
本文介绍如何使用消息队列Kafka连接器。
背景信息
Apache Kafka是一款开源的分布式消息队列系统,广泛用于高性能数据处理、流式分析、数据集成等大数据领域。Kafka连接器基于开源Apache Kafka客户端,为阿里云实时计算Flink提供高性能的数据吞吐、多种数据格式的读写和精确一次语义的支持。
类别 | 详情 |
支持类型 | 源表和结果表,数据摄入目标端 |
运行模式 | 流模式 |
数据格式 | |
特有监控指标 | |
API种类 | SQL,Datastream和数据摄入YAML |
是否支持更新或删除结果表数据 | 不支持更新和删除结果表数据,只支持插入数据。 说明 更新和删除数据相关功能请参见Upsert Kafka。 |
前提条件
请根据需求选择以下任意一种方式连接集群:
连接阿里云云消息队列Kafka版集群
Kafka集群版本在0.11及以上。
云消息队列 Kafka 版集群已创建。详情请参见创建资源。
Flink工作空间与Kafka集群处于同一VPC内,且云消息队列 Kafka 版已对Flink开放白名单,具体操作请参见配置白名单。
重要写入阿里云Kafka的限制:
阿里云Kafka不支持zstd压缩格式写入。
阿里云Kafka不支持幂等和事务写入,无法使用Kafka结果表提供的精确一次语义exactly-once semantic功能。自实时计算引擎VVR 8.0.0版本起,Kafka Connector 使用的开源Kafka client版本升级到3.x版本,
该Client的properties.enable.idempotence属性默认值从false变为true表示显示开启幂等写入, 因此在使用实时计算引擎VVR 8.0.0及以上版本写入阿里云Kafka时,需要在结果表中添加显示配置properties.enable.idempotence=false以关闭幂等写入功能,避免无法写入阿里云Kafka的问题。阿里云Kafka的存储引擎对比与功能限制参见存储引擎对比。
连接自建Apache Kafka集群
注意事项
目前不推荐使用事务写入,这是 Flink 社区和 Kafka 社区的设计缺陷所致。当设置sink.delivery-guarantee = exactly-once,Kafka Connector 会启用事务写入,存在三个已知问题:
每个 Checkpoint 会生成一个 Transaction ID。如果 Checkpoint 间隔太短,Transaction ID会过多。Kafka 集群的 Coordinator 可能因此内存不足,从而破坏 Kafka 集群的稳定性。
每个事务会创建一个 Producer 实例。如果同时提交的事务太多,TaskManager 的内存可能耗尽,从而破坏 Flink 作业的稳定性。
多个 Flink 作业若使用相同的
sink.transactional-id-prefix,它们生成的事务 ID 可能冲突。一个作业写入失败时,会阻塞 Kafka 分区的 LSO(Log Start Offset)前进,这会影响所有消费者读取该分区的数据。
如果你需要 Exactly-Once 语义,改用 Upsert Kafka 写入主键表,并用主键保证幂等性。如果需要使用事务写入,请参见EXACTLY_ONCE语义注意事项。
网络连接排查
Flink作业启动时若报错Timed out waiting for a node assignment,通常是因为 Flink 与 Kafka 之间网络不通。
Kafka 客户端连接服务端如下所示:
客户端用
bootstrap.servers中的地址连接 Kafka。Kafka 返回集群中各 broker 的元数据,包括它们的连接地址。
客户端再用这些返回的地址连接各 broker,进行读写。
即使bootstrap.servers地址能通,若 Kafka 返回的 broker 地址错误,客户端仍无法读写。这类问题常出现在使用代理、端口转发或专线等网络架构中。
排查步骤
消息队列Kafka
自建Kafka(ECS)
使用Flink开发控制台进行网络探测。
排除
bootstrap.servers地址连通性问题,确认内外网接入点正确性。检查安全组与白名单
ECS 安全组必须放行 Kafka 接入点端口(通常为 9092 或 9093)。
ECS 实例需将 Flink 所在VPC加入白名单,详情请参见查看VPC网段。
配置排查
登录 Kafka 所用的 ZooKeeper 集群,使用 zkCli.sh 或 zookeeper-shell.sh工具。
执行命令获取 broker 元数据。例如:
get /brokers/ids/0。在返回结果的endpoints字段中,找到 Kafka 向客户端通告的地址。
Flink开发控制台进行网络探测,测试该地址是否可达。
说明若不可达,请 Kafka 运维人员检查并修正
listeners和advertised.listeners配置,确保返回的地址对 Flink 可访问。更多关于Kafka客户端与服务端的连接信息,请参见Troubleshoot Connectivity。
检查 SASL 配置(如启用)
若使用 SASL_SSL接入点,必须在 Flink 作业中正确配置 JAAS、SSL 与 SASL 机制。缺少认证会导致连接在握手阶段失败,也可能表现为超时,详情请参见安全与认证。
SQL
Kafka连接器可以在SQL作业中使用,作为源表或者结果表。
语法结构
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL
) WITH (
'connector' = 'kafka',
'topic' = 'user_behavior',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'testGroup',
'scan.startup.mode' = 'earliest-offset',
'format' = 'csv'
)元信息列
可以在源表和结果表中定义元信息列,以获取或写入Kafka消息的元信息。例如,当WITH参数中定义了多个topic时,如果在Kafka源表中定义了元信息列,那么Flink读取到的数据就会被标识是从哪个topic中读取的数据。元信息列的使用示例如下。
CREATE TABLE kafka_source (
--读取消息所属的topic作为`record_topic`字段
`record_topic` STRING NOT NULL METADATA FROM 'topic' VIRTUAL,
--读取ConsumerRecord中的时间戳作为`ts`字段
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL,
--读取消息的offset作为`record_offset`字段
`record_offset` BIGINT NOT NULL METADATA FROM 'offset' VIRTUAL,
...
) WITH (
'connector' = 'kafka',
...
);
CREATE TABLE kafka_sink (
--将`ts`字段中的时间戳作为ProducerRecord的时间戳写入Kafka
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp' VIRTUAL,
...
) WITH (
'connector' = 'kafka',
...
);下表列出了Kafka源表和结果表所支持的元信息列。
Key | 数据类型 | 说明 | 源表或结果表 |
topic | STRING NOT NULL METADATA VIRTUAL | Kafka消息所在的Topic名称。 | 源表 |
partition | INT NOT NULL METADATA VIRTUAL | Kafka消息所在的Partition ID。 | 源表 |
headers | MAP<STRING, BYTES> NOT NULL METADATA VIRTUAL | Kafka消息的消息头(header)。 | 源表和结果表 |
leader-epoch | INT NOT NULL METADATA VIRTUAL | Kafka消息的Leader epoch。 | 源表 |
offset | BIGINT NOT NULL METADATA VIRTUAL | Kafka消息的偏移量(offset)。 | 源表 |
timestamp | TIMESTAMP(3) WITH LOCAL TIME ZONE NOT NULL METADATA VIRTUAL | Kafka消息的时间戳。 | 源表和结果表 |
timestamp-type | STRING NOT NULL METADATA VIRTUAL | Kafka消息的时间戳类型:
| 源表 |
__raw_key__ | STRING NOT NULL METADATA VIRTUAL | Kafka原始消息的Key字段。 | 源表和结果表 说明 仅VVR 11.4及以上版本支持该参数。 |
__raw_value__ | STRING NOT NULL METADATA VIRTUAL | Kafka原始消息的Value字段。 | 源表和结果表 说明 仅VVR 11.4及以上版本支持该参数。 |
WITH参数
通用
参数
说明
数据类型
是否必填
默认值
备注
connector
表类型。
String
是
无
固定值为kafka。
properties.bootstrap.servers
Kafka broker地址。
String
是
无
格式为host:port,host:port,host:port,以英文逗号(,)分割。
properties.*
对Kafka客户端的直接配置。
String
否
无
Flink会将properties.前缀移除,并将剩余的配置传递给Kafka客户端。例如可以通过
'properties.allow.auto.create.topics'='false'来禁用自动创建topic。不能通过该方式修改以下配置,因为它们会被Kafka连接器覆盖:
key.deserializer
value.deserializer
format
读取或写入Kafka消息value部分时使用的格式。
String
否
无
支持的格式
csv
json
avro
debezium-json
canal-json
maxwell-json
avro-confluent
raw
说明更多format参数设置请参见Format参数。
key.format
读取或写入Kafka消息key部分时使用的格式。
String
否
无
支持的格式
csv
json
avro
debezium-json
canal-json
maxwell-json
avro-confluent
raw
说明使用该配置时,key.options配置是必填的。
key.fields
Kafka消息key部分对应的源表或结果表字段。
String
否
无
多个字段名以分号(;)分隔。例如
field1;field2key.fields-prefix
为所有Kafka消息key部分指定自定义前缀,以避免与消息value部分格式字段重名。
String
否
无
该配置项仅用于源表和结果表的列名区分,解析和生成Kafka消息key部分时,该前缀会被移除。
说明使用该配置时,
value.fields-include必须配置为EXCEPT_KEY。value.format
读取或写入Kafka消息value部分时使用的格式。
String
否
无
该配置等同于
format,只能设置format或value.format中的一个。如果同时配置,value.format会覆盖format。value.fields-include
