OSS-HDFS服务支持RootPolicy。通过RootPolicy,您可以为OSS-HDFS服务设置自定义前缀。此功能使得Serverless Spark能够在无需修改原有访问hdfs://前缀的任务的情况下,直接操作OSS-HDFS上的数据。
前提条件
配置RootPolicy
若您已为集群的OSS-HDFS服务配置了RootPolicy,请跳过配置章节,直接阅读使用RootPolicy。
配置环境变量。
连接ECS实例。具体操作,请参见连接ECS实例。
下载JindoFS命令行工具。
配置访问密钥和环境变量。
进入已安装的Jindofs JAR包下的bin目录。
以下以
jindofs-sdk-x.x.x-linux为例,x.x.x替换为对应的版本号。cd jindofs-sdk-x.x.x-linux/bin/在bin目录下新建配置文件jindofs.cfg,并配置阿里云账号的访问密钥(包括Accesskey ID和Accesskey Secret),或者满足权限要求的RAM用户的访问密钥。
[client] fs.oss.accessKeyId = <key> fs.oss.accessKeySecret = <secret>设置环境变量。
说明<JINDOSDK_CONF_DIR>填写
jindofs.cfg配置文件所在的绝对路径。export JINDOSDK_CONF_DIR=<JINDOSDK_CONF_DIR>
设置RootPolicy。
您可以通过SetRootPolicy命令为指定Bucket注册自定义前缀访问地址,配置命令如下:
./jindofs admin -setRootPolicy oss://<bucket_name>.<dls_endpoint>/ hdfs://<your_ns_name>/以上命令涉及的各项参数说明如下:
参数
说明
bucket_name
填写已开通OSS-HDFS服务的Bucket名称。
dls_endpoint
开通OSS-HDFS服务所在地域对应的Endpoint,例如
cn-hangzhou.oss-dls.aliyuncs.com。如果您不希望在每一次使用RootPolicy相关命令时重复添加<dls_endpoint>选项,您可以选择以下任意方式在Hadoop的
core-site.xml文件中添加配置项。方式一
