
本文为您介绍实时计算Flink版连接器方面的常见问题。
Kafka
DataHub
MaxCompute
MySQL
RDS MySQL
ClickHouse
Print
Tablestore
消息队列RocketMQ
Hologres
日志服务SLS
流式数据湖仓Paimon
Hudi
AnalyticDB MySQL版(ADB)3.0
自定义连接器
Flink如何获取Kafka中的JSON数据?
如果您需要获取普通JSON数据,方法详情请参见JSON Format。
如果您需要获取嵌套的JSON数据,则源表DDL中使用ROW格式定义JSON Object,结果表DDL中定义好要获取的JSON数据对应的Key,在DML语句中设置好Key获取的方式,就可以获取到对应的嵌套Key的Value。代码示例如下:
测试数据
{ "a":"abc", "b":1, "c":{ "e":["1","2","3","4"], "f":{"m":"567"} } }源表DDL定义
CREATE TEMPORARY TABLE `kafka_table` ( `a` VARCHAR, b int, `c` ROW<e ARRAY<VARCHAR>,f ROW<m VARCHAR>> --c是一个JSON Object,对应Flink里面是ROW;e是json list,对应ARRAY。 ) WITH ( 'connector' = 'kafka', 'topic' = 'xxx', 'properties.bootstrap.servers' = 'xxx', 'properties.group.id' = 'xxx', 'format' = 'json', 'scan.startup.mode' = 'xxx' );结果表DDL定义
CREATE TEMPORARY TABLE `sink` ( `a` VARCHAR, b INT, e VARCHAR, `m` varchar ) WITH ( 'connector' = 'print', 'logger' = 'true' );DML语句
INSERT INTO `sink` SELECT `a`, b, c.e[1], --Flink从1开始遍历数组,本示例为获取数组中的元素1。如果获取整个数组,则去掉[1]。 c.f.m FROM `kafka_table`;测试结果
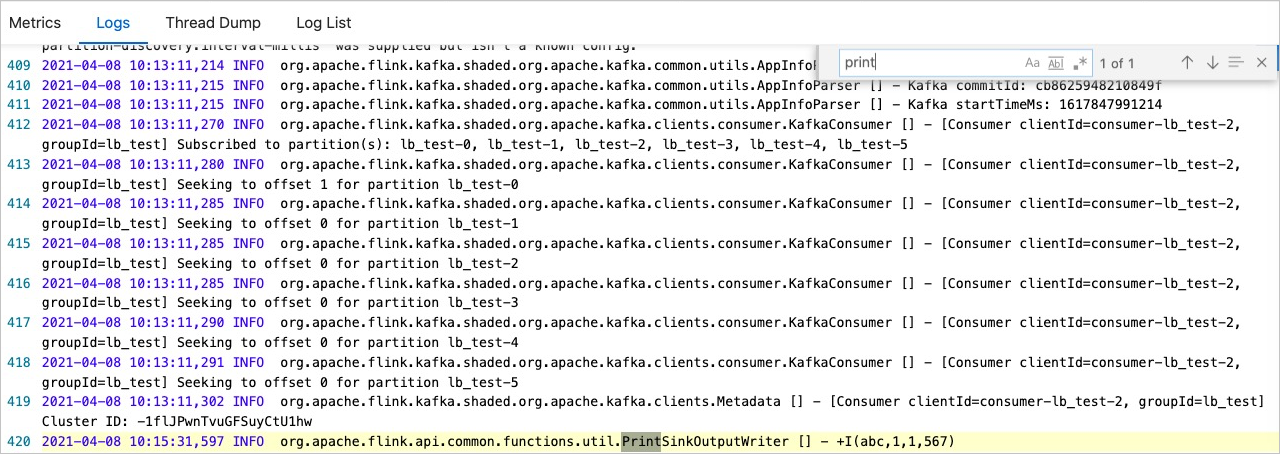
Flink和Kafka网络连通,但Flink无法消费或者写入数据?
问题原因
如果Flink与Kafka之间存在代理或端口映射等转发机制,则Kafka客户端拉取Kafka服务端的网络地址为Kafka服务器本身的地址而非代理的地址。此时,虽然Flink与Kafka之间网络连通,但是Flink无法消费或者写入数据。
Flink和Kafka客户端(Flink Kafka连接器)之间建立连接分为两个步骤:
Kafka客户端拉取Kafka服务端(Kafka Broker)元信息,包括Kafka服务端所有Broker的网络地址。
Flink使用Kafka客户端拉取下拉的Kafka服务端网络地址来消费或者写入数据。
排查方法
通过以下步骤来确认Flink与Kafka之间是否存在代理或端口映射等转发机制:
使用ZooKeeper命令行工具(zkCli.sh或zookeeper-shell.sh)登录您Kafka使用的ZooKeeper集群。
根据您的集群实际情况执行正确的命令,来获取您的Kafka Broker元信息。
通常可以使用
get /brokers/ids/0命令来获取Kafka Broker元信息。Kafka的连接地址位于endpoints字段中。
使用
ping或telnet等命令来测试Endpoint中显示的地址与Flink的连通性。如果无法连通,则代表Flink与Kafka之间存在代理或端口映射等转发机制。
解决方案
不使用代理或端口映射等转发机制,直接打通Flink与Kafka之间的网络,使Flink能够直接连通Kafka元信息中显示的Endpoint。
联系Kafka运维人员,将转发地址作为Kafka Broker端的advertised.listeners,以使Kafka客户端拉取的Kafka服务端元信息包含转发地址。
说明仅Kafka 0.10.2.0及以上版本支持将代理地址添加到Kafka Broker的Listener中。
如果您想了解更多的关于该问题的原理和解释,请参见KIP-103:区分内部与外部网络流量和Kafka网络连接问题详解。
为什么Kafka源表数据基于Event Time的窗口后,不能输出数据?
问题详情
Kafka作为源表,基于Event Time的窗口后,不能输出数据。
问题原因
Kafka某个分区没有数据,会影响Watermark的产生,从而导致Kafka源表数据基于Event Time的窗口后,不能输出数据。
解决方案
确保所有分区都存在数据。
开启源数据空闲监测功能。在其他配置中添加如下代码后保存生效,具体操作请参见如何配置自定义的作业运行参数?。
table.exec.source.idle-timeout: 5table.exec.source.idle-timeout参数详情,请参见Configuration。
Kafka中的Commit Offset有什么作用?
Kafka Commit Offset主要是用于确保流式数据处理的一致性和可靠性,通过记录已处理数据的位置,避免数据重复或丢失。Commit Offset通常与流式数据处理中的消息队列(如Kafka)一起使用,用于控制数据消费的进度。Flink在每次Checkpoint成功时,才会向Kafka提交当前读取Offset,可以记录下已经处理的数据的位置。如果未开启Checkpoint,或者Checkpoint设置的间隔过大,在Kafka端可能会查询不到当前读取的Offset从而导致数据处理的重复或者丢失。
如何通过Kafka连接器解析嵌套JSON格式的数据?
