
本文介绍Hive作业异常的排查方法和解决方法。
异常排查
如果客户端遇到作业异常或性能等问题,您可以按照如下步骤进行排查:
查看Hive客户端日志。
Hive CLI命令行提交的作业客户端日志位于集群或Gateway节点的/tmp/hive/$USER/hive.log或者/tmp/$USER/hive.log。
Hive Beeline或者JDBC提交的作业日志位于HiveServer服务日志中(一般位于/var/log/emr/hive或者/mnt/disk1/log/hive目录)。
查看Hive作业提交的YARN Application日志,使用yarn命令可以获取日志。
yarn logs -applicationId application_xxx_xxx -appOwner userName
内存问题引起的报错
Container内存不足引起的OOM
报错日志:java.lang.OutOfMemoryError: GC overhead limit exceeded或者java.lang.OutOfMemoryError: Java heap space。
解决方法:调大Container的内存,Hive on MR作业需要同时调大JVM Heap Size。
Hive on MR:在YARN服务的配置页面,单击mapred-site.xml页签,调大maper和reducer的内存。
mapreduce.map.memory.mb=4096 mapreduce.reduce.memory.mb=4096同时修改mapreduce.map.java.opts和mapreduce.reduce.java.opts的JVM参数
-Xmx为mapreduce.map.memory.mb和mapreduce.reduce.memory.mb的80%。mapreduce.map.java.opts=-Xmx3276m (其他参数保持不变) mapreduce.reduce.java.opts=-Xmx3276m (其他参数保持不变)Hive on Tez
如果Tez container内存不足,则在Hive服务的配置页面,单击hive-site.xml页签,调大Tez container内存。
hive.tez.container.size=4096如果Tez am内存不足,则在Tez服务的配置页面,单击tez-site.xml页签,调大Tez am内存。
tez.am.resource.memory.mb=4096
Hive on Spark:在Spark服务的
spark-defaults.conf中调大Spark Executor内存。spark.executor.memory=4g
因Container内存使用过多被YARN Kill
报错日志:Container killed by YARN for exceeding memory limits。
原因分析:Hive Task使用的内存(包括JVM堆内和堆外内存,以及子进程)超过了作业向YARN申请的内存。比如Hive on MR作业的Map Task JVM进程heap size(mapreduce.map.java.opts=-Xmx4g)超过了YARN内存申请量(mapreduce.map.memory.mb=3072,3G),会导致Container被YARN NodeManager Kill。
解决方法:
Hive on MR作业可增大mapreduce.map.memory.mb和mapreduce.reduce.memory.mb参数值,并确保大于mapreduce.map.java.opts和mapreduce.reduce.java.opts的JVM参数
-Xmx值的1.25倍及以上。Hive on Spark作业可增大spark.executor.memoryOverhead参数值,并确保大于spark.executor.memory参数值的25%及以上。
SortBuffer配置太大导致OOM
报错日志:
Error running child: java.lang.OutOfMemoryError: Java heap space at org.apache.hadoop.mapred.MapTask$MapOutputBuffer.init(MapTask.java:986)原因分析:Sort Buffer Size超过了Hive Task Container Size,例如:Container内存配了1300 MB,但Sortbuffer配了1024 MB。
解决方法:调大Container内存,或调小Sortbuffer。
tez.runtime.io.sort.mb (Hive on Tez) mapreduce.task.io.sort.mb (Hive on MR)
部分GroupBy语句引起的OOM
报错日志:
