通过阿里云Milvus与PAI搭建高效的检索增强对话系统
阿里云Milvus现已无缝集成于阿里云PAI平台,一站式赋能用户构建高性能的RAG(Retrieval-Augmented Generation)对话系统。您可以利用Milvus作为向量数据的实时存储与检索核心,高效结合PAI和LangChain技术栈,实现从理论到实践的快速转化,搭建起功能强大的RAG解决方案。
背景信息
EAS简介
模型在线服务EAS(Elastic Algorithm Service)是一种模型在线服务平台,可支持您一键部署模型为在线推理服务或AI-Web应用。它提供的弹性扩缩容和蓝绿部署等功能,可以支撑您以较低的资源成本获取高并发且稳定的在线算法模型服务。此外,EAS还提供了资源组管理、版本控制以及资源监控等功能,方便您将模型服务应用于业务。EAS适用于实时同步推理、近实时异步推理等多种AI推理场景,并具备完整运维监控体系等能力。
更多信息,请参见EAS模型服务概述。
RAG简介
随着AI技术的飞速发展,生成式人工智能在文本生成、图像生成等领域展现出了令人瞩目的成就。然而,在广泛应用大语言模型(LLM)的过程中,一些固有局限性逐渐显现:
领域知识局限:大语言模型通常基于大规模通用数据集训练而成,这意味着它们在处理专业垂直领域的具体应用时可能缺乏针对性和深度。
信息更新滞后:由于模型训练所依赖的数据集具有静态特性,大模型无法实时获取和学习最新的信息与知识进展。
模型误导性输出:受制于数据偏差、模型内在缺陷等因素,大语言模型有时会出现看似合理实则错误的输出,即所谓的“大模型幻觉”。
