
Power BI是一个统一、可扩展的自助服务和企业商业智能( BI)平台,支持用户对数据进行建模与可视化分析,并能够创建个性化的报表。本文介绍如何通过Power BI连接EMR Serverless Spark并可视化分析数据。
使用限制
不支持访问Paimon和Iceberg的数据目录或表。
前提条件
下载并安装Power BI。下载地址请参见Microsoft Power BI。
已创建Spark Thrift Server会话及其Token,详情请参见创建Spark Thrift Server会话和管理Spark Thrift Server会话。
(可选)准备测试数据
本文以user_behavior表为例进行说明。如您已拥有相关测试数据,则可跳过此步骤。
单击user.csv下载测试数据,并上传至阿里云OSS。
例如,本文上传的路径为
oss://emr-oss-hdfs/spark/user_behavior/user.csv,上传文件具体操作,请参见上传文件。创建SQL会话。
进入会话管理页面。
在左侧导航栏,选择。
在Spark页面,单击目标工作空间名称。
在EMR Serverless Spark页面,单击左侧导航栏中的会话管理。
在SQL 会话页面,单击创建 SQL 会话。
在创建 SQL 会话页面,单击创建。
更多参数详情,请参见管理SQL会话。
创建SQL开发。
在EMR Serverless Spark页面,单击左侧导航栏中的数据开发。
在开发目录页签下,单击
 图标。
图标。在新建对话框中,输入名称(例如user_behavior),类型使用默认的SparkSQL,然后单击确定。
拷贝如下代码到新增的SparkSQL页签(user_behavior)中。
