
TPC-DS是大数据领域最为知名的Benchmark标准。阿里云E-MapReduce多次刷新TPC-DS官方最好成绩,并且是第一个通过认证的可运行TPC-DS 100 TB的大数据系统。本文介绍如何在EMR集群完整运行TPC-DS的99个SQL,并得到最佳的性能体验。
背景信息
TPC-DS是全球最知名的数据管理系统评测基准标准化组织TPC(事务性管理委员会)制定的标准规范,并由TPC管理测试结果的发布。TPC-DS官方工具只包含SQL生成器以及单机版数据生成工具,并不适合大数据场景,所以本文教程中使用的工具和集群信息如下:
- Hive TPC-DS Benchmark测试工具。
该工具是业界最常用的测试工具,是由Hortonworks公司开发,支持使用Hive和Spark运行TPC-DS以及TPC-H等Benchmark。
EMR集群版本为EMR-5.19.0。
Hive TPC-DS Benchmark测试工具是基于Hortonworks HDP 3版本开发的,对应的Hive版本是3.1。本文教程使用的是EMR-5.19.0版本。
使用限制
EMR-4.8.0及之后的版本、EMR-5.1.0以及之后的版本均可运行该教程。
注意事项
本文示例使用的是DataLake集群,所以Master节点名称为master-1-1。如果您使用的是Hadoop集群,请修改文档中的节点名称为emr-header-1。
步骤一:创建EMR集群和下载TPC-DS Benchmark工具
创建EMR-5.19.0集群,具体操作步骤,请参见创建集群。
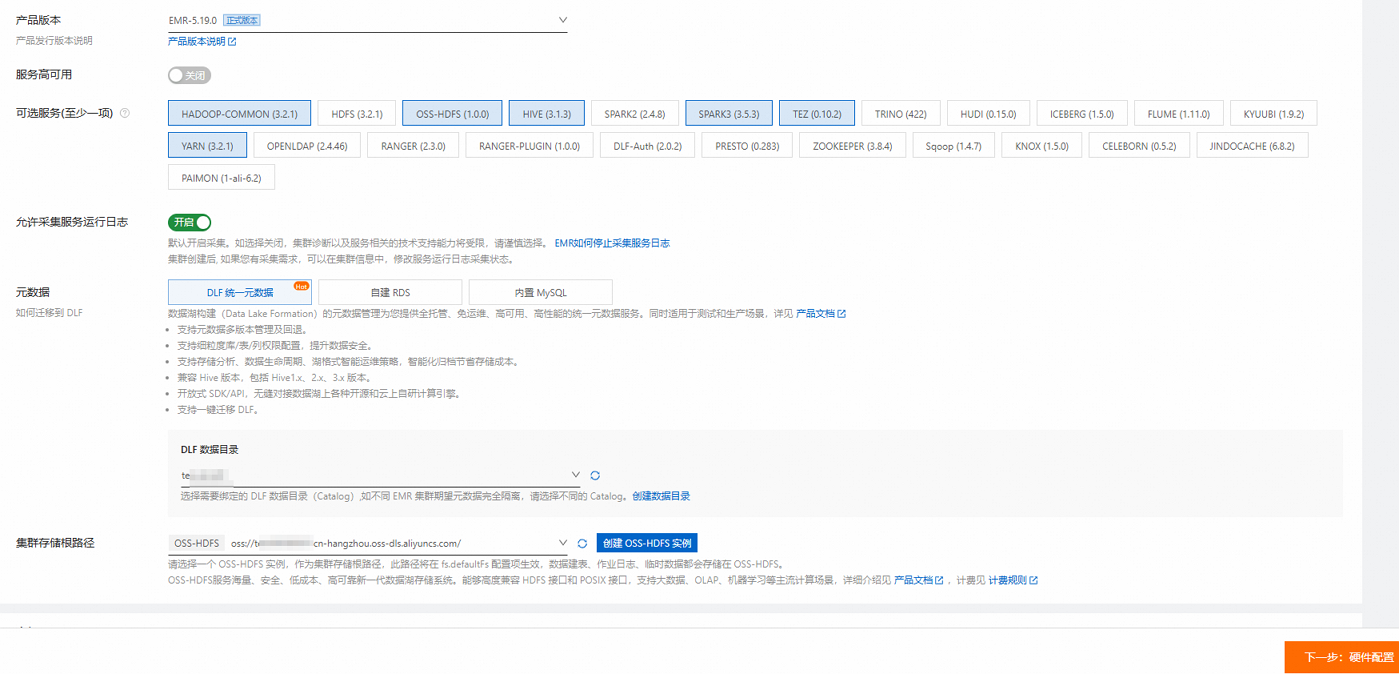
在创建集群时,请关注如下配置信息:
业务场景:选择数据湖。
产品版本:以EMR-5.19.0版本为例。
可选服务:使用默认配置。
元数据:推荐使用DLF统一元数据。
集群存储根路径:选择一个开通HDFS服务的Bucket。
如果您当前的地域不支持OSS-HDFS,请考虑更换地域或改为使用HDFS服务,即在可选服务中去掉OSS-HDFS服务,选择HDFS服务。

硬件配置:如果想获得最佳性能,Core实例推荐使用大数据型或本地SSD。如果想用小规模数据快速完成所有流程,Core实例也可以选择4 vCPU 16 GiB规格的通用型实例。
重要根据您选择运行的数据集确定集群规模,确保Core实例的数据盘总容量大于数据集规模的三倍。数据集相关信息,请参见步骤三:生成并加载数据。
挂载公网:在Master节点组中,打开挂载公网开关。
通过SSH方式连接集群的Master节点,具体操作请参见登录集群。
安装Git和Maven。
执行以下命令,安装Git。
sudo yum install -y git在Apache Maven Project下载最新的Binary tar.gz archive。
本文将以apache-maven-3.9.10-bin.tar.gz为例进行说明。
上传下载好的文件到EMR集群的Master节点,并解压缩。
tar zxf apache-maven-3.9.10-bin.tar.gz cd apache-maven-3.9.10 # 设置Maven环境变量(仅在当前终端会话中有效) export MAVEN_HOME=`pwd` export PATH=`pwd`/bin:$PATH
下载TPC-DS Benchmark工具。
执行以下命令,上传ZIP文件到EMR集群的Master节点。
scp hive-testbench-hdp3.zip root@**.**.**.**:/root/说明**.**.**.**为Master节点的公网IP地址。您可以在集群的节点管理页面,单击Master节点组所在行的 图标,获取Master节点的公网IP地址。
图标,获取Master节点的公网IP地址。执行以下命令,解压缩ZIP文件。
unzip hive-testbench-hdp3.zip
步骤二:编译并打包数据生成器
(可选)配置阿里云镜像。