在解析或生成Kafka消息value部分时,是否要包含消息key部分对应的字段。
String
否
ALL
参数取值如下:
ALL(默认值):所有列都会作为Kafka消息value部分处理EXCEPT_KEY:除去key.fields定义的字段,剩余字段作为Kafka消息value部分处理
源表
参数
说明
数据类型
是否必填
默认值
备注
topic
读取的topic名称。
String
否
无
以英文分号 (;) 分隔多个topic名称,例如topic-1和topic-2
说明topic和topic-pattern两个选项只能指定其中一个。
topic-pattern
匹配读取topic名称的正则表达式。所有匹配该正则表达式的topic在作业运行时均会被读取。
String
否
无
说明topic和topic-pattern两个选项只能指定其中一个。
properties.group.id
消费组ID。
String
否
KafkaSource-{源表表名}
如果指定的group id为首次使用,则必须将properties.auto.offset.reset设置为earliest或latest以指定首次启动位点。
scan.startup.mode
Kafka读取数据的启动位点。
String
否
group-offsets
取值如下:
earliest-offset:从Kafka最早的分区开始读取。latest-offset:从Kafka最新位点开始读取。group-offsets(默认值):从指定的properties.group.id已提交的位点开始读取。timestamp:从scan.startup.timestamp-millis指定的时间戳开始读取。specific-offsets:从scan.startup.specific-offsets指定的偏移量开始读取。
说明该参数在作业无状态启动时生效。作业在从checkpoint重启或状态恢复时,会优先使用状态中保存的进度恢复读取。
scan.startup.specific-offsets
specific-offsets启动模式下,指定每个分区的启动偏移量。
String
否
无
例如
partition:0,offset:42;partition:1,offset:300scan.startup.timestamp-millis
timestamp启动模式下,指定启动位点时间戳。
Long
否
无
单位为毫秒
scan.topic-partition-discovery.interval
动态检测Kafka topic和partition的时间间隔。
Duration
否
5分钟
分区检查间隔默认为5分钟。需要显式地设置分区检查间隔为非正数才能关闭此功能。开启动态分区发现后,Kafka Source 可以自动地发现新增的分区并自动读取对应分区上的数据。在topic-pattern模式下,不仅读取已有topic的新增分区数据,也会读取符合正则匹配的新增topic的所有分区数据。
说明在实时计算引擎VVR 6.0.x版本中,动态分区检测默认为关闭。自8.0版本起该功能默认打开,检测间隔默认设置为5分钟。
scan.header-filter
根据Kafka数据是否包含指定的消息头(Header)对数据进行条件过滤。
String
否
无
Header key和value使用冒号(:)分隔,多个header条件之间使用逻辑运算符(&、|)连接,支持取反逻辑运算符(!)。例如
depart:toy|depart:book&!env:test表示保留header中包含depart=toy或depart=book,且不包含env=test的Kafka数据。说明仅实时计算引擎VVR 8.0.6及以上版本支持配置该参数。
暂不支持括号运算。
逻辑运算顺序为从左至右。
Header value会以UTF-8格式转换为字符串,与参数指定的header value进行比较。
scan.check.duplicated.group.id
是否检查通过
properties.group.id指定的消费者组有重复。Boolean
否
false
参数取值如下:
true:在启动作业前,系统会检查消费者组是否存在重复。若发现重复,作业将报错并停止运行,从而避免与现有消费者组产生冲突。
false:直接启动作业,不检查消费者组冲突。
说明仅VVR 6.0.4及以上版本支持该参数。
结果表
参数
说明
数据类型
是否必填
默认值
备注
topic
写入的topic名称。
String
是
无
无
sink.partitioner
从Flink并发到Kafka分区的映射模式。
String
否
default
取值如下:
default(默认值):使用Kafka默认的分区模式
fixed:每个Flink并发对应一个固定的Kafka分区。
round-robin:Flink并发中的数据将被轮流分配至Kafka的各个分区。
自定义分区映射模式:如果fixed和round-robin不满足需求,可以创建一个FlinkKafkaPartitioner的子类来自定义分区映射模式。例如org.mycompany.MyPartitioner
sink.delivery-guarantee
Kafka结果表的语义模式。
String
否
at-least-once
取值如下:
none:不保证任何语义,数据可能会丢失或重复。
at-least-once(默认值):保证数据不丢失,但可能会重复。
exactly-once:使用Kafka事务保证数据不会丢失和重复。
说明在使用exactly-once语义时,sink.transactional-id-prefix是必填的。
sink.transactional-id-prefix
在exactly-once语义下使用的Kafka事务ID前缀。
String
否
无
只有sink.delivery-guarantee配置为exactly-once时该配置才会生效。
sink.parallelism
Kafka结果表算子的并发数。
Integer
否
无
上游算子的并发,由框架决定。
安全与认证
如果Kafka集群要求安全连接或认证,请将相关的安全与认证配置添加properties.前缀后设置在WITH参数中。配置Kafka表以使用PLAIN作为SASL机制,并提供JAAS配置的示例如下。
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
...
'properties.security.protocol' = 'SASL_PLAINTEXT',
'properties.sasl.mechanism' = 'PLAIN',
'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule required username="username" password="password";'
)使用SASL_SSL作为安全协议,并使用SCRAM-SHA-256作为SASL机制的示例如下。
CREATE TABLE KafkaTable (
`user_id` BIGINT,
`item_id` BIGINT,
`behavior` STRING,
`ts` TIMESTAMP_LTZ(3) METADATA FROM 'timestamp'
) WITH (
'connector' = 'kafka',
...
'properties.security.protocol' = 'SASL_SSL',
/*SSL配置*/
/*配置服务端提供的truststore (CA 证书) 的路径*/
/*文件管理上传的文件会存放在/flink/usrlib/路径下*/
'properties.ssl.truststore.location' = '/flink/usrlib/kafka.client.truststore.jks',
'properties.ssl.truststore.password' = 'test1234',
/*如果要求客户端认证,则需要配置keystore (私钥) 的路径*/
'properties.ssl.keystore.location' = '/flink/usrlib/kafka.client.keystore.jks',
'properties.ssl.keystore.password' = 'test1234',
/*客户端验证服务器地址的算法,空值表示禁用服务器地址验证*/
'properties.ssl.endpoint.identification.algorithm' = '',
/*SASL配置*/
/*将SASL机制配置为as SCRAM-SHA-256*/
'properties.sasl.mechanism' = 'SCRAM-SHA-256',
/*配置JAAS*/
'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.scram.ScramLoginModule required username="username" password="password";'
)示例中提到的CA证书和私钥可使用实时计算控制台的文件管理功能上传至平台。上传后文件存放在/flink/usrlib目录下,需要使用的CA证书文件名为my-truststore.jks,则上传后在WITH参数中有两种方式可以设置'properties.ssl.truststore.location'来使用该证书:
配置
'properties.ssl.truststore.location' = '/flink/usrlib/my-truststore.jks',采用这种方式Flink运行期间不需要动态下载OSS文件,但是不支持调试模式。实时计算引擎版本为 VVR 11.5 及以上,可以配置
properties.ssl.truststore.location和properties.ssl.keystore.location为OSS绝对路径地址,文件路径格式为oss://flink-fullymanaged-<工作空间ID>/artifacts/namespaces/<项目空间名称>/<文件名>。采用这种方式会在Flink运行期间动态下载OSS文件,支持调试模式。
配置确认:上文中的示例仅适用于大多数配置情况。在配置Kafka连接器前,请与Kafka服务端运维人员联系,以获取正确的安全与认证配置信息。
转义说明:与开源Flink不同,实时计算Flink版的SQL编辑器默认已经对双引号(")进行转义处理,因此在配置
properties.sasl.jaas.config时无需对用户名和密码中的双引号(")添加额外的转义符(\)。
源表起始位点
启动模式
Kafka源表可通过配置scan.startup.mode来指定初始读取位点:
最早位点(earliest-offset):从当前分区的最早位点开始读取。
最末尾位点(latest-offset):从当前分区的最末尾位点开始读取。
已提交位点(group-offsets):从指定group id的已提交位点开始读取,group id通过properties.group.id指定。
指定时间戳(timestamp):从时间戳大于等于指定时间的第一条消息开始读取,时间戳通过scan.startup.timestamp-millis指定。
特定位点(specific-offsets):从指定的分区位点开始消费,位点通过scan.startup.specific-offsets指定。
如果不指定启动位点,则默认会从已提交位点(group-offsets)启动消费。
scan.startup.mode只针对无状态启动的作业生效,有状态作业启动时会从状态中存储的位点开始消费。
代码示例如下:
CREATE TEMPORARY TABLE kafka_source (
...
