
本文将指导您如何使用StarRocks跨集群数据迁移工具。该工具提供全量及增量同步功能,旨在为您解决迁移过程中源集群与目标集群的数据同步问题,确保数据一致性的同时,最大限度减少对业务运营的影响。
迁移准备
在开始迁移前,请完成以下准备工作,确保迁移过程顺利。
适用场景与版本兼容性
本工具主要适用于以下场景:
从自建StarRocks或EMR on ECS(半托管)集群迁移至Serverless StarRocks。
在Serverless StarRocks实例之间进行数据迁移。
版本要求
组件 | 要求 | 说明 |
源集群 | 存算一体集群 | 版本无特定要求。 |
目标集群 | 存算一体或存算分离集群 | 版本必须为 3.1.9、3.2.4 及其之后的版本。不支持迁移至2.x系列版本。建议升级到最新版本。 |
使用限制与风险
迁移内容:仅支持同步StarRocks的内表、视图和物化视图。不支持外表。依赖外表的视图或物化视图在迁移后可能会失效,请提前排查。
自增列(AUTO_INCREMENT):不支持迁移包含自增列的表。
数据写入:迁移期间,禁止在目标集群对正在同步的表执行任何写入或DDL操作,以免数据错乱或迁移失败。查询操作是允许的。
实时写入源集群的表:该迁移工具的写入性能无法保障与实时写入任务的实时数据同步。建议采用实时任务双写方案,以确保双方集群的数据一致性。详情请参见从自建StarRocks集群向Serverless StarRocks的迁移方案。
资源与网络准备
部署环境
您需要准备一台独立的云服务器 ECS来部署和运行迁移工具。
规格建议:选择至少 4 vCPU 8 GiB 或更高配置的实例,以保证迁移效率。
创建实例:请参见自定义购买实例完成ECS创建。
网络连通性
迁移工具、源集群和目标集群之间必须网络互通。网络拓扑与流量方向如下:

迁移工具 (ECS) -> 源集群 (FE/BE)
迁移工具 (ECS) -> 目标集群 (FE/BE)
目标集群 (BE) -> 源集群 (BE)
端口要求
请确保在相关安全组、防火墙或网络ACL中已放行以下端口:
组件 | 端口名称 | 默认端口号 | 协议 | 说明 |
FE | FE QueryPort | 9030 | TCP | SQL查询端口 |
FE | FE RpcPort | 9020 | TCP | 内部RPC端口 |
FE | FE HttpPort | 8030 | TCP | HTTP服务端口 |
BE | BE BePort | 9060 | TCP | BE间通信端口 |
BE | BE HttpPort | 8040 | TCP | BE的HTTP服务端口 |
如未使用默认端口,请通过 SHOW FRONTENDS; 和 SHOW BACKENDS; 命令确认实际端口。
连通性检查
在开始迁移前,务必在部署迁移工具的ECS实例上执行以下检查。
检查ECS到各集群的连通性
目的:验证ECS到源、目标集群所有FE和BE节点的网络链路。
操作:在ECS上对每个FE和BE节点的IP执行
telnet命令。# 检查到源集群 telnet <source_fe_ip> 9030 telnet <source_fe_ip> 9020 telnet <source_fe_ip> 8030 # 检查到目标集群 telnet <target_fe_ip> 9030 telnet <target_fe_ip> 9020 telnet <target_fe_ip> 8030
检查目标集群到源集群的连通性
同一VPC:源集群与目标集群位于同一VPC内,默认情况下网络互通。