为克服这些挑战,并进一步强化大模型的功能性和准确性,检索增强生成技术RAG应运而生。这一技术通过整合外部知识库,能够显著减少大模型虚构的问题,并提升其获取及应用最新知识的能力,从而实现更个性化和精准化的LLM定制。
RAG技术架构的核心为检索和生成。其中,检索部分采用了高效的向量检索引擎和向量数据库技术,例如基于开源库Faiss、Annoy以及HNSW算法优化构建的Milvus系统,极大地提升了对大规模数据进行快速检索和精确分析的能力。这样的设计使得RAG能够在必要时即时调用相关领域或最新信息,有效弥补了传统大语言模型的不足之处。
前提条件
已创建Milvus实例,并配置了公网访问。具体操作请参见快速创建Milvus实例和网络访问与安全设置。
已开通PAI(EAS)并创建了默认工作空间。具体操作,请参见开通PAI并创建默认工作空间。
使用限制
Milvus实例和PAI(EAS)须在相同地域下。
操作流程
步骤一:通过PAI部署RAG系统
进入模型在线服务页面。
登录PAI控制台。
在左侧导航栏单击工作空间列表,在工作空间列表页面中单击待操作的工作空间名称,进入对应工作空间内。
在工作空间页面的左侧导航栏选择模型部署>模型在线服务(EAS),进入模型在线服务(EAS)页面。

在PAI-EAS模型在线服务页面,单击部署服务。
在部署服务页面,选择大模型RAG对话系统部署。
在部署大模型RAG对话系统页面,配置以下关键参数,其余参数可使用默认配置,更多参数详情请参见大模型RAG对话系统。
参数
描述
基本信息
服务名称
您可以自定义。
模型来源
使用默认的开源公共模型。
模型类别
本示例以Qwen1.5-1.8b为例。
资源配置
