
Spark Thrift Server是Apache Spark提供的一种服务,支持通过JDBC或ODBC连接并执行SQL查询,从而便捷地将Spark环境与现有的商业智能(BI)工具、数据可视化工具及其他数据分析工具集成。本文主要为您介绍如何创建并连接Spark Thrift Server。
前提条件
已创建工作空间,详情请参见管理工作空间。
创建Spark Thrift Server会话
Spark Thrift Server创建完成后,您可以在创建Spark SQL类型任务时选择此会话。
进入会话管理页面。
在左侧导航栏,选择。
在Spark页面,单击目标工作空间名称。
在EMR Serverless Spark页面,单击左侧导航栏中的会话管理。
在会话管理页面,单击Spark Thrift Server会话页签。
单击创建Spark Thrift Server会话。
在创建Spark Thrift Server会话页面,配置以下信息,单击创建。
参数
说明
名称
新建Spark Thrift Server的名称。
长度限制为1~64个字符,仅支持字母、数字、短划线(-)、下划线(_)和空格。
部署队列
请选择合适的开发队列部署会话。仅支持选择开发或者开发和生产共用的队列。
队列更多信息,请参见管理资源队列。
引擎版本
当前会话使用的引擎版本。引擎版本号含义等详情请参见引擎版本介绍。
使用Fusion加速
Fusion可加速Spark负载的运行并降低任务的总成本。有关计费信息,请参见产品计费。有关Fusion引擎介绍,请参见Fusion引擎。
自动停止
默认开启。45分钟不活动后自动停止Spark Thrift Server会话。
网络连接
选择已创建的网络连接,以便直接访问VPC内的数据源或外部服务。有关创建网络连接的具体操作,请参见EMR Serverless Spark与其他VPC间网络互通。
Spark Thrift Server端口
使用外网域名访问时端口号为443,使用内网域名访问时端口号为80。
访问凭证
仅支持Token方式。
spark.driver.cores
用于指定Spark应用程序中Driver进程所使用的CPU核心数量。默认值为1 CPU。
spark.driver.memory
用于指定Spark应用程序中Driver进程可以使用的内存量。默认值为3.5 GB。
spark.executor.cores
用于指定每个Executor进程可以使用的CPU核心数量。默认值为1 CPU。
spark.executor.memory
用于指定每个Executor进程可以使用的内存量。默认值为3.5 GB。
spark.executor.instances
Spark分配的执行器(Executor)数量。默认值为2。
动态资源分配
默认关闭。开启后,需要配置以下参数:
executors数量下限:默认为2。
executors数量上限:如果未设置spark.executor.instances,则默认值为10。
更多内存配置
spark.driver.memoryOverhead:每个Driver可利用的非堆内存。如果未设置该参数,Spark会根据默认值自动分配,默认值为
max(384MB, 10% × spark.driver.memory)。spark.executor.memoryOverhead:每个Executor可利用的非堆内存。如果未设置该参数,Spark会根据默认值自动分配,默认值为