如果在中国内地可以使用阿里云镜像加速Maven编译。使用阿里云镜像,编译并打包数据生成器的耗时为2min~3min。
执行如下命令,新建文件目录。
mkdir -p ~/.m2/执行如下命令,将Maven配置文件拷贝到新文件目录下。
cp $MAVEN_HOME/conf/settings.xml ~/.m2/在
~/.m2/settings.xml文件中添加镜像信息,具体内容如下所示。<mirror> <id>aliyun</id> <mirrorOf>central</mirrorOf> <name>Nexus aliyun</name> <url>http://maven.aliyun.com/nexus/content/groups/public</url> </mirror>
切换到
hive-testbench目录。cd hive-testbench使用TPC-DS工具集进行编译并打包数据生成器。
./tpcds-build.sh
步骤三:生成并加载数据
设置数据规模SF(Scale Factor)。
SF单位相当于GB,所以SF=1相当于1 GB,SF=100相当于100 GB,SF=1000相当于1 TB,以此类推。本步骤示例采用小规模数据集,推荐使用SF=3。具体命令如下:
SF=3重要请确保数据盘总大小是数据集规模的3倍以上,否则后续流程中会出现报错情况。
检查并清理Hive数据库。
检查Hive数据库是否存在。
hive -e "desc database tpcds_bin_partitioned_orc_$SF"(可选)清理已经存在的Hive数据库。
重要如果Hive数据库tpcds_bin_partitioned_orc_$SF已经存在,需要执行下面的命令清理数据库,否则后续流程会报错。如果不存在,则跳过该步骤。
hive -e "drop database tpcds_bin_partitioned_orc_$SF cascade"
配置Hive服务地址。
tpcds-setup.sh脚本默认配置的Hive服务地址与EMR集群环境不一致,所以需要将脚本中HiveSever的地址替换为EMR集群中的Hive服务地址。具体命令如下所示。sed -i 's/localhost:2181\/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2?tez.queue.name=default/master-1-1:10000\//' tpcds-setup.sh脚本默认配置的Hive服务地址为:
jdbc:hive2://localhost:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2?tez.queue.name=default。通过上述命令替换后的Hive服务地址为:jdbc:hive2://master-1-1:10000/。修复开源工具配置问题。
部分参数在Hive 2和Hive 3等开源版本中不支持,继续使用TPC-DS会导致作业报错,所以需要参考以下命令替换参数。
sed -i 's/hive.optimize.sort.dynamic.partition.threshold=0/hive.optimize.sort.dynamic.partition=true/' settings/*.sql生成并加载数据。
在SF=3时,该步骤耗时为40min~50min。如果运行正常,TPC-DS数据表将会加载到tpcds_bin_partitioned_orc_$SF数据库中。通过EMR存储和计算分离的架构能力,可以很方便地做到将数据保存在OSS-HDFS。
执行以下命令,生成并加载数据。
./tpcds-setup.sh $SF返回信息如下图所示。
获取Hive表统计信息。
推荐使用Hive SQL ANALYZE命令获取Hive表统计信息,可以加快后续SQL的查询速度。此步骤在SF=3时,耗时为20min~30min。