例如如下JSON格式的数据,直接用JSON format解析,会被解析成一个ARRAY<ROW<cola VARCHAR, colb VARCHAR>> 字段,就是一个 Row类型的数组,其中这个Row类型包含两个VARCHAR字段,然后通过自定义表值函数(UDTF)解析。
{"data":[{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"},{"cola":"test1","colb":"test2"}]}如何连接配置了安全信息的Kafka集群?
在Kafka DDL的WITH参数中添加要加密和认证相关的安全配置,安全配置详情请参见SECURITY,代码示例如下。
重要需将安全配置加上properties. 前缀。
如何配置Kafka表以使用PLAIN作为SASL机制并提供JAAS配置。
CREATE TABLE KafkaTable ( `user_id` BIGINT, `item_id` BIGINT, `behavior` STRING, `ts` TIMESTAMP(3) METADATA FROM 'timestamp' ) WITH ( 'connector' = 'kafka', ... 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.sasl.mechanism' = 'PLAIN', 'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule required username=\"username\" password=\"password\";' );使用SASL_SSL作为安全协议,并使用SCRAM-SHA-256作为SASL机制。
CREATE TABLE KafkaTable ( `user_id` BIGINT, `item_id` BIGINT, `behavior` STRING, `ts` TIMESTAMP(3) METADATA FROM 'timestamp' ) WITH ( 'connector' = 'kafka', ... 'properties.security.protocol' = 'SASL_SSL', /* SSL配置 */ /* 配置服务端提供的truststore (CA证书) 的路径 */ 'properties.ssl.truststore.location' = '/flink/usrlib/kafka.client.truststore.jks', 'properties.ssl.truststore.password' = 'test1234', /* 如果要求客户端认证,则需要配置keystore(私钥) 的路径 */ 'properties.ssl.keystore.location' = '/flink/usrlib/kafka.client.keystore.jks', 'properties.ssl.keystore.password' = 'test1234', /* SASL配置 */ /* 将SASL机制配置为SCRAM-SHA-256 */ 'properties.sasl.mechanism' = 'SCRAM-SHA-256', /* 配置JAAS */ 'properties.sasl.jaas.config' = 'org.apache.flink.kafka.shaded.org.apache.kafka.common.security.scram.ScramLoginModule required username=\"username\" password=\"password\";' );说明如果properties.sasl.mechanism是SCRAM-SHA-256,则properties.sasl.jaas.config用org.apache.flink.kafka.shaded.org.apache.kafka.common.security.scram.ScramLoginModule。
如果properties.sasl.mechanism是PLAINTEXT的话,则properties.sasl.jaas.config用 org.apache.flink.kafka.shaded.org.apache.kafka.common.security.plain.PlainLoginModule。
在作业的附加依赖文件中,上传将要使用到的所有文件(证书、公钥或私钥)。
上传后文件会被存储在/flink/usrlib目录下。如何在附加依赖文件中上传文件,详情请参见部署作业。
重要如果您的Kafka Broker上的用户名和密码的认证机制为SASL_SSL,但是客户端上认证机制为SASL_PLAINTEXT,作业在校验时就会报错OutOfMemory exception。此时,您需要修改客户端的认证机制。
如何解决字段命名冲突的问题?
问题现象
来自Kafka数据源的消息,这些消息数据被序列化成了两个JSON格式的串。这种情况下,键(key)和值(value)的内容中,均存在一个相同名称的字段(例如示例中id字段)。如果将其直接解析为Flink表进行处理,将会引发字段命名冲突的问题。
key
{ "id": 1 }value
{ "id": 100, "name": "flink" }
解决方案
此问题可以通过使用key.fields-prefix属性来避免。以下是定义Flink表的SQL语句。
CREATE TABLE kafka_table ( -- 在此定义键中和值中的字段 key_id INT, value_id INT, name STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'test_topic', 'properties.bootstrap.servers' = 'localhost:9092', 'format' = 'json', 'json.ignore-parse-errors' = 'true', -- 指定键中的字段和对应的数据类型 'key.format' = 'json', 'key.fields' = 'id', 'value.format' = 'json', 'value.fields' = 'id, name', -- 为键中的字段设置前缀 'key.fields-prefix' = 'key_' );在创建Flink表时,指定了属性key.fields-prefix为key_。这意味着在处理来自Kafka的数据时,键中的字段(在该环境中就是id字段)会被添加一个key_的前缀。因此在Flink表中的字段名会变为key_id,这样它就被清晰地与区分开了。
