
配置MongoDB Catalog后,您可以在Flink作业开发中直接访问MongoDB集合,无需再定义Schema。本文为您介绍如何创建、查看、使用和删除MongoDB Catalog。
背景信息
MongoDB Catalog通过自动解析Bson文档来推导集合的Schema,您无需在Flink SQL中声明MongoDB集合的Schema便可以获取具体字段信息。MongoDB Catalog具有以下功能特点:
MongoDB Catalog的表名对应MongoDB集合名,无需再通过DDL语句手动注册MongoDB表,提升开发效率和正确性。
MongoDB Catalog提供的表可以直接作为Flink SQL作业中的源表、维表和结果表使用。
VVR 8.0.6及以上版本MongoDB Catalog可以配合CREATE TABLE AS(CTAS)语句或CREATE DATABASE AS(CDAS)语句完成表结构变更的同步。
本文将从以下方面为您介绍如何管理MongoDB Catalog:
使用限制
仅Flink计算引擎VVR 8.0.5及以上版本支持配置MongoDB Catalog。
不支持通过DDL语句修改已有的MongoDB Catalog。
仅支持查询数据库表,不支持创建、修改和删除数据库和表。
创建MongoDB Catalog
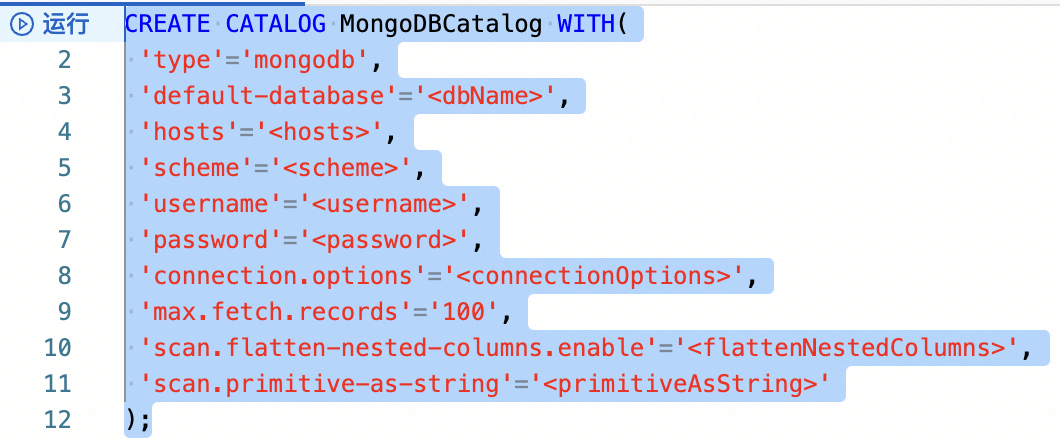
在数据查询文本编辑区域,输入配置MongoDB Catalog的命令。
CREATE CATALOG <yourcatalogname> WITH( 'type'='mongodb', 'default-database'='<dbName>', 'hosts'='<hosts>', 'scheme'='<scheme>', 'username'='<username>', 'password'='<password>', 'connection.options'='<connectionOptions>', 'max.fetch.records'='100', 'scan.flatten-nested-columns.enable'='<flattenNestedColumns>', 'scan.primitive-as-string'='<primitiveAsString>' );参数
类型
说明
是否必填
备注
yourcatalogname
String
MongoDB Catalog名称。
是
请填写为自定义的英文名。
重要参数替换为您的Catalog名称后,需要去掉尖括号(<>),否则语法检查会报错。
type
String
Catalog类型。
是
固定值为mongodb。
hosts
String
MongoDB所在的主机名称。
是
可以使用英文逗号(
,)分隔多个主机名。default-database
String
默认的MongoDB数据库名称。
是
无。
scheme
String
MongoDB使用的连接协议。
否
参数取值如下:
mongodb(默认值):使用默认的MongoDB协议进行连接。mongodb+srv:使用DNS SRV记录协议进行连接。
username
String
连接到MongoDB时使用的用户名。
否
开启身份验证功能时,必须配置该参数。
password
String
连接到MongoDB时使用的密码。
否
开启身份验证功能时,必须配置该参数。
说明为了避免您的密码信息泄露,建议您使用变量的方式填写,详情请参见项目变量。
connection.options
String
MongoDB侧的连接参数。
否
使用
&分隔的key=value式额外连接参数。例如connectTimeoutMS=12000&socketTimeoutMS=13000。max.fetch.records
Int
解析Bson文档时,最多尝试获取的文档数量。
否
默认值为100。
scan.flatten-nested-columns.enabled
Boolean
解析Bson文档时,是否递归式地展开Bson中的嵌套文档。
否
参数取值如下:
true:递归式展开。对于被展开的列,Flink使用索引该值的路径作为名字。例如对于
{"nested":{"col":true}}中的列col,它展开后的名字为nested.col。false(默认值):将Bson嵌套文档类型当作String处理。
重要仅当MongoDB Catalog提供的表作为Flink SQL作业源表时支持该参数。
scan.primitive-as-string
Boolean
解析Bson文档时,是否推导所有基本类型为String类型。
否
参数取值如下:
true:推导所有基本类型为String。
false(默认值):按照基本规则进行推导。基本规则详情请参见从MongoDB Catalog获取的表信息详解。
选中创建Catalog的代码后,单击左侧代码行数上的运行。
在左侧元数据区域,查看创建的Catalog。
查看MongoDB Catalog
在数据查询文本编辑区域,输入以下命令。
DESCRIBE `${catalog_name}`.`${db_name}`.`${collection_name}`;参数
说明
${catalog_name}
MongoDB Catalog名称。
${db_name}
MongoDB数据库名称。
${collection_name}
MongoDB集合名称。
选中查看Catalog的代码后,单击左侧代码行数上的运行。
运行成功后,可以在运行结果中查看表的具体信息。

使用MongoDB Catalog
作为源表,从MongoDB中读取数据。
INSERT INTO ${other_sink_table} SELECT... FROM `${mongodb_catalog}`.`${db_name}`.`${collection_name}` /*+OPTIONS('scan.incremental.snapshot.enabled'='true')*/;作为源表,使用CREATE TABLE AS(CTAS)语句或CREATE DATABASE AS(CDAS)语句将MongoDB中的数据同步至目标表中。
重要使用CTAS或CDAS语句将MongoDB中的数据同步至目标表时,必须满足以下要求:
VVR版本必须为8.0.6及以上,MongoDB数据库版本必须为6.0及以上。