实例数
使用默认的1。
资源配置选择
按需选择GPU资源配置。例如,ml.gu7i.c16m30.1-gu30。
向量检索库设置
版本类型
选择Milvus。
访问地址
Milvus实例的内网地址。您可以在Milvus实例的实例详情页面查看。
代理端口
Milvus实例的Proxy Port。您可以在Milvus实例的实例详情页面查看。默认为19530。
账号
配置为root。
密码
配置为创建Milvus实例时,由您自定义的root用户的密码。
数据库名称
配置为已创建的数据库名称,例如default。
Collection名称
输入新的Collection名称。
专有网络配置
VPC
创建Milvus实例时选择的VPC、交换机和安全组。您可以在Milvus实例的实例详情页面查看。
交换机
安全组名称
单击部署。
当服务状态变为运行中时,表示服务部署成功。
步骤二:通过RAG WebUI上传知识库
配置RAG对话系统。
在模型在线服务(EAS)页面,单击查看Web应用,进入WebUI页面。
配置Embedding模型。
在RAG服务WebUI界面的Settings选项卡中,系统已自动识别并应用了部署服务时配置的向量检索库设置。
Embedding Model Name:系统内置四种模型供您选择,将自动为您配置最合适的模型。
Embedding Dimension:选择Embedding Model Name后,系统会自动进行配置,无需手动操作。
测试向量检索库连接是否正常。
系统已自动识别并应用了部署服务时配置的向量检索库设置,并且该设置不支持修改。您可以单击Connect Milvus,来验证Milvus连接是否正常。