不同VPC:源集群和目标集群位于不同VPC,需要通过VPC对等连接实现网络互通,详情请参见VPC对等连接。
VPC与本地数据中心:源集群是本地数据中心, 目标集群是VPC。您可以通过专线连接或VPN连接实现两者之间的互联,详情请参见VPC连接本地数据中心。
临时关闭Compaction
如果您的目标集群是 3.3.13之前版本的存算分离集群,您必须在迁移前手动关闭Compaction。而对于3.3.13及之后的版本,则无需关闭Compaction,建议3.3.13之前版本升级至最新版本。
操作步骤
目的:关闭目标集群的Compaction功能,以兼容旧版本迁移逻辑。
操作:
登录目标StarRocks实例的参数配置页面。
搜索参数
lake_compaction_max_tasks。将其值修改为
0;若参数值为0,则无需进行调整。提交修改并根据提示重启集群使配置生效。
迁移完成后,必须立即恢复此配置,详见步骤六:完成迁移与业务切换。
迁移流程
步骤一:配置目标集群
目的:启用目标集群的数据迁移功能,并设置兼容性参数。
在目标StarRocks实例的参数配置页面,新增或修改以下配置项:
文件
Key
Value
说明
FE
emr_serveless_replication_enabletrue必须配置。启用数据迁移功能。
FE
enable_legacy_compatibility_for_replicationtrue按需配置。如果源集群版本为2.4.0及以上,且从未从2.3.18及以下版本升级而来,则无需配置此项。否则,必须配置。
default_warehouse
compact_threads将默认值修改为当前BE/CN节点CU的两倍
迁移完成后,将其恢复为原来的默认值。
如果目标集群版本低于3.3.13,需在SQL Editor中执行以下命令:
SET GLOBAL enable_filter_unused_columns_in_scan_stage=false;
步骤二:获取源集群Token
自建集群或EMR on ECS(半托管)集群
(推荐)方法一:通过FE节点的元数据获取Token
登录FE节点所在的服务器,执行以下命令获取集群Token。
cat fe/meta/image/VERSION | grep token如果您使用的是EMR on ECS的集群,请登录集群的Master节点,然后执行以下命令获取集群token。
cat /mnt/disk1/starrocks/meta/image/VERSION | grep token返回信息如下所示。其中
token字段即为当前集群的Token。token=wwwwwwww-xxxx-yyyy-zzzz-uuuuuuuuuu方法二:通过FE的HTTP端口获取Token
在源集群的FE节点上,执行以下命令获取Token。
curl -v http://<fe_host>:<fe_http_port>/check其中,涉及参数如下:
<fe_host>:集群FE的IP地址或FQDN。<fe_http_port>:集群FE的HTTP端口(默认为8030,EMR半托管环境为18030)。
如果您使用的是EMR on ECS的集群,则命令执行后会返回类似以下内容。其中
