改JVM参数。
在进行内存配置时,首先应修改JVM配置。
在EMR控制台Trino服务的配置页面,单击jvm.config页签,按照以下说明修改-Xmx后面对应的值:
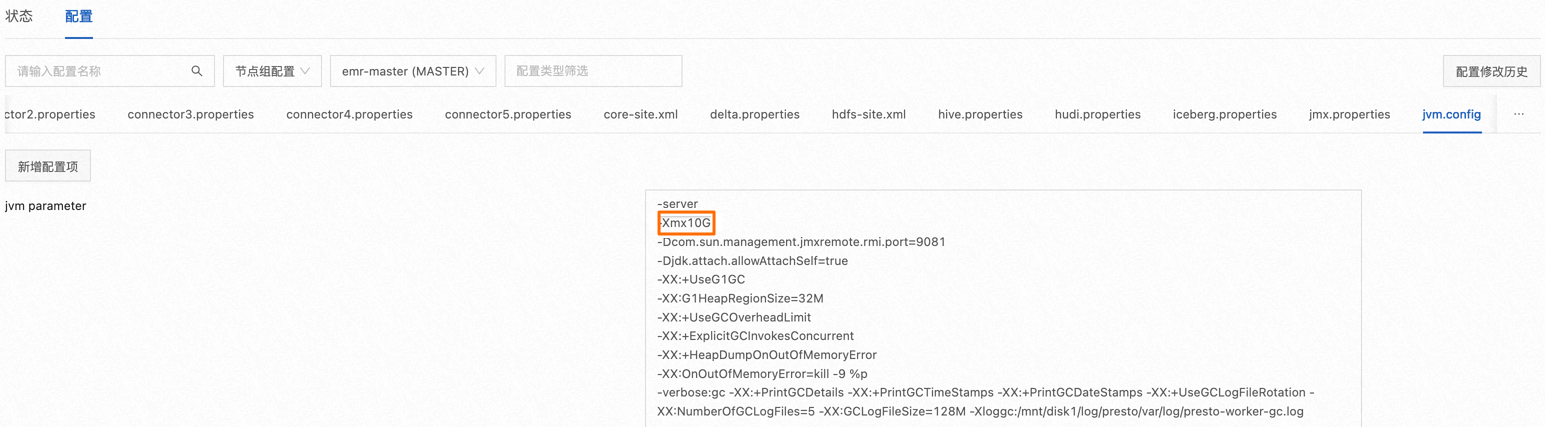
对于Trino独立集群,或是仅使用Trino服务的集群,该值可以调整为集群物理内存的70%左右,这样可以兼顾效率和稳定性。
集群配置较大时(例如实例内存超过128 GB时)可以适当增大该值,但不建议过大。尤其是在存在大量Native方法请求时,应根据实际情况降低这个值,否则进程容易因内存不足被操作系统终止,从而出现Worker重启导致任务失败。
如果Master和Core节点的配置不同,可以分别修改节点组或单台节点的配置。
对于Trino集群选型建议中所列规格的集群,JVM参数可以配置为45 GB~50 GB。
配置内存参数。
在EMR控制台Trino服务的配置页面,单击config.properties页签,修改对应的值。
参数
描述
默认值
建议值
query.max-memory-per-node
一条查询在单台Worker节点的用户内存。
2 GB
不大于JVM内存与memory.heap-headroom-per-node的差值即可,即不大于70%的JVM内存。并发高时建议适当降低。
query.max-memory
一条查询在集群所有节点上的总用户内存。
4 GB
query.max-memory-per-node * Worker数。
query.max-total-memory
一条查询在集群上消耗的总内存,应该高于或等于
query.max-memory的值。6 GB
并发不高时,配置为与query.max-memory相等即可;并发较高时,query.max-total-memory不能超过集群的最大内存容量,即70%的JVM内存 * Worker数。应根据需求按比例同步降低query.max-memory和query.max-memory-per-node的值,query.max-memory最多可降低到query.max-total-memory的二分之一,此时query.max-memory-per-node相应调整为query.max-memory/Worker数。
memory.heap-headroom-per-node
预留的JVM堆内存。
30%的JVM内存
无特殊需求不建议修改。
其中,对于query.max-memory-per-node和memory.heap-headroom-per-node参数,每个节点可以单独配置;query.max-memory和query.max-total-memory全集群建议保持一致。
对于Trino集群选型建议中所列规格的集群,query.max-memory-per-node可以设置为30 GB~35 GB,query.max-memory和query.max-total-memory则相应为150 GB~165 GB。如果经常遇到查询执行过程中Worker停止服务的情况,可以尝试逐渐减小query.max-memory-per-node的值。
配置保存并部署后,重启所有节点服务,使得内存配置生效。
其他相关配置
如果想要对单个查询使用的资源进行限制,可以使用资源组功能,详情请参见Resource groups。
如果查询速度慢,可尝试修改task.concurrency的值来调整并发数,更多参数请参见Task properties。