) WITH (
'connector' = 'kafka',
...
--从最早位点开始消费
'scan.startup.mode' = 'earliest-offset',
--从最末尾位点开始消费
'scan.startup.mode' = 'latest-offset',
--从消费者组"my-group"的已提交位点开始消费
'properties.group.id' = 'my-group',
'scan.startup.mode' = 'group-offsets',
'properties.auto.offset.reset' = 'earliest', -- 如果 "my-group" 为首次使用,则从最早位点开始消费
'properties.auto.offset.reset' = 'latest', -- 如果 "my-group" 为首次使用,则从最末尾位点开始消费
--从指定的毫秒时间戳1655395200000开始消费
'scan.startup.mode' = 'timestamp',
'scan.startup.timestamp-millis' = '1655395200000',
--从指定位点开始消费
'scan.startup.mode' = 'specific-offsets',
'scan.startup.specific-offsets' = 'partition:0,offset:42;partition:1,offset:300'
);起始位点优先级
源表起始位点的优先级为:
优先级从高到低 | Checkpoint或Savepoint中存储的位点 |
实时计算控制台作业启动选择的启动时间 | |
WITH参数中通过scan.startup.mode指定的启动位点 | |
未指定scan.startup.mode的情况下使用group-offsets,使用对应消费组的位点 |
在以上任何一个步骤中,如果位点过期或Kafka集群发生问题等原因导致位点无效,则会使用properties.auto.offset.reset指定的策略进行位点重置,如果未设置该配置项,则会产生异常要求用户介入。
一种常见情况是使用全新的group id开始消费。首先源表会向Kafka集群查询该group的已提交位点,由于该group id是第一次使用,不会查询到有效位点,所以会通过properties.auto.offset.reset参数配置的策略进行重置。因此在使用全新group id进行消费时,必须配置properties.auto.offset.reset来指定位点重置策略。
源表位点提交
Kafka源表只在checkpoint成功后将当前消费位点提交至Kafka集群。如果checkpoint间隔设置较长,在Kafka集群侧观察到的消费位点会有延迟。在进行checkpoint时,Kafka源表会将当前读取进度存储在状态中,并不依赖于提交到集群上的位点进行故障恢复,提交位点仅仅是为了在Kafka侧能够监控到读取进度,位点提交失败不会对数据正确性产生任何影响。
结果表自定义分区器
如果内置的Kafka Producer分区模式无法满足需求,可以实现自定义分区模式将数据写入对应的分区。自定义分区器需要继承FlinkKafkaPartitioner,开发完成后编译JAR包,使用文件管理功能上传至实时计算控制台。上传并引用完成后,请在WITH参数中设置sink.partitioner参数,参数值为分区器完整的类路径,如org.mycompany.MyPartitioner。
Kafka、Upsert Kafka或Kafka JSON catalog的选择
Kafka是一种只能添加数据的消息队列系统,无法进行数据的更新和删除操作,因此在流式SQL计算中无法处理上游的CDC变更数据和聚合、联合等算子的回撤逻辑。如果需要将含有变更或回撤类型的数据写入Kafka,请使用对变更数据进行特殊处理的Upsert Kafka结果表。
为了方便将上游数据库中一个或多个数据表中的变更数据批量同步到Kafka中,可以使用Kafka JSON catalog。如果Kafka中存储的数据格式为JSON,使用Kafka JSON catalog可以省去定义schema和WITH参数的步骤。详情可参见管理Kafka JSON Catalog。
使用示例
示例一:从Kafka中读取数据后写入Kafka
从名称为源表的Topic中读取Kafka数据,再写入名称为结果表的Topic,数据使用CSV格式。
CREATE TEMPORARY TABLE kafka_source (
id INT,
name STRING,
age INT
) WITH (
'connector' = 'kafka',
'topic' = 'source',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'properties.group.id' = '<yourKafkaConsumerGroupId>',
'format' = 'csv'
);
CREATE TEMPORARY TABLE kafka_sink (
id INT,
name STRING,
age INT
) WITH (
'connector' = 'kafka',
'topic' = 'sink',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'properties.group.id' = '<yourKafkaConsumerGroupId>',
'format' = 'csv'
);
INSERT INTO kafka_sink SELECT id, name, age FROM kafka_source;示例二:同步表结构以及数据
将Kafka Topic中的消息实时同步到Hologres中。在该情况下,可以将Kafka消息的offset和partition id作为主键,从而保证在Failover时,Hologres中不会有重复消息。
CREATE TEMPORARY TABLE kafkaTable (
`offset` INT NOT NULL METADATA,
`part` BIGINT NOT NULL METADATA FROM 'partition',
PRIMARY KEY (`part`, `offset`) NOT ENFORCED
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'topic' = 'kafka_evolution_demo',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json',
'json.infer-schema.flatten-nested-columns.enable' = 'true'
--可选,将嵌套列全部展开。
);
CREATE TABLE IF NOT EXISTS hologres.kafka.`sync_kafka`
WITH (
'connector' = 'hologres'
) AS TABLE vvp.`default`.kafkaTable;示例三:同步表结构以及Kafka消息的key和value数据
Kafka消息中的key部分已经存储了相关信息,可以同时同步Kafka中的key和value。
CREATE TEMPORARY TABLE kafkaTable (
`key_id` INT NOT NULL,
`val_name` VARCHAR(200)
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'topic' = 'kafka_evolution_demo',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'json',
'value.format' = 'json',
'key.fields' = 'key_id',
'key.fields-prefix' = 'key_',
'value.fields-prefix' = 'val_',
'value.fields-include' = 'EXCEPT_KEY'
);
CREATE TABLE IF NOT EXISTS hologres.kafka.`sync_kafka`(
WITH (
'connector' = 'hologres'
) AS TABLE vvp.`default`.kafkaTable;Kafka消息中的key部分不支持表结构变更和类型解析,需要手动声明。
示例四:同步表结构和数据并进行计算
在同步Kafka数据到Hologres时,往往需要一些轻量级的计算。
CREATE TEMPORARY TABLE kafkaTable (
`distinct_id` INT NOT NULL,
`properties` STRING,
`timestamp` TIMESTAMP_LTZ METADATA,
`date` AS CAST(`timestamp` AS DATE)
) WITH (
'connector' = 'kafka',
'properties.bootstrap.servers' = '<yourKafkaBrokers>',
'topic' = 'kafka_evolution_demo',
'scan.startup.mode' = 'earliest-offset',
'key.format' = 'json',
'value.format' = 'json',
'key.fields' = 'key_id',
'key.fields-prefix' = 'key_'
);
CREATE TABLE IF NOT EXISTS hologres.kafka.`sync_kafka` WITH (
'connector' = 'hologres'
) AS TABLE vvp.`default`.kafkaTable
ADD COLUMN
`order_id` AS COALESCE(JSON_VALUE(`properties`, '$.order_id'), 'default');
--使用COALESCE处理空值情况。示例五:嵌套JSON解析
JSON消息示例
{
"id": 101,
"name": "VVP",
"properties": {
"owner": "阿里云",
"engine": "Flink"
}
}为避免后续使用 JSON_VALUE(payload, '$.properties.owner') 等函数解析字段,可直接在 Source DDL 中定义结构:
CREATE TEMPORARY TABLE kafka_source (
id VARCHAR,
`name` VARCHAR,
properties ROW<`owner` STRING, engine STRING>
) WITH (
'connector' = 'kafka',
'topic' = 'xxx',
'properties.bootstrap.servers' = 'xxx',
'scan.startup.mode' = 'earliest-offset',
'format' = 'json'
);这样,Flink会在读取阶段一次性将 JSON 解析为结构化字段,后续 SQL 查询直接使用 properties.owner,无需额外函数调用,整体性能更优。