上传知识库。
在RAG服务WebUI界面的Upload选项卡中,可以上传知识库文档。
设置语义切块参数。
通过配置以下参数来控制文档切块粒度的大小和进行QA信息提取:
参数
描述
Chunk Size
指定每个分块的大小,单位为字节,默认为500。
Chunk Overlap
表示相邻分块之间的重叠量,默认为10。
Process with QA Extraction Model
通过选中Yes复选框启动QA信息提取功能,系统将在您上传业务数据文件后自动抽取出QA对,以获得更好的检索和回答效果。
在Files页签下上传业务数据文件(支持多文件上传)。
本文以唐诗三百首的poems.txt文档作为示例数据,您可以直接使用。
单击Upload,系统会先对上传的文件进行数据清洗(文本提取、超链接替换等)和语义切块,然后进行上传。
步骤三:通过RAG WebUI对话
在RAG服务WebUI界面的Chat选项卡中,提供了多种不同的Prompt策略,您可以选择合适的预定义Prompt模板或输入自定义的Prompt模板以获得更好的推理效果。
配置LLM问答策略
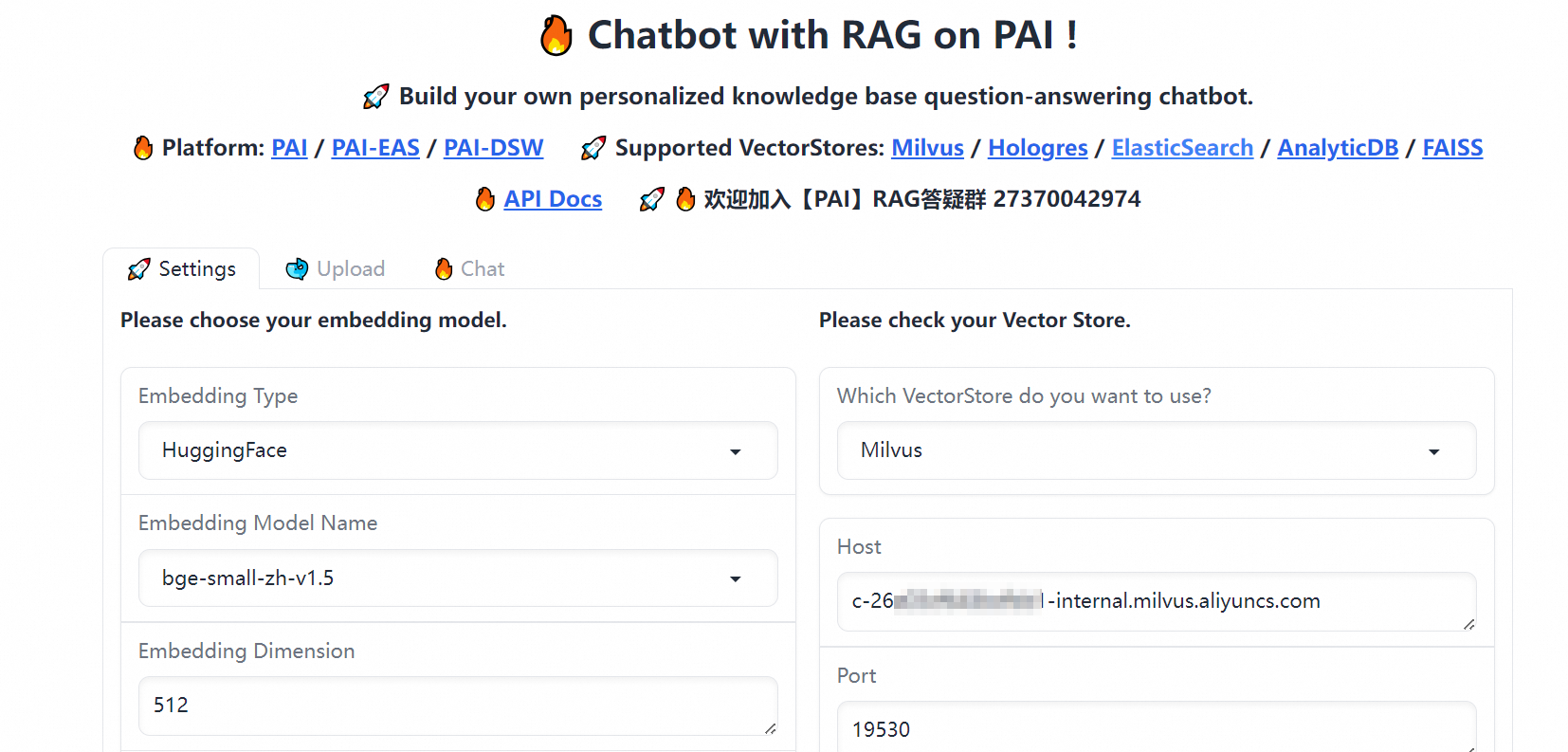
在RAG服务WebUI界面的Chat选项卡中,选择LLM。
直接与LLM对话,返回大模型的回答。
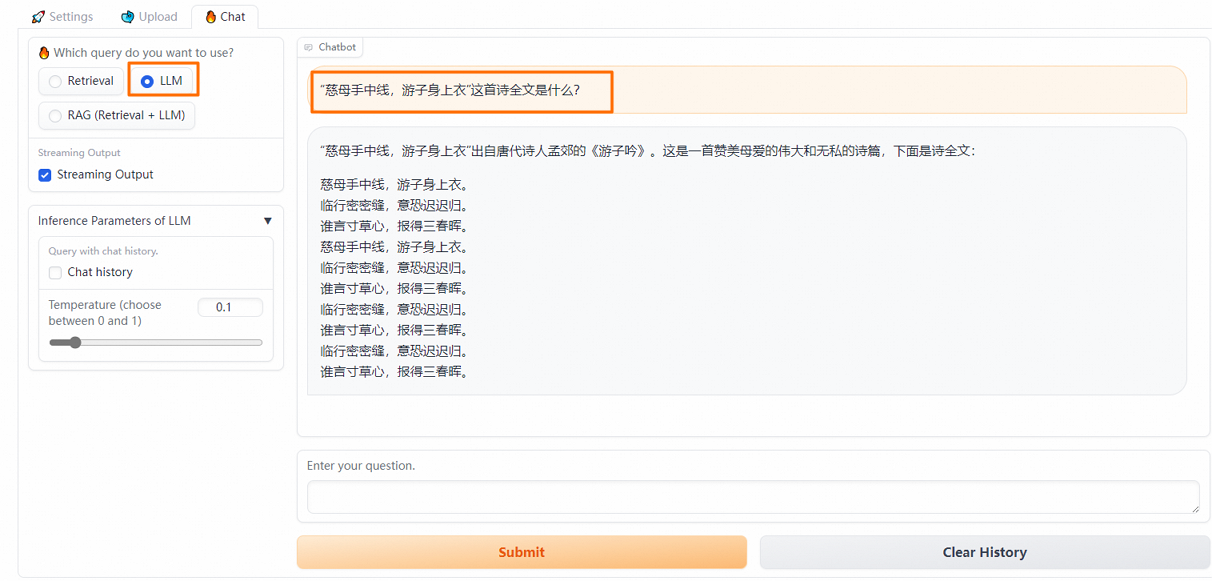
配置Retrieval问答策略
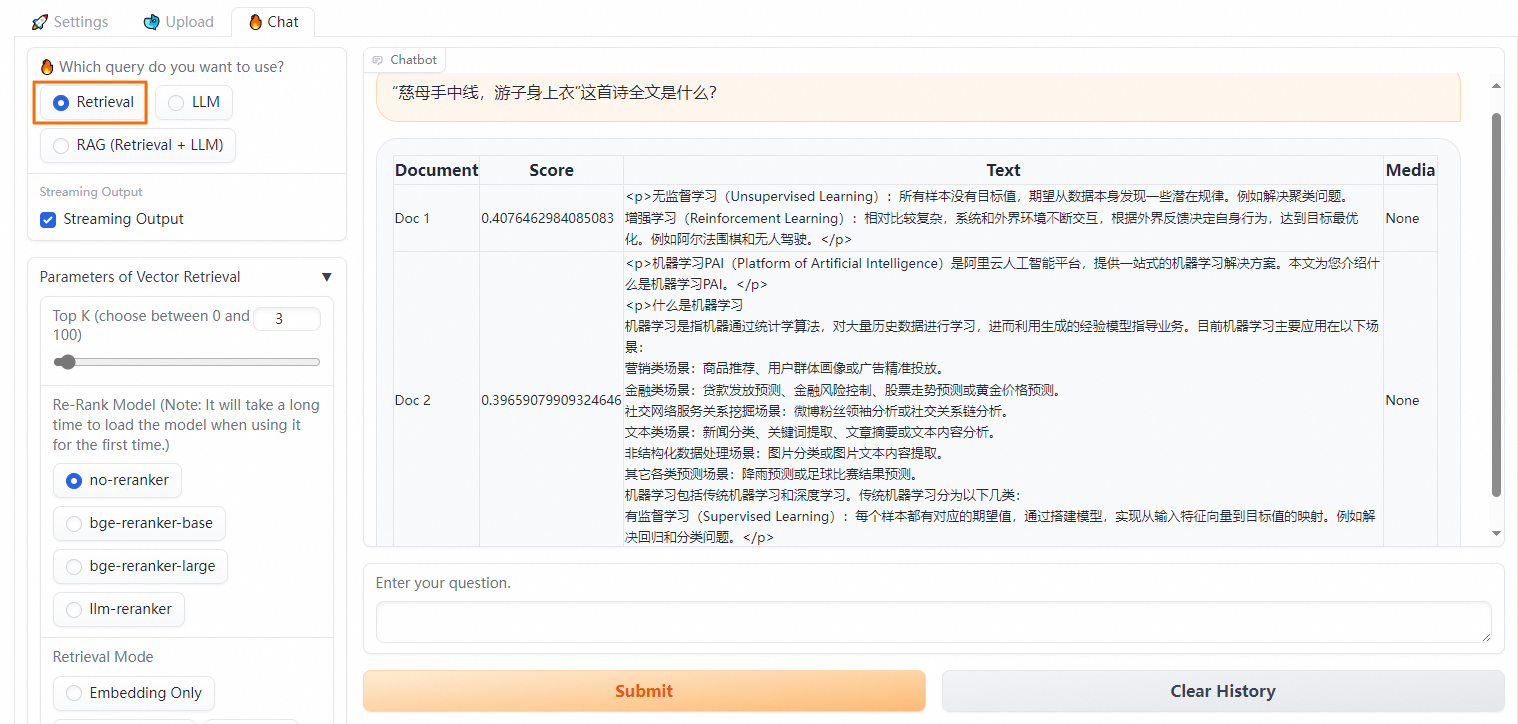