现在运行
SELECT * FROM kafka_table;查询,输出结果示例如下。key_id: 1, value_id: 100, name: flink
读取Kafka源表显示业务延迟,不符合预期,如何处理?
问题详情
读取Kafka源表存在currentEmitEventTimeLag 50多年,例如下图所示。
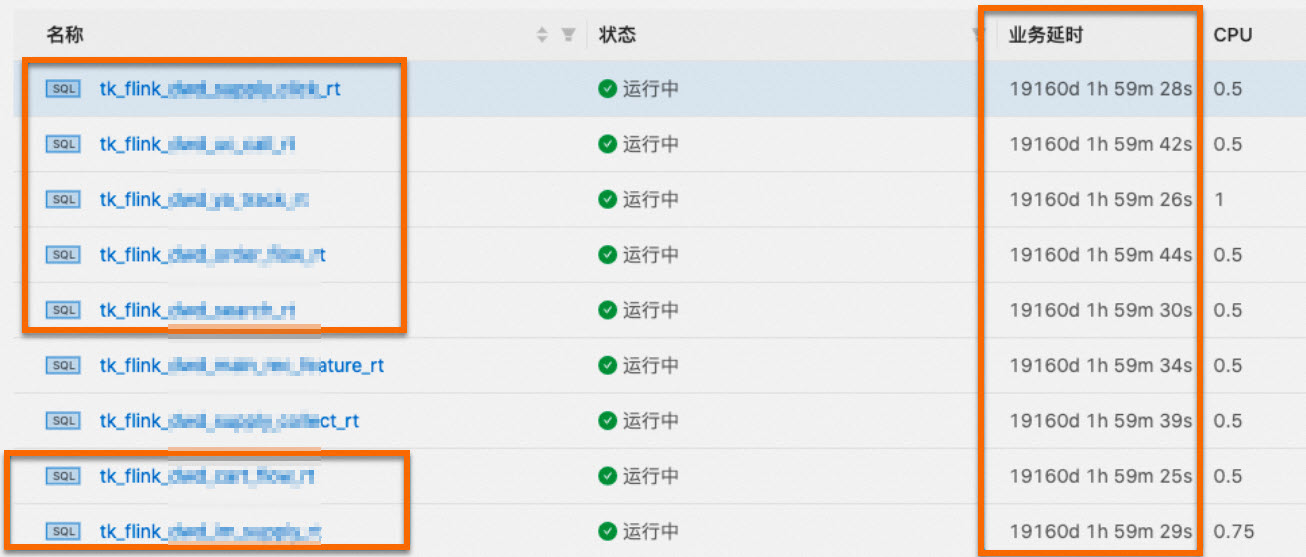
排查思路
先判断是JAR作业还是SQL作业。
如果是JAR作业,您还需要再确认下Pom使用的Kafka依赖是否为实时计算Flink版内置的,开源的没有汇报曲线。
判断上游Kafka是否所有分区都有实时数据进入。
判断Kafka message上的元数据timestamp是不是0或者null,
Kafka source的延迟是用当前时间减去Kafka消息上带的时间戳算出来的,如果消息上不带时间戳的话就会显示50+年。具体的判断方式如下:
SQL可以通过定义元信息列获取消息的时间戳,详情请参见消息队列Kafka源表。
CREATE TEMPORARY TABLE sk_flink_src_user_praise_rt ( `timestamp` BIGINT , `timestamp` TIMESTAMP METADATA, --元数据时间戳。 ts as to_timestamp ( from_unixtime (`timestamp`, 'yyyy-MM-dd HH:mm:ss') ), watermark for ts as ts - interval '5' second ) WITH ( 'connector' = 'kafka', 'topic' = '', 'properties.bootstrap.servers' = '', 'properties.group.id' = '', 'format' = 'json', 'scan.startup.mode' = 'latest-offset', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true' );写一个简单的Java程序把消息用KafkaConsumer读出来进行测试。
报错:'upsert-kafka' table require PRIMARY KEY
问题详情
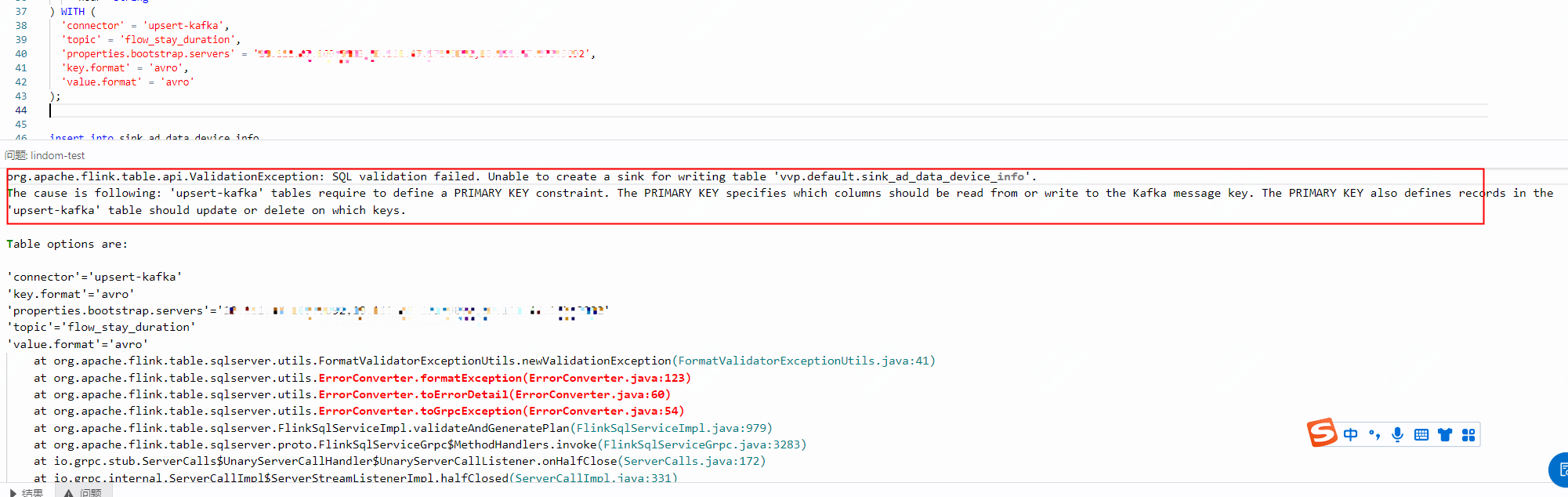
问题原因
在定义DDL时未指定主键。若使用upsert-kafka作为结果表,连接器可以消费上游计算逻辑产生的Changelog流,并将INSERT或UPDATE_AFTER数据写入的Kafka,将DELETE数据以value为空的消息写入,表示对应key的消息被删除。Flink将根据主键列的值对数据进行分区,从而保证主键上的消息有序,同一主键上的更新或删除消息将落在同一分区中。
解决方案
在定义DDL时指定主键。
分裂或者缩容DataHub Topic后导致Flink作业失败,如何恢复?
如果分裂或者缩容了Flink正在读取的某个Topic,则会导致任务持续出错,无法自行恢复。该情况下需要重新启动(先停止再启动)来使任务恢复正常。
可以删除正在消费的DataHub Topic吗?
不支持删除或重建正在消费的DataHub Topic。
endPoint和tunnelEndpoint是指什么?如果配置错误会产生什么结果?
endPoint和tunnelEndpoint参数说明参见Endpoint。VPC环境中这两个参数如果配置错误可能会导致任务异常,异常情况详情如下:
如果endPoint配置错误,则任务上线停滞在91%的进度。
如果tunnelEndpoint配置错误,则任务运行失败。
启动作业时出现Akka超时报错,但是全量MaxCompute源表和增量MaxCompute获取Metadata速率正常,应该如何处理?
请合并小文件,具体步骤请参见文档小文件优化及作业诊断常见问题。
全量MaxCompute和增量MaxCompute是如何读取MaxCompute数据的?
全量MaxCompute和增量MaxCompute是通过Tunnel读取MaxCompute数据的,读取速度受MaxCompute Tunnel带宽限制。
引用MaxCompute作为数据源,在作业启动后,向已有的分区或者表里追加数据,这些新数据是否能被全量MaxCompute或增量MaxCompute源表读取?
启动Flink作业后,如果正在被Source读取或已经被Source读取完成的表或分区有新的数据追加,则这部分数据不会被读取,而且可能导致作业Failover。
全量MaxCompute和增量MaxCompute源表均使用ODPS DOWNLOAD SESSION读取表数据或者分区数据。新建DOWNLOAD SESSION,服务端会创建一个Index文件,相当于创建DOWNLOAD SESSION一瞬间数据的映射,后续的数据读取以这个映射为基础。因此在新建 DOWNLOAD SESSION 后,追加到MaxCompute表或者分区里的数据,正常流程下是不会被读取的。但如果MaxCompute源表中写入新数据,则会出现两种异常:
产生报错:如果Tunnel在读取数据的过程中写入新数据,则会产生报错
ErrorCode=TableModified,ErrorMessage=The specified table has been modified since the download initiated.。数据正确性无法保证:如果在Tunnel已经关闭后写入新数据,则这些数据不会被读取。但当作业发生Failover或者暂停后恢复作业,已经读过的数据可能会被重读,新写入的数据可能被读不全。
全量MaxCompute和增量MaxCompute源表作业是否支持暂停作业后修改并发数,再恢复作业?