Datastream API
通过DataStream的方式读写数据时,则需要使用对应的DataStream连接器连接实时计算Flink版,DataStream连接器设置方法请参见DataStream连接器使用方法。
构建Kafka Source
Kafka Source提供了构建类来创建Kafka Source的实例。我们将通过以下示例代码介绍如何构建Kafka Source来消费input-topic最早位点的数据,消费组名称为my-group,并将Kafka消息体反序列化为字符串。
Java
KafkaSource<String> source = KafkaSource.<String>builder() .setBootstrapServers(brokers) .setTopics("input-topic") .setGroupId("my-group") .setStartingOffsets(OffsetsInitializer.earliest()) .setValueOnlyDeserializer(new SimpleStringSchema()) .build(); env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");在构建KafkaSource时,必须指定以下参数。
参数
说明
BootstrapServers
Kafka Broker地址,通过setBootstrapServers(String)方法配置。
GroupId
消费者组ID,通过setGroupId(String)方法配置。
Topics或Partition
订阅的Topic或Partition名称。Kafka Source提供了以下三种Topic或Partition的订阅方式:
Topic列表,订阅Topic列表中所有Partition。
KafkaSource.builder().setTopics("topic-a","topic-b")正则表达式匹配,订阅与正则表达式所匹配的Topic下的所有Partition。
KafkaSource.builder().setTopicPattern("topic.*")Partition列表,订阅指定的Partition。
final HashSet<TopicPartition> partitionSet = new HashSet<>(Arrays.asList( new TopicPartition("topic-a", 0), // Partition 0 of topic "topic-a" new TopicPartition("topic-b", 5))); // Partition 5 of topic "topic-b" KafkaSource.builder().setPartitions(partitionSet)
Deserializer
解析Kafka消息的反序列化器。
反序列化器通过setDeserializer(KafkaRecordDeserializationSchema)来指定,其中KafkaRecordDeserializationSchema定义了如何解析Kafka的ConsumerRecord。如果只解析Kafka消息中的消息体(Value)的数据,可以通过以下任何一种方式实现:
使用Flink提供的KafkaSource构建类中的setValueOnlyDeserializer(DeserializationSchema)方法,其中DeserializationSchema定义了如何解析Kafka消息体中的二进制数据。
使用Kafka提供的解析器,包括多种实现类。例如,可以使用StringDeserializer来将Kafka消息体解析成字符串。
import org.apache.kafka.common.serialization.StringDeserializer; KafkaSource.<String>builder() .setDeserializer(KafkaRecordDeserializationSchema.valueOnly(StringDeserializer.class));
说明如果需要完整地解析ConsumerRecord,则需要自行实现KafkaRecordDeserializationSchema接口。
XML
Maven中央库中已经放置了Kafka DataStream连接器。
<dependency> <groupId>com.alibaba.ververica</groupId> <artifactId>ververica-connector-kafka</artifactId> <version>${vvr-version}</version> </dependency>在使用Kafka DataStream连接器时,需要了解以下Kafka属性:
起始消费位点
Kafka Source能够通过位点初始化器(OffsetsInitializer)来指定从不同的偏移量开始消费。内置的位点初始化器包括以下内容。
位点初始化器
代码设置
从最早位点开始消费。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.earliest())从最末尾位点开始消费。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.latest())从时间戳大于等于指定时间的数据开始消费,单位为毫秒。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.timestamp(1592323200000L))从消费组提交的位点开始消费,如果提交位点不存在,使用最早位点。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.committedOffsets(OffsetResetStrategy.EARLIEST))从消费组提交的位点开始消费,不指定位点重置策略。
KafkaSource.builder().setStartingOffsets(OffsetsInitializer.committedOffsets())说明如果以上内置的初始化器不能满足需求,也可以自己实现自定义的位点初始化器。
如果未指定位点初始化器,则默认使用OffsetsInitializer.earliest(),即最早位点。
流模式和批模式
Kafka Source支持流式和批式两种运行模式。默认情况下,Kafka Source设置为以流模式运行,因此作业永远不会停止,直到Flink作业失败或被取消。如果要配置Kafka Source在批模式下运行,可以使用setBounded(OffsetsInitializer)指定停止偏移量,当所有分区都达到其停止偏移量时,Kafka Source会退出运行。
说明通常,流模式下Kafka Source没有停止偏移量。为了方便对代码进行调试,流模式下可以使用 setUnbounded(OffsetsInitializer) 指定停止偏移量。请留意指定流模式和批模式停止偏移量的方法名(setUnbounded 和 setBounded)是不同的。
动态分区检查
为了在不重启Flink作业的情况下,处理Topic扩容或新建Topic等场景,可以在提供的Topic或Partition订阅模式下,启用动态分区检查功能。DataStream连接器中,该功能默认关闭,需要手动显式配置开启:
KafkaSource.builder() .setProperty("partition.discovery.interval.ms", "10000") // 每10秒检查一次新分区。重要动态分区检查功能依赖于Kafka集群的元信息更新机制。如果Kafka集群未及时更新分区信息,可能导致新分区无法被发现。请确保Kafka集群的partition.discovery.interval.ms配置与实际情况匹配。
事件时间和水印
Kafka Source默认使用Kafka消息中的时间戳作为事件时间。可以自定义水印策略(Watermark Strategy)以从消息中提取事件时间,并向下游发送水印。
env.fromSource(kafkaSource, new CustomWatermarkStrategy(), "Kafka Source With Custom Watermark Strategy")如果需要了解自定义水印策略(Watermark Strategy),请参见Generating Watermarks。
说明若并行Source的部分任务长期处于空闲状态(如某个Kafka分区长时间无数据输入,或Source并发数超过Kafka分区数量),可能导致Watermark生成机制失效。此时系统将无法正常触发窗口计算,造成数据处理流程停滞。
为解决此类问题,可通过以下方式调整:
配置Watermark超时机制:启用table.exec.source.idle-timeout参数,强制系统在指定超时时间后生成Watermark,确保窗口计算周期的推进。
数据源优化:建议保持Kafka分区数与Source并发度的合理比例(推荐分区数≥Source并行度)。
消费位点提交
Kafka Source在Checkpoint完成时,提交当前的消费位点,以保证Flink的Checkpoint状态和Kafka Broker上的提交位点一致。如果未开启Checkpoint,Kafka Source依赖于Kafka Consumer内部的位点定时自动提交逻辑,自动提交功能由enable.auto.commit和 auto.commit.interval.ms两个Kafka Consumer配置项进行配置。
说明Kafka Source不依赖于Broker上提交的位点来恢复失败的作业。提交位点只是为了上报Kafka Consumer和消费组的消费进度,以在Broker端进行监控。
其他属性
除了上述属性之外,还可以使用setProperties(Properties) 和setProperty(String, String) 为Kafka Source和Kafka Consumer设置任意属性。KafkaSource通常有以下配置项。
配置项
说明
client.id.prefix
指定用于Kafka Consumer的客户端ID前缀。
partition.discovery.interval.ms
定义Kafka Source检查新分区的时间间隔。
说明partition.discovery.interval.ms会在批模式下被覆盖为-1。
register.consumer.metrics
指定是否在Flink中注册Kafka Consumer的指标。
其他Kafka Consumer配置
Kafka Consumer的配置详情,请参见Apache Kafka。
重要Kafka Connector会强制覆盖部分手动配置的参数项,覆盖详情如下:
key.deserializer始终被覆盖为ByteArrayDeserializer。
value.deserializer始终被覆盖为ByteArrayDeserializer。
auto.offset.reset.strategy被覆盖为OffsetsInitializer#getAutoOffsetResetStrategy()。
以下示例展示如何配置Kafka Consumer,以使用PLAIN作为SASL机制并提供JAAS配置。