max(384MB, 10% × spark.executor.memory)。spark.memory.offHeap.size:Spark可用的堆外内存大小。默认值为1 GB。
仅在
spark.memory.offHeap.enabled设置为true时生效。默认情况下,当采用Fusion Engine时,该功能将处于启用状态,其非堆内存默认设置为1 GB。
Spark配置
填写Spark配置信息,默认以空格符分隔,例如,
spark.sql.catalog.paimon.metastore dlf。获取Endpoint信息。
在Spark Thrift Server会话页签,单击新增的Spark Thrift Server的名称。
在总览页签,复制Endpoint信息。
根据网络环境的不同,可以选择以下两种Endpoint:
外网Endpoint:适用于通过公网访问EMR Serverless Spark的场景,例如本地开发机、外部网络或跨云环境的访问。此方式可能会产生流量费用,请确保采取必要的安全措施。
内网Endpoint:适用于同地域的阿里云ECS实例通过内网访问EMR Serverless Spark的场景。内网访问免费且更加安全,但仅限同一地域的阿里云内网环境使用。
创建Token
在Spark Thrift Server会话页签,单击新增的Spark Thrift Server会话的名称。
单击Token管理页签。
单击创建Token。
在创建Token对话框中,配置以下信息,单击确定。
参数
说明
名称
新建Token的名称。
过期时间
设置该Token的过期时间。设置的天数应大于或等于1。默认情况下为开启状态,365天后过期。
复制Token信息。
重要Token创建完成后,请务必立即复制新Token的信息,后续不支持查看。如果您的Token过期或遗失,请选择新建Token或重置Token。
连接Spark Thrift Server
在连接Spark Thrift Server时,请根据您的实际情况替换以下信息:
<endpoint>:您在总览页签获取的Endpoint(外网)或Endpoint(内网)信息。如果使用内网Endpoint,访问Spark Thrift Server限于同一VPC内的资源。
<port>:端口号。使用外网域名访问时端口号为443,使用内网域名访问时端口号为80。<username>:您在Token管理页签新建的Token的名称。<token>:您在Token管理页签复制的Token信息。
使用Python连接Spark Thrift Server
执行以下命令,安装PyHive和Thrift包。
pip install pyhive thrift编写Python脚本,连接Spark Thrift Server。
以下是一个Python脚本示例,展示如何连接到Hive并显示数据库列表。根据网络环境的不同(外网或内网),您可以选择适合的连接方式。
使用外网域名连接