CREATE TABLE user_behavior ( user_id INT, item_id INT, behavior_type INT, user_geohash STRING, item_category INT, time STRING )USING CSV Location 'oss://emr-oss-hdfs/spark/user_behavior'; SELECT * FROM user_behavior limit 1000;选择一个数据库(例如default),并选择在前面步骤中已启动的SQL会话实例。
单击运行,执行创建的任务。

使用Power BI连接EMR Serverless Spark
请根据您的使用习惯选择合适的方式。如果选择使用ODBC方式,则需安装并配置ODBC。
ODBC方式
下载并安装Microsoft Spark ODBC Driver。下载地址请参见Microsoft Spark ODBC Driver。
配置ODBC驱动。
打开ODBC数据源,在用户 DSN页签,单击添加。
在创建新数据源对话框中,选择Microsoft Spark ODBC Driver,单击完成。
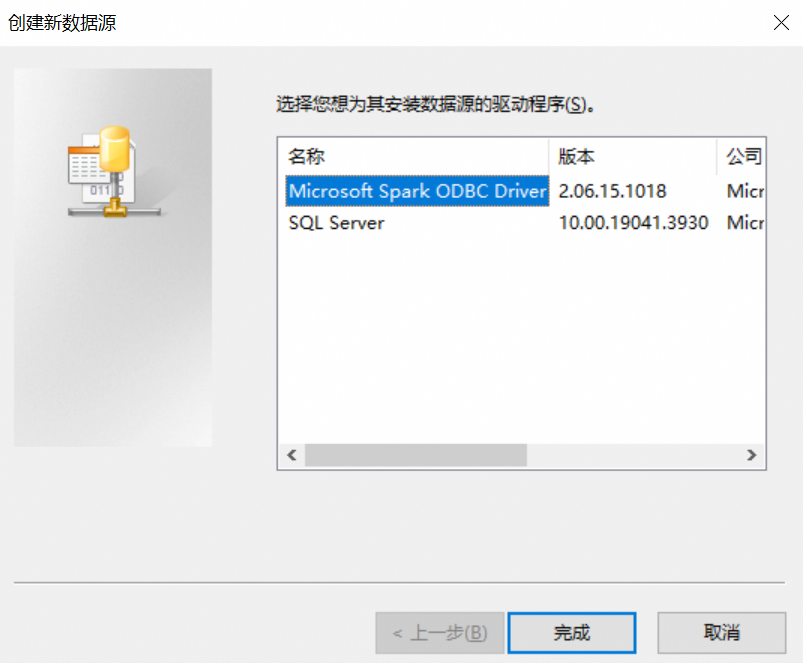
在Microsoft Spark ODBC Driver DSN Setup对话框中,输入以下信息,其余参数可以使用默认设置。
参数
说明
Date Source Name
数据源名称。例如,serverless_spark_test。
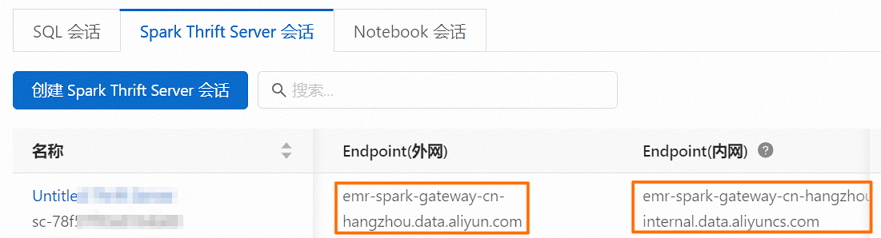
Host(s)
您创建的Spark Thrift Server会话的Endpoint(外网)或Endpoint(内网)信息。
Mechanism
鉴权方式。选择User Name and Password。
User Name
Token管理页签的Token名称。
Password
Token管理页签的Token信息。
