
ES-Hadoop是Elasticsearch推出的专门用于对接Hadoop生态的工具,可以让数据在Elasticsearch和Hadoop之间双向移动,无缝衔接Elasticsearch与Hadoop服务,充分使用Elasticsearch的快速搜索及Hadoop批处理能力,实现交互式数据处理。本文介绍通过ES-Hadoop组件在Hive上进行Elasticsearch数据的查询和写入,帮助您将Elasticsearch与Hadoop生态组件结合起来,实现更灵活的数据分析。
背景信息
Hadoop生态的优势是处理大规模数据集,但是其缺点也很明显,就是当用于交互式分析时,查询时延会比较长。而Elasticsearch擅长于交互式分析,对于很多查询类型,特别是对于Ad-hoc查询(即席查询),可以达到秒级。ES-Hadoop的推出提供了一种组合两者优势的可能性。使用ES-Hadoop,您只需要对代码进行很小的改动,即可快速处理存储在Elasticsearch中的数据,并且能够享受到Elasticsearch带来的加速效果。
ES-Hadoop的原理是将Elasticsearch作为MR、Spark或Hive等数据处理引擎的数据源,在计算存储分离的架构中扮演存储的角色。这和MR、Spark或Hive的数据源并无差异,但相对于这些数据源,Elasticsearch具有更快的数据选择过滤能力。这种能力正是分析引擎最为关键的能力之一。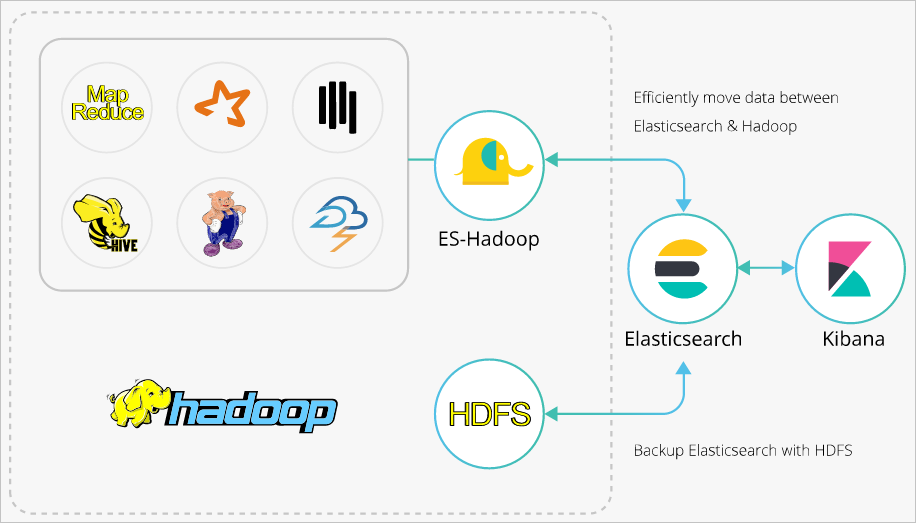
如果您需要了解ES-Hadoop与Hive更高级的配置,请参见Elasticsearch官方说明文档。
操作流程
创建同一专有网络下的阿里云Elasticsearch和E-MapReduce(以下简称EMR)实例、关闭Elasticsearch实例的自动创建索引功能并创建索引和Mapping、下载与Elasticsearch实例版本一致的ES-Hadoop安装包。
将已下载的ES-Hadoop安装包上传至EMR Master节点的HDFS目录下。
创建Hive外表,与Elasticsearch索引中的字段进行映射。
通过HiveSQL,向Elasticsearch实例的索引中写入数据。
通过HiveSQL,读取Elasticsearch实例中的索引数据。
准备工作
创建阿里云Elasticsearch实例。
本文使用6.7.0版本的实例,具体操作步骤请参见创建阿里云Elasticsearch实例。
关闭实例的自动创建索引功能,并提前创建索引和Mapping。
开启自动创建索引功能后,可能会导致Elasticsearch自动创建的索引类型和您预期的类型不一致。例如您定义了一个字段age,为INT类型,开启自动创建索引后,可能将其索引成了LONG类型,因此建议手动创建索引。本文使用的索引和Mapping如下。