<configuration> <property> <name>fs.oss.endpoint</name> <value><dls_endpoint></value> </property> </configuration>方式二
<configuration> <property> <name>fs.oss.bucket.<bucket_name>.endpoint</name> <value><dls_endpoint></value> </property> </configuration>
your_ns_name
自定义访问OSS-HDFS服务的nsname,支持任意非空字符串,例如
test,当前版本仅支持根目录。配置Access Policy发现地址和Scheme实现类。
您需要在Hadoop的core-site.xml文件中完成以下配置项。
<configuration> <property> <name>fs.accessPolicies.discovery</name> <value>oss://<bucket_name>.<dls_endpoint>/</value> </property> <property> <name>fs.AbstractFileSystem.hdfs.impl</name> <!-- 请根据Hadoop版本选择fs.AbstractFileSystem.hdfs.impl --> <!-- Hadoop 2.x使用com.aliyun.jindodata.hdfs.v28.HDFS --> <!-- hadoop 3.x使用com.aliyun.jindodata.hdfs.v3.HDFS --> <value>com.aliyun.jindodata.hdfs.v3.HDFS</value> </property> <property> <name>fs.hdfs.impl</name> <!-- 请根据Hadoop版本选择 fs.hdfs.impl --> <!-- Hadoop 2.x使用 com.aliyun.jindodata.hdfs.v28.JindoDistributedFileSystem --> <!-- Hadoop 3.x使用 com.aliyun.jindodata.hdfs.v3.JindoDistributedFileSystem --> <value>com.aliyun.jindodata.hdfs.v3.JindoDistributedFileSystem</value> </property> </configuration>如果您需要为多个Bucket配置Access Policy发现地址和Scheme实现类,则多个Bucket之间需使用逗号
