
阿里云 EMR Serverless Spark 的 Notebook 会话中引入了 DuckDB 的 Python 库,除了支持 DuckDB 开源版本所具备的所有功能外,还额外提供了免密访问 OSS/OSS-HDFS 的能力,从而能够直接读取 OSS 路径下的文件进行操作。
背景信息
DuckDB 是一款轻量级、高性能的嵌入式分析型数据库引擎,专为 OLAP(联机分析处理)场景优化。
功能特性
嵌入式架构:无需独立服务器,以库的形式直接嵌入应用程序(类似SQLite),支持内存/磁盘模式。
列式存储:数据按列存储,优化聚合查询与扫描性能。
向量化执行:利用SIMD指令并行处理数据批次,减少CPU开销。
标准兼容:支持SQL-92、SQL:2011标准,涵盖CTE、窗口函数、JOIN(包括ASOF JOIN)、子查询等。
多格式直读:直接查询CSV、Parquet、JSON文件,无需导入。
零拷贝集成:与Pandas、Arrow等内存数据结构无缝转换,避免数据迁移开销。
联邦查询:通过
httpfs扩展访问远程文件(如S3),或连接PostgreSQL等外部数据库联合查询。
适用场景
交互式分析:快速处理GB~TB级数据集,替代Pandas/Excel处理大数据。
边缘计算:嵌入式部署在终端设备,执行本地数据分析。
数据科学:与Python/R生态无缝衔接,作为ML数据预处理引擎。
实时OLAP:支持高频更新与复杂查询并存的分析需求。
使用限制
仅以下引擎版本支持本文操作:
esr-4.x:esr-4.4.0及之后版本。
esr-3.x:esr-3.4.0及之后版本。
esr-2.x:esr-2.8.0及之后版本。
使用方法
在EMR Serverless Spark页面,单击左侧的数据开发。
新建Notebook。
在开发目录页签下,单击
 图标。
图标。在弹出的对话框中,输入名称,类型使用,然后单击确定。
在右上角选择已创建并启动的Notebook会话实例。
您也可以在下拉列表中选择创建Notebook会话,新建一个Notebook会话实例。关于Notebook会话更多介绍,请参见管理Notebook会话。
说明由于 DuckDB 是单机 SQL 引擎,仅会使用 Notebook Spark driver 的资源,因此建议增大 Spark driver 的
spark.driver.cores和spark.driver.memory资源配置。在 Notebook 的 Python 代码中,可以直接通过
import duckdb进行使用。以下列举了几种常用的 DuckDB 使用方法。查看 parquet、csv、json 文件的内容。
import duckdb # 查看 parquet 文件的内容 duckdb.sql("SELECT * FROM 'oss://bucket/path/to/test.parquet'") # 查看 csv 文件的内容 duckdb.sql("SELECT * FROM 'oss://bucket/path/to/test.csv'") # 查看 json文件的内容 duckdb.sql("SELECT * FROM 'oss://bucket/path/to/test.json'")
查看 parquet 文件的 schema 信息。
import duckdb # 查看 parquet 文件的 schema 信息 duckdb.sql("SELECT * FROM parquet_schema('oss://bucket/path/to/test.parquet')")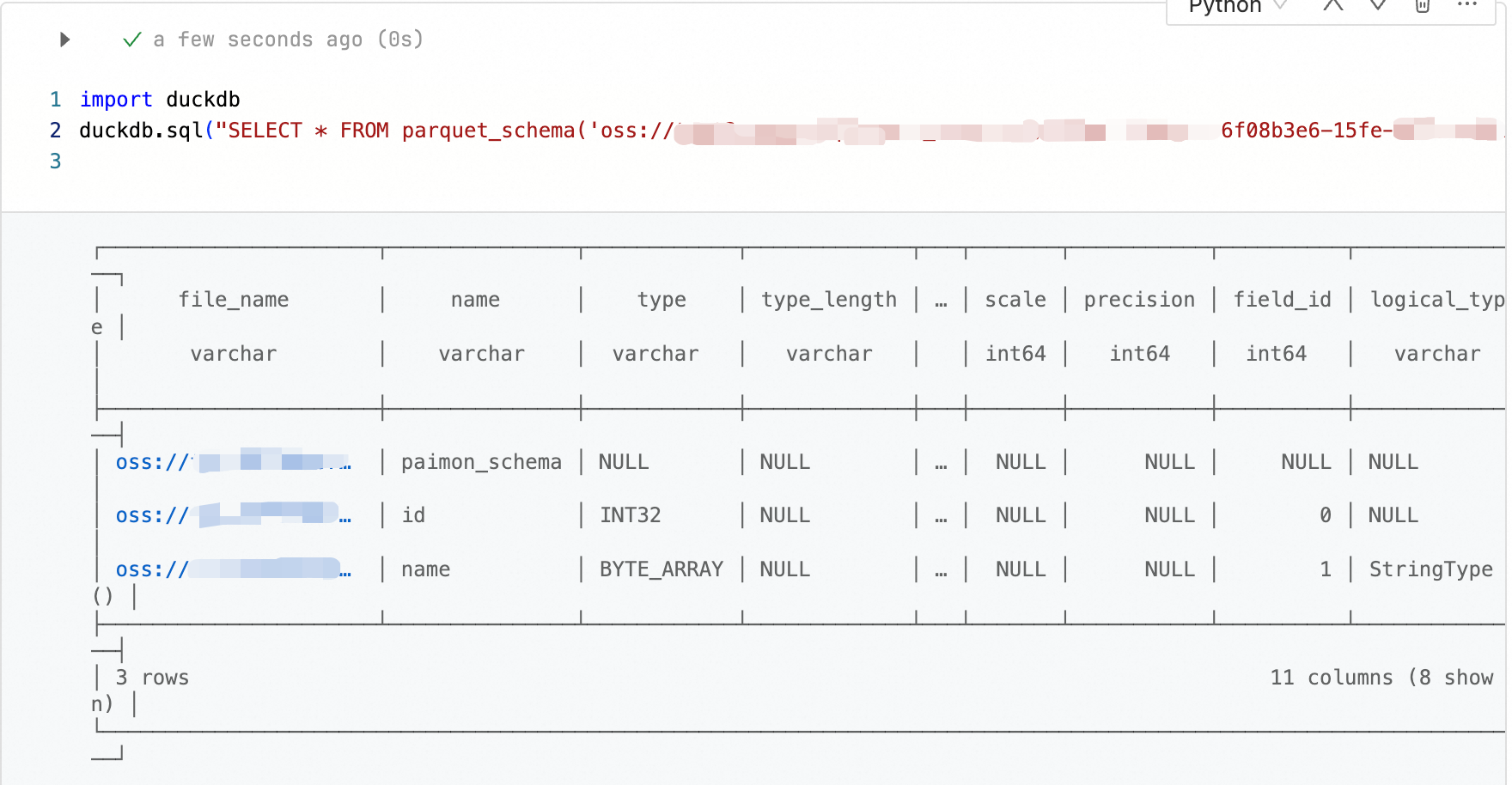
将 parquet 文件的内容导出为 csv 文件。
import duckdb # 将 parquet 文件的内容导出为 csv 文件 duckdb.sql("COPY (SELECT * FROM 'oss://bucket/path/to/test.parquet') TO 'oss://bucket/path/to/output.csv' (HEADER, DELIMITER ',');")
说明在进行OSS文件的读写操作之前,请确保已开通OSS服务,并创建相应的存储空间,同时确认具备对该存储空间的访问权限。
了解更加详细的功能使用,请参考 DuckDB 的官方文档。