
本文为您介绍流存储Fluss的应用场景。
背景说明
流存储Fluss作为专为流式数据设计的存储系统,可广泛应用于实时湖仓架构的构建。通过与Apache Flink的深度集成,Fluss能覆盖当前主流实时计算场景,相较传统方案,在性能与成本方面具备显著优势。
可查询的低成本流式数仓

业务场景
适用于多种实时业务场景实时数据分析,推荐系统,用户画像等。
原有方案及痛点
传统架构中,通常采用消息队列构建实时数仓的 ODS/DWD 层,并配合 OLAP 引擎提供即席查询能力,以保障链路的实时性。但在链路异常时,由于消息队列无法直接查询,问题定位困难,需将数据导入其他系统进行分析。
Fluss方案优势
与 Flink 生态无缝集成,提升开发与运维效率
支持列裁剪和部分更新,显著降低 IO 与计算资源消耗,降低成本
支持 KV 点查,便于快速定位异常,提升调试与排查效率
湖流一体方案
业务场景
适用于希望基于数据湖架构构建统一大数据服务体系的企业,追求架构简化、成本优化与实时能力提升。尤其适合需要同时支撑实时分析、离线加工与流式计算的混合负载场景。
原有方案及痛点
在传统的数据湖架构中,为满足不同时效性需求,通常采用“湖流分离”的模式:
实时链路 :通过消息队列(如 Kafka)+ 流处理引擎(如 Flink)+ OLAP 引擎(如 Doris、ClickHouse)处理秒级延迟需求。
离线链路 :通过 Flink + Paimon/ Iceberg 等湖格式构建 T+1 或分钟级延迟的批处理链路。
该模式存在明显痛点:数据多份冗余、架构复杂、一致性难保障、运维成本高 。
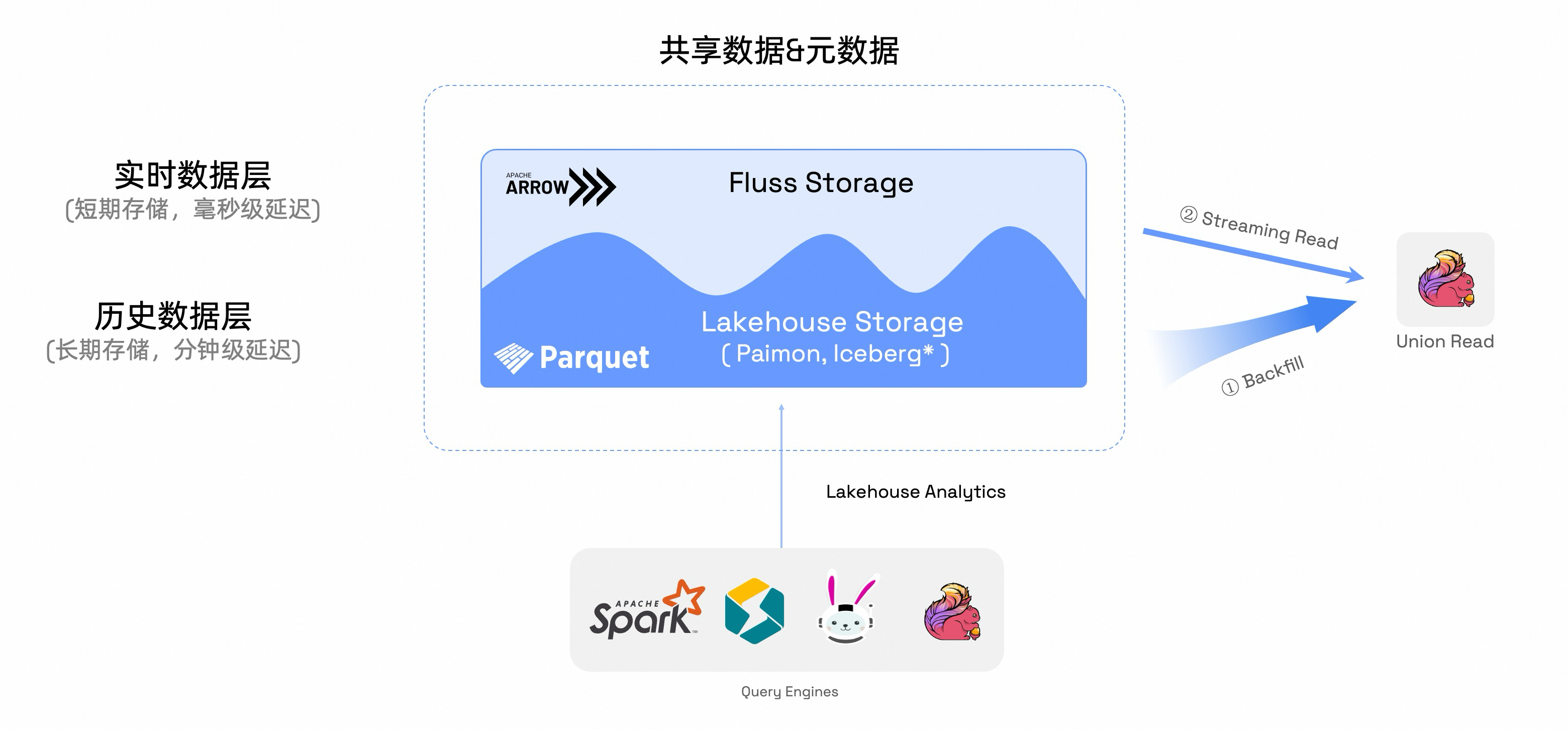
Fluss 湖流一体方案优势
Fluss 提出并实现了真正的“湖流一体 ”架构,核心在于:一份数据、实时写入、统一存储、多场景共享 。
一份数据,统一存储 :Fluss 作为统一的数据入口,支持高并发、低延迟的实时写入,数据直接持久化至对象存储,避免在消息队列、缓存、湖表之间多次复制,显著降低存储与运维成本。
无缝对接 Paimon 等湖格式 :Fluss 并非替代 Paimon,而是与其形成互补。Fluss 负责高性能实时摄入,Paimon 可作为下游湖表格式进行批处理、变更追踪或长期存储。两者通过统一元数据层实现自动、高效的数据与元数据同步 ,无需额外 ETL。
端到端秒级延迟 :支持实时写入与即时查询,满足实时大屏、实时数仓、实时特征等对延迟敏感的场景,真正实现“流式处理的时效性,湖仓架构的统一性”。