from pyhive import hive if __name__ == '__main__': # 替换<endpoint>、<username>和<token>为您的实际信息。 cursor = hive.connect('<endpoint>', port=443, scheme='https', username='<username>', password='<token>').cursor() cursor.execute('show databases') print(cursor.fetchall()) cursor.close()使用内网域名连接
from pyhive import hive if __name__ == '__main__': # 替换<endpoint>、<username>和<token>为您的实际信息。 cursor = hive.connect('<endpoint>', port=80, scheme='http', username='<username>', password='<token>').cursor() cursor.execute('show databases') print(cursor.fetchall()) cursor.close()
使用Java连接Spark Thrift Server
请在您的
pom.xml中引入以下Maven依赖。<dependencies> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>3.0.0</version> </dependency> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-jdbc</artifactId> <version>2.1.0</version> </dependency> </dependencies>说明当前Serverless Spark内置的Hive版本为2.x,因此仅支持hive-jdbc 2.x版本。
编写Java代码,连接Spark Thrift Server。
以下是一个Sample Java代码,用于连接到Spark Thrift Server,并查询数据库列表。
使用外网域名连接
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import org.apache.hive.jdbc.HiveStatement; public class Main { public static void main(String[] args) throws Exception { String url = "jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>"; Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection conn = DriverManager.getConnection(url); HiveStatement stmt = (HiveStatement) conn.createStatement(); String sql = "show databases"; System.out.println("Running " + sql); ResultSet res = stmt.executeQuery(sql); ResultSetMetaData md = res.getMetaData(); String[] columns = new String[md.getColumnCount()]; for (int i = 0; i < columns.length; i++) { columns[i] = md.getColumnName(i + 1); } while (res.next()) { System.out.print("Row " + res.getRow() + "=["); for (int i = 0; i < columns.length; i++) { if (i != 0) { System.out.print(", "); } System.out.print(columns[i] + "='" + res.getObject(i + 1) + "'"); } System.out.println(")]"); } conn.close(); } }使用内网域名连接
import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.ResultSetMetaData; import org.apache.hive.jdbc.HiveStatement; public class Main { public static void main(String[] args) throws Exception { String url = "jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>"; Class.forName("org.apache.hive.jdbc.HiveDriver"); Connection conn = DriverManager.getConnection(url); HiveStatement stmt = (HiveStatement) conn.createStatement(); String sql = "show databases"; System.out.println("Running " + sql); ResultSet res = stmt.executeQuery(sql); ResultSetMetaData md = res.getMetaData(); String[] columns = new String[md.getColumnCount()]; for (int i = 0; i < columns.length; i++) { columns[i] = md.getColumnName(i + 1); } while (res.next()) { System.out.print("Row " + res.getRow() + "=["); for (int i = 0; i < columns.length; i++) { if (i != 0) { System.out.print(", "); } System.out.print(columns[i] + "='" + res.getObject(i + 1) + "'"); } System.out.println(")]"); } conn.close(); } }
通过Spark Beeline连接Spark Thrift Server
如果您使用的是自建集群,需先进入Spark的