单击HTTP Options,在HTTP Path中输入
/cliservice,然后单击OK。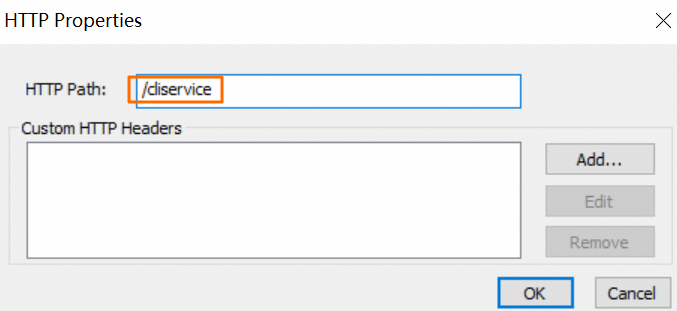
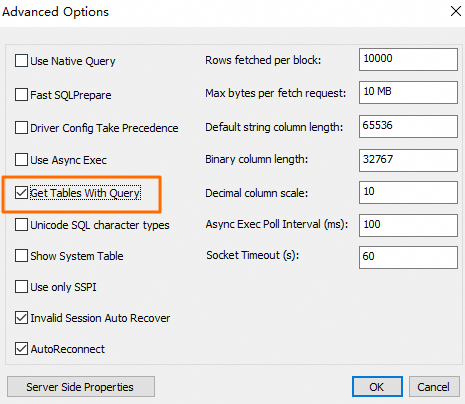
(可选)单击Advanced Options,在弹出的对话框中勾选Get Tables With Query,然后单击OK。
说明如果默认Catalog中存在Paimon表或Iceberg表,则建议配置。
在Microsoft Spark ODBC Driver DSN Setup对话框中,单击Test,测试连接性。
如果返回信息中包含
SUCCESS,则表示ODBC连接Serverless Spark Thrift Server成功。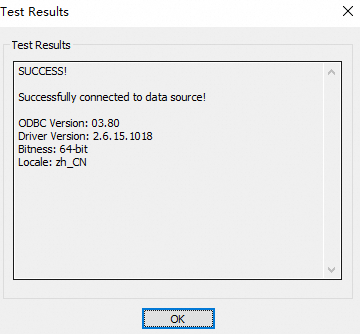
在Microsoft Spark ODBC Driver DSN Setup对话框中,单击OK,保存DSN配置。
连接EMR Serverless Spark。
打开Power BI Desktop,在主页页签,单击从其他源获取数据 。
在获取数据页面的全部选项中,搜索并选择ODBC,然后单击连接。
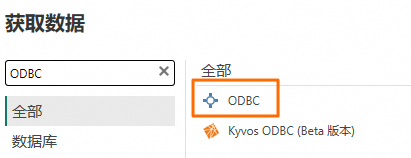
选择刚才保存的数据源名称(serverless_spark_test),然后单击确定。

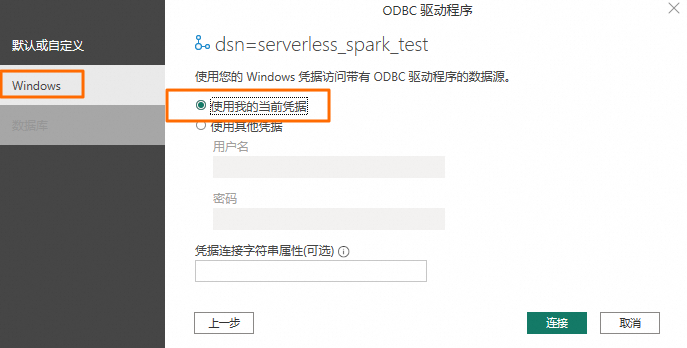
在弹出的对话框的Windows页签,选择使用我的当前凭据,然后单击连接。
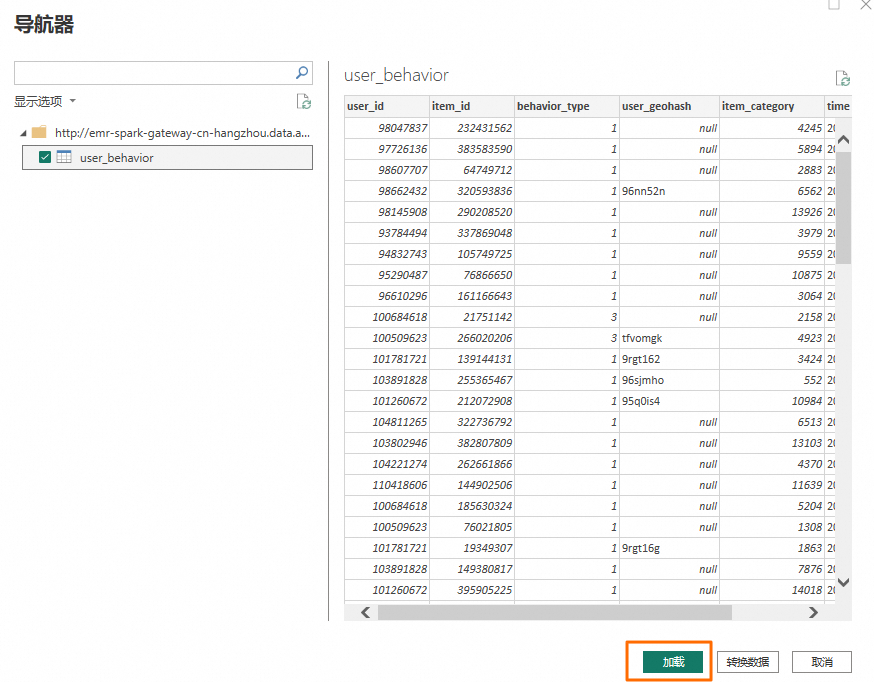
在导航器对话框中,选择需要导入的表,并单击加载。
Spark方式
打开Power BI Desktop,在主页页签,单击从其他源获取数据 。