KafkaSource.builder() .setProperty("sasl.mechanism", "PLAIN") .setProperty("sasl.jaas.config", "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";")监控
Kafka Source在Flink中注册指标,用于监控和诊断。
指标范围
Kafka source reader的所有指标都注册在KafkaSourceReader指标组下,KafkaSourceReader是operator指标组的子组。与特定主题分区相关的指标注册在KafkaSourceReader.topic.<topic_name>.partition.<partition_id>指标组中。
例如Topic "my-topic"、分区1的当前消费位点(currentOffset)注册在<some_parent_groups>.operator.KafkaSourceReader.topic.my-topic.partition.1.currentOffset。成功提交位点的次数(commitsSucceeded)注册在<some_parent_groups>.operator.KafkaSourceReader.commitsSucceeded。
指标列表
指标名称
描述
范围
currentOffset
当前消费位点
TopicPartition
committedOffset
当前提交位点
TopicPartition
commitsSucceeded
成功提交的次数
KafkaSourceReader
commitsFailed
失败的提交次数
KafkaSourceReader
Kafka Consumer指标
Kafka Consumer的指标注册在指标组KafkaSourceReader.KafkaConsumer。例如Kafka Consumer指标records-consumed-total注册在<some_parent_groups>.operator.KafkaSourceReader.KafkaConsumer.records-consumed-total。
可以使用配置项register.consumer.metrics配置是否注册Kafka消费者的指标。默认此选项设置为true。对于Kafka Consumer的指标,可参见Apache Kafka。
构建Kafka Sink
Flink Kafka Sink可以实现将流数据写入一个或多个Kafka Topic。
DataStream<String> stream = ... Properties properties = new Properties(); properties.setProperty("bootstrap.servers", ); KafkaSink<String> kafkaSink = KafkaSink.<String>builder() .setKafkaProducerConfig(kafkaProperties) // // producer config .setRecordSerializer( KafkaRecordSerializationSchema.builder() .setTopic("my-topic") // target topic .setKafkaValueSerializer(StringSerializer.class) // serialization schema .build()) .setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE) // fault-tolerance .build(); stream.sinkTo(kafkaSink);需要配置以下参数。
参数
说明
Topic
数据写入的默认Topic名称。
数据序列化
构建时需要提供
KafkaRecordSerializationSchema来将输入数据转换为 Kafka的ProducerRecord。Flink提供了schema构建器,以提供一些通用的组件,例如消息键(key)/消息体(value)序列化、topic选择、消息分区,同样也可以通过实现对应的接口来进行更丰富的控制。ProducerRecord<byte[], byte[]> serialize(T element, KafkaSinkContext context, Long timestamp)方法会在每条数据流入的时候调用,来生成ProducerRecord写入Kafka。用户可以对每条数据如何写入Kafka进行细粒度地控制。通过ProducerRecord可以进行以下操作:
设置写入的Topic名称。
定义消息键(Key)。
指定数据写入的Partition。
Kafka客户端属性
bootstrap.servers必填,以逗号分隔的Kafka Broker列表。
容错语义
启用Flink的Checkpoint后,Flink Kafka Sink可以保证精确一次的语义。除了启用Flink的Checkpoint外,还可以通过DeliveryGuarantee参数来指定不同的容错语义,DeliveryGuarantee参数详情如下:
DeliveryGuarantee.NONE:(默认设置)Flink不做任何保证,数据可能会丢失或重复。
DeliveryGuarantee.AT_LEAST_ONCE:保证不会丢失任何数据,但可能会重复。
DeliveryGuarantee.EXACTLY_ONCE:使用Kafka事务提供精确一次的语义保证。
说明使用EXACTLY_ONCE语义时,需要注意的事项请参见EXACTLY_ONCE语义注意事项。
数据摄入
Kafka连接器可以用于数据摄入YAML作业开发,作为源端读取或目标端写入。
使用限制
建议在实时计算引擎VVR 11.1及以上版本使用Kafka作为Flink CDC数据摄入的同步数据源。
仅支持JSON、Debezium JSON和Canal JSON格式,其他数据格式暂不支持。
对于数据源,仅实时计算引擎VVR 8.0.11及以上版本支持同一张表的数据分布在多个分区。
语法结构
source:
type: kafka
name: Kafka source
properties.bootstrap.servers: localhost:9092
topic: ${kafka.topic}sink:
type: kafka
name: Kafka Sink
properties.bootstrap.servers: localhost:9092配置项
通用
参数
说明
是否必填
数据类型
默认值
备注
type
源端或目标端类型。
是
String
无
固定值为kafka
name
源端或目标端名称。
否
String
无
无
properties.bootstrap.servers
Kafka broker地址。
是
String
无
格式为
host:port,host:port,host:port,以英文逗号(,)分割。properties.*
对Kafka客户端的直接配置。
否
String
无
Flink会将properties.前缀移除,并将剩余的配置传递给Kafka客户端。例如可以通过
'properties.allow.auto.create.topics' = 'false'来禁用自动创建topic。key.format
读取或写入Kafka消息key部分使用的格式。
否
String
无
对Source,仅支持json。
对Sink,取值如下:
csv
json
说明仅实时计算引擎VVR 11.0.0及以上版本支持该参数。
value.format
读取或写入Kafka消息value部分时使用的格式。
否
String
debezium-json
对Source,取值如下:
debezium-json
canal-json
json
对Sink,取值如下:
debezium-json
canal-json
canal-protobuf
说明仅实时计算引擎VVR 8.0.10及以上版本支持debezium-json和canal-json格式。
仅实时计算引擎VVR 11.0.0及以上版本支持json格式。
源表
参数
说明
是否必填
数据类型
默认值
备注
topic
读取的topic名称。
否
String
无
以英文分号 (;) 分隔多个topic名称,例如topic-1和topic-2
说明topic和topic-pattern两个选项只能指定其中一个。
topic-pattern
匹配读取topic名称的正则表达式。所有匹配该正则表达式的topic在作业运行时均会被读取。
否
String
无
说明topic和topic-pattern两个选项只能指定其中一个。
properties.group.id
消费组ID。
否
String
无
如果指定的group id为首次使用,则必须将properties.auto.offset.reset设置为earliest或latest以指定首次启动位点。
scan.startup.mode
Kafka读取数据的启动位点。
否
String
group-offsets
取值如下:
earliest-offset:从Kafka最早分区开始读取。
latest-offset:从Kafka最新位点开始读取。
group-offsets(默认值):从指定的properties.group.id已提交的位点开始读取。
timestamp:从scan.startup.timestamp-millis指定的时间戳开始读取。
specific-offsets:从scan.startup.specific-offsets指定的偏移量开始读取。
说明该参数在作业无状态启动时生效。作业在从checkpoint重启或状态恢复时,会优先使用状态中保存的进度恢复读取。
scan.startup.specific-offsets
specific-offsets启动模式下,指定每个分区的启动偏移量。
否
String
无
例如
partition:0,offset:42;partition:1,offset:300scan.startup.timestamp-millis
timestamp启动模式下,指定启动位点时间戳。
否
Long
无
单位为毫秒
scan.topic-partition-discovery.interval
动态检测Kafka topic和partition的时间间隔。
否
Duration
5分钟
分区检查间隔默认为5分钟。需要显式地设置分区检查间隔为非正数才能关闭此功能。开启动态分区发现后,Kafka Source 可以自动地发现新增的分区并自动读取对应分区上的数据。在topic-pattern模式下,不仅读取已有topic的新增分区数据,也会读取符合正则匹配的新增topic的所有分区数据。
scan.check.duplicated.group.id
是否检查通过
properties.group.id指定的消费者组有重复。否
Boolean
false
参数取值如下:
true:在启动作业前检查消费者组是否有重复,如有重复作业将会报错,避免与现有的消费者组产生冲突。
false:直接启动作业,不检查消费者组冲突。
schema.inference.strategy
Schema解析策略。
否
String
continuous
取值如下:
continuous:对每条数据均进行 Schema 解析。在前后 Schema 不兼容时,解析出更宽的 Schema 并产生 Schema 变更事件。
static:仅在作业启动时进行一次Schema解析,后续根据初始Schema解析数据,不会产生Schema变更事件。
说明Schema解析详情可见表结构解析和变更同步策略。
仅VVR 8.0.11及以上版本支持该配置项。
scan.max.pre.fetch.records
Schema初始解析时,对每个分区最多尝试消费解析的消息数量
否
Int
50
在作业实际读取并处理数据前,对每个分区尝试提前消费指定数量的最新消息,用于初始化Schema信息。
key.fields-prefix
自定义添加到消息键(Key)解析出字段名称的前缀,以避免Kafka消息键解析后的命名冲突问题。
否
String
无
假设该配置项设为key_,当key中包含字段名a时,解析key后该字段名称为key_a。
说明key.fields-prefix的配置值不可以是value.fields-prefix的前缀。
value.fields-prefix
自定义添加到消息体(Value)解析出字段名称的前缀,以避免Kafka消息体解析后的命名冲突问题。
否
String
无
假设该配置项设为value_,当value中包含字段名b时,解析value后该字段名称为value_b。
说明value.fields-prefix的配置值不可以是key.fields-prefix的前缀。
metadata.list
需要传递给下游的元数据列
否
String
无
可用的元数据列包括
topic、partition、offset、timestamp、timestamp-type、headers、leader-epoch,使用英文逗号分隔。scan.value.initial-schemas.ddls
通过DDL方式指定某些表的初始Schema。
否
String
无
多个DDL使用英文
;连接。例如,使用CREATE TABLE db1.t1 (id BIGINT, name VARCHAR(10)); CREATE TABLE db1.t2 (id BIGINT);为表db1.t1和表db1.t2分别指定初始Schema。这里的DDL表结构应当和写入目标表保持一致,并且满足Flink SQL的语法规则。
说明VVR 11.5及以上版本支持该配置。
ingestion.ignore-errors
是否忽略数据解析过程中的报错。
否
Boolean
false
说明VVR 11.5及以上版本支持该配置。
ingestion.error-tolerance.max-count
忽略数据解析过程报错时,累计多少次报错后作业失败。
否
Integer
-1
仅当ingestion.ignore-errors开启时生效,默认值-1表示解析异常不触发作业失败。
说明VVR 11.5及以上版本支持该配置。
源表 Debezium JSON 格式
参数
是否必填
数据类型
默认值
描述
debezium-json.distributed-tables
否
Boolean
false
如果Debezium JSON内单张表数据会出现在多个分区,则需要开启此选项。
说明仅VVR 8.0.11及以上版本支持该配置项。
重要修改该配置项后,需要无状态启动作业。
debezium-json.schema-include
否
Boolean
false
设置Debezium Kafka Connect时,可以启用Kafka配置value.converter.schemas.enable,以在消息中包含schema。此选项表明Debezium JSON消息是否包含schema。
参数取值如下:
true:Debezium JSON消息包含schema。
false:Debezium JSON消息不包含schema。
debezium-json.ignore-parse-errors
否
Boolean
false
参数取值如下:
true:当解析异常时,跳过当前行。
false(默认值):报出错误,作业启动失败。
debezium-json.infer-schema.primitive-as-string
否
Boolean
false
解析表结构时,是否解析所有类型为String类型。
参数取值如下:
true:解析所有基本类型为String。
false(默认值):按照基本规则进行解析。
源表 Canal JSON 格式
参数
是否必填
数据类型
默认值
描述
canal-json.distributed-tables
否
Boolean
false
如果Canal JSON内单张表数据会出现在多个分区,则需要开启此选项。
说明仅VVR 8.0.11及以上版本支持该配置项。
重要修改该配置项后,需要无状态启动作业。
canal-json.database.include
否
String
无
一个可选的正则表达式,通过正则匹配Canal记录中的database元字段,仅读取指定数据库的changelog记录。正则字符串与Java的Pattern兼容。
canal-json.table.include
否
String
无
一个可选的正则表达式,通过正则匹配Canal记录中的table元字段,仅读取指定表的changelog记录。正则字符串与Java的Pattern兼容。
canal-json.ignore-parse-errors
否
Boolean
false
参数取值如下:
true:当解析异常时,跳过当前行。
false(默认值):报出错误,作业启动失败。
canal-json.infer-schema.primitive-as-string
否
Boolean
false
解析表结构时,是否所有类型解析为String类型。
参数取值如下:
true:解析所有基本类型为String。
false(默认值):按照基本规则进行解析。
canal-json.infer-schema.strategy
否
String
AUTO
解析表结构时的解析策略。
参数取值如下:
AUTO(默认值):通过解析JSON数据自动解析。如果数据中不包含sqlType字段,建议使用AUTO以避免解析失败。
SQL_TYPE:通过canal json数据中的sqlType数组解析。如果数据包含sqlType字段时,建议将canal-json.infer-schema.strategy设置为SQL_TYPE以获得更精确的类型。
MYSQL_TYPE:通过canal json数据中的mysqlType数组解析。
当Kafka中的Canal JSON数据包含sqlType字段且需要更精确的类型映射时,建议将canal-json.infer-schema.strategy设置为SQL_TYPE。
sqlType类型映射规则请见Canal JSON的Schema解析。
说明VVR 11.1及以上版本支持该配置。
MYSQL_TYPE在VVR 11.3及以上版本支持使用。
canal-json.mysql.treat-mysql-timestamp-as-datetime-enabled
否
Boolean
true
是否将mysql timestamp类型映射到cdc timestamp类型:
true(默认):mysql timestamp类型映射到cdc timestamp类型。
false:mysql timestamp类型映射到cdc timestamp_ltz类型。
canal-json.mysql.treat-tinyint1-as-boolean.enabled
否
Boolean
true
使用MYSQL_TYPE解析时,是否将mysql tinyint(1)类型映射到cdc boolean类型:
true(默认):mysql tinyint(1)类型映射到cdc boolean类型。
false:mysql tinyint(1)类型映射到cdc tinyint(1)类型。
该配置仅当canal-json.infer-schema.strategy配置为MYSQL_TYPE时生效。
源表 JSON 格式
参数
是否必填
数据类型
默认值
描述
json.timestamp-format.standard
否
String
SQL
指定输入和输出时间戳格式。参数取值如下:
SQL:解析yyyy-MM-dd HH:mm:ss.s{precision}格式的输入时间戳,例如2020-12-30 12:13:14.123。
ISO-8601:解析yyyy-MM-ddTHH:mm:ss.s{precision}格式的输入时间戳,例如2020-12-30T12:13:14.123。
json.ignore-parse-errors
否
Boolean
false
参数取值如下:
true:当解析异常时,跳过当前行。
false(默认值):报出错误,作业启动失败。
json.infer-schema.primitive-as-string
否
Boolean
false
解析表结构时,是否解析所有类型为String类型。
参数取值如下:
true:解析所有基本类型为String。
false(默认值):按照基本规则进行解析。
json.infer-schema.flatten-nested-columns.enable
否
Boolean
false
解析JSON格式数据时,是否递归式地展开JSON中的嵌套列。参数取值如下:
true:递归式展开。
false(默认值):将嵌套列当作String处理。
json.decode.parser-table-id.fields
否
String
无
解析JSON格式数据时,是否使用部分JSON字段值生成tableId,多个字段使用英文
,连接。例如:JSON数据为{"col0":"a", "col1","b", "col2","c"},生成结果如下:配置
tableId
col0
a
col0,col1
a.b
col0,col1,col2
a.b.c
json.infer-schema.fixed-types
否
String
无
解析JSON格式数据时,指定某些字段的具体类型,多个字段使用英文
,连接。例如:id BIGINT, name VARCHAR(10)可以指定JSON数据中的id字段类型为BIGINT,name字段类型为VARCHAR(10)。说明VVR 11.5及以上版本支持该配置。
VVR 11.5版本使用该配置时,需要额外添加配置
scan.max.pre.fetch.records: 0。
结果表
参数
说明
是否必填
数据类型
默认值
备注
type
目标端类型。
是
String
无
固定值为kafka
name
目标端名称。
否
String
无
无
topic
Kafka Topic名称。
否
String
无
开启时,所有的数据都会写入这个Topic。
说明如果没有开启,每条数据会写入到其TableID对应字符串(通过
.拼接生成)的Topic,例如databaseName.tableName。partition.strategy
数据写入Kafka分区的策略。
否
String
all-to-zero
取值如下:
all-to-zero(默认值):将所有数据写入 0 号分区。
hash-by-key:根据主键的哈希值将数据写到多个分区。保证同一个主键的数据在同一个分区并且有序。
sink.tableId-to-topic.mapping
上游表名到下游 Kafka Topic名的映射关系。
否
String