bin目录,然后使用beeline连接Spark Thrift Server。使用外网域名连接
cd /opt/apps/SPARK3/spark-3.4.2-hadoop3.2-1.0.3/bin/ ./beeline -u "jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>"使用内网域名连接
cd /opt/apps/SPARK3/spark-3.4.2-hadoop3.2-1.0.3/bin/ ./beeline -u "jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>"说明代码中的
/opt/apps/SPARK3/spark-3.4.2-hadoop3.2-1.0.3是以EMR on ECS 集群的Spark安装路径为例,实际应根据客户端的Spark安装路径进行相应调整。如果您不确定Spark的安装路径,可以通过env | grep SPARK_HOME命令查找。如果您使用的是EMR on ECS 集群,可以直接使用Spark Beeline客户端连接到Spark Thrift Server。
使用外网域名连接
spark-beeline -u "jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>"使用内网域名连接
spark-beeline -u "jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>"
在使用Hive Beeline连接Serverless Spark Thrift Server时,如果出现以下报错,通常是由于Hive Beeline的版本与Spark Thrift Server不兼容导致。因此,建议使用Hive 2.x版本的Beeline。
24/08/22 15:09:11 [main]: ERROR jdbc.HiveConnection: Error opening session
org.apache.thrift.transport.TTransportException: HTTP Response code: 404配置Apache Superset以连接Spark Thrift Server
Apache Superset是一个现代数据探索和可视化平台,具有丰富的从简单的折线图到高度详细的地理空间图表的图表形态。更多Superset信息,请参见Superset。
安装依赖。
请确保您已经安装了0.20.0版本的
thrift包。如未安装,您可以使用以下命令安装。pip install thrift==0.20.0启动Superset,进入Superset界面。
更多启动操作信息,请参见Superset文档。
在页面右上角单击DATABASE,进入Connect a database页面。
在Connect a database页面,选择Apache Spark SQL。
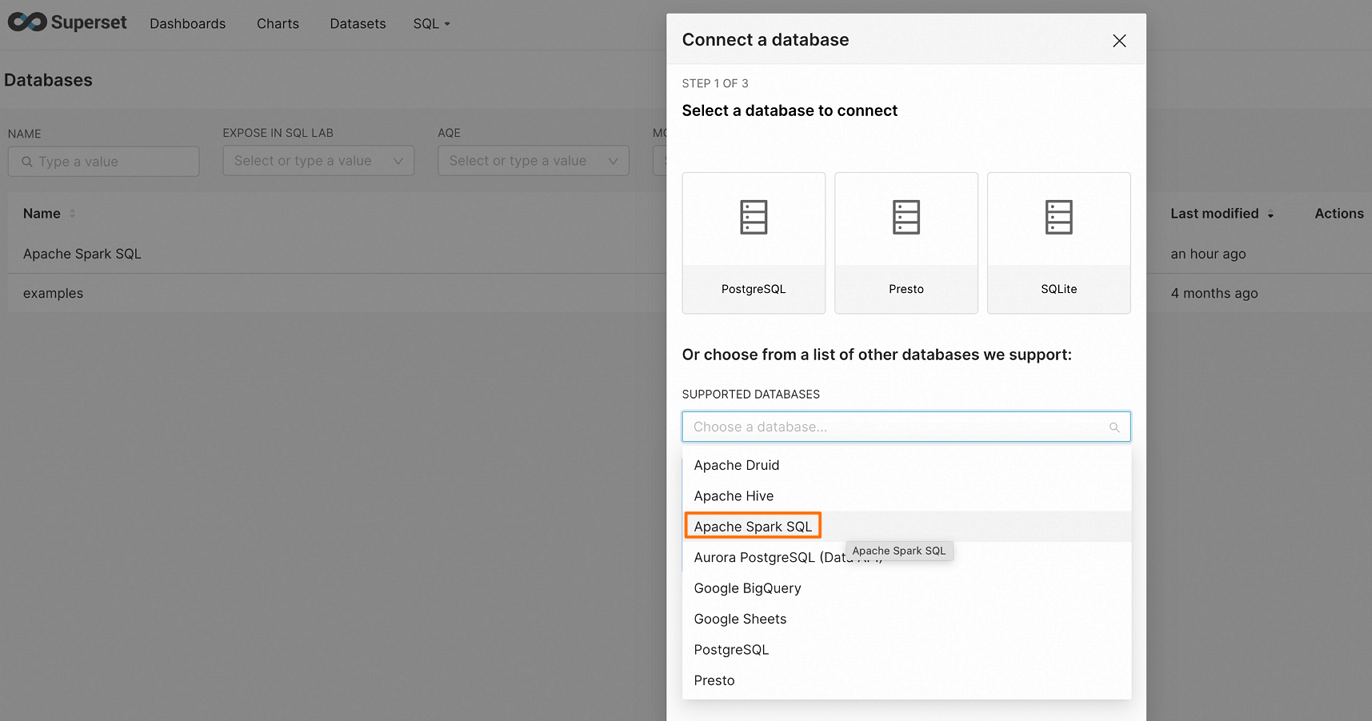
填写连接字符串,然后配置相关数据源参数。
使用外网域名连接
hive+https://<username>:<token>@<endpoint>:443/<db_name>使用内网域名连接