22/11/28 08:24:43 ERROR Executor: Exception in task 1.0 in stage 0.0 (TID 0) java.lang.OutOfMemoryError: GC overhead limit exceeded at org.apache.hadoop.hive.ql.exec.GroupByOperator.updateAggregations(GroupByOperator.java:611) at org.apache.hadoop.hive.ql.exec.GroupByOperator.processHashAggr(GroupByOperator.java:813) at org.apache.hadoop.hive.ql.exec.GroupByOperator.processKey(GroupByOperator.java:719) at org.apache.hadoop.hive.ql.exec.GroupByOperator.process(GroupByOperator.java:787) at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:897) at org.apache.hadoop.hive.ql.exec.SelectOperator.process(SelectOperator.java:95) at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:897) at org.apache.hadoop.hive.ql.exec.TableScanOperator.process(TableScanOperator.java:130) at org.apache.hadoop.hive.ql.exec.MapOperator$MapOpCtx.forward(MapOperator.java:148) at org.apache.hadoop.hive.ql.exec.MapOperator.process(MapOperator.java:547)原因分析:GroupBy的HashTable占用太多内存导致OOM。
解决方法:
减小Split Size至128 MB、64 MB或更小,增大作业并发度:
mapreduce.input.fileinputformat.split.maxsize=134217728或mapreduce.input.fileinputformat.split.maxsize=67108864。增大Mapper、Reducer的并发度。
增大Container的内存。具体方法,请参见Container内存不足引起的OOM。
读取Snappy文件出现OOM
原因分析:LogService等服务写入的标准Snappy文件和Hadoop生态的Snappy文件格式不同,EMR默认处理的是Hadoop修改过的Snappy格式,处理标准格式时会报错OutOfMemoryError。
解决方法:对Hive作业配置如下参数。
set io.compression.codec.snappy.native=true;
元数据相关报错
Drop大分区表超时
报错日志:
FAILED: Execution ERROR, return code 1 from org.apache.hadoop.hive.ql.exec.DDLTask. org.apache.thrift.transport.TTransportException: java.net.SocketTimeoutException: Read timeout原因分析:作业异常的可能原因是表分区太多,Drop耗时较长,导致Hive Metastore client网络超时。
解决方法:
在EMR控制台Hive服务的配置页面,单击hive-site.xml页签,调大Client访问metastore的超时时间。
hive.metastore.client.socket.timeout=1200s批量删除分区,例如多次执行带条件的分区。
alter table [TableName] DROP IF EXISTS PARTITION (ds<='20220720')
insert overwrite动态分区导致作业失败
报错日志:通过
insert overwrite操作动态分区或执行类似存在insert overwrite操作的作业时,出现Exception when loading xxx in table报错,HiveServer日志中出现了以下报错日志。Error in query: org.apache.hadoop.hive.ql.metadata.HiveException: Directory oss://xxxx could not be cleaned up.;原因分析:元数据和数据不一致,元数据中存在某个分区的记录,但数据存储系统中没有该路径,导致使用cleanup方法的时候报错找不到路径。
解决方法:您可以尝试修复元数据问题之后再重新执行作业。
Hive读表或者删除表时报错java.lang.IllegalArgumentException: java.net.UnknownHostException: emr-header-1.xxx
原因分析:当EMR集群使用DLF统一元数据或者统一meta数据库(旧版功能)时,创建的数据库初始路径是EMR当前集群的HDFS路径(例如