对于开启了useNewApi选项(默认开启)的MaxCompute源表,在流模式下支持暂停作业后修改并发数再恢复作业。MaxCompute源表顺序读取匹配到的多个分区,在读取当前分区时会分配每个并发读取分区中不同范围的数据。修改并发不改变作业暂停之前正在读取分区的并发分配方式,当读取下一个分区时再根据新的并发度分配每个并发的读取范围。因此可能出现读取单个大分区时,增加并发并重启作业后只有部分MaxCompute算子读取数据的情况。
对于指定了useNewApi为false的作业,以及批作业不支持修改并发。
作业启动位点设置了2019-10-11 00:00:00, 为什么启动位点前的分区也会被全量MaxCompute源表读取?
设置启动位点只对消息队列(例如DataHub)类型的数据源有效,对MaxCompute源表无效。Flink作业启动后数据读取的范围如下:
分区表:读取当前所有分区。
非分区表:读取当前存在的数据。
增量MaxCompute源表监听到新分区时,如果该分区还有数据没有写完,如何处理?
目前暂无机制可以标志一个分区的数据是否完整,只要监听到新分区,就会读入。用增量MaxCompute源表读取一个MaxCompute分区表T,分区列是ds,推荐的写入方法为:不创建分区,先执行Insert overwrite table T partition (ds='20191010') ...语句,作业结束且成功后,分区和数据一起可见。
不允许的写入方法为:先创建好分区,例如ds=20191010,再往分区里写数据。增量MaxCompute源表监听到新分区ds=20191010,立刻读入,如果此时该分区还有数据没有写完,就会漏读数据。
MaxCompute连接器运行报错:ErrorMessage=Authorization Failed [4019], You have NO privilege
报错详情
作业运行过程中会在Failover页面或TaskManager.log页面报错,报错信息如下。
ErrorMessage=Authorization Failed [4019], You have NO privilege'ODPS:***'报错原因
MaxCompute DDL定义中填写的用户身份信息无法访问MaxCompute。
解决方案
通过阿里云账号、RAM用户账号或RAM角色认证用户身份,详情请参见用户认证。
如何填写增量MaxCompute的startPartition参数?
请按以下步骤填写startPartition参数。
步骤 | 说明 | 示例 |
1 | 将每个分区列名及对应的分区值用等号(=)连接。分区值必须是一个固定值。 | 分区列为dt,需要读取分区值从20220901开始的数据,结果为dt=20220901。 |
2 | 将第一步中得到的结果按分区级别从小到大排序,然后用逗号(,)连接,中间不能有任何空格。这一步得到的结果即为startPartition参数的值。 说明 可以只指定前若干级分区。 |
|
系统在加载分区列表时,会把每个分区列表的所有分区和startPartition按照字典序进行比较,加载字典序大于等于startPartition的分区。例如,一个增量MaxCompute分区表,有一级分区ds和二级分区type两个分区列,假设表里有以下6个分区:
ds=20191201,type=a
ds=20191201,type=b
ds=20191202,type=a
ds=20191202,type=b
ds=20191202,type=c
ds=20191203,type=a
当startPartition的值为ds=20191202时,将会读取ds=20191202,type=a、ds=20191202,type=b、ds=20191202,type=c、ds=20191203,type=a四个分区。当startPartition的值为ds=20191202,type=b时,将会读取ds=20191202,type=b、ds=20191202,type=c、ds=20191203,type=a三个分区。
startPartition指定的分区不一定需要存在,只要字典序大于等于startPartition的分区就会被读取。
为什么带有增量MaxCompute源表的作业启动后,迟迟不开始读取数据?
这是因为目前已经存在的字典序大于等于startPartition的分区数太多,或这些分区里的小文件数量太多。增量MaxCompute源表需要首先整理符合条件的存量分区的信息再开始读取,因此建议:
不要读取太多历史数据。
说明如果您需要处理历史数据,可以运行带有MaxCompute源表的批作业。
减少历史数据中小文件的数量,具体步骤请参见小文件优化及作业诊断常见问题。
在读取或写入分区时,如何填写Partition参数?
读取分区
读取固定分区
源表与维表需要读取固定分区时,请按以下步骤填写partition参数。
步骤
说明
示例
1
对于维表,将每个分区列名及对应的分区值用等号(=)连接。分区值是一个固定值。
对于源表,将每个分区列名及对应的分区值用等号(=)连接。分区值可以是一个固定值,也可以是一个包含通配符(*)的值。通配符可以匹配任意字符串(含空字符串)。
分区列为dt,需要读取分区值为20220901的数据,结果为
dt=20220901。分区列为dt,需要读取分区值以202209开头的数据,结果为
dt=202209*(仅对源表生效)。分区列为dt,需要读取分区值以2022开头,01结尾的数据,结果为
dt=2022*01(仅对源表生效)。分区列为dt,需要读取所有分区的数据,结果为
dt=*(仅对源表生效)。
2
将第一步中得到的结果按分区级别从小到大排序,然后用逗号(,)连接,中间不能有任何空格。这一步得到的结果即为partition参数的值。
可以只对前若干级分区进行指定。
只有一个一级分区dt。需要读取dt=20220901的数据,直接填写
'partition' = 'dt=20220901'。有三级分区,一级分区为dt,二级分区为hh,三级分区为mm。需要读取dt=20220901,hh=08,mm=10的数据,填写
'partition' = 'dt=20220901,hh=08,mm=10'。有三级分区,一级分区为dt,二级分区为hh,三级分区为mm。需要读取dt=20220901,hh=08,mm任意的数据,填写
'partition' = 'dt=20220901,hh=08'或'partition' = 'dt=20220901,hh=08,mm=*'。有三级分区,一级分区为dt,二级分区为hh,三级分区为mm。需要读取dt=20220901,hh任意的数据,mm=10的数据,填写
'partition' = 'dt=20220901,hh=*,mm=10'。
如果以上步骤无法满足筛选分区的需求,也可以将筛选条件写入SQL语句的WHERE条件中,利用SQL优化器的分区下推功能进行分区筛选。有两级分区,一级分区为dt,二级分区为hh,需要读取dt>=20220901,且dt<=20220903,且hh>=09,且hh<=17的分区,SQL代码示例如下。
CREATE TABLE maxcompute_table ( content VARCHAR, dt VARCHAR, hh VARCHAR ) PARTITIONED BY (dt, hh) WITH ( -- 需要通过PARTITIONED BY指定分区列,否则无法启用SQL优化器的分区下推功能,影响执行效率。 'connector' = 'odps', ... -- 填写accessId等必填参数。partition可不填写,由SQL优化器进行筛选。 ); SELECT content, dt, hh FROM maxcompute_table WHERE dt >= '20220901' AND dt <= '20220903' AND hh >= '09' AND hh <= '17'; -- 在WHERE条件里填写分区筛选条件。读取字典序最大的分区
如果源表或维表需要读取字典序最大的分区,partition参数应填写为
'partition' = 'max_pt()'。如果源表或维表需要读取字典序最大的两个分区,partition参数应填写为
'partition' = 'max_two_pt()'。如果源表或维表需要读取伴随有.done的字典序最大的分区,partition参数应填写为
'partition' = 'max_pt_with_done()'。
在多数应用场景下,字典序最大的分区也是最新产生的分区。有时最新分区的数据还未准备好,希望维表暂时先读取较老分区的数据时,可以使用max_pt_with_done()这一partition参数值。
当一个分区的数据准备完成后,您需要同时创建一个空分区,该分区的名称为对应包含数据的分区名.done。例如,当分区dt=20220901的数据准备完成后,您需要同时创建空分区dt=20220901.done。设置了max_pt_with_done()这一partition参数值后,维表只会读取数据分区与.done分区同时存在的分区,没有.done分区的数据分区则暂不读取。详情请参见max_pt()和max_pt_with_done()的区别是什么?。
说明源表仅会在作业启动时获取字典序最大的分区,在读完所有数据后结束运行,不会监控是否有新分区产生。如果您需要持续读取新分区,请使用增量源表模式。维表在每次更新时都会检查最新分区并读取最新数据。
写入分区
写入固定分区
结果表需要将数据写入固定分区时,可以按读取固定分区中相同的步骤填写partition参数。
重要结果表的partition参数不支持通配符(*)。
写入动态分区
结果表需要根据写入数据中分区列具体值写入对应分区时,需要将分区列名按分区级别从小到大排序,然后用逗号(,)连接,中间不能有任何空格。得到的结果即为partition参数的值。例如,有三级分区,一级分区为dt,二级分区为hh,三级分区为mm,此时可以填写为
'partition' = 'dt,hh,mm'。
为什么含有MaxCompute源表的作业一直在启动中,或作业启动成功后过了很久才产生数据?