hive+http://<username>:<token>@<endpoint>:80/<db_name>单击FINISH,以确认成功连接和验证。
配置Hue以连接Spark Thrift Server
Hue是一个流行的开源Web界面,可用于与Hadoop生态系统进行交互。关于Hue的更多介绍,请参见Hue官方文档。
安装依赖。
请确保您已经安装了0.20.0版本的
thrift包。如未安装,您可以使用以下命令安装。pip install thrift==0.20.0在Hue的配置文件中添加Spark SQL连接串。
请找到Hue的配置文件(通常位于
/etc/hue/hue.conf),并在文件中添加以下内容。使用外网域名连接
[[[sparksql]]] name = Spark Sql interface=sqlalchemy options='{"url": "hive+https://<username>:<token>@<endpoint>:443/"}'使用内网域名连接
[[[sparksql]]] name = Spark Sql interface=sqlalchemy options='{"url": "hive+http://<username>:<token>@<endpoint>:80/"}'重启Hue。
修改配置后,您需要执行以下命令重启Hue服务以使更改生效。
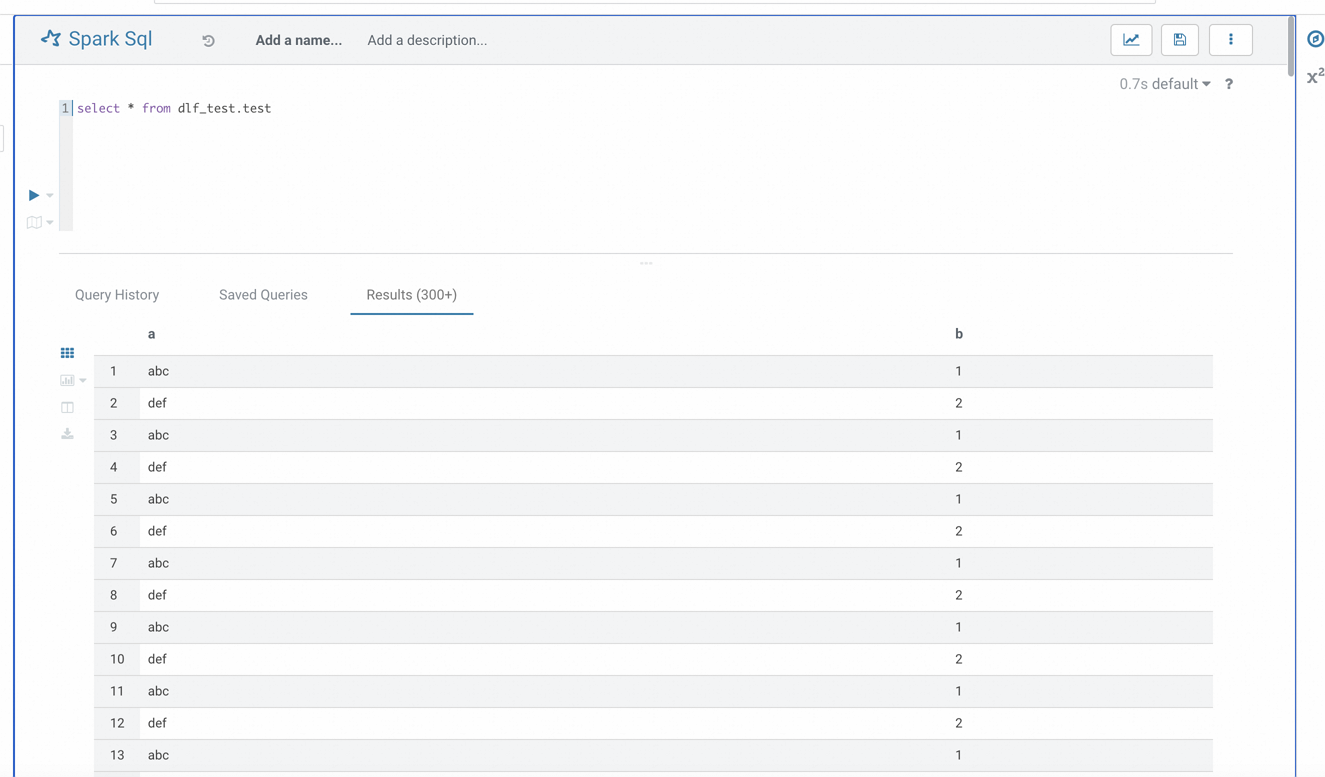
sudo service hue restart验证连接。
成功重启后,访问Hue界面,找到Spark SQL选项。如果配置正确,您应能够成功连接到Spark Thrift Server并执行SQL查询。
使用DataGrip连接Spark Thrift Server
DataGrip是面向开发人员的数据库管理环境,旨在便捷地进行数据库的查询、创建和管理。数据库可运行于本地、服务器或云端。如需了解更多关于DataGrip的信息,请参见DataGrip。
安装DataGrip,详情请参见Install DataGrip。
本文示例中的DataGrip版本为2025.1.2。
打开DataGrip客户端,进入DataGrip界面。
创建项目。
单击
 ,选择。
,选择。
在New Project对话框中,输入项目名,例如
Spark,单击OK。
单击Database Explorer菜单栏的
 图标。选择。
图标。选择。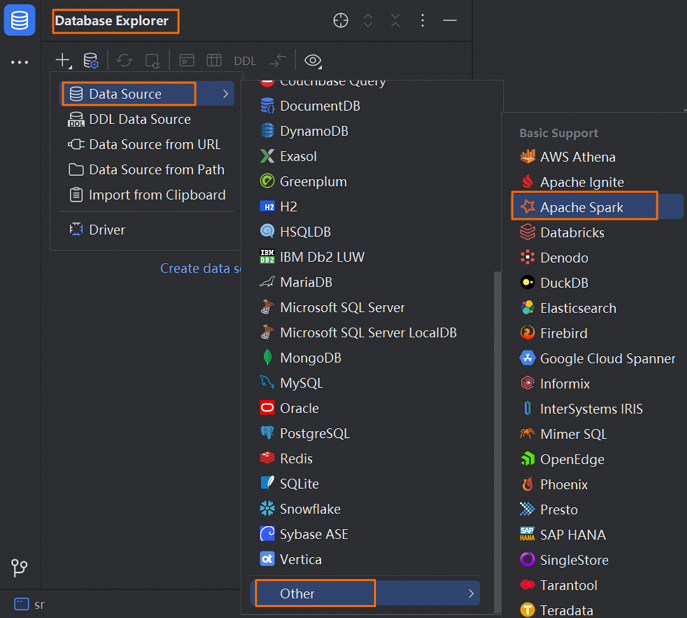
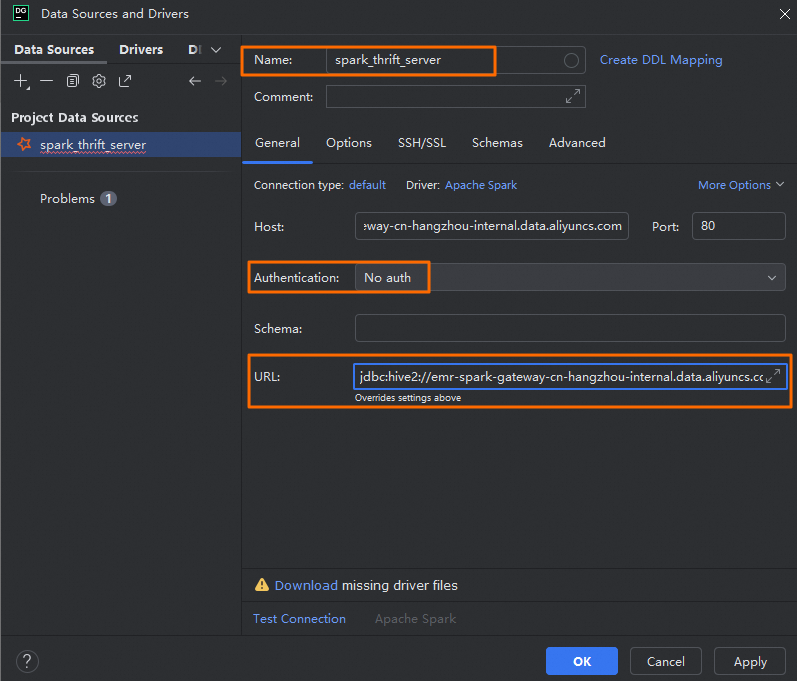
在Data Sources and Drivers对话框,配置如下参数。
页签
参数
说明
General
Name
自定义的连接名称。例如,spark_thrift_server。
Authentication
选择鉴权方式。本文选择的No auth。
在生产环境中,请选择User & Password,确保只有授权用户能够提交SQL任务,提高系统的安全性。
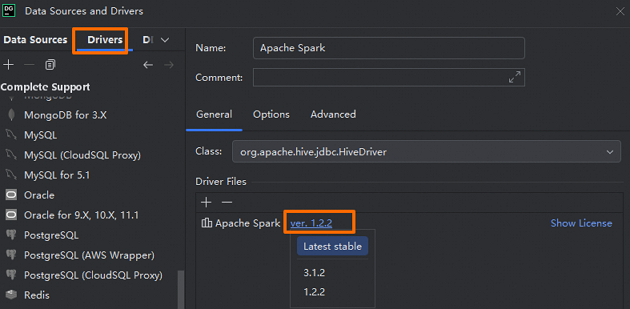
Driver
单击Apache Spark,然后单击Go to Driver ,确认Driver版本为