,分隔,例如<value>oss://<bucket1_name>.<dls_endpoint>, oss://<bucket2_name>.<dls_endpoint>/</value>。验证是否已成功配置RootPolicy。
hadoop fs -ls hdfs://<your_ns_name>/返回以下结果,说明已成功配置RootPolicy。
drwxr-x--x - hdfs hadoop 0 2025-06-30 12:27 hdfs://<your_ns_name>/apps drwxrwxrwx - spark hadoop 0 2025-06-30 12:27 hdfs://<your_ns_name>/spark-history drwxrwxrwx - hdfs hadoop 0 2025-06-30 12:27 hdfs://<your_ns_name>/tmp drwxrwxrwx - hdfs hadoop 0 2025-06-30 12:27 hdfs://<your_ns_name>/user使用自定义前缀访问OSS-HDFS服务。
重启Hive、Spark等服务后,您可以通过使用自定义前缀访问OSS-HDFS服务。
(可选)RootPolicy其他用法。
列举指定Bucket当前注册的所有前缀地址
您可以通过listAccessPolicies命令列举指定Bucket当前注册的所有前缀地址。
./jindofs admin -listAccessPolicies oss://<bucket_name>.<dls_endpoint>/删除指定Bucket当前注册的所有前缀地址
您可以通过unsetRootPolicy命令删除指定Bucket当前注册的所有前缀地址。
./jindofs admin -unsetRootPolicy oss://<bucket_name>.<dls_endpoint>/ hdfs://<your_ns_name>/
使用RootPolicy
场景一:在Notebook会话中使用
配置Spark配置。
在EMR Serverless Spark页面,单击左侧导航栏中的会话管理。
在Notebook会话页面,单击创建Notebook会话。
在创建Notebook会话页面,配置以下Spark 配置。