原因有以下几点:
MaxCompute表小文件数量太多,具体步骤请参见小文件优化及作业诊断常见问题。
MaxCompute存储集群与Flink计算集群不在同一地区,导致网络通信时间过长。建议统一存储集群与计算集群的地区后再次尝试。
MaxCompute权限设置不正确,读取源表需要MaxCompute表的download权限。
如何选择数据通道?
MaxCompute提供Batch Tunnel与Streaming Tunnel两种数据通道。您可以根据一致性与运行效率的需求,选择不同的数据通道。两种数据通道的区别如下。
需求 | Batch Tunnel | Streaming Tunnel |
一致性 | 相比Streaming Tunnel,该方式在多数情况下能更稳定地将数据写入 MaxCompute 表,保证数据不会丢失(At Least Once语义)。 只有当Checkpoint过程中出现异常,且作业同时写入多个分区时,才有可能在部分分区中产生重复数据。 | 保证数据不会丢失(At Least Once语义),当作业在任意情况下出现异常时,都有可能产生重复数据。 |
运行效率 | 由于需要在Checkpoint过程中提交数据以及在服务端创建文件等操作,整体效率低于Streaming Tunnel。 | 无需在Checkpoint过程中Commit数据。如果使用了Streaming Tunnel,同时设置numFlushThreads值大于1,在Flush数据的过程中也能不间断地接收上游数据,整体效率高于Batch Tunnel。 |
对于目前使用MaxCompute Batch Tunnel的作业,在Checkpoint进行得很慢甚至超时,且确认下游可以接受重复数据时,可以考虑使用MaxCompute Stream Tunnel。
如何处理MaxCompute结果表写入数据出现重复的情况?
在Flink作业通过MaxCompute连接器写入数据到MaxCompute时出现重复数据时,您可以从以下几个方面进行排查:
检查作业逻辑。在MaxCompute结果表中即使声明了主键约束,Flink在向外部存储写入数据时也不会进行主键唯一性检查,并且MaxCompute中非事务性表不支持主键约束。如果Flink作业逻辑计算出了重复数据,写入MaxCompute的数据仍会出现重复的情况。
是否存在多个Flink作业同时写入同一张MaxCompute表。如上文所述,MaxCompute侧不支持主键约束,若多个Flink作业计算得到了相同结果,则会在MaxCompute表中重复存在。
使用Batch Tunnel时,Flink作业在进行Checkpoint时失败。Checkpoint时失败,MaxCompute结果表可能已经将数据提交至服务侧,因此从上一个Checkpoint恢复作业时,两个Checkpoint之间的数据可能出现重复的情况。
使用Stream Tunnel时发生了Flink作业的failover。在开启Stream Tunnel向MaxCompute写入数据时,在Checkpoint之间会将数据提交到MaxCompute服务侧,因此当作业failover并从最新Checkpoint恢复时,最新Checkpoint完成之后、作业failover之前期间的数据可能会出现重复。详情请参见如何选择数据通道?此时,您可以切换到Batch Tunnel模式来避免这种情况产生的重复数据。
使用Batch Tunnel时,Flink作业failover或取消后启动(例如由autopilot调优触发)。在vvr-6.0.7-flink-1.15版本之前,MaxCompute结果表会在关闭时提交数据,因此当Flink作业停止并从上一个Checkpoint恢复时,Checkpoint和作业停止之间的数据可能出现重复。您可以将Flink版本升级到vvr-6.0.7-flink-1.15及更高版本来解决该问题。
含有MaxCompute结果表的作业运行过程中报错Invalid partition spec
报错原因:因为写入MaxCompute的数据,分区列的值不合法。不合法的值包括:空字符串,空值(null值),以及含有等号(=)、英文逗号(,)或斜杠(/)的值。
解决方案:请检查是否含有不合法数据。
含有MaxCompute结果表的作业运行过程中报错No more available blockId
报错原因:因为写入MaxCompute结果表的block数量超过限制,说明每次flush的数据量太小而且flush太频繁。
解决方案:建议调整batchSize与flushIntervalMs参数值大小。
如何使用维表SHUFFLE_HASH注解?
在默认情况下,每个并发都会存储整张维表的信息。如果维表数据量较大,可以使用SHUFFLE_HASH注解将维表数据均匀分散到各个并发中,降低JVM堆内存的消耗。如下示例中,维表dim_1和dim_3的数据都分散到了各个并发中,而维表dim_2的数据仍然被完整地缓存在每个并发中。
-- 创建源表与三张维表。
CREATE TABLE source_table (k VARCHAR, v VARCHAR) WITH ( ... );
CREATE TABLE dim_1 (k VARCHAR, v VARCHAR) WITH ('connector' = 'odps', 'cache' = 'ALL', ... );
CREATE TABLE dim_2 (k VARCHAR, v VARCHAR) WITH ('connector' = 'odps', 'cache' = 'ALL', ... );
CREATE TABLE dim_3 (k VARCHAR, v VARCHAR) WITH ('connector' = 'odps', 'cache' = 'ALL', ... );
-- 将需要分散数据的维表名称写在SHUFFLE_HASH注解内。
SELECT /*+ SHUFFLE_HASH(dim_1), SHUFFLE_HASH(dim_3) */
k, s.v, d1.v, d2.v, d3.v
FROM source_table AS s
INNER JOIN dim_1 FOR SYSTEM_TIME AS OF PROCTIME() AS d1 ON s.k = d1.k
LEFT JOIN dim_2 FOR SYSTEM_TIME AS OF PROCTIME() AS d2 ON s.k = d2.k
LEFT JOIN dim_3 FOR SYSTEM_TIME AS OF PROCTIME() AS d3 ON s.k = d3.k;如何填写CacheReloadTimeBlackList参数?