token字段即为当前集群的Token。* Trying xxx.xx.xxx.xx... * TCP_NODELAY set * Connected to xxx.xx.xxx.xx (xxx.xx.xxx.xx) port 18030 (#0) > GET /check HTTP/1.1 > Host: xxx.xx.xxx.xx:18030 > User-Agent: curl/7.29.0 > Accept: */* > < HTTP/1.1 200 OK < content-length: 0 < cluster_id: yyyyyyyyyyy < content-type: text/html < token: wwwwwwww-xxxx-yyyy-zzzz-uuuuuuuuuu < connection: keep-alive < * Connection #0 to host xxx.xx.xxx.xx left intactServerless StarRocks实例
在进行Serverless StarRocks实例间的数据迁移时,您可以在StarRocks实例的实例详情页面的基础信息区域,单击获取迁移Token,以获取待迁移实例所需的Token。
步骤三:部署与配置迁移工具
下载并上传。
单击starrocks-cluster-sync-2.1.1.tar.gz以获取EMR Serverless StarRocks迁移工具。
连接ECS实例,并上传获取到的迁移工具,详情请参见连接实例和使用Workbench上传或下载文件。
配置迁移工具。
修改
starrocks-cluster-sync-2.1.1/conf/目录下的sync.properties配置文件。必填参数
以下参数是迁移任务成功运行所必需的,请根据实际环境正确配置。
参数
说明
source_fe_host源集群FE的IP地址或FQDN。
source_fe_query_port源集群FE的查询端口(
query_port)。source_cluster_user用于登录源集群的用户名。
source_cluster_password用于登录源集群的用户密码。
source_cluster_token源集群的Token。
target_fe_host目标集群FE的IP地址或FQDN。
target_fe_query_port目标集群FE的查询端口(
query_port)。target_cluster_user用于登录目标集群的用户名。
target_cluster_password用于登录目标集群的用户密码。
include_data_list需要迁移的数据库和表,多个对象时使用逗号(
,)分隔。例如,db1,db2.tbl2,db3。说明如果您需要迁移集群中所有数据库和表,则无须配置该项。
exclude_data_list不需要迁移的数据库和表,多个对象时使用逗号(
,)分隔。例如,db1,db2.tbl2,db3。该参数优先于include_data_list生效。说明如果您需要迁移集群中所有数据库和表,则无须配置该项。
说明在同时配置
include_data_list和exclude_data_list时,最终需要迁移的数据表是从include_data_list中排除exclude_data_list所指定的表。例如,配置include_data_list=db1.tbl1,db1.tbl2,db1.tbl3以及exclude_data_list=db1.tbl2时,最终生效的数据表为db1.tbl1和db1.tbl3。可选参数
以下参数可以根据需求进行调整,但通常保持默认值即可。
参数
说明
target_cluster_storage_volume当目标集群是存算分离集群时,用于指定待迁移的表所在的Storage Volume,默认为空,表示使用目标集群的默认存储卷。