ver. 1.2.2。说明由于当前Serverless Spark引擎的版本为3.x,为确保系统的稳定性和功能的兼容性,Driver版本必须选择1.2.2。
URL
连接Spark Thrift Server的URL。根据网络环境的不同(外网或内网),您可以选择适合的连接方式。
使用外网域名连接
jdbc:hive2://<endpoint>:443/;transportMode=http;httpPath=cliservice/token/<token>使用内网域名连接
jdbc:hive2://<endpoint>:80/;transportMode=http;httpPath=cliservice/token/<token>
Options
Run keep-alive query
该参数为可选配置。勾选该参数可防止超时自动断开。
单击Test Connection,确认数据源配置成功。
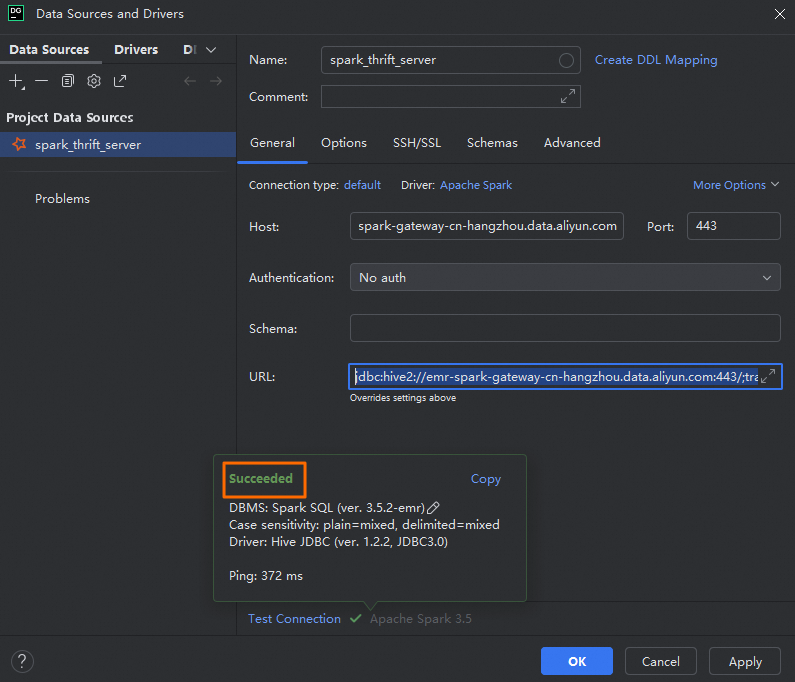
单击OK,完成配置。
使用DataGrip管理Spark Thrift Server。
DataGrip成功连接Spark Thrift Server后,您可以进行数据开发,更多信息请参见DataGrip帮助文档。
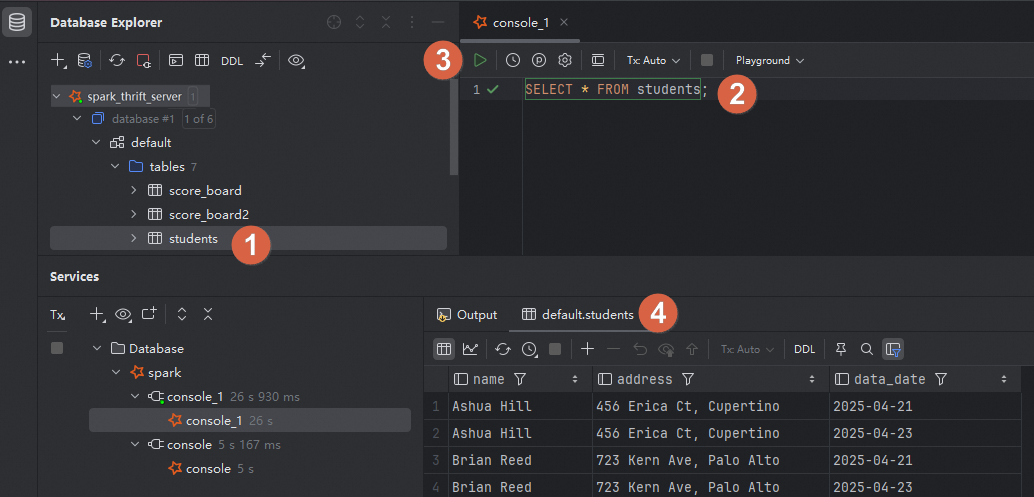
例如,您可以在创建的连接下,在目标表上右键,选择,并在右侧SQL编辑器中编写并运行SQL脚本,即可查看表数据信息。
使用Redash连接Spark Thrift Server
Redash是一款开源的BI工具,提供了基于Web的数据库查询和数据可视化功能。如需了解更多关于Redash的信息,请参见Redash官方文档。
安装Redash,详情请参见Redash官方文档。
安装依赖。
请确保您已经安装了0.20.0版本的
thrift包。如未安装,您可以使用以下命令安装。pip install thrift==0.20.0登录Redash。
在左侧导航栏单击Settings,并在Data Sources页签下单击+New Data Source。
在弹出的对话框中配置以下参数,然后单击Create。
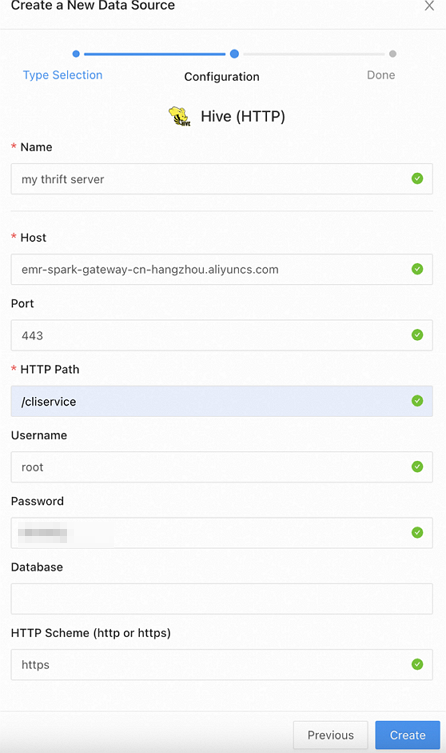
参数
说明
Type Selection
数据源类型。在搜索框中查找并选择Hive(HTTP)。
Configuration
Name
数据源名称。您可以自定义。
Host
Spark Thrift Server的Endpoint地址。
您可以在总览页签获取的Endpoint(外网)或Endpoint(内网)信息。
Port
如果使用外网域名访问,端口号为443。
如果使用内网域名访问,端口号为80。
HTTP Path
固定填写为
/cliservice。Username
用户名。可以任意填写,例如
root。Password
填写您创建的Token信息。
HTTP Scheme
如果使用外网域名访问,填写为
https。如果使用内网域名访问,填写为
http。
在页面上方选择,您可以在页面的编辑框中编写SQL语句。

查看运行记录
在数据开发任务执行完成后,您可以通过会话管理页面查看任务的运行记录。具体操作步骤如下:
在会话列表页面,单击会话名称。
单击运行记录页签。
在该页面中,您可以查看任务的详细运行信息,包括运行ID,启动时间,Spark UI等信息。