hive -f ./ddl-tpcds/bin_partitioned/analyze.sql \ --hiveconf hive.execution.engine=tez \ --database tpcds_bin_partitioned_orc_$SF
因为同时使用了数据湖构建(DLF)来保存Hive表的元数据,所以数据生成后,您可以随时释放当前的EMR集群,并在同一地域的其他EMR集群上再次查询当前生成的TPC-DS数据集。
步骤四:运行TPC-DS SQL
本步骤分别介绍如何使用Hive和Spark运行TPC-DS SQL。
使用Hive运行TPC-DS SQL
通过以下命令执行单SQL。
TPC-DS SQL共有99个文件都放在
sample-queries-tpcds工作目录下(包括query10.sql和query11.sql等文件)。在SF=3时,所有的SQL都可以在5min内返回结果。重要因为TPC-DS Query和数据都是随机生成,所以部分SQL查询返回结果数为0属于正常现象。
cd sample-queries-tpcds hive --database tpcds_bin_partitioned_orc_$SF set hive.execution.engine=tez; source query10.sql;执行完命令后,可以执行退出Hive
利用工具包中的脚本顺序执行99个完整SQL。具体命令如下:
cd ~/hive-testbench # 生成一个Hive配置文件,并指定Hive执行引擎为Tez。 echo 'set hive.execution.engine=tez;' > sample-queries-tpcds/testbench.settings ./runSuite.pl tpcds $SF返回信息如下图所示。
使用Spark运行TPC-DS SQL
TPC-DS工具集中包含Spark SQL用例,用例位于spark-queries-tpcds目录下,可以使用spark-sql或者spark-beeline等命令行工具执行这些SQL。本步骤以Spark Beeline工具连接Spark ThriftServer为例,介绍如何使用Spark运行TPC-DS SQL来查询步骤三:生成并加载数据生成的TPC-DS数据集。
EMR Spark支持HDFS和OSS等多种存储介质保存的数据表,也支持数据湖构建(DLF)元数据。
使用Spark Beeline ANALYZE命令获得Hive表统计信息,加快后续SQL查询速度。
cd ~/hive-testbench spark-beeline -u jdbc:hive2://master-1-1:10001/tpcds_bin_partitioned_orc_$SF \ -f ./ddl-tpcds/bin_partitioned/analyze.sql切换到Spark SQL用例所在的文件目录。
cd spark-queries-tpcds/通过以下命令执行单个SQL。
spark-beeline -u jdbc:hive2://master-1-1:10001/tpcds_bin_partitioned_orc_$SF -f q1.sql通过脚本顺序执行99个SQL。
TPC-DS工具集中没有包含批量执行Spark SQL的脚本,所以本步骤提供一个简单脚本供参考。
for q in `ls *.sql`; do spark-beeline -u jdbc:hive2://master-1-1:10001/tpcds_bin_partitioned_orc_$SF -f $q > $q.out done重要SQL列表中
q30.sql文件存在列名c_last_review_date_sk错写为c_last_review_date的情况,所以该SQL运行失败属于正常现象。通过脚本顺序执行99个Spark SQL的时候,如果出现报错情况,解决方案请参见常见问题。