在获取数据页面的全部选项中,搜索并选择Spark,然后单击连接。
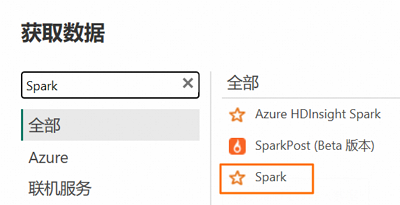
在弹出的对话框中配置连接信息,然后单击确定。
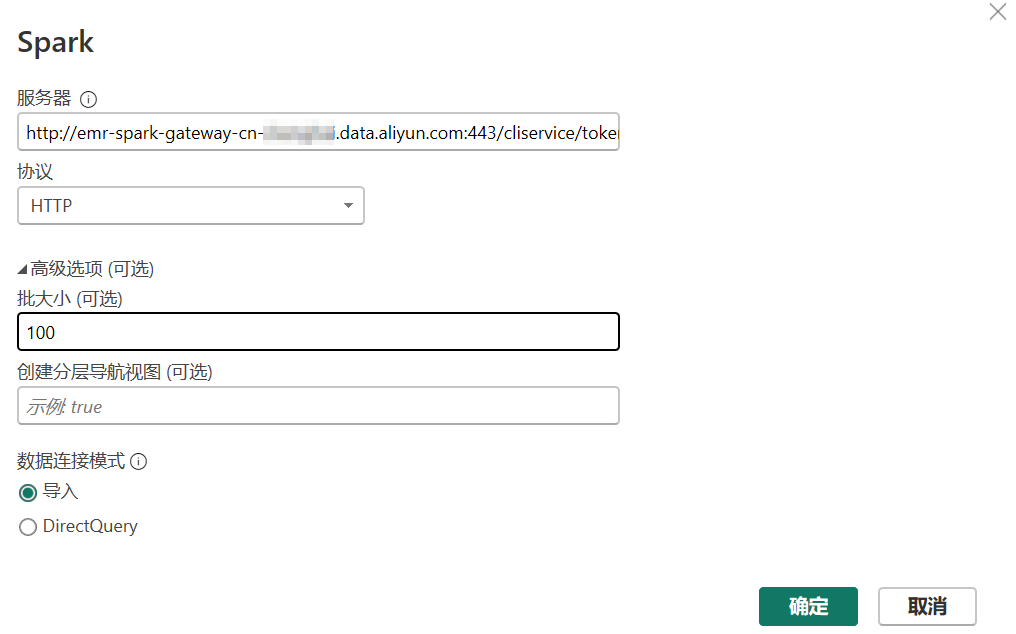 在连接Spark Thrift Server时,请根据您的实际情况替换以下信息。
在连接Spark Thrift Server时,请根据您的实际情况替换以下信息。参数
描述
服务器
填写格式为
http//<endpoint>:<port>/cliservice/token/<token>。其中:<endpoint>:您创建的Spark Thrift Server会话的Endpoint(外网)或Endpoint(内网)信息。<port>:端口号。使用外网域名访问时端口号为443,使用内网域名访问时端口号为80。<token>:Token管理页签的Token信息。
协议
选择HTTP。
数据连接模式
取值说明:
导入:将数据复制到Power BI中。
DirectQuery:从其连接的数据源动态请求数据。
说明在以下情况下,更适合使用DirectQuery。
数据源中包含大量数据。
需要使用“准实时”数据。
高级选项
此处示例无需配置,保持默认值即可。您也可以根据实际业务需求进行精细化配置。
在弹出的对话框中配置用户名和密码,然后单击连接。
参数
描述
用户名
Token管理页签的Token名称。
密码
Token管理页签的Token信息。
在导航器对话框中,选择需要导入的表,并单击加载。
使用Power BI进行可视化分析
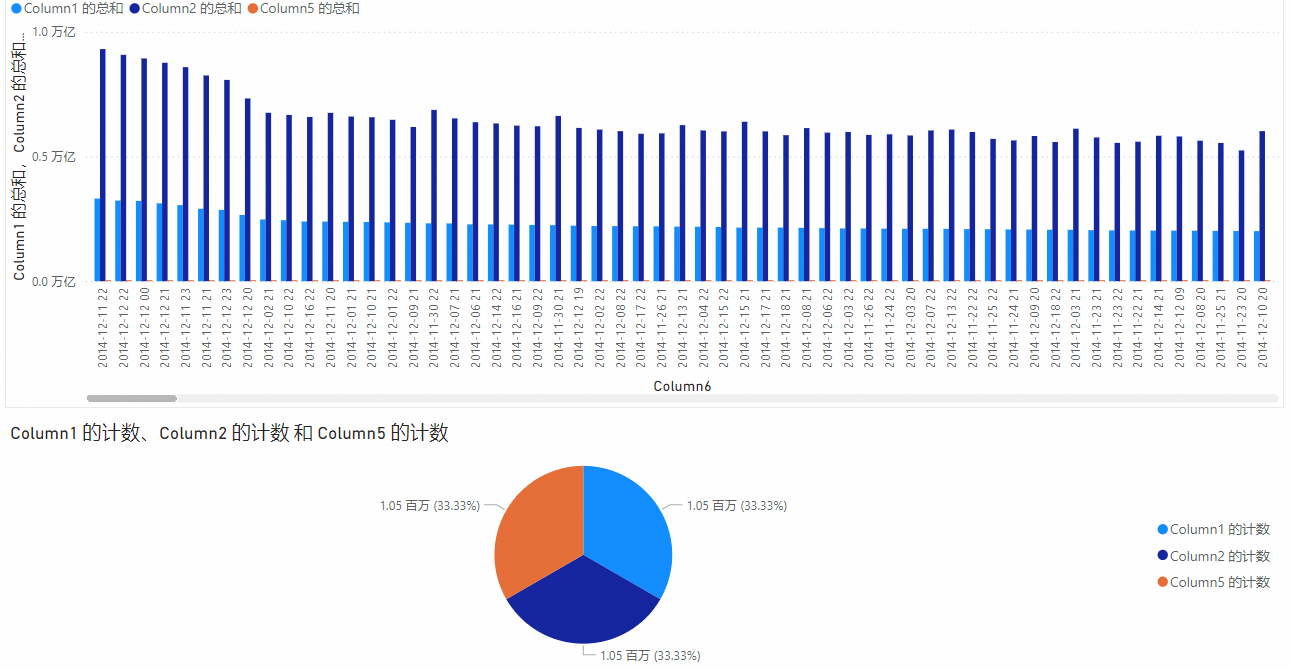
在报表视图页签的可视化窗格中,选择所需图形。
在数据窗格中选择表中的列。本文所示示例的可视化效果应如下图所示。
(可选)单击左上角
 图标保存报表。
图标保存报表。