开源大数据开发平台E-MapReduce(简称EMR)是运行在阿里云平台上的一种大数据处理系统解决方案。EMR基于开源的Apache Hadoop和Apache Spark,让您可以方便地使用Hadoop和Spark生态系统中的其他周边系统分析和处理数据。EMR还可以与阿里云其他的云数据存储系统和数据库系统(例如,阿里云OSS和RDS等)进行数据传输。
产品介绍
阿里云EMR提供了on ECS、on ACK和Serverless形态,以满足不同用户的需求。
形态 | 描述 |
EMR on ECS | EMR负责将开源Hadoop生态的组件安装部署在ECS上,并启动相应的服务。您可以在EMR控制台完成对集群ECS及服务的运维操作。 关于EMR on ECS的更多介绍,请参见什么是EMR on ECS。 |
EMR on ACK | 您需要先完成ACK集群的安装部署。当ACK集群准备就绪后,EMR将基于ACK的资源安装部署大数据服务组件,并在容器内运行。关于EMR on ACK的更多介绍,请参见什么是EMR on ACK。 |
EMR Serverless StarRocks | EMR Serverless StarRocks是开源StarRocks在阿里云上的全托管服务,您可以通过其灵活地创建和管理实例以及数据。本文为您介绍StarRocks的核心特性,并详述EMR Serverless StarRocks在此基础之上所引入的诸多增强功能与服务优势。 关于EMR Serverless StarRocks的更多介绍,请参见什么是EMR Serverless StarRocks。 |
EMR Serverless Spark | EMR Serverless Spark是一款面向Data+AI的高性能Lakehouse产品。该产品为企业提供了一站式的数据平台服务,包括任务开发、调试、调度及运维等功能,显著简化了数据处理与模型训练的全流程。同时,它100%兼容开源Spark生态,能够无缝集成到客户现有的数据平台。通过使用EMR Serverless Spark,企业可以更加专注于数据处理分析及模型训练的优化,从而提升工作效率。 关于EMR Serverless Spark的更多介绍,请参见什么是EMR Serverless Spark。 |
产品架构
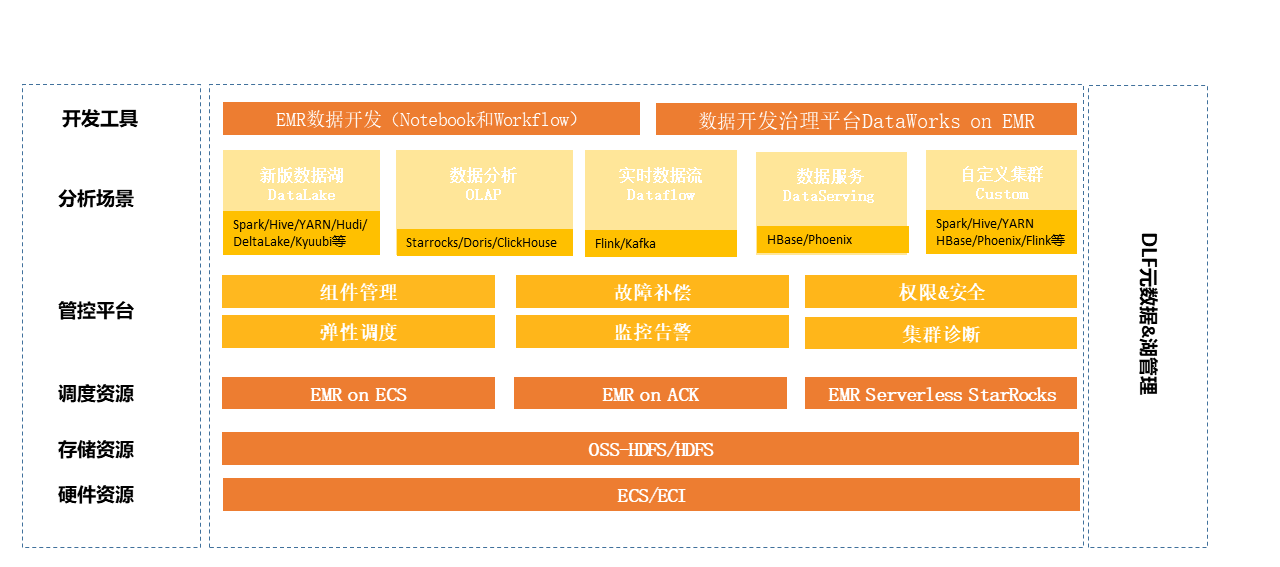
产品优势
EMR on ECS
EMR为您提供了相对方便可控的企业级开源大数据服务。您可以快速搭建开源大数据服务,例如Hadoop、Spark、Flink、Kafka和HBase服务。
100%采用社区开源组件,适配并优化开源组件,性能远高于开源版本。
基于时间的弹性伸缩能力,抢占式实例可进一步降低成本。
解耦了计算与存储之间的绑定关系,实现了资源的弹性利用。
分钟级别创建和扩容集群,无需手动部署和启动服务。