hdfs://master-1-1.xxx:9000/user/hive/warehouse/test.db或者hdfs://emr-header-1.cluster-xxx:9000/user/hive/warehouse/test.db)。Hive表路径会继承数据库路径,同样也会使用当前集群的HDFS路径(例如hdfs://master-1-1.xxx:9000/user/hive/warehouse/test.db/test_tbl)。当启用一个新EMR集群,同时使用Hive读写旧集群创建的Hive表或者数据库时,新集群可能无法连接旧集群或者因旧集群已释放,会出现java.net.UnknownHostException异常。解决方法:
方法1:如果确认Hive表数据是临时或者测试数据,可以尝试修改Hive表路径为某个OSS路径,并且再次调用drop table或drop database命令。
-- Hive SQL alter table test_tbl set location 'oss://bucket/not/exists' drop table test_tbl; alter table test_pt_tbl partition (pt=xxx) set location 'oss://bucket/not/exists'; alter table test_pt_tbl drop partition pt=xxx); alter database test_db set location 'oss://bucket/not/exists' drop datatabase test_db方法2:如果确认Hive表数据是有效数据,但在新集群上无法访问。此时EMR旧集群上的Hive表数据保存在HDFS上,可以先尝试将 HDFS数据转移到OSS上,并且创建新表。
hadoop fs -cp hdfs://emr-header-1.xxx/old/path oss://bucket/new/path hive -e "create table new_tbl like old_tbl location 'oss://bucket/new/path'"
Hive UDF和第三方包
Hive lib目录下放置三方包导致冲突
原因分析:在Hive lib目录($HIVE_HOME/lib)下放置三方包或者替换Hive包经常会导致各种冲突问题,请避免此类操作。
解决方法:把放在$HIVE_HOME/lib里的三方包移除,恢复替换为原始的Hive JAR包。
Hive无法使用reflect函数
原因分析:在Ranger鉴权开启的情况下可能无法使用reflect函数。
解决方法:将reflect函数从黑名单移除,在
hive-site.xml中配置。hive.server2.builtin.udf.blacklist=empty_blacklist
自定义UDF导致作业运行慢
原因分析:Hive作业运行慢,但未发现异常日志,可能原因是Hive自定义UDF性能存在问题。
解决方法:可以通过对Hive task进行thread dump定位问题,根据thread dump发现的性能热点针对性优化自定义UDF。
grouping()使用异常
异常现象:在使用
grouping()函数时,遇到以下报错信息。grouping() requires at least 2 argument, got 1该错误表明
grouping()函数的调用参数解析异常。原因分析:此问题是由开源版本 Hive 的一个已知Bug导致的。Hive 对
grouping()函数的解析是大小写敏感的。当使用小写的grouping()时,Hive 可能无法正确识别该函数,从而导致参数解析错误。解决方法:将 SQL 中的
grouping()函数改为大写的GROUPING()即可解决问题。
引擎兼容问题
Hive和Spark时区不一致导致结果不一致
异常现象:Hive的from_unix_time时区固定为UTC,而Spark使用的是本地时区,如果两者的时区不一致会导致结果不一致。
解决方法:修改Spark时区为UTC,在Spark SQL中插入如下代码:
set spark.sql.session.timeZone=UTC;或者修改Spark配置文件,添加新的配置:
spark.sql.session.timeZone=UTC
历史Hive版本缺陷
Hive on Spark打开动态分区执行慢(已知缺陷)
原因分析:Hive开源版本的缺陷,Beeline的方式把spark.dynamicAllocation.enabled打开了,导致Hive在计算Shuffle的Partition的时候总是算成1。
解决方法:Hive on Spark作业关闭动态资源伸缩或者使用Hive on Tez。
spark.dynamicAllocation.enabled=false
打开dynamic.partition.hashjoin后tez报错(已知缺陷)
报错日志:
