
Spark原生支持通过JDBC Connector访问MySQL。Serverless Spark在启动时将自动加载MySQL JDBC驱动(版本 8.0.33)。您可以通过SQL会话、批处理任务或Notebook等方式连接MySQL,从而实现数据的读取与写入操作。
前提条件
已创建Serverless Spark工作空间,详情请参见创建工作空间。
已创建MySQL实例。
您可以选择自建的MySQL实例,或选择阿里云提供的RDS MySQL与PolarDB MySQL数据库。
本文以阿里云的RDS MySQL为例,详情请参见创建RDS MySQL实例与配置数据库。
注意事项
确保Serverless Spark能够与MySQL之间的网络互通。具体配置请参见EMR Serverless Spark与其他VPC间网络互通。
配置安全组规则时,请根据实际需求选择性开放必要的端口范围(1~65535)。本文示例需开启TCP 3306端口。
操作步骤
方式一:使用SQL会话
创建SQL会话。 在会话管理中创建SQL会话,并选择预先配置的网络连接。具体配置请参见创建SQL会话。
创建SQL任务。 在数据开发中创建SparkSQL类型的任务,使用以下SQL进行测试。
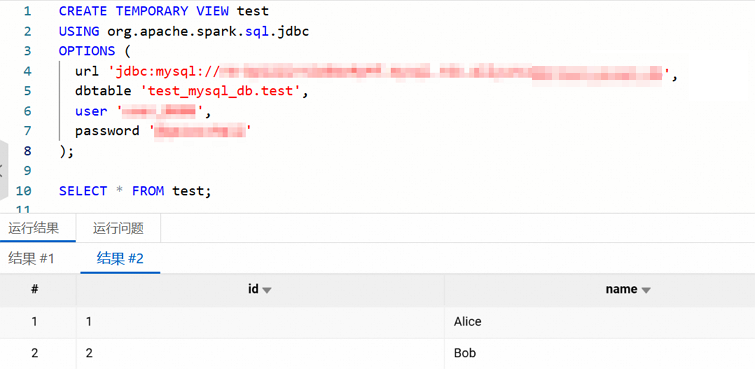
CREATE TEMPORARY VIEW test USING org.apache.spark.sql.jdbc OPTIONS ( url 'jdbc:mysql://<jdbc_url>/', dbtable '<db>.<table>', user '<username>', password '<password>' ); SELECT * FROM test;涉及参数说明如下所示。
参数
说明
urlJDBC连接字符串。填写格式为
jdbc:mysql://<jdbc_url>/,需替换<jdbc_url>为实际值。dbtable待读取的数据库表名,格式为
<db>.<table>。本文示例为test_mysql_db.test。userMySQL数据库用户名。
说明需具备目标表的读取权限。
passwordMySQL数据库密码。
如果能够正确输出表的内容,则说明连接成功。
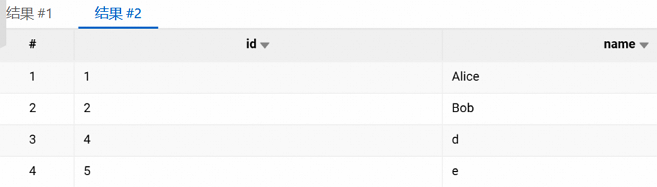
插入数据。 请使用以下命令向MySQL表中插入数据。
INSERT INTO test VALUES(4, 'd'),(5, 'e'); SELECT * FROM test;如果能正确查询到插入的数据,说明写入功能正常。
方式二:使用Notebook会话
创建Notebook会话。 在会话管理中创建Notebook会话,并选择预先配置的网络连接。具体配置请参见创建Notebook会话。
创建Notebook任务。 在数据开发中创建类型的任务,使用以下Python代码进行测试。
df = spark.read \ .format("jdbc") \ .option("url", "jdbc:mysql://<jdbc_url>") \ .option("dbtable", "<db>.<table>") \ .option("user", "<username>") \ .option("password", "<password>") \ .load() df.show()如果能够正确输出表的内容,说明连接成功。

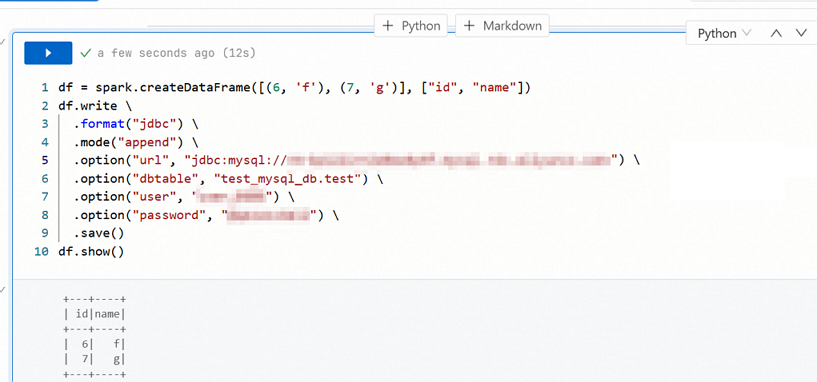
插入数据。 请使用以下代码向MySQL表中插入数据。
df = spark.createDataFrame([(6, 'f'), (7, 'g')], ["id", "name"]) df.write \ .format("jdbc") \ .mode("append") \ .option("url", "jdbc:mysql://<jdbc_url>") \ .option("dbtable", "<db>.<table>") \ .option("user", "<username>") \ .option("password", "<password>") \ .save() df.show()涉及参数
mode("append"),该参数指定写入模式为追加模式,确保新数据被追加至目标表中,而不会覆盖或删除已存数据。如果能正确返回插入的数据,说明写入功能正常。
方式三:使用Spark批任务
编写测试代码。 使用以下Scala代码编译并打包为JAR文件。
package spark.test import org.apache.spark.sql.SparkSession object Main { def main(args: Array[String]): Unit = { val spark = SparkSession.builder() .appName("test") .getOrCreate() val newRows = spark.createDataFrame(Seq((6, "f"), (7, "g"))).toDF("id", "name") newRows.write.format("jdbc") .mode("append") .option("url", "jdbc:mysql://<jdbc_url>") .option("dbtable", "<db>.<table>") .option("user", "<username>") .option("password", "<password>") .save() spark.read.format("jdbc") .option("url", "jdbc:mysql://<jdbc_url>") .option("dbtable", "<db>.<table>") .option("user", "<username>") .option("password", "<password>") .load() .show() spark.stop() } }创建批任务。 在数据开发中创建类型的任务,然后配置以下参数进行测试。具体配置请参见批任务或流任务开发。
主jar资源:选择或者填写打包好的JAR文件地址。
Main Class:
spark.test.Main。网络连接:选择预先配置的网络连接。
查看验证结果。 任务执行后,您可以单击下方运行记录区域中的日志探查,在Driver日志的Stdout页签,查看到MySQL对应库表中的内容。