
本文通过场景化为您介绍如何使用Jindo DistCp。
前提条件
- 已创建相应版本的集群,详情请参见创建集群。
- 已安装JDK 1.8。
- 根据您使用的Hadoop版本,下载jindo-distcp-<version>.jar。
- Hadoop 2.7及后续版本,请下载jindo-distcp-3.0.0.jar。
- Hadoop 3.x系列版本,请下载jindo-distcp-3.0.0.jar。
场景预览
- 场景一:导入HDFS数据至OSS,需要使用哪些参数?如果数据量很大、文件很多(百万千万级别)时,该使用哪些参数优化?
- 场景二:使用Jindo DistCp成功导完数据后,如何验证数据完整性?
- 场景三:导入HDFS数据至OSS时,DistCp任务存在随时失败的情况,该使用哪些参数支持断点续传?
- 场景四:成功导入HDFS数据至OSS,数据不断增量增加,在Distcp过程中可能已经产生了新文件,该使用哪些参数处理?
- 场景五:如果需要指定Jindo DistCp作业在Yarn上的队列以及可用带宽,该使用哪些参数?
- 场景六:当通过冷归档、归档或低频形式写入OSS,该使用哪些参数?
- 场景七:针对小文件比例和文件大小情况,该使用哪些参数来优化传输速度?
- 场景八:如果需要使用S3作为数据源,该使用哪些参数?
- 场景九:如果需要写入文件至OSS上并压缩(LZO和GZ格式等)时,该使用哪些参数?
- 场景十:如果需要把本次Copy中符合特定规则或者同一个父目录下的部分子目录作为Copy对象,该使用哪些参数?
- 场景十一:如果想合并符合一定规则的文件,以减少文件个数,该使用哪些参数?
- 场景十二:如果Copy完文件,需要删除原文件,只保留目标文件时,该使用哪些参数?
- 场景十三:如果不想将OSS AccessKey这种参数写在命令行里,该如何处理?
场景一:导入HDFS数据至OSS,需要使用哪些参数?如果数据量很大、文件很多(百万千万级别)时,该使用哪些参数优化?
- 可以访问HDFS,并有读数据权限。
- 需要提供OSS的AccessKey(AccessKey ID和AccessKey Secret),以及Endpoint信息,且该AccessKey具有写目标Bucket的权限。
- OSS Bucket不能为归档类型。
- 环境可以提交MapReduce任务。
- 已下载Jindo DistCp JAR包。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 10--enableBatch参数来进行优化。优化命令如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 500 --enableBatch场景二:使用Jindo DistCp成功导完数据后,如何验证数据完整性?
- Jindo DistCp Counters
您可以在MapReduce任务结束的Counter信息中,获取Distcp Counters的信息。
Distcp Counters Bytes Destination Copied=11010048000 Bytes Source Read=11010048000 Files Copied=1001 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0参数含义如下:- Bytes Destination Copied:表示目标端写文件的字节数大小。
- Bytes Source Read:表示源端读文件的字节数大小。
- Files Copied:表示成功Copy的文件数。
- Jindo DistCp --diff
您可以使用
--diff命令,进行源端和目标端的文件比较。该命令会对文件名和文件大小进行比较,记录遗漏或者未成功传输的文件,存储在提交命令的当前目录下,生成manifest文件。在场景一的基础上增加--diff参数即可,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diff当全部文件传输成功时,系统返回如下信息。INFO distcp.JindoDistCp: distcp has been done completely
场景三:导入HDFS数据至OSS时,DistCp任务存在随时失败的情况,该使用哪些参数支持断点续传?
- 增加一个
--diff命令,查看所有文件是否都传输完成。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --diff当所有文件都传输完成,则会提示如下信息。INFO distcp.JindoDistCp: distcp has been done completely. - 文件没有传输完成时会生成manifest文件,您可以使用
--copyFromManifest和--previousManifest命令进行剩余文件的Copy。示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --dest oss://destBucket/hourly_table --previousManifest=file:///opt/manifest-2020-04-17.gz --copyFromManifest --parallelism 20file:///opt/manifest-2020-04-17.gz为您当前执行命令的本地路径。
场景四:成功导入HDFS数据至OSS,数据不断增量增加,在Distcp过程中可能已经产生了新文件,该使用哪些参数处理?
在使用时,上游进程会不断产生新的文件。例如,新文件可能每小时或每分钟创建一次。您可以配置下游进程,按不同的日程安排接收文件。JindoDistCp提供了update方式来增量Copy文件。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --parallelism 10 --update--update:指定为增量Copy模式,在Copy前先比较文件名,再比较文件大小,最后比较文件Checksum。如果您不希望比较文件Checksum,可以通过增加--disableChecksum参数来关闭,即只比较文件名和文件大小。
场景五:如果需要指定Jindo DistCp作业在Yarn上的队列以及可用带宽,该使用哪些参数?
--queue:指定Yarn队列的名称。--bandwidth:指定带宽的大小,单位为MB。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --queue yarnqueue --bandwidth 6 --parallelism 10场景六:当通过冷归档、归档或低频形式写入OSS,该使用哪些参数?
- 当通过冷归档形式写入OSS时,需要在场景一的基础上增加
--policy coldArchive参数,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --policy coldArchive --parallelism 20说明 冷归档存储类型目前只支持部分地域,详情请参见存储类型介绍。 - 当通过归档形式写入OSS时,需要在场景一的基础上增加
--policy archive参数,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --policy archive --parallelism 20 - 当通过低频形式写入OSS时,需要在场景一的基础上增加
--policy ia参数,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --policy ia --parallelism 20
场景七:针对小文件比例和文件大小情况,该使用哪些参数来优化传输速度?