Vertex failed, vertexName=Reducer 2, vertexId=vertex_1536275581088_0001_5_02, diagnostics=[Task failed, taskId=task_1536275581088_0001_5_02_000009, diagnostics=[TaskAttempt 0 failed, info=[Error: Error while running task ( failure ) : attempt_1536275581088_0001_5_02_000009_0:java.lang.RuntimeException: java.lang.RuntimeException: cannot find field _col1 from [0:key, 1:value] at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:296) at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:250)原因分析:Hive开源版本缺陷。
解决方法:临时解决方案是关闭配置。
hive.optimize.dynamic.partition.hashjoin=false
MapJoinOperator报错NullPointerException(已知缺陷)
报错日志:
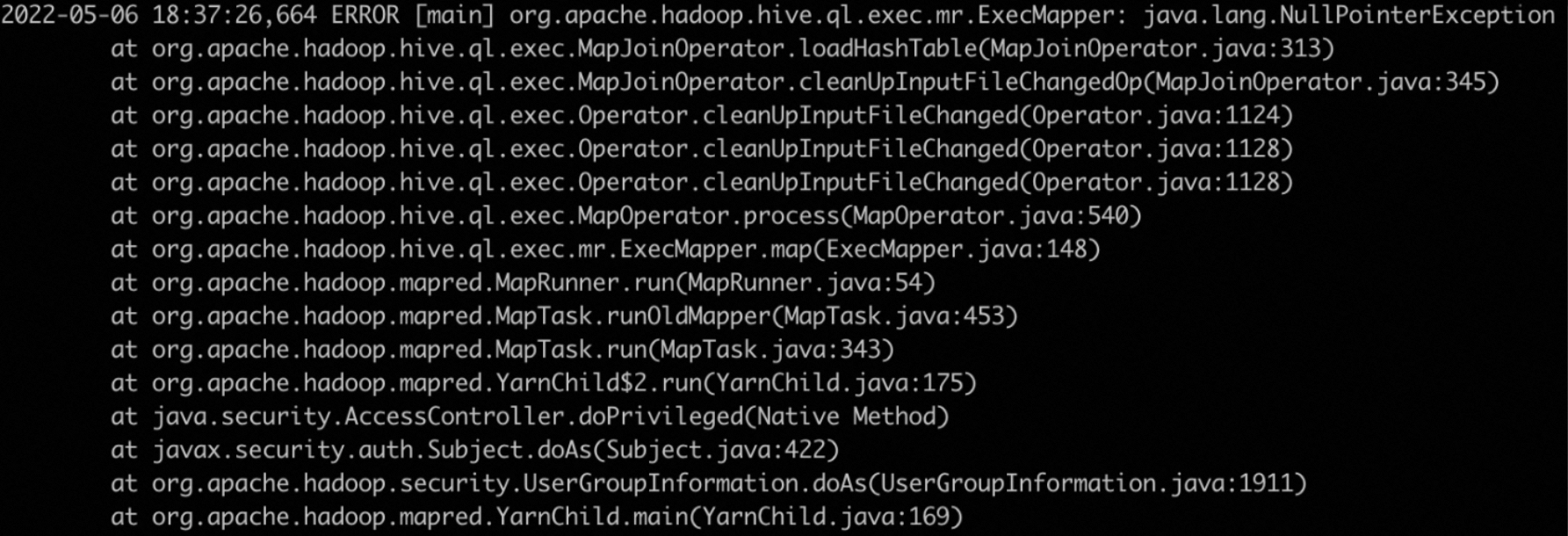
原因分析:开启了hive.auto.convert.join.noconditionaltask会导致报错。
解决方法:关闭相关配置。
hive.auto.convert.join.noconditionaltask=false
Hive on Tez报错IllegalStateException(已知缺陷)
报错日志:
java.lang.RuntimeException: java.lang.IllegalStateException: Was expecting dummy store operator but found: FS[17] at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:296) at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:250) at org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:374) at org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:73) at org.apache.tez.runtime.task.TaskRunner2Callable$1.run(TaskRunner2Callable.java:61) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1730) at org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:61) at org.apache.tez.runtime.task.TaskRunner2Callable.callInternal(TaskRunner2Callable.java:37) at org.apache.tez.common.CallableWithNdc.call(CallableWithNdc.java:36)原因分析:Hive开源版本缺陷,在开启Hive am reuse之后出现,目前EMR Hive暂未解决该问题。
解决方法:在单个作业层面把Tez ApplicationMaster reuse功能关掉。
set tez.am.container.reuse.enabled=false;
其他异常
select count(1)结果为0
原因分析:
select count(1)使用的是Hive表统计信息(statistics),但这张表的统计信息不准确。解决方法:修改配置不使用统计信息。
hive.compute.query.using.stats=false或者使用analyze命令重新统计表统计信息。
analyze table <table_name> compute statistics;
在自建ECS上提交Hive作业异常
在自建ECS上提交Hive作业(不在EMR产品范围内),会出现不可预期报错。请使用EMR Gateway集群或者使用EMR-CLI自定义部署Gateway环境。更多信息,请参见使用EMR-CLI自定义部署Gateway环境。
数据倾斜导致的作业异常
异常现象:
Shuffle数据把磁盘打满。
某些Task执行时间特别长。
某些Task或Container出现OOM。
解决方法:
打开Hive skewjoin优化。
set hive.optimize.skewjoin=true;增大Mapper、Reducer的并发度。
增大Container的内存。具体方法,请参见Container内存不足引起的OOM。
报错“Too many counters: 121 max=120”,该如何处理?
问题描述:使用Tez或MR引擎,在使用Hive SQL执行作业时报错。
报错分析:当前作业的counters数量超过默认的counters限制。
解决方法:您可以在EMR控制台YARN服务的配置页签,搜索mapreduce.job.counters.max参数,调大该参数值,修改完后重新提交Hive作业,如果使用Beeline或者JDBC提交作业,需要重启HiveServer服务。