target_cluster_replication_num指定目标集群表的副本数量,默认为
-1,表示目标集群表的副本数量与源集群保持一致。target_cluster_max_disk_used_percent迁移工具对目标集群 BE 磁盘检查阈值,当任何一个 BE 的最大磁盘使用率大于这个配置的百分比,迁移工具会自动退出,防止磁盘打满。默认为
90。max_replication_data_size_per_job_in_gb迁移工具触发数据同步任务的(分区)数据大小阈值。单位:GB。如果要迁移的数据大小超过此值,将产生多个数据同步任务,默认值为
1024。非必要不调整的参数
以下参数通常可以使用默认值,无需调整。仅在特殊场景下需要修改时,请根据实际需求进行调整。
参数
默认值
说明
one_time_run_modefalse选择是否关闭增量同步模式。启用后,系统将仅执行一次全量数据同步而不进行后续的增量数据更新,即每张表将只同步一次。
meta_job_interval_seconds180迁移工具获取源集群和目标集群元数据的周期,单位为秒。
meta_job_threads4迁移工具获取源集群和目标集群元数据的线程数量。
ddl_job_interval_seconds10迁移工具在目标集群执行DDL的周期,单位为秒。
ddl_job_batch_size10迁移工具在目标集群执行DDL的批大小。
ddl_job_allow_drop_target_onlyfalse迁移工具是否自动删除仅在目标集群存在而源集群不存在的数据库和数据表。
ddl_job_allow_drop_partition_target_onlytrue迁移工具是否自动删除仅在目标集群存在而源集群不存在的分区。
ddl_job_allow_drop_schema_change_tabletrue迁移工具是否自动删除源集群和目标集群Schema不一致的表。
ddl_job_allow_drop_inconsistent_partitiontrue迁移工具是否自动删除源集群和目标集群数据分布方式不一致的分区。
ddl_job_allow_drop_materialized_view_target_onlyfalse迁移工具是否自动删除仅在目标集群存在而源集群不存在的物化视图。
ddl_job_allow_drop_view_target_onlyfalse迁移工具是否自动删除仅在目标集群存在而源集群不存在的逻辑视图。
ddl_job_allow_drop_bitmap_index_target_onlytrue迁移工具是否自动删除仅在目标集群存在而源集群不存在的bitmap索引。
replication_job_interval_seconds15迁移工具触发数据同步任务的周期,单位为秒。
replication_job_batch_size10迁移工具触发数据同步任务的批大小。
compaction_job_interval_seconds30迁移工具在目标集群对迁移完成的表执行Compaction的周期,单位为秒。
compaction_job_batch_size10迁移工具在目标集群对迁移完成的表执行Compaction的批大小。
步骤四:启动与停止迁移工具
启动迁移:进入工具根目录,执行启动脚本。
./bin/start.sh说明迁移工具将定期检查目标集群的数据状态,以确认其是否与源集群同步。如果发现目标集群数据版本落后,工具将自动启动新的数据迁移任务。
若源集群在迁移过程中不断有新数据加入,数据同步将持续进行直到目标集群的数据完全与源集群相匹配。