每天固定时段禁止维表更新的时间段
数据类型:
String用
->连接开始和结束时间。用
,分隔多个时间段。时间格式:
YYYY-MM-DD HH:mm(仅小时分钟时,默认为每天)。
'cacheReloadTimeBlackList' = '14:00 -> 15:00,23:00 -> 01:00'示例场景 | 示例值 |
单一时间段 | 14:00 -> 15:00 |
多时间段 | 14:00 -> 15:00,23:00 -> 01:00 |
特殊时间段 | 14:00 -> 15:00, 23:00 -> 01:00,2025-10-01 22:00 -> 2025-10-01 23:00 |
报错:java.io.EOFException: SSL peer shut down incorrectly
报错详情
Caused by: java.io.EOFException: SSL peer shut down incorrectly at sun.security.ssl.SSLSocketInputRecord.decodeInputRecord(SSLSocketInputRecord.java:239) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketInputRecord.decode(SSLSocketInputRecord.java:190) ~[?:1.8.0_302] at sun.security.ssl.SSLTransport.decode(SSLTransport.java:109) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketImpl.decode(SSLSocketImpl.java:1392) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketImpl.readHandshakeRecord(SSLSocketImpl.java:1300) ~[?:1.8.0_302] at sun.security.ssl.SSLSocketImpl.startHandshake(SSLSocketImpl.java:435) ~[?:1.8.0_302] at com.mysql.cj.protocol.ExportControlled.performTlsHandshake(ExportControlled.java:347) ~[?:?] at com.mysql.cj.protocol.StandardSocketFactory.performTlsHandshake(StandardSocketFactory.java:194) ~[?:?] at com.mysql.cj.protocol.a.NativeSocketConnection.performTlsHandshake(NativeSocketConnection.java:101) ~[?:?] at com.mysql.cj.protocol.a.NativeProtocol.negotiateSSLConnection(NativeProtocol.java:308) ~[?:?] at com.mysql.cj.protocol.a.NativeAuthenticationProvider.connect(NativeAuthenticationProvider.java:204) ~[?:?] at com.mysql.cj.protocol.a.NativeProtocol.connect(NativeProtocol.java:1369) ~[?:?] at com.mysql.cj.NativeSession.connect(NativeSession.java:133) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.connectOneTryOnly(ConnectionImpl.java:949) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.createNewIO(ConnectionImpl.java:819) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.<init>(ConnectionImpl.java:449) ~[?:?] at com.mysql.cj.jdbc.ConnectionImpl.getInstance(ConnectionImpl.java:242) ~[?:?] at com.mysql.cj.jdbc.NonRegisteringDriver.connect(NonRegisteringDriver.java:198) ~[?:?] at org.apache.flink.connector.jdbc.internal.connection.SimpleJdbcConnectionProvider.getOrEstablishConnection(SimpleJdbcConnectionProvider.java:128) ~[?:?] at org.apache.flink.connector.jdbc.internal.AbstractJdbcOutputFormat.open(AbstractJdbcOutputFormat.java:54) ~[?:?] ... 14 more报错原因
该错误通常发生在MySQL数据库启用了SSL协议,但客户端未正确配置SSL连接时。例如在MySQL driver版本为8.0.27时,MySQL数据库开启了SSL协议,但默认访问方式不通过SSL连接数据库,导致报错。
解决方案
建议WITH参数中连接器设置为RDS,且MySQL维表URL参数中追加
characterEncoding=utf-8&useSSL=false,例如:'url'='jdbc:mysql://***.***.***.***:3306/test?characterEncoding=utf-8&useSSL=false'
为什么主键为bigint unsigned的MySQL表注册Flink Catalog,主键会变为decimal?但是使用CTAS同步到Hologres后,主键又变为text?
由于Flink不支持bigint unsigned,考虑到数值范围的限制,Flink会将MySQL的bigint unsigned主键识别为decimal类型。而在进行Hologres同步时,由于Hologres不支持bigint unsigned,并且不支持将decimal类型用作主键,因此系统会自动将其转换为了text类型。
建议在开发和设计过程中根据这一规范进行调整。如果您希望此列依然使用decimal类型,可以在Hologres端提前手动建表,并将其他字段设置为主键或者不设置主键。然而,这可能导致数据重复问题,因为不同或缺失的主键会影响数据的唯一性。因此,需要在应用层面解决这一问题,例如可以容忍一定程度的数据重复或加入去重逻辑。
Flink的结果数据写入RDS表,是按主键更新的,还是生成1条新的记录?
如果在DDL中定义了主键,会采用INSERT INTO tablename(field1,field2, field3, ...) VALUES(value1, value2, value3, ...) ON DUPLICATE KEY UPDATE field1=value1,field2=value2, field3=value3, ...;的方式更新记录,即对于不存在的主键字段会直接插入,存在的主键字段则更新相应的值。如果DDL中没有声明PRIMARY KEY,则会用insert into方式插入记录,追加数据。
使用RDS表中的唯一索引进行GROUP BY时需要注意什么?
需要在作业中的GROUP BY中声明该唯一索引。
RDS中只有一个自增主键,Flink作业中不能声明为PRIMARY KEY。
为什么MySQL物理表(包含RDS MySQL和ADB)的INT UNSIGNED字段类型,在Flink SQL中要被声明为其他类型?
