
Apache Fluss (Incubating)
Fluss是用于实时分析的流存储,可以用作Lakehouse Architectures的实时数据层。 Fluss凭借其列存储和实时更新功能,与Apache Flink无缝集成,来构建高吞吐,低延迟,具有成本效益的流式湖仓。
流存储Fluss版
一款由阿里云提供的Fluss全托管服务,具备免部署、免运维、低成本、高弹性、高可靠、高吞吐等优势。
RAM
阿里云提供的管理阿里云用户身份与阿里云资源访问权限的服务。RAM只针对流存储Fluss控制台和API操作,客户端使用SDK收发消息与RAM无关。
Fluss实例
一个独立的使用和管理的Fluss集群,您的所有操作需要在实例下完成。
数据库
实例下按照数据结构来组织、存储和管理数据的方式。您可以在数据库中创建、更新或删除表。
表
在 Fluss 中,表是用户数据存储的基本单位,以行和列的形式组织。表存储在特定的数据库中,遵循层次结构(数据库 -> 表)。
根据是否包含主键,表可分为两种类型:
日志表(Log Tables):
适用于仅追加(append-only)的场景。
仅支持 INSERT 操作。
主键表(Primary Key Tables):
用于业务数据库中的数据更新与管理。
支持基于定义的主键进行 INSERT、UPDATE 和 DELETE 操作。
当定义了分区列时,表即成为分区表。具有相同分区值的数据会被存储在同一个分区中。分区列可以应用于日志表和主键表,但需注意以下事项:
对于日志表,分区通常用于日志类数据,常见于按日期列进行分区,以便于数据分离和清理。
对于主键表,分区列必须是主键的一个子集,以确保数据唯一性。
这种设计确保了高效的数据组织方式、灵活应对不同使用场景的能力,并符合数据完整性约束的要求。
表数据组织
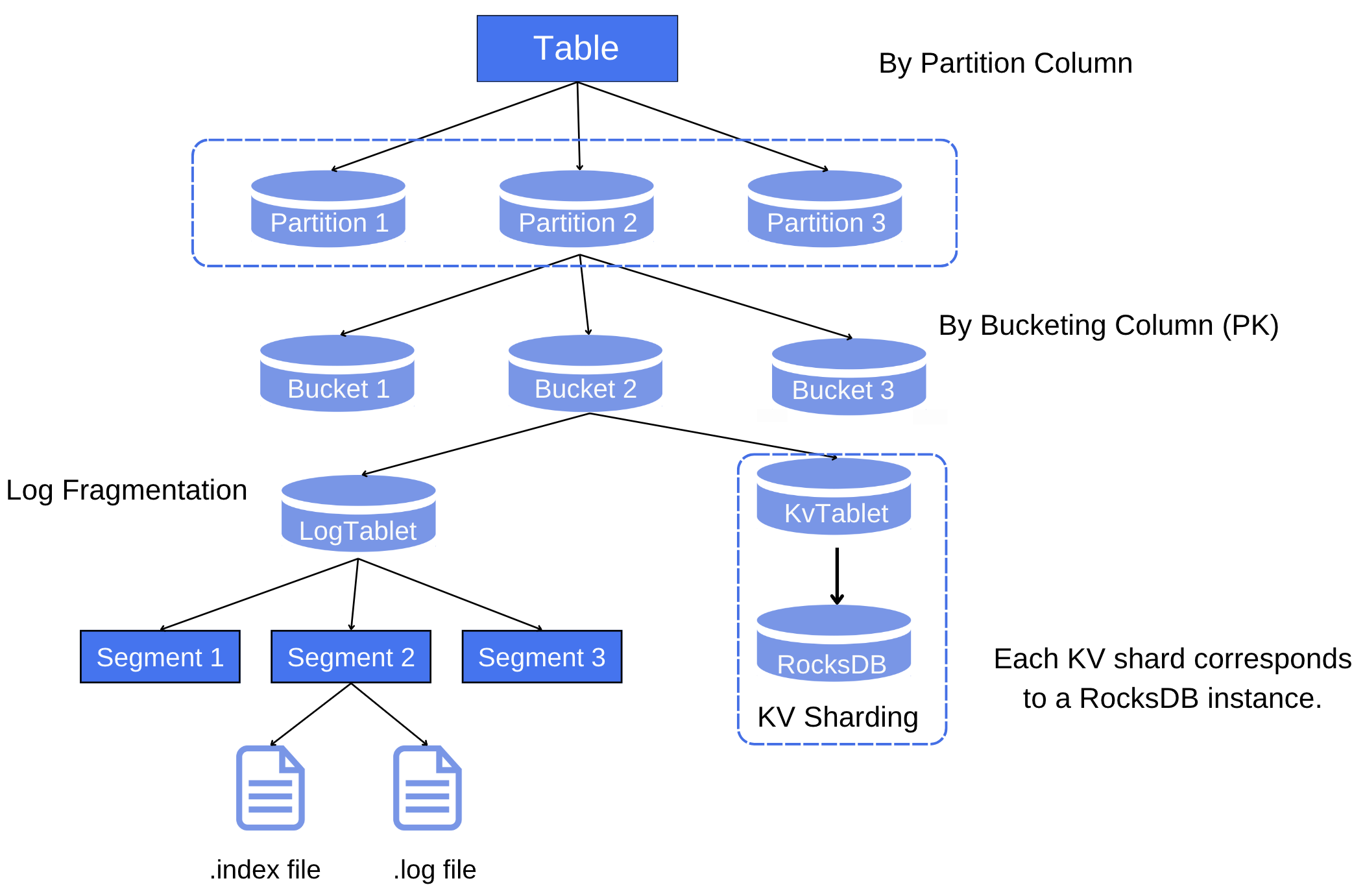
分区(Partition)
分区是根据一个或多个指定列(称为分区列)的值,将表的数据逻辑上划分为更小、更易管理的子集。分区列中的每个唯一值(或值的组合)定义了一个独立的分区。
桶(Bucket)
桶根据分桶策略将表或分区的数据水平划分为 N 个桶。桶的数量 N 可以按表进行配置。桶是数据迁移和备份的最小单位。一个桶的数据由一个 LogTablet 和一个(可选的)KvTablet 组成。
LogTablet
对于日志表(Log Table)和主键表(PrimaryKey Table)的每一个桶,都需要生成一个 LogTablet。对于日志表,LogTablet 同时包含主表数据和日志数据。对于主键表,LogTablet 作为主表数据的日志。
KvTablet
主键表的每个桶都需要生成一个 KvTablet。底层实现中,每个 KvTablet 对应一个嵌入式的 RocksDB 实例。RocksDB 是一个 LSM(日志结构合并)引擎,它使得 KvTablet 能够支持高性能的更新和查询操作。
CoordinatorServer
Fluss 分布式存储系统中的核心协调组件,主要负责管理整个集群的运行,包括管理集群的状态、元数据的处理、TabletServer的协调调度以及保障多副本下数据的可用性
TabletServer
Fluss 中的关键服务端组件,负责管理和处理多个 Tablet,负责数据持久化,直接面向 I/O 服务,提供高效的数据读写能力,确保数据的安全性和可靠性。在分布式环境下,TabletServer与其他组件协作,通过数据复制、故障转移等机制,保证数据的高可用性和一致性。
ZooKeeper
一款开源的分布式应用程序协调服务。在流存储Fluss中,ZooKeeper主要用于集群管理、配置管理、Leader选举。ZooKeeper是流存储Fluss管控服务的一部分,您无需感知ZooKeeper。