无
每个映射关系由
;分割,上游表的表名和下游 Kafka 的Topic名由:分割,表名可以使用正则表达式,映射到同一个topic的多张表可以使用,拼接。例如mydb.mytable1:topic1;mydb.mytable2:topic2。说明配置这个参数能够在保留原始表名信息的同时修改映射的Topic。
结果表Debezium JSON格式
参数
是否必填
数据类型
默认值
描述
debezium-json.include-schema.enabled
否
Boolean
false
Debezium JSON数据中是否包含Schema信息。
debezium-json.emit.full-table-id.enabled
否
Boolean
false
是否将完整的三段式Table ID写入Debezium JSON元数据字段中。
启用此参数时的映射关系为:
CDC Table ID部分
Debezium JSON键
Namespace
dbSchema
schemaTable
table禁用此参数时的映射关系为:
CDC Table ID部分
Debezium JSON键
Namespace
无
Schema
dbTable
table说明VVR 11.6及以上版本支持此配置。
使用示例
使用 Kafka 作为数据摄入源端:
source: type: kafka name: Kafka source properties.bootstrap.servers: ${kafka.bootstraps.server} topic: ${kafka.topic} value.format: ${value.format} scan.startup.mode: ${scan.startup.mode} sink: type: hologres name: Hologres sink endpoint: <yourEndpoint> dbname: <yourDbname> username: ${secret_values.ak_id} password: ${secret_values.ak_secret} sink.type-normalize-strategy: BROADEN使用 Kafka 作为数据摄入目标端:
source: type: mysql name: MySQL Source hostname: ${secret_values.mysql.hostname} port: ${mysql.port} username: ${secret_values.mysql.username} password: ${secret_values.mysql.password} tables: ${mysql.source.table} server-id: 8601-8604 sink: type: kafka name: Kafka Sink properties.bootstrap.servers: ${kafka.bootstraps.server} route: - source-table: ${mysql.source.table} sink-table: ${kafka.topic}其中,使用route模块以设置源表写入Kafka的Topic名称。
阿里云Kafka默认不开启自动创建Topic功能,参见自动化创建Topic相关问题,写入到阿里云Kafka时,需要预先创建对应的Topic,详情请参见步骤三:创建资源。
表结构解析和变更同步策略
Kafka连接器会维护当前已知的所有表的Schema。
表结构信息初始化
表结构信息包含字段和数据类型信息、库表信息和主键信息,这三种信息的初始化方式如下:
字段和数据类型信息
数据摄入作业能够根据数据自动推导出表的字段和数据类型信息,然而在某些场景下,您可能希望指定某些表的字段和类型,根据用户指定字段类型的粒度,表结构信息的初始化有以下三种配置策略:
完全由程序推导表结构
在读取Kafka数据前,Kafka连接器会预先在每个分区中尝试消费最多scan.max.pre.fetch.records条消息,解析每条数据的Schema,再将这些Schema合并,用于初始化表结构信息。后续在实际消费数据前会根据初始化的Schema产生对应的建表事件。
对于Debezium JSON和Canal JSON格式,表信息在具体消息中,提前消费的scan.max.pre.fetch.records条消息中可能包含了若干个表的数据,因此对每张表而言,提前消费的数据条数无法确定。预消费和初始化表结构信息只会在实际消费和处理每个分区的消息前进行一次,若后续有新表数据,该表的第一条数据解析出的表结构会作为初始表结构,不会重新预消费和初始化对应的表结构。
仅VVR 8.0.11及以上版本支持单表数据分布在多个分区,对于该场景需要将配置项debezium-json.distributed-tables或canal-json.distributed-tables设为true。
指定初始表结构
在某些场景下,您希望自行指定初始的表结构,例如将 Kafka 的数据写入到一张预先创建的下游表中。这时您可以通过添加scan.value.initial-schemas.ddls参数指定初始的表结构。配置示例如下:
source:
type: kafka
name: Kafka Source
properties.bootstrap.servers: host:9092
topic: test-topic
value.format: json
scan.startup.mode: earliest-offset
# 设置初始表结构
scan.value.initial-schemas.ddls: CREATE TABLE db1.t1 (id BIGINT, name VARCHAR(10)); CREATE TABLE db1.t2 (id BIGINT);这里的建表语句需要和目标表的表结构保持一致。这样,我们就为 db1.t1 这张表指定了 id 这个字段的初始类型为 BIGINT,name 这个字段的初始类型为 VARCHAR(10) ,为 db1.t2 这张表指定了 id 这个字段的初始类型为 BIGINT。
这里的建表语句使用的是 FlinkSQL 的语法。
指定字段设置为固定类型
在某些场景下,您希望固定特定字段的数据类型,例如对于某些可能被推导为 TIMESTAMP 类型的字段,您希望以字符串的格式下发,这时您可以通过添加json.infer-schema.fixed-types参数指定初始的表结构(仅在消息格式为 json 时有效)。配置示例如下:
source:
type: kafka
name: Kafka Source
properties.bootstrap.servers: host:9092
topic: test-topic
value.format: json
scan.startup.mode: earliest-offset
# 设置特定字段始终为固定类型
json.infer-schema.fixed-types: id BIGINT, name VARCHAR(10)
scan.max.pre.fetch.records: 0这样,我们就为所有的 id 字段指定了类型固定为 BIGINT,所有的 name 字段指定了类型固定为 VARCHAR(10)。
这里的类型与 FlinkSQL 的数据类型一致。
库表信息
对于Canal JSON和Debezium JSON格式,表信息由具体消息解析得到,包括数据库和表名。
对于JSON格式,默认配置下,表信息仅包含表名,即数据所在的topic名称。如果您的数据中包含库表信息,可以通过json.infer-schema.fixed-types指定库表信息所在的字段,我们会将这些字段映射到库名/表名中。配置示例如下:
source: type: kafka name: Kafka Source properties.bootstrap.servers: host:9092 topic: test-topic value.format: json scan.startup.mode: earliest-offset # 使用 col1 字段中的值作为库名,使用 col2 字段中的值作为表名 json.decode.parser-table-id.fields: col1,col2这样,我们会将每条数据下发到库名为col1字段的值,表名为col2字段的值的表中。
主键信息
对于Canal JSON格式,会根据JSON中的pkNames字段定义表的主键。
对于Debezium JSON和JSON格式,JSON中不包含主键信息,可以通过transform规则手动为表添加主键:
transform: - source-table: \.*.\.* projection: \* primary-keys: key1, key2
Schema解析和Schema变更
在表结构初始化完成后,若schema.inference.strategy配置为static,Kafka连接器会根据初始的表结构解析每个消息的消息体(Value),不会产生Schema变更事件。若schema.inference.strategy配置为continuous,Kafka连接器会解析每个Kafka消息的消息体,解析出消息的物理列,并与当前维护的Schema比对,若解析出的Schema与当前Schema不一致时,会尝试将Schema合并,同时生成对应的表结构变更事件,合并规则如下:
如果解析出的物理列中包含当前Schema中没有的字段,则会将这些字段加入到Schema中,同时产生新增可空列事件。
如果解析出的物理列中不包含当前Schema中已有的字段,该字段仍会保留,该列的数据会填充为NULL,不产生删除列事件。
如果两者出现了同名列,则按照以下场景进行处理:
当类型相同且精度不同时,会取两者中较大精度的类型,同时产生列类型变更事件。
当类型不同时,会按照如下图的树形结构找到最小父节点,作为该同名列的类型,同时产生列类型变更事件。
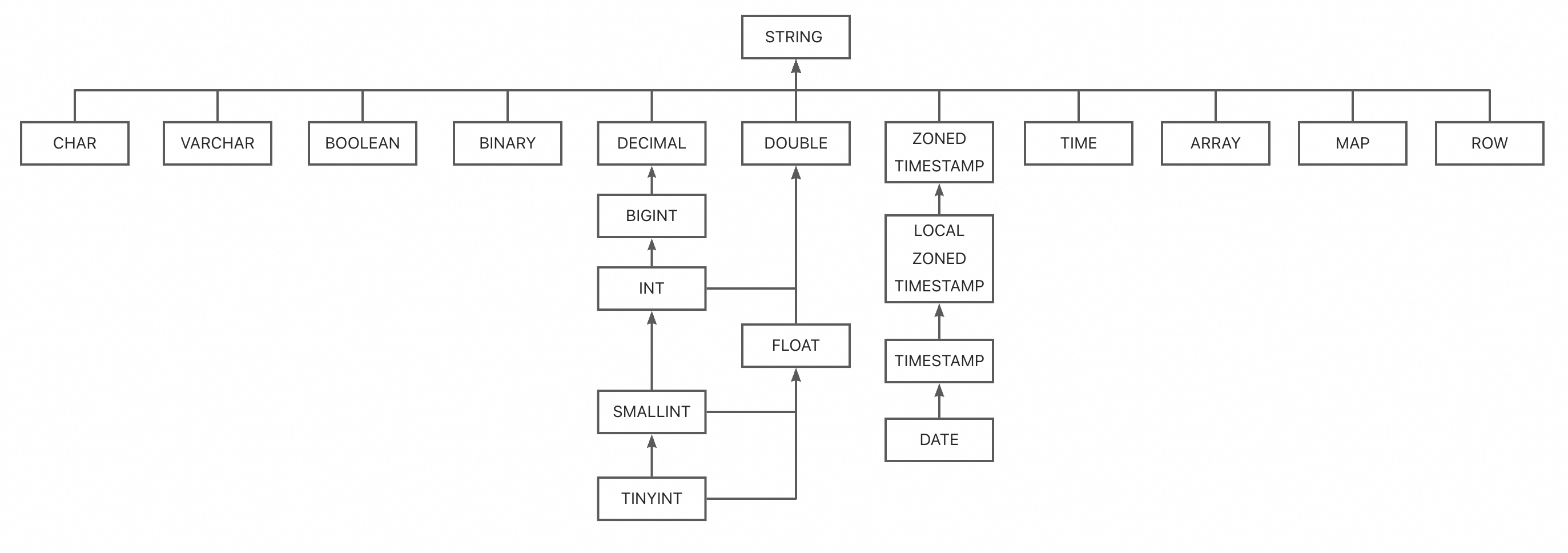
当前支持的Schema变更策略如下:
添加列:会在当前Schema末尾添加对应的列,并同步新增列的数据,新增的列会设置为可空列。
删除列:不会产生删除列事件,而是后续将该列的数据自动填充为NULL值。
重命名列:被看作为添加列和删除列,在当前Schema末尾添加重命名后的列,并将重命名前的列数据填充为NULL值。
列类型变更:
对于支持列类型变更的下游系统,在下游Sink支持处理列类型变更后,数据摄入作业支持普通列的类型变更,例如,从INT类型变更到BIGINT类型。此类变更依赖于下游Sink支持的列类型变更规则,不同的结果表支持的列类型变更规则也不相同,请参考结果表文档获取其支持的列类型变更规则。
对于不支持列类型变更的下游系统,比如Hologres,此类场景可以使用宽类型映射,即作业启动时在下游系统建立类型更加宽泛的表,在列类型变更发生时判断该类型变更下游Sink是否可以接受从而实现宽容的列类型变更支持。
当前暂不支持的Schema变更:
主键或索引等约束的变更。
从NOT NULL转为NULLABLE变更。
Canal JSON的Schema解析
Canal JSON数据中可能包含可选的sqlType字段,其中记录了数据列的精确类型信息。为了获取更准确的Schema,可以通过将canal-json.infer-schema.strategy配置为SQL_TYPE使用sqlType中的类型。类型映射关系如下:
JDBC类型
Type Code
CDC类型
BIT
-7
BOOLEAN
BOOLEAN
16
TINYINT
-6
TINYINT
SMALLINT
-5
SMALLINT
INTEGER
4
INT
BIGINT
-5
BIGINT
DECIMAL
3
DECIMAL(38,18)
NUMERIC
2
REAL
7
FLOAT
FLOAT
6
DOUBLE
8
DOUBLE
BINARY
-2
BYTES
VARBINARY
-3
LONGVARBINARY
-4
BLOB
2004
DATE
91
DATE
TIME
92
TIME
TIMESTAMP
93
TIMESTAMP
CHAR
1
STRING
VARCHAR
12
LONGVARCHAR
-1
其他类型
脏数据容忍与收集
在某些情况下,您的 Kafka 数据源中可能包含一些格式不正确的数据(脏数据),为了避免同步作业因为这些脏数据导致频繁失败重启,您可以配置忽略这部分异常数据。配置示例如下:
source:
type: kafka
name: Kafka Source
properties.bootstrap.servers: host:9092
topic: test-topic
value.format: json
scan.startup.mode: earliest-offset
# 开启脏数据容忍功能
ingestion.ignore-errors: true
# 容忍 1000 条脏数据
ingestion.error-tolerance.max-count: 1000这里配置了忽略 1000 条脏数据的策略,让您的作业能够在存在小批量脏数据时正常运行,而在脏数据条数超过这个阈值时让作业进入失败状态,提醒您对数据进行校验。
如果您希望作业永远不因为脏数据的存在导致失败,可以采用如下的配置:
source:
type: kafka
name: Kafka Source
properties.bootstrap.servers: host:9092
topic: test-topic
value.format: json
scan.startup.mode: earliest-offset
# 开启脏数据容忍功能
ingestion.ignore-errors: true
# 容忍所有的脏数据
ingestion.error-tolerance.max-count: -1脏数据容忍策略保障了作业不会因为异常数据频繁失败,您可能还希望进一步的了解这些脏数据的信息以调整 Kafka 数据生产者的行为,参考脏数据收集中介绍的流程,您可以在 TaskManager 日志中查看到作业的脏数据,配置示例如下:
source:
type: kafka
name: Kafka Source
properties.bootstrap.servers: host:9092
topic: test-topic
value.format: json
scan.startup.mode: earliest-offset
# 开启脏数据容忍功能
ingestion.ignore-errors: true
# 容忍所有的脏数据
ingestion.error-tolerance.max-count: -1
pipeline:
dirty-data.collector:
# 将脏数据写入 TaskManager 的日志文件中
type: logger表名与Topic的映射策略
在使用kafka作为数据摄入作业的目标端时,由于写入到Kafka消息格式(debezium-json或者canal-json)中还包含表名信息,后续消费Kafka消息时往往以数据中的表名信息作为实际表名(而非topic名称),因此需要谨慎配置表名与Topic的映射策略。
假设在MySQL有mydb.mytable1,mydb.mytable2两张表需要同步,可能的配置策略有以下几种:
1. 不配置任何映射策略
在没有任何映射策略的情况下,每张表会写入到对应的由“库名.表名”组成的topic中。因此mydb.mytable1的数据会写入到名为mydb.mytable1的topic中,mydb.mytable2的数据会写入到名为mydb.mytable2的topic中。配置示例如下:
source:
type: mysql
name: MySQL Source
hostname: ${secret_values.mysql.hostname}
port: ${mysql.port}
username: ${secret_values.mysql.username}
password: ${secret_values.mysql.password}
tables: mydb.mytable1,mydb.mytable2
server-id: 8601-8604
sink:
type: kafka
name: Kafka Sink
properties.bootstrap.servers: ${kafka.bootstraps.server}2. 配置route规则进行映射(不推荐)
在很多场景下,用户不希望写入的topic直接为“库名.表名”的格式,希望将数据写入到指定的topic中,因此会配置route规则进行映射。配置示例如下:
source:
type: mysql
name: MySQL Source
hostname: ${secret_values.mysql.hostname}
port: ${mysql.port}
username: ${secret_values.mysql.username}
password: ${secret_values.mysql.password}
tables: mydb.mytable1,mydb.mytable2
server-id: 8601-8604
sink:
type: kafka
name: Kafka Sink
properties.bootstrap.servers: ${kafka.bootstraps.server}
route:
- source-table: mydb.mytable1,mydb.mytable2
sink-table: mytable1此时所有来自mydb.mytable1,mydb.mytable2的数据都会写入到mytable1这一个topic中。
然而,通过route规则修改写入的topic名称时,也会修改Kafka消息(debezium-json或者canal-json格式)中的表名信息,此时Kafka消息中所有的表名都为mytable1,在其他系统消费这个topic的Kafka消息时,可能出现不符合预期的情况。
3. 配置sink.tableId-to-topic.mapping参数进行映射(推荐)
为了在配置表名与Topic的映射规则的同时保留源表表名信息,可以使用sink.tableId-to-topic.mapping参数完成该需求。配置示例如下:
source:
type: mysql
name: MySQL Source
hostname: ${secret_values.mysql.hostname}
port: ${mysql.port}
username: ${secret_values.mysql.username}
password: ${secret_values.mysql.password}
tables: mydb.mytable1,mydb.mytable2
server-id: 8601-8604
sink.tableId-to-topic.mapping: mydb.mytable1,mydb.mytable2:mytable
sink:
type: kafka
name: Kafka Sink
properties.bootstrap.servers: ${kafka.bootstraps.server}或者
source:
type: mysql
name: MySQL Source
hostname: ${secret_values.mysql.hostname}
port: ${mysql.port}
username: ${secret_values.mysql.username}
password: ${secret_values.mysql.password}
tables: mydb.mytable1,mydb.mytable2
server-id: 8601-8604
sink.tableId-to-topic.mapping: mydb.mytable1:mytable;mydb.mytable2:mytable
sink:
type: kafka
name: Kafka Sink
properties.bootstrap.servers: ${kafka.bootstraps.server}此时所有来自mydb.mytable1,mydb.mytable2的数据都会写入到mytable1这一个topic中,并且Kafka消息(debezium-json或者canal-json格式)中的表名信息仍然为mydb.mytable1或者mydb.mytable2,在其他系统消费这个topic的Kafka消息时,能正确获取源表表名信息。
EXACTLY_ONCE语义注意事项
配置消费者隔离级别
所有消费 Kafka 数据的应用必须设置 isolation.level:
read_committed:只读取已提交的数据。read_uncommitted(默认):可读取未提交的数据。
EXACTLY_ONCE 依赖
read_committed。否则消费者可能看到未提交数据,破坏一致性。事务超时与数据丢失
Flink 从 Checkpoint 恢复时,仅依赖该 Checkpoint 开始前已提交的事务。如果作业崩溃到重启的时间超过 Kafka 事务超时,Kafka 会自动中止事务,导致数据丢失。
Kafka Broker 默认
transaction.max.timeout.ms= 15 分钟。Flink Kafka Sink 默认设置
transaction.timeout.ms= 1 小时。你必须在 Broker 端提高
transaction.max.timeout.ms,使其不小于 Flink 的设置。
Producer 池与 Checkpoint 并发
EXACTLY_ONCE 模式使用固定大小的 Kafka Producer 池。每个 Checkpoint 占用池中的一个 Producer。如果并发 Checkpoint 数超过池大小,作业会失败。
请根据最大并发 Checkpoint 数调整 Producer 池大小。
并行度缩容限制
如果作业在第一个 Checkpoint 前失败,重启后不会保留原有 Producer 池信息。因此,在第一个 Checkpoint 完成前,不要缩减作业并行度。如必须缩容,并行度不得低于
FlinkKafkaProducer.SAFE_SCALE_DOWN_FACTOR。事务阻塞读取
在
read_committed模式下,任何未结束(未提交也未中止)的事务会阻塞整个 Topic 的读取。例如:
事务 1 写入数据。
事务 2 写入并提交数据。
只要事务 1 未结束,事务 2 的数据对消费者不可见。
因此:
正常运行时,数据可见延迟约等于 Checkpoint 间隔。
作业失败时,正在写入的 Topic 会阻塞消费者,直到作业重启或事务超时,极端情况下,事务超时甚至会影响读取。