因为MySQL的JDBC Driver在获取数据时,由于精度问题,会采用不同的数据类型进行承接。具体来说,对于MySQL的INT UNSIGNED类型,在Java中会使用LONG类型来承接数据,对应Flink SQL中为BIGINT。而对于MySQL的BIGINT UNSIGNED类型,Java中会使用BIGINTEGER类型来承接数据,对应Flink SQL中为DECIMAL(20, 0)。
报错:Incorrect string value: '\xF0\x9F\x98\x80\xF0\x9F...' for column 'test' at row 1
报错详情
Caused by: java.sql.BatchUpdateException: Incorrect string value: '\xF0\x9F\x98\x80\xF0\x9F...' for column 'test' at row 1 at sun.reflect.GeneratedConstructorAccessor59.newInstance(Unknown Source) at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45) at java.lang.reflect.Constructor.newInstance(Constructor.java:423) at com.mysql.cj.util.Util.handleNewInstance(Util.java:192) at com.mysql.cj.util.Util.getInstance(Util.java:167) at com.mysql.cj.util.Util.getInstance(Util.java:174) at com.mysql.cj.jdbc.exceptions.SQLError.createBatchUpdateException(SQLError.java:224) at com.mysql.cj.jdbc.ClientPreparedStatement.executeBatchedInserts(ClientPreparedStatement.java:755) at com.mysql.cj.jdbc.ClientPreparedStatement.executeBatchInternal(ClientPreparedStatement.java:426) at com.mysql.cj.jdbc.StatementImpl.executeBatch(StatementImpl.java:796) at com.alibaba.druid.pool.DruidPooledPreparedStatement.executeBatch(DruidPooledPreparedStatement.java:565) at com.alibaba.ververica.connectors.rds.sink.RdsOutputFormat.executeSql(RdsOutputFormat.java:488) ... 15 more报错原因
数据中存在特殊的字符或编码格式,导致数据库编码不能被正常解析。
解决方案
在使用JDBC连接MySQL数据库时,URL地址后面加上UTF-8,例如
jdbc:mysql://<内网地址>/<databaseName>?characterEncoding=UTF-8。
写MySQL(TDDL/RDS)时,出现死锁(DeadLock)
问题详情
写MySQL(TDDL/RDS)时,出现死锁(DeadLock)。
重要在实时计算Flink中,下游数据库使用MySQL等关系数据库(对应的连接器为TDDL/RDS),当实时计算Flink版频繁写入某个表或者资源时,存在死锁风险。
死锁形成的示例如下:
假设完成一次INSERT需要依次抢占(A,B)2个锁。A是一个范围锁,有2个事务(T1,T2),表的Schema为(id(自增主键),nid(唯一键))。T1包含2条insert(null,2),(null,1),T2包含1条insert(null,2)。
t时刻,T1第一条INSERT插入,此时T1持有(A,B)2个锁。
t+1时刻T2开始插入,需要等待锁A来锁住(-inf,2],此时A被T1拥有,且锁住了(-inf,2],区间存在包含关系,所以T2依赖T1释放A。
t+2时刻T1第二条INSERT执行,需要A锁住(-inf,1],该区间属于(-inf,2],所以需要排队等T2释放锁,所以T1依赖T2释放A。
当T1和T2相互依赖且相互等待时死锁形成。
RDS/TDDL、OTS数据库引擎锁的区别
RDS/TDDL:InnoDB的行锁是针对索引加的锁,不是针对单条记录加的锁。因此,虽然是访问不同行的记录,但是如果使用相同的索引键,会出现锁冲突,导致整个区域的数据都无法更新。
OTS:单行锁,不影响其他数据更新。
死锁的解决方案
高QPS/TPS或高并发写入场景,建议使用OTS作为结果表,可以解决死锁的问题。通常,不建议使用TDDL或者RDS作为Flink Job的结果表。
如果必须要使用MySQL等关系数据库作为Sink节点,以下是一些建议:
确保没有其他读写业务方的干扰。
如果Job的数据量不大可以尝试单并发写入。但是在高QPS/TPS、高并发情况下,写入性能会降低。
尽可能不使用UniqueKey(唯一主键),带UniqueKey表的写入可能会导致死锁。如果业务要求表必须包含UniqueKey,请按照字段区分能力从大到小排列来定义UniqueKey,可以大幅降低死锁出现概率。例如,您可以把MD5函数放在day_time(20171010)前面,就可以使得字段区分能力从大到小排列来定义UniqueKey,从而解决死锁问题。
根据业务特点做分库分表,尽可能避免单表写入,实施细节请联系对应的数据库管理员。
更新了MySQL中的表结构,但是下游的表结构没有变化是怎么回事?
表结构的变更同步并不识别具体的DDL,而是捕获前后两条数据之间的Schema变化。如果仅仅发生了DDL变更,但是上游无任何新增数据或者数据变更,则不会触发下游的数据变更。详细说明请参见表结构变更的同步策略。
Source出现finish split response timeout异常,是什么原因?
该异常是因为Task的CPU使用率过高导致来不及响应Coordinator的RPC请求。此时,您需要在资源配置页面增加Task Manager的CPU资源。
在MySQL CDC全量阶段发生表结构变更有什么影响?
全量阶段发生了表结构变更,可能会导致作业报错或无法同步表结构变更。此时需要先停止作业,然后删除同步的下游表,并无状态地启动作业。
如果CTAS/CDAS同步期间发生了不支持的表结构变更,导致作业报错同步失败,该怎么解决?
您需要重新同步该表的数据。即先停止作业,然后删除下游表并重新无状态启动同步作业。请您避免这种不兼容的修改,否则重启作业后还会报错同步失败。表结构变更支持情况详情请参见CREATE TABLE AS(CTAS)语句。
ClickHouse结果表是否支持回撤更新数据?
当Flink结果表的DDL上指定了Primary Key,且参数 ignoreDelete设置为false时,则支持回撤更新数据,但性能会显著下降。
因为ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统,对UPDATE和DELETE的支持不够完善,如果在Flink DDL上指定了Primary Key,则会尝试使用ALTER TABLE UPDATE和ALTER TABLE DELETE来更新和删除数据,更新和删除的效率很低。
何时才可以在ClickHouse中看到写入到结果表的数据?
对于没开启exactlyOnce语义(默认不开启)的ClickHouse结果表,只要缓存中的数据条数达到了batchSize参数值,或者等待时间超过flushIntervalMs后,系统就会自动将缓存中的数据写入ClickHouse表中,此时就可以在ClickHouse中看到写入到结果表的数据,并不需要等checkpoint执行成功。
对于开启exactlyOnce语义的ClickHouse结果表,则需要等checkpoint执行成功后才可以在ClickHouse中看到写入到结果表的数据。
如何在控制台查看print数据结果?
查看print数据结果的步骤,有以下两种方式:
在实时计算开发控制台查看:
在实时计算开发控制台左侧导航栏,选择。
单击目标作业名称。
单击作业日志。
在左侧运行日志页签,单击作业右侧的下拉框,选择正在运行作业。
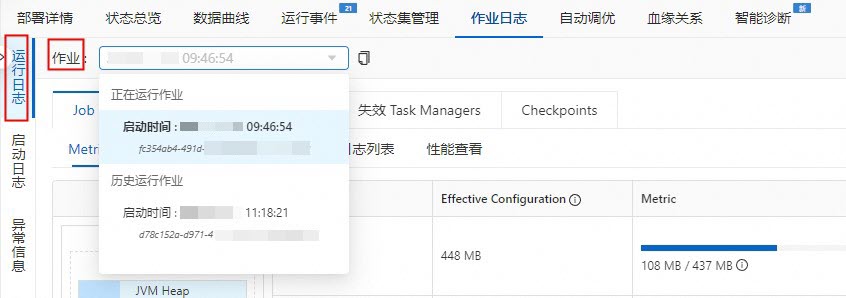
在运行 Task Managers页签,单击Path, ID。
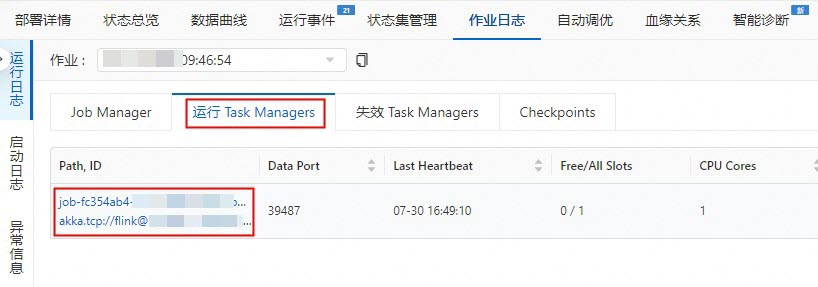
单击日志,查看print数据结果。
跳转到Flink UI界面查看:
在实时计算开发控制台左侧导航栏,选择。
单击目标作业名称。
在目标作业状态总览页签,单击Flink UI。

单击Task Managers。
单击Path, ID。
在logs页签,查看print数据结果。
维表进行JOIN时,如果查询不到数据,应该如何处理?