spark.hadoop.fs.accessPolicies.discovery oss://<buckename>.cn-<region>.oss-dls.aliyuncs.com spark.hadoop.fs.AbstractFileSystem.hdfs.impl com.aliyun.jindodata.hdfs.v3.HDFS spark.hadoop.fs.hdfs.impl com.aliyun.jindodata.hdfs.v3.JindoDistributedFileSystem在数据开发Notebook任务中直接使用通过RootPolicy为OSS-HDFS服务设置自定义前缀。
--建表 spark.sql("""CREATE TABLE default.my_orc_table ( id INT, name STRING, age INT ) location 'hdfs://<ns_name>/user/hive/warehouse/ads_user_info_1d_emr/my_orc_table/'""") --插入数据 spark.sql("""INSERT INTO table default.my_orc_table(id, name, age) VALUES (1, 'Alice', 30)"""); --查询 spark.sql("SELECT * FROM default.my_orc_table").show()说明建表语句中“<ns_name>”需替换成您访问OSS-HDFS服务的自定义前缀。
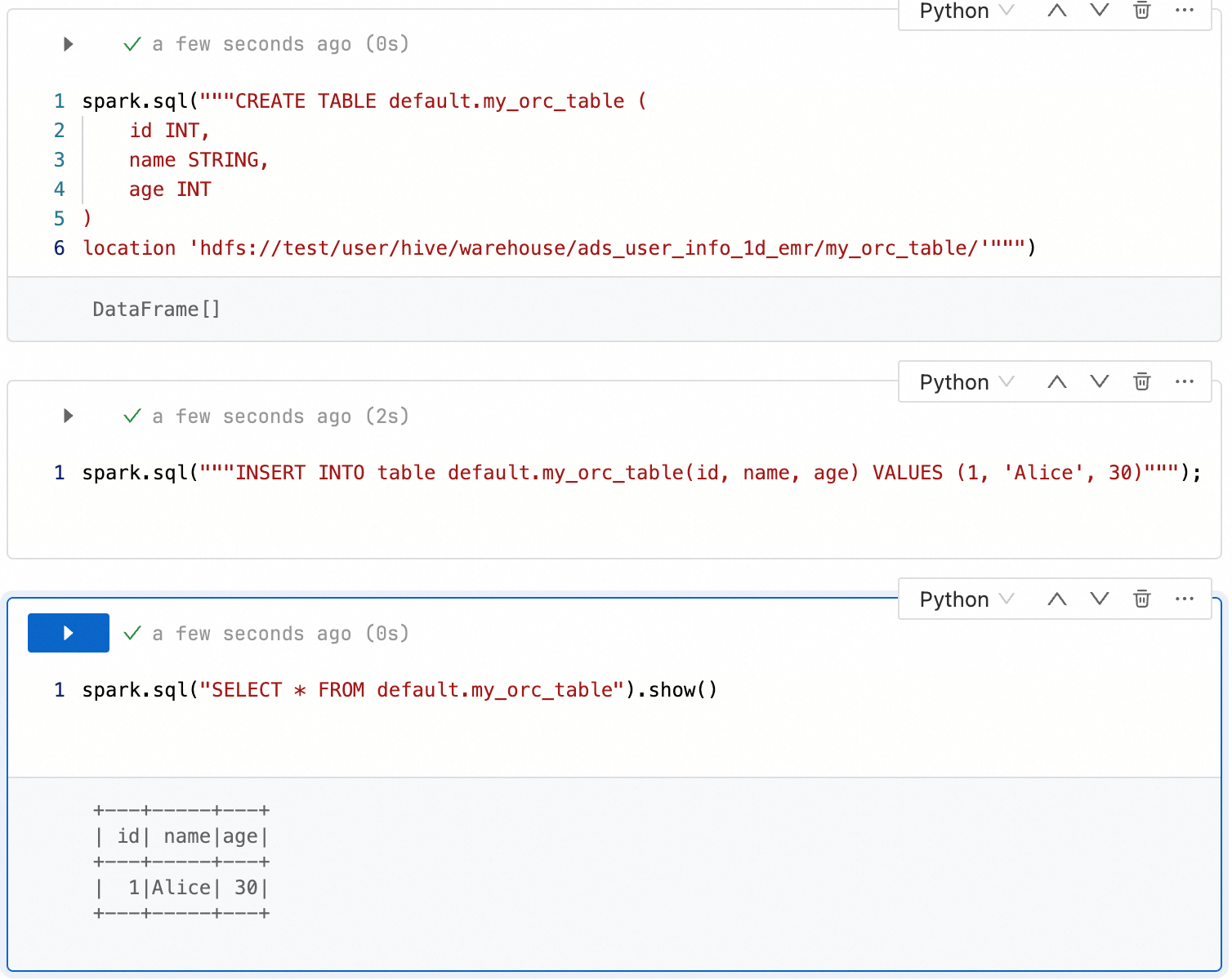
Notebook的!hadoop fs命令暂不支持RootPolicy。
场景二:在SQL会话中使用
配置Spark配置。
在EMR Serverless Spark页面,单击左侧导航栏中的会话管理。
在SQL会话页面,单击创建SQL会话。
在创建SQL会话页面,配置以下Spark 配置。
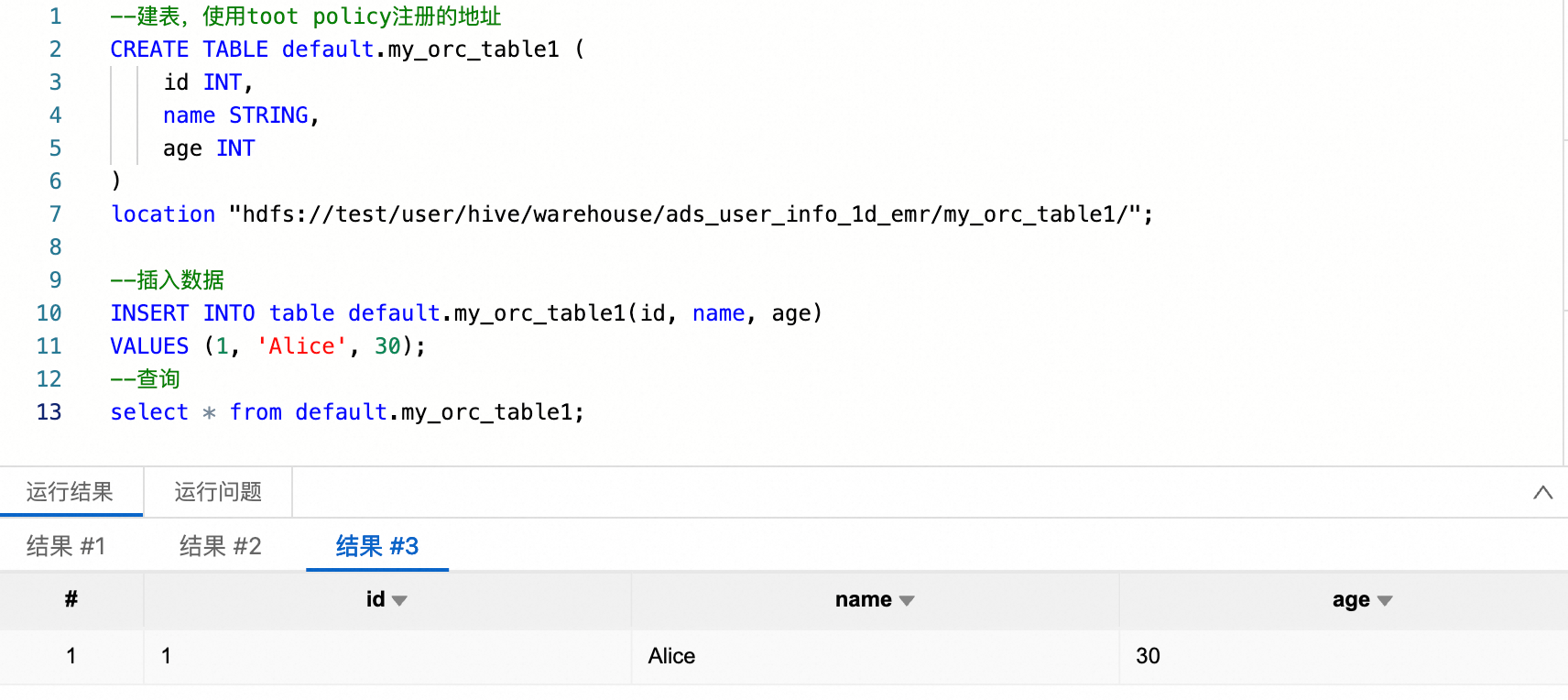
spark.hadoop.fs.accessPolicies.discovery oss://<buckename>.cn-<region>.oss-dls.aliyuncs.com spark.hadoop.fs.AbstractFileSystem.hdfs.impl com.aliyun.jindodata.hdfs.v3.HDFS spark.hadoop.fs.hdfs.impl com.aliyun.jindodata.hdfs.v3.JindoDistributedFileSystem在数据开发SparkSQL任务中直接使用通过RootPolicy为OSS-HDFS服务设置自定义前缀。