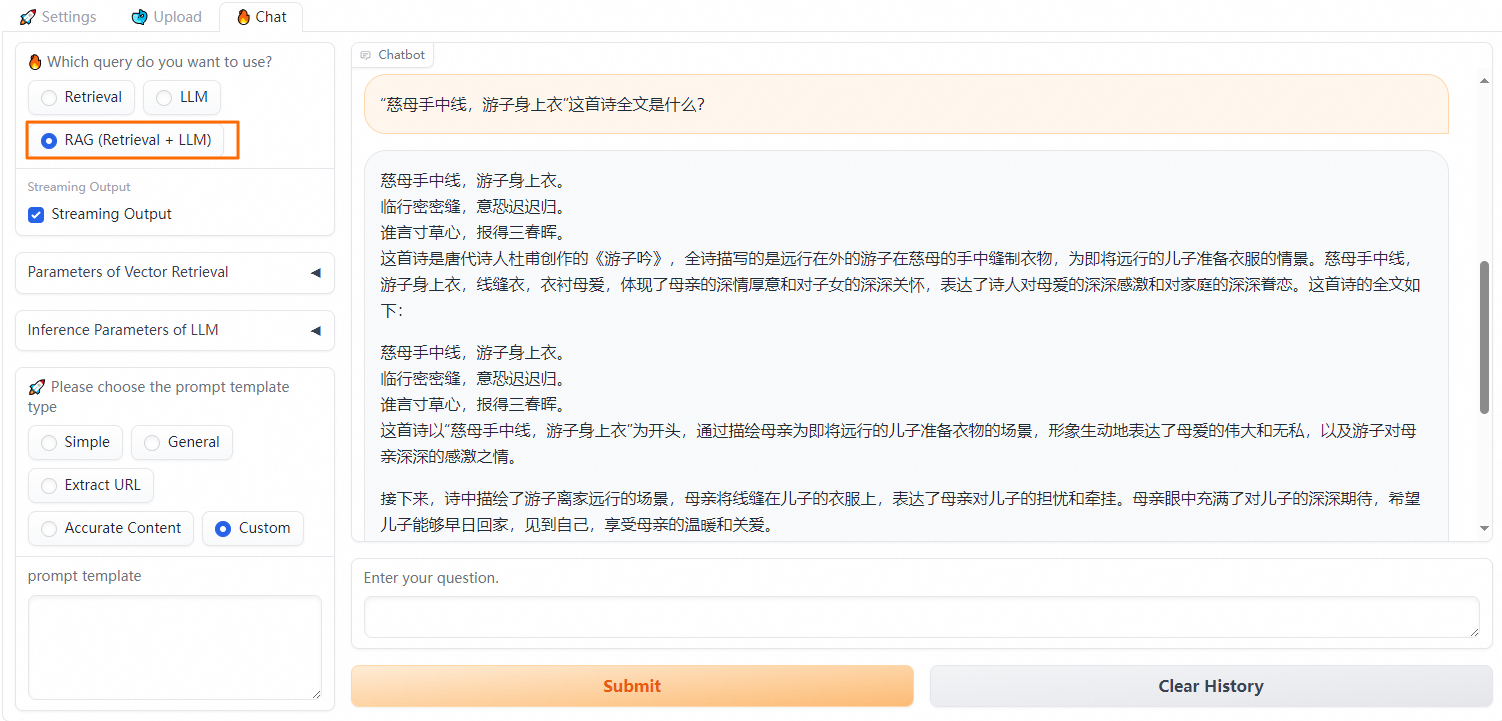
配置RAG(Retrieval + LLM)问答策略
选择RAG (Retrieval + LLM),然后进行向量检索等一系列实验。
步骤四:查看知识库切块
Attu是一款专为Milvus向量数据库打造的开源数据库管理工具,提供了便捷的图形化界面,极大地简化了对Milvus数据库的操作与管理流程。下面,我们将使用Milvus的Attu工具,查看向量数据库的存储内容。
进入安全配置页面。
登录阿里云Milvus控制台。
在左侧导航栏,单击Milvus实例。
在顶部菜单栏处,根据实际情况选择地域。
在Milvus实例页面,单击目标实例名称。
单击安全配置页签。
配置公网访问。
在安全配置页签,单击开启公网。

输入当前服务器的公网访问IP地址或符合CIDR定义的IP地址段。
多个IP条目以半角逗号(,)隔开,不可重复。您可以通过访问IP地址,获取当前服务器的公网访问IP地址。

单击确定。
访问Attu页面。
单击页面上方的Attu manager。

在弹出的对话框中输入所要访问的数据库、用户名和密码,单击连接,即可打开Attu管理页面。
实例创建完成后,系统会自动创建一个名为default的默认数据库,并为您创建一个名为root的用户,该用户的密码由您在创建实例时自行设置。
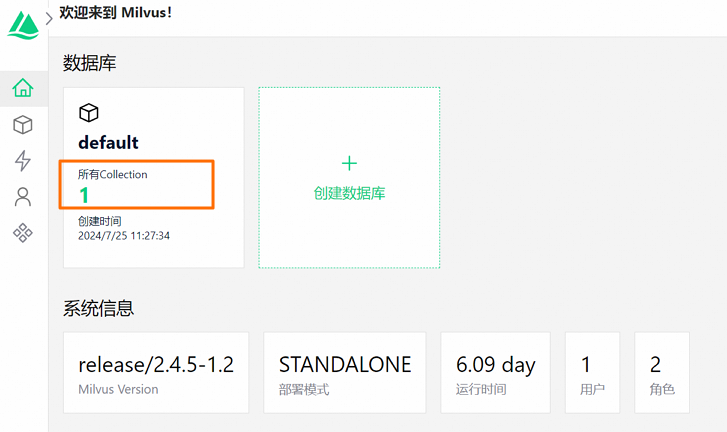
在Attu页面,您可以看到RAG服务自动创建的Collection。
相关文档
更多关于Milvus的介绍,请参见什么是向量检索服务Milvus版。
更多关于EAS的介绍,请参见EAS模型服务概述。