EMR on ACK
节省成本:无需单独购买ACK集群。
简化运维:一套运维体系,一套集群管理,全面覆盖大数据和在线等多种业务。
优化体验:支持ECS和ACK两套IaaS资源模型,您可以无缝切换。
深度集成:完全采用云原生数据湖架构,计算使用阿里云ACK,计算资源可以无限扩展。
EMR Serverless StarRocks
EMR Serverless StarRocks主要在企业级功能方面做了以下增强:
全托管的免运维产品服务形态,大大降低了运维和使用的复杂度以及成本。
可视化的StarRocks实例管理控制台,使得实例的整体运维和管理更加方便。
可视化的监控及运维能力。
支持大、小版本自动升级,方便StarRocks进行版本升级管理。
增加EMR StarRocks Manager,提供了企业级的StarRocks管理能力:
安全能力:支持用户及权限管理。
诊断分析:支持可视化慢SQL,及SQL查询分析能力。
数据管理:提供数据库、表、分区、分片、任务的查询能力,方便运维管理。
EMR Serverless Spark
云原生极速计算引擎
内置Fusion Engine (Spark Native Engine):相对开源版本性能提升300%,显著加速大数据计算任务。通过向量化引擎和批量数据处理技术优化计算效率,同时减少内存占用,大幅提升整体性能。
内置Celeborn(Remote Shuffle Service):支持PB级Shuffle数据处理,大幅提高大Shuffle任务的稳定性和性能。计算节点无需配置大规格云盘,充分利用Spark的动态资源伸缩能力,降低存储成本,计算资源总成本最高下降30%。
开放化的数据湖架构
按需弹性伸缩:支持计算与存储分离架构,计算资源可实现秒级弹性伸缩,最小粒度为1核,精细化按任务或队列级别进行资源计量。存储采用按量付费模式,避免资源浪费,大幅降低企业运营成本。
无缝迁移与兼容性:对接OSS-HDFS,完全兼容HDFS的云上存储,支持用户业务平滑迁移上云。通过DLF实现湖仓元数据全面打通,确保数据访问一致性与权限管理完整性,助力企业轻松构建现代化数据湖仓架构。
一站式的开发体验
全流程开发支持:提供从任务开发、调试、发布到调度的一站式开发体验,满足企业级开发与发布的高标准需求。内置版本管理功能,完整记录每次发布历史,支持源码与配置差异对比,确保变更可追溯。
高效协作与稳定性保障:开发与生产环境严格隔离,保障业务稳定性,助力团队高效协作与稳定交付。
Serverless的资源平台
开箱即用:无需手动管理和复杂的基础设施搭建,即可快速启动任务开发。
秒级弹性:基于Spark任务的资源需求,动态拉取资源启动Pod,运算完毕后立即释放资源,计费仅针对实际使用的资源量,进一步降低计算总成本。
成本预估:提供任务级别的资源计量与成本预估,帮助企业实现精细化运营。