PUT company { "mappings": { "_doc": { "properties": { "id": { "type": "long" }, "name": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "birth": { "type": "text" }, "addr": { "type": "text" } } } }, "settings": { "index": { "number_of_shards": "5", "number_of_replicas": "1" } } }创建与Elasticsearch实例在同一专有网络下的EMR集群。
重要Elasticsearch实例的私网访问白名单默认为0.0.0.0/0,您可在安全配置页面查看,如果未使用默认配置,您还需要在白名单中加入EMR集群的内网IP地址:
请参见查看集群列表与详情,获取EMR集群的内网IP地址。
请参见配置实例公网或私网访问白名单,配置Elasticsearch实例的VPC私网访问白名单。
步骤一:上传ES-Hadoop JAR包至HDFS
下载ES-Hadoop安装包,其版本需要与Elasticsearch实例保持一致。
本文使用elasticsearch-hadoop-6.7.0.zip。
登录E-MapReduce控制台,获取Master节点的IP地址,并通过SSH登录对应的ECS机器。
具体操作步骤请参见登录集群。
将已下载的elasticsearch-hadoop-6.7.0.zip上传至Master节点,并解压获得elasticsearch-hadoop-hive-6.7.0.jar。
创建HDFS目录,将elasticsearch-hadoop-hive-6.7.0.jar上传至该目录下。
hadoop fs -mkdir /tmp/hadoop-es hadoop fs -put elasticsearch-hadoop-6.7.0/dist/elasticsearch-hadoop-hive-6.7.0.jar /tmp/hadoop-es
步骤二:创建Hive外表
在EMR控制台的数据开发模块中,创建HiveSQL类型的作业。
具体操作步骤请参见Hive SQL作业配置。
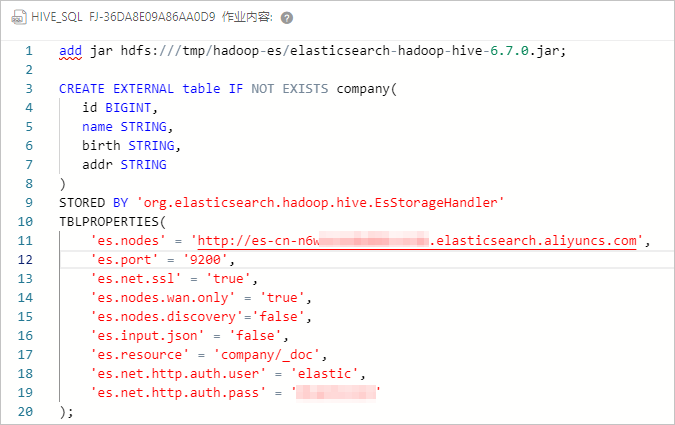
配置作业,创建外表。
作业配置如下。
####添加jar包,仅对当前会话有效######## add jar hdfs:///tmp/hadoop-es/elasticsearch-hadoop-hive-6.7.0.jar; ####创建hive外表,与es索引进行映射##### CREATE EXTERNAL table IF NOT EXISTS company( id BIGINT, name STRING, birth STRING, addr STRING ) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES( 'es.nodes' = 'http://es-cn-mp91kzb8m0009****.elasticsearch.aliyuncs.com', 'es.port' = '9200', 'es.net.ssl' = 'true', 'es.nodes.wan.only' = 'true', 'es.nodes.discovery'='false', 'es.input.use.sliced.partitions'='false', 'es.input.json' = 'false', 'es.resource' = 'company/_doc', 'es.net.http.auth.user' = 'elastic', 'es.net.http.auth.pass' = 'xxxxxx' );表 1. ES-Hadoop相关参数说明
参数
默认值
说明
es.nodes
localhost
指定阿里云Elasticsearch实例的访问地址,建议使用私网地址,可在实例的基本信息页面查看,详情请参见查看实例的基本信息。
es.port
9200
Elasticsearch实例的访问端口号。
es.net.http.auth.user
elastic
Elasticsearch实例的访问用户名。
说明如果程序中指定elastic账号访问Elasticsearch服务,后续在修改elastic账号对应密码后需要一些时间来生效,在密码生效期间会影响服务访问,因此不建议通过elastic来访问。建议在Kibana控制台中创建一个符合预期的Role角色用户进行访问,详情请参见通过Elasticsearch X-Pack角色管理实现用户权限管控。
es.net.http.auth.pass
/
Elasticsearch实例的访问密码。
es.nodes.wan.only
false
开启Elasticsearch集群在云上使用虚拟IP进行连接,是否进行节点嗅探:
true:设置
false:不设置
es.nodes.discovery
true
是否使用节点发现:
true:使用
false:不使用
重要使用阿里云Elasticsearch,必须将此参数置为false。
es.input.use.sliced.partitions
true
是否使用slice分区:
true:使用。设置为true,可能会导致索引在预读阶段的时间明显变长,有时会远远超出查询数据所耗费的时间。建议设置为false,以提高查询效率。
false:不使用。
es.index.auto.create
true
通过Hadoop组件向Elasticsearch集群写入数据,是否自动创建不存在的index:
true:自动创建
false:不会自动创建
es.resource
/
指定要读写的index和type。
es.mapping.names