停止迁移:迁移工具不会自动停止。在确认数据完全同步并完成业务切换后,您必须手动停止工具。
终止类型
适用场景
操作说明
永久终止
表进度和任务进度都达到100%,且源集群无新数据写入。
终止任务后进行数据校验。
临时终止
需要中途验证数据。
校验完成后可重新启动,继续同步增量数据。
步骤五:查看迁移进度与验证数据
查看迁移进度
您可以通过迁移工具日志log/sync.INFO.log查看迁移进度,包括同步任务进度和同步表进度。
正在同步的表:搜索关键字
Running table detail,会输出当前正在迁移的表名称。
同步任务进度:搜索关键字
Sync job progress,如果进度显示100%,则说明迁移完成。说明显示所有同步任务的完成情况。由于源集群数据不断更新,工具会定期检测新增数据并启动新的同步任务,因此进度百分比可能会下降(如从100%降至90%),这是正常现象。
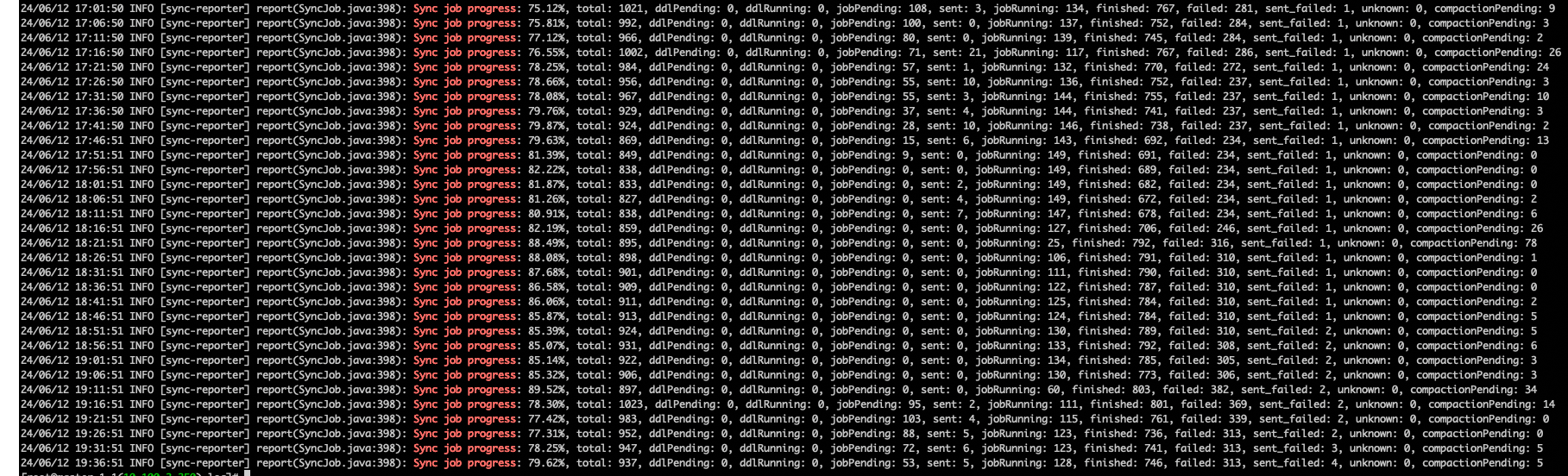
以下是与进度相关的参数详情。
参数
说明
total此次数据迁移中的总作业数。
ddlPending待执行的DDL作业数量。
ddlRunning当前正在执行的DDL作业的数量,该参数值通常为0或1。
jobPending待执行的数据同步作业数量。
sent已发送但尚未开始的数据同步作业数量。
running正在运行中的数据同步作业数量。
finished已成功执行完毕的数据同步作业数量。
failed执行失败的数据同步作业累积数量。通常,此数值可忽略,因为迁移过程中会周期性地重试失败的作业。
unknown状态未知的作业数量。
同步表进度:搜索关键字
Sync table progress。说明同步表进度说明
同步表进度表示已至少成功完成一次同步的表数量占所配置总表数的比例。
进度为 100%:所有配置的表均已至少完成一次全量同步,该值不会再下降。
进度低于 100%:还有部分表尚未成功同步。
进度状态判断逻辑
表进度 = 100% 且任务进度 = 100%:所有表的数据已完全同步,源集群与目标集群数据一致。
表进度 = 100% 但任务进度 < 100%:所有表已完成至少一次同步,部分表正在同步增量数据。
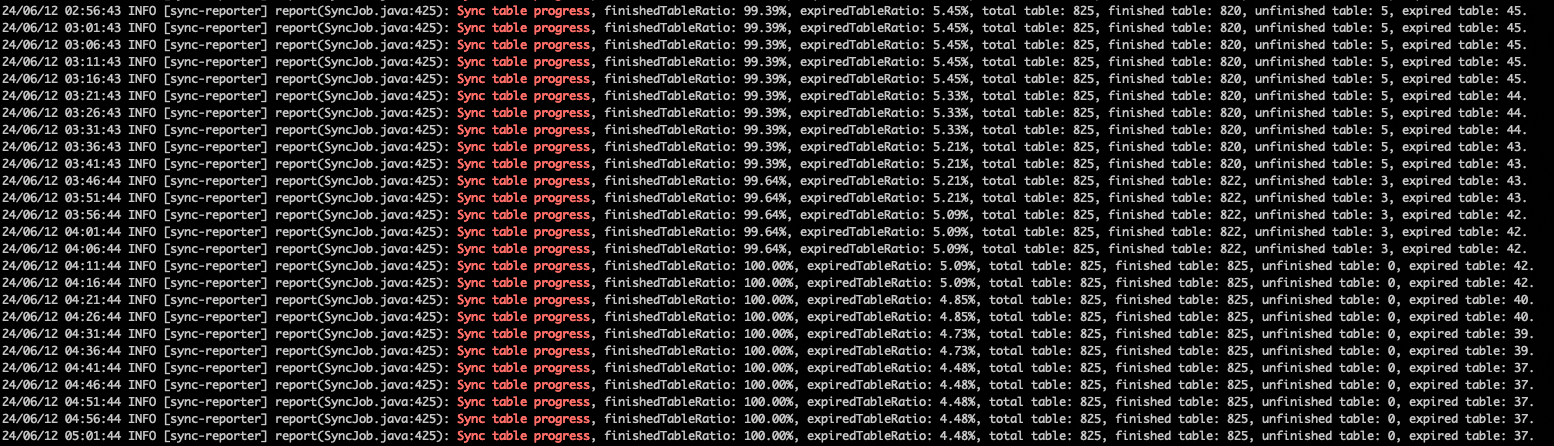
以下是与进度相关的参数详情。
参数
说明
finishedTableRatio至少有一次成功执行同步任务的数据表所占比例。
expiredTableRatio数据表过期数据所占比例。
total table此次数据迁移配置的数据表总数。
finished table至少有一次同步任务执行成功过的数据表数量。
unfinished table还未进行过数据同步的数据表数量。
unfinished detail还未进行过数据同步的数据表名称列表。
验证数据
在迁移过程中及迁移完成后,您可以通过以下SQL命令抽样对比源、目标集群的数据,作为辅助验证手段。
查看迁移事务状态:迁移工具会为每张表开启一个事务,您可以通过查看事务的状态了解该表的迁移进度。
SHOW PROC "/transactions/<db_name>/running";其中,
<db_name>为该表所在数据库的名称。返回结果中会显示当前正在运行的事务及其状态。如果事务状态为“完成”,则表示该表的迁移任务已完成;如果长时间处于“运行中”,可能需要排查是否存在异常。
查看分区数据版本:对比分区版本号是最可靠的方式之一。