在SQL Hints中已将scan.incremental.snapshot.enabled和scan.full-changelog参数都设置为true。
MongoDB数据库已开启前像后像(Pre- and Post-images)记录功能,开启方法参见Document Preimages。
单表同步,实时同步数据。
CREATE TABLE IF NOT EXISTS `${target_table_name}` WITH(...) AS TABLE `${mongodb_catalog}`.`${db_name}`.`${collection_name}` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */;在一个作业中同步多张表。
BEGIN STATEMENT SET; CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table0` AS TABLE `mongodb-catalog`.`database`.`collection0` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */; CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table1` AS TABLE `mongodb-catalog`.`database`.`collection1` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */; CREATE TABLE IF NOT EXISTS `some_catalog`.`some_database`.`some_table2` AS TABLE `mongodb-catalog`.`database`.`collection2` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */; END;结合MongoDB Catalog,您可以在同一个任务中同步多个MongoDB集合,但需要满足以下条件:
每张表关于MongoDB的配置必须完全相同,包括hosts、scheme、username、password、connectionOptions。
每张表的scan.startup.mode配置必须完全相同。
同步整库。
CREATE DATABASE IF NOT EXISTS `some_catalog`.`some_database` AS DATABASE `mongodb-catalog`.`database` /*+ OPTIONS('scan.incremental.snapshot.enabled'='true', 'scan.full-changelog'='true') */;
从MongoDB维表中读取数据。
INSERT INTO ${other_sink_table} SELECT ... FROM ${other_source_table} AS e JOIN `${mysql_catalog}`.`${db_name}`.`${table_name}` FOR SYSTEM_TIME AS OF e.proctime AS w ON e.id = w.id;写入结果数据至MongoDB表中。
INSERT INTO `${mysql_catalog}`.`${db_name}`.`${table_name}` SELECT ... FROM ${other_source_table}
删除MongoDB Catalog
删除MongoDB Catalog不会影响已运行的作业,但会导致使用该Catalog下表的作业,在上线或重启时报无法找到该表的错误,请您谨慎操作。
在数据查询文本编辑区域,输入以下命令。
DROP CATALOG ${catalog_name};其中${catalog_name}为您要删除的目标MongoDB Catalog名称。
选中删除Catalog的命令,鼠标右键选择运行。
在左侧元数据区域,查看目标Catalog是否已删除。
从MongoDB Catalog获取的表信息详解
为了方便使用MongoDB Catalog获取的表,MongoDB Catalog会在推导的表上添加默认的配置参数和主键信息。MongoDB Catalog在解析Bson文档获取集合的Schema时,Catalog会尝试获取最多max.fetch.records条数据,解析每条数据的Schema,再将这些Schema合并作为最终的Schema。Schema主要包含以下部分:
推导的物理列(Physical Columns)
MongoDB Catalog会从Bson文档推导出数据的物理列。
默认添加的主键约束
从MongoDB Catalog获取的表,会默认把_id列作为主键,确保数据不重复。
当拉取到一组Bson文档后,Catalog会逐条解析Bson文档并按以下规则合并解析出的物理列,从而作为整个集合的Schema。合并规则如下:
如果解析出的物理列中包含结果Schema中没有的字段,则MongoDB Catalog会自动将这些字段加入到结果Schema。
如果两者出现了同名列,则按照以下场景进行处理:
当类型相同且精度不同时,会取两者中较大的精度的类型。
当类型不同时,会按照如下图的树型结构找到最小父节点,作为该同名列的类型。但当Decimal和Float类型合并时,为了保留精度会合并为Double类型。

在推导Schema时,Bson类型与Flink类型的映射关系如下:
Bson类型 | Flink SQL类型 |
Boolean | BOOLEAN |
Int32 | INT |
Int64 | BIGINT |
Binary | BYTES |
Double | DOUBLE |
Decimal128 | DECIMAL |
String | STRING |
ObjectId | STRING |
DateTime | TIMESTAMP_LTZ(3) |
Timestamp | TIMESTAMP_LTZ(0) |
Array | STRING |
Document | STRING |
相关文档
MongoDB连接器的使用详情,请参见MongoDB。
如果内置的Catalog无法满足您的业务需求,您可以使用自定义Catalog,详情请参见管理自定义Catalog。