/
表字段与Elasticsearch的索引字段名映射。
es.read.metadata
false
操作Elasticsearch字段涉及到_id之类的内部字段,请开启此属性。
更多的ES-Hadoop配置项说明,请参见官方配置说明。
保存并运行作业。
运行成功后,结果如下。

步骤三:通过Hive写入索引数据
创建一个HiveSQL类型的写数据作业。
作业配置如下。
add jar hdfs:///tmp/hadoop-es/elasticsearch-hadoop-hive-6.7.0.jar; INSERT INTO TABLE company VALUES (1, "zhangsan", "1990-01-01","No.969, wenyixi Rd, yuhang, hangzhou"); INSERT INTO TABLE company VALUES (2, "lisi", "1991-01-01", "No.556, xixi Rd, xihu, hangzhou"); INSERT INTO TABLE company VALUES (3, "wangwu", "1992-01-01", "No.699 wangshang Rd, binjiang, hangzhou");保存并运行作业。

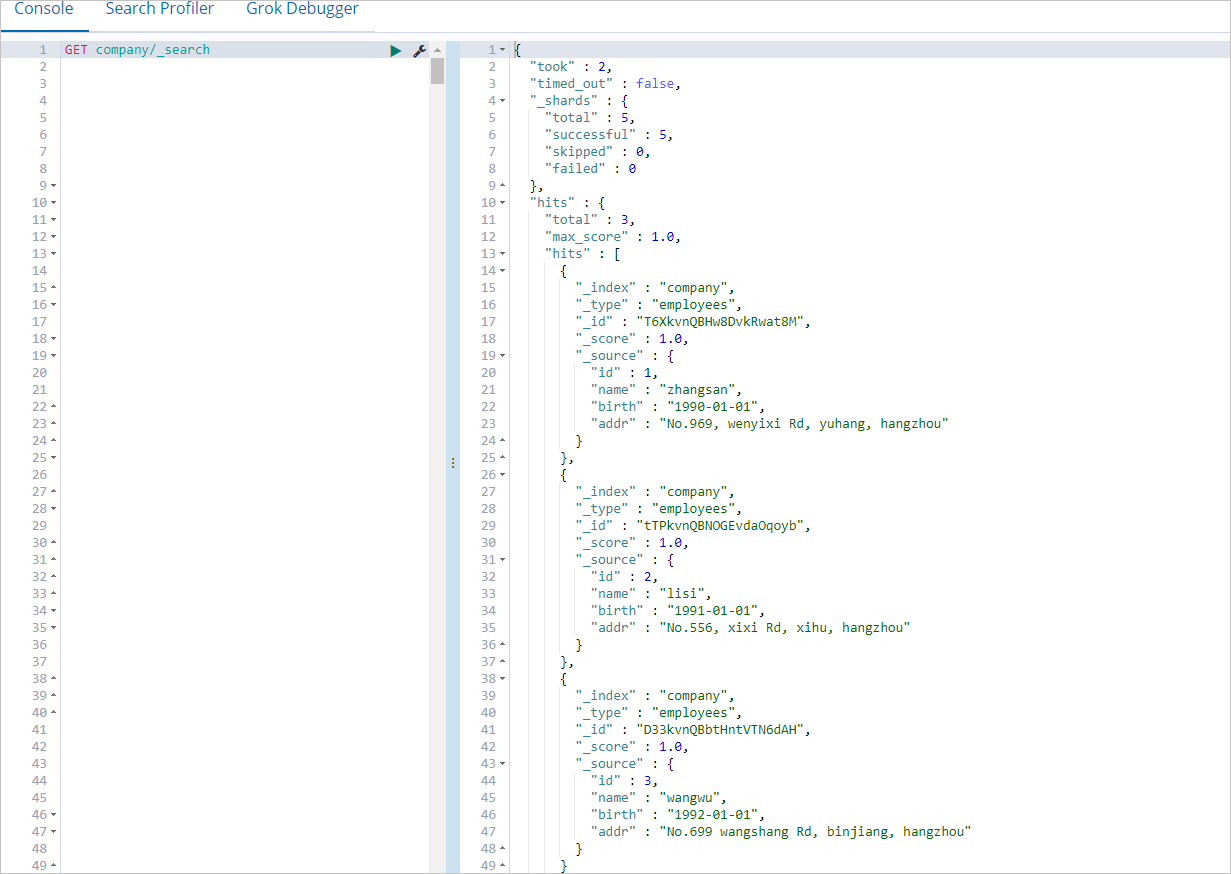
运行成功后,登录Elasticsearch实例的Kibana控制台,查看company索引数据。
登录Kibana控制台的具体操作步骤,请参见登录Kibana控制台。您可以在Kibana控制台中,执行以下命令查看company索引数据。
GET company/_search执行成功后,返回结果如下。
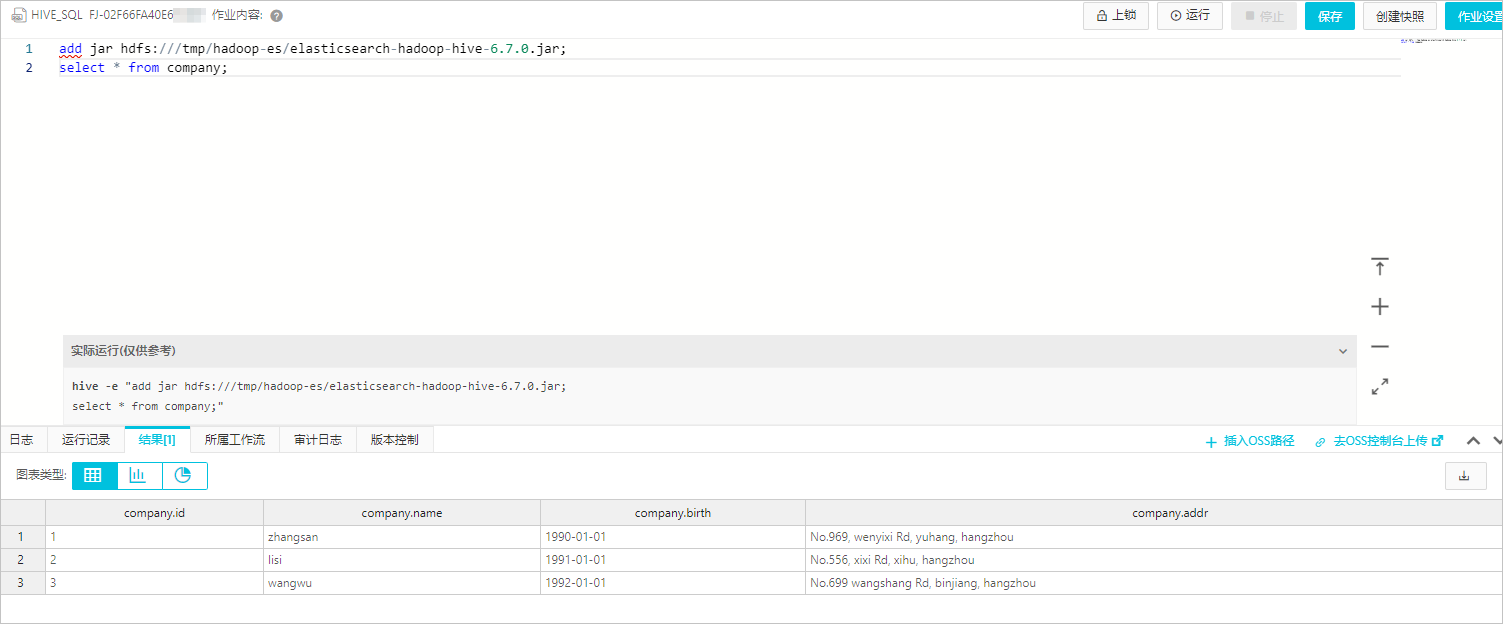
步骤四:通过Hive读取索引数据
创建一个HiveSQL类型的读数据作业。
作业配置如下。
add jar hdfs:///tmp/hadoop-es/elasticsearch-hadoop-hive-6.7.0.jar; select * from company;保存并运行作业。
常见问题
Q:Hive读写Elasticsearch数据时,遇到如下报错信息,该如何处理?
报错信息: FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Could not initialize class org.elasticsearch.hadoop.rest.commonshttp.CommonsHttpTransport。A:报错的原因是EMR 5.6.0版本的Hive组件缺少commons-httpclient-3.1.jar文件。处理方法为手动增加缺少的文件到Hive的lib目录下,文件下载地址,请参见commons-httpclient-3.1。