- 小文件较多,大文件较大情况。
如果要Copy的所有文件中小文件的占比较高,大文件较少,但是单个文件数据较大,在正常流程中是按照随机方式来进行Copy文件分配,此时如果不做优化很可能造成一个Copy进程分配到大文件的同时也分配到很多小文件,不能发挥最好的性能。
在场景一的基础上增加--enableDynamicPlan开启优化选项,但不能和--enableBalancePlan一起使用。示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableDynamicPlan --parallelism 10优化对比如下。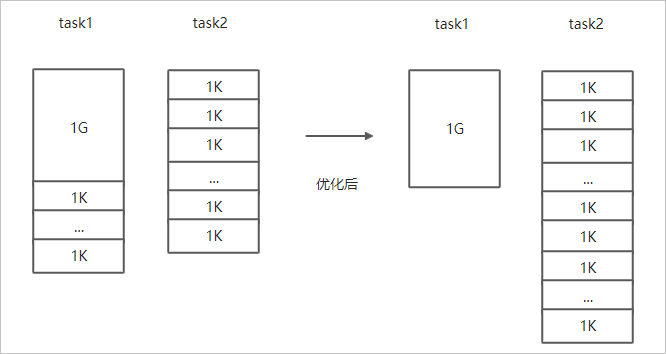
- 文件总体均衡,大小差不多情况。
如果您要Copy的数据里文件大小总体差不多,比较均衡,您可以使用
--enableBalancePlan优化。示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --enableBalancePlan --parallelism 10优化对比如下。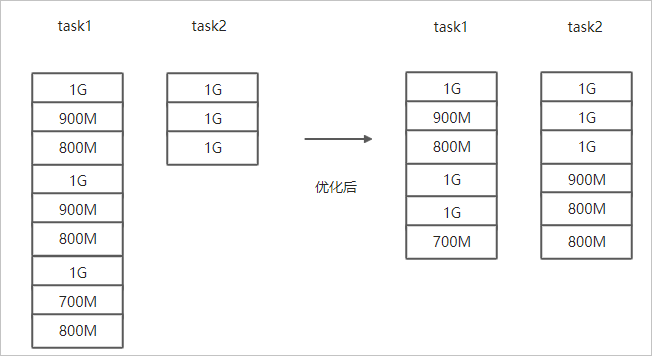
场景八:如果需要使用S3作为数据源,该使用哪些参数?
--s3Key:连接S3的AccessKey ID。--s3Secret:连接S3的AccessKey Secret。--s3EndPoint:连接S3的EndPoint信息。
hadoop jar jindo-distcp-<version>.jar --src s3a://yourbucket/ --dest oss://destBucket/hourly_table --s3Key yourkey --s3Secret yoursecret --s3EndPoint s3-us-west-1.amazonaws.com --parallelism 10场景九:如果需要写入文件至OSS并压缩文件(LZO和GZ格式等)时,该使用哪些参数?
如果您想压缩写入的目标文件,例如LZO和GZ等格式,以降低目标文件的存储空间,您可以使用--outputCodec参数来完成。
--outputCodec参数,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --outputCodec=gz --parallelism 10- none表示保存为未压缩的文件。如果文件已压缩,则Jindo DistCp会将其解压缩。
- keep表示不更改文件压缩形态,按原样复制。
场景十:如果需要把本次Copy中符合特定规则或者同一个父目录下的部分子目录作为Copy对象,该使用哪些参数?
- 如果您需要将Copy列表中符合一定规则的文件进行Copy,需要在场景一的基础上增加
--srcPattern参数,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPattern .*\.log --parallelism 10--srcPattern:进行过滤的正则表达式,符合规则进行Copy,否则抛弃。 - 如果您需要Copy同一个父目录下的部分子目录,需要在场景一的基础上增加
--srcPrefixesFile参数。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --srcPrefixesFile file:///opt/folders.txt --parallelism 20--srcPrefixesFile:存储需要Copy的同父目录的文件夹列表的文件。示例中的folders.txt内容如下。hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-01 hdfs://emr-header-1.cluster-50466:9000/data/incoming/hourly_table/2017-02-02
场景十一:如果想合并符合一定规则的文件,以减少文件个数,该使用哪些参数?
--targetSize:合并文件的最大大小,单位MB。--groupBy:合并规则,正则表达式。
hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --targetSize=10 --groupBy='.*/([a-z]+).*.txt' --parallelism 20场景十二:如果Copy完文件,需要删除原文件,只保留目标文件时,该使用哪些参数?
--deleteOnSuccess参数,示例如下。hadoop jar jindo-distcp-<version>.jar --src /data/incoming/hourly_table --dest oss://destBucket/hourly_table --ossKey yourkey --ossSecret yoursecret --ossEndPoint oss-cn-hangzhou.aliyuncs.com --deleteOnSuccess --parallelism 10场景十三:如果不想将OSS AccessKey这种参数写在命令行里,该如何处理?
- 如果您需要保存OSS的AccessKey相关信息,您需要将以下信息保存在core-site.xml中。
<configuration> <property> <name>fs.jfs.cache.oss-accessKeyId</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-accessKeySecret</name> <value>xxx</value> </property> <property> <name>fs.jfs.cache.oss-endpoint</name> <value>oss-cn-xxx.aliyuncs.com</value> </property> </configuration> - 如果您需要保存S3的AccessKey相关信息,您需要将以下信息保存在core-site.xml中。
<configuration> <property> <name>fs.s3a.access.key</name> <value>xxx</value> </property> <property> <name>fs.s3a.secret.key</name> <value>xxx</value> </property> <property> <name>fs.s3.endpoint</name> <value>s3-us-west-1.amazonaws.com</value> </property> </configuration>