SHOW PARTITIONS FROM <table_name>;在源和目标集群上对同一张表执行,比较各分区的
Version是否一致。查看表行数:可作为快速概览,但并非精确验证。
-- 在源和目标集群上分别执行 SELECT TABLE_NAME, TABLE_ROWS FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = '<db_name>';返回结果中将列出每个表的名称及其对应的行数。通过对比源集群与目标集群中相同表的行数,若行数一致,则表明该表已成功迁移。
查看数据量:通过对比源集群和目标集群的数据量,可以快速了解整体迁移进度。
SHOW DATA;返回结果中会显示每个数据库和表的数据量(包括磁盘占用大小)。对比源集群和目标集群的数据量,若两者一致,则表示数据迁移已完成。
步骤六:完成迁移与业务切换
当您通过监控确认数据已完全同步(Sync job progress持续稳定在100%),并且业务处于可切换的窗口期时,请按以下流程完成最终切换。
停止业务写入源集群:暂停向源集群写入新数据的应用程序。
最终确认数据同步:再次检查迁移工具日志,确保
Sync job progress在业务停止写入后达到并保持100%。停止迁移工具:执行停止命令,终止数据同步。
恢复目标集群配置:
目的:将迁移期间的临时配置改回默认值,确保集群性能和稳定性。
操作清单:
在参数配置页面,将
emr_serveless_replication_enable修改为false,将compact_threads修改为默认值。若曾配置,将
enable_legacy_compatibility_for_replication修改为false。若曾修改,在SQL Editor中执行
SET GLOBAL enable_filter_unused_columns_in_scan_stage=true;。(极其重要)如果曾关闭Compaction,请务必在参数配置页面将
lake_compaction_max_tasks恢复为默认值(如-1)或一个正整数,并重启集群。
业务切换:将您的应用程序或服务的数据源配置从源集群地址修改为目标集群地址,并启动业务。
最终验证:在新集群上验证业务功能是否正常。
性能调优
您可以根据源集群负载和迁移时效性要求,调整以下参数来优化性能。通常默认值即可满足大部分场景。如果您对性能要求较高,可以适当调整这些参数以加速迁移,但需要注意,增大这些配置项可能会增加源集群的负载压力。
FE参数(通过
ADMIN SET FRONTEND CONFIG命令修改)参数
默认值
描述
replication_max_parallel_table_count100
允许同时执行同步任务的表的最大数量。
replication_max_parallel_data_size_mb1048576
所有并发同步任务允许处理的最大数据量(MB)。
replication_max_parallel_replica_count10240
同时执行的并发副本同步任务总数。
BE参数(通过
ADMIN SET BACKEND CONFIG命令修改)参数
默认值
描述
replication_threads0
每个BE节点上用于执行同步任务的线程数。
0表示自动设置为CPU核数。
常见问题
查询性能下降
原因: 同步过程中产生大量小文件,未及时合并。
解决方案:
检查
Compaction Score指标是否过高。临时调大合并线程数:
推荐值:
8或16可加快文件合并效率
联系我们
如果您在迁移过程中有任何疑问,请提交工单进行咨询。