--建表 CREATE TABLE default.my_orc_table1 ( id INT, name STRING, age INT ) location "hdfs://<ns_name>/user/hive/warehouse/ads_user_info_1d_emr/my_orc_table1/"; --插入数据 INSERT INTO table default.my_orc_table1(id, name, age) VALUES (1, 'Alice', 30); --查询 select * from default.my_orc_table1;说明建表语句中“<ns_name>”需替换成您访问OSS-HDFS服务的自定义前缀。
场景三:在批任务中使用
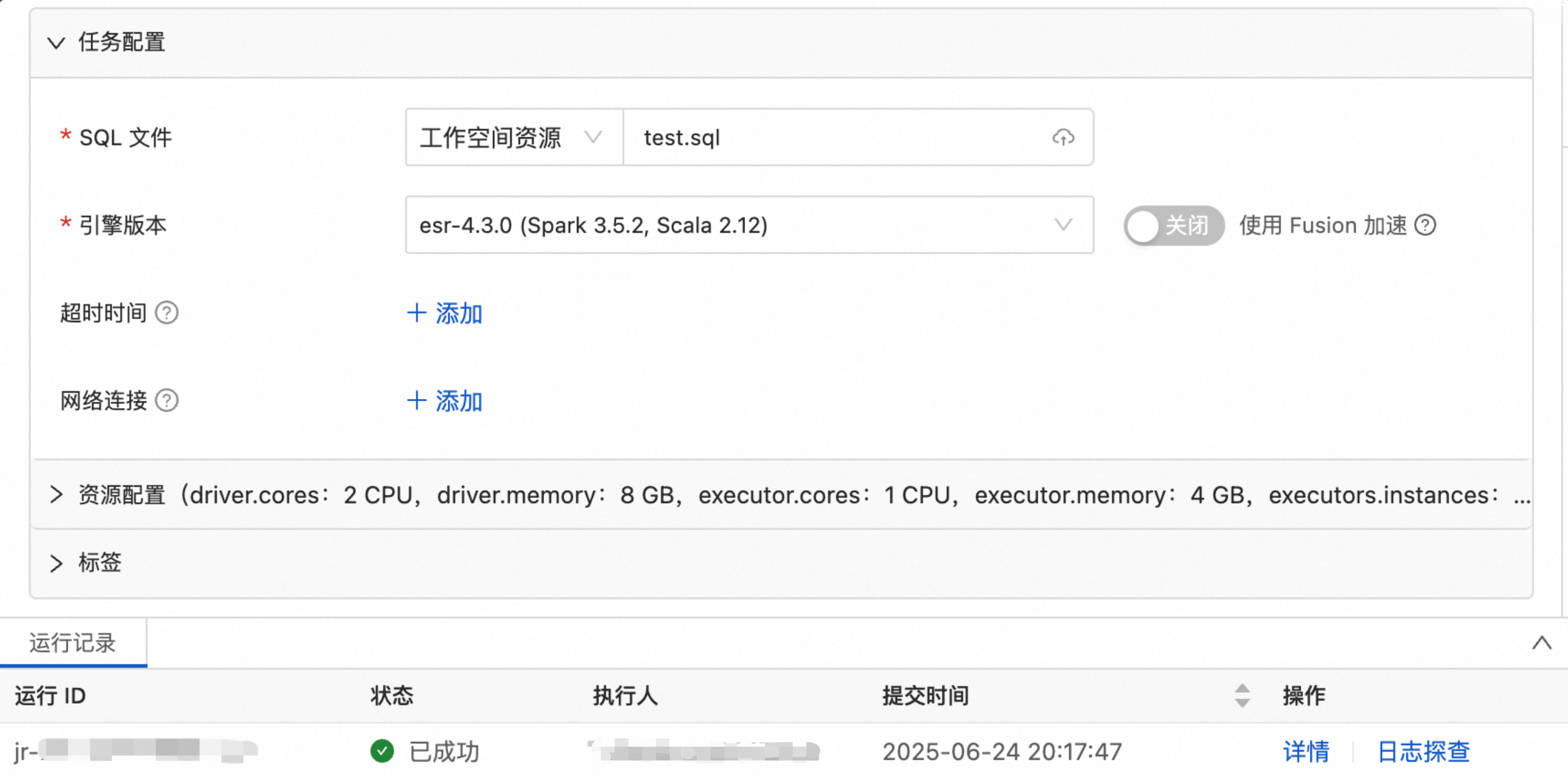
上传文件。本文演示示例SQL文件test.sql。
在EMR Serverless Spark页面,单击左侧导航栏中的文件管理。
在托管文件目录页面,单击上传文件。
在上传文件对话框中,单击待上传文件区域选择本地文件,或者直接拖拽目标文件到待上传文件区域。
配置Spark配置。
在EMR Serverless Spark页面,单击左侧导航栏中的数据开发。
在开发目录页签下,单击
 (新建)图标。
(新建)图标。在弹出的对话框中,输入名称,选择批任务类型下的SQL任务,然后单击确定。
在任务配置页面,配置以下Spark 配置。
spark.hadoop.fs.accessPolicies.discovery oss://<buckename>.cn-<region>.oss-dls.aliyuncs.com spark.hadoop.fs.AbstractFileSystem.hdfs.impl com.aliyun.jindodata.hdfs.v3.HDFS spark.hadoop.fs.hdfs.impl com.aliyun.jindodata.hdfs.v3.JindoDistributedFileSystem
在数据开发页面单击运行,单击运行,结果如下。