检查DDL语句和物理表中的Schema类型和名称是否一致。
max_pt()和max_pt_with_done()的区别是什么?
max_pt()选取的是所有分区中字典序最大的分区。max_pt_with_done()选取的是所有分区中字典序最大,且伴随有.done分区的分区。如果分区列表示例如下:
ds=20190101
ds=20190101.done
ds=20190102
ds=20190102.done
ds=20190103
则max_pt()和max_pt_with_done()的区别如下:
`partition`='max_pt_with_done()'匹配的分区是ds=20190102。`partition`='max_pt()',匹配的分区是ds=20190103。
写Paimon作业出现Heartbeat of TaskManager timed out
此类报错最有可能的原因是Task Manager堆内存不足。Paimon使用堆内存的主要方式为:
Paimon主键表writer算子的每个并发都有一个内存Buffer用于排序。该buffer的大小受
write-buffer-size表参数控制,默认值为256 MB。Paimon默认使用ORC文件格式,因此还需要一个内存Buffer将内存里的数据分批转为列存格式。该Buffer的大小受
orc.write.batch-size表参数控制,默认值为1024,即默认保存1024行数据。每个被修改的分桶都有一个专用的writer对象处理该分桶的写入数据。
基于堆内存的使用方式,可能导致堆内存不足的原因和相应解决方法如下:
write-buffer-size的值过大。可适当减小该参数。但buffer太小会导致磁盘被频繁写入,触发小文件合并的频率也会变高,影响写入性能。
单条数据的大小太大。
例如,数据中包含一个大小为4 MB的JSON字段,此时ORC Buffer大小将达到4 MB × 1024 = 4 GB,占用大量的堆内存。有以下两种解决方法:
调小
orc.write.batch-size的值。如果您不需要对Paimon结果表进行即席查询(OLAP),只需进行批式或流式消费,可以在建表时通过设置
'file.format' = 'avro'以及'metadata.stats-mode' = 'none'这两个表参数,来使用AVRO格式,并关闭统计信息的收集。说明参数仅支持在建表时设置,建表完成后无法通过ALTER TABLE语句或SQL Hint进行修改。
同时写入的分区数太多或每个分区的分桶数太多,导致writer对象创建太多。
需检查分区列的设置是否合理,是否由于SQL编写错误导致分区列被写入其它数据,以及分桶数是否合理。建议每个分桶中的数据总量在2 GB左右,最大不超过5 GB,分桶数调整请参见调整固定分桶表的分桶数量。
写Paimon作业出现Sink materializer must not be used with Paimon sink
Sink materializer算子原本用于解决流作业中级联JOIN导致的数据乱序问题。然而,在写入Paimon表的作业时,该算子不仅会引入额外的开销,在使用Aggregation数据合并机制时还可能导致计算结果错误。因此,写入Paimon表的作业中不能使用Sink materializer算子。
您可以通过SET语句或运行参数配置将table.exec.sink.upsert-materialize参数设为false,来关闭Sink materializer算子。如果您同时还需要解决级联JOIN导致的数据乱序问题,请参见乱序数据处理。
写Paimon作业出现File deletion conflicts detected或LSM conflicts detected
出现该报错的原因可能有以下几种:
有多个作业同时写入同一张Paimon表的同一个分区,此时Paimon表需要通过失败重启的方式解决冲突,这是正常现象。如果报错没有重复出现则无需处理。
从一个已存在的老状态恢复作业。此时该报错会重复出现,您需要从最新状态恢复作业,或无状态启动作业。
在同一个作业中,使用多条INSERT语句写入同一张Paimon表。Paimon目前暂不支持在同一个作业中通过多条INSERT语句分别写入,请使用UNION ALL语句将多条数据流写入Paimon表。
Global Committer节点或写入Append Scalable表时的Compaction Coordinator节点的并发数大于1。这两个节点的并发数必须为1,否则无法保证数据的一致性。
读Paimon作业出现File xxx not found, Possible causes
Paimon表的消费依赖快照文件,快照过期时间太短或消费作业效率低会导致正在消费的快照文件因过期被删除,消费作业将会报错。
您可以考虑调整快照文件过期时间、指定Consumer ID或消费作业优化。如果您需要查询目前可用的快照文件,以及每个快照文件创建的时间点,请参见Snapshots系统表。
Paimon作业出现No space left on device
如果该作业涉及到Paimon的查询过程(如使用Paimon table作为维表,或写入Paimon表时使用changelog-producer=lookup等),可通过SQL Hints设置如下参数,以限制查询过程中磁盘占用的最大空间和缓存过期时间,避免过多缓存文件导致磁盘空间不足问题。
lookup.cache-max-disk-size:查询缓存能使用的最大本地磁盘空间大小。建议取256mb、512mb、1gb等数值。lookup.cache-file-retention:查询缓存过期时间。建议取30min、15min或更小的时间。
对于写入Paimon表的作业,可通过SQL Hints设置如下参数,以限制写出过程中本地临时文件的总大小,避免过多临时文件导致磁盘空间不足问题。
write-buffer-spillable:写数据缓存溢出到磁盘的总开关。设置为false可直接避免所有本缓存占用磁盘空间的情况。write-buffer-spill.max-disk-size:写数据缓存可溢出到磁盘的最大空间。建议取256mb、512mb、1gb等数值。
OSS上有大量Paimon文件如何处理?
Paimon连接器写入数据的可见性和Checkpoint间隔有关系吗?
有关系。Paimon的exactly-once语义是依赖于系统检查点(Checkpoint)来保证。只有在每次Checkpoint时,Paimon才会真正提交数据,使这些数据对下游可见。在提交之前,本地Buffer中的数据被Flush到远程文件系统中,但不会通知下游可以读取这些数据。
写Paimon作业长时间内出现内存占用缓慢上涨的现象
如果作业rps同样也在缓慢上涨,则作业内存占用同样上涨属于正常现象。
如果是使用Paimon FileSystem Catalog读写OSS,请确保您在Catalog参数中配置过
fs.oss.endpoint、fs.oss.accessKeyId与fs.oss.accessKeySecret。否则该Flink作业保持长时间运行,可能会存在社区已知的内存缓慢泄漏问题。
报错:IllegalArgumentException: timeout value is negative
报错详情

报错原因
如果有一段时间没有消费到新的MQ消息,MetaQSource线程休眠,而休眠的时长为pullIntervalMs参数设置的值。但是pullIntervalMs参数默认值是-1。如果用-1作为休眠时长的值时,作业就会报错。
解决方案
设置pullIntervalMs参数为非负数。
RocketMQ Topic扩容时,RocketMQ如何感知Topic分区数变化?
Flink实时计算引擎VVR 6.0.2以下版本的实现是每5-10分钟获取一次当前分区数,如果分区数量连续三次都与原来的分区数不同,就会触发Failover。因此分区数发生变化后10-30分钟Source能感知到,并且发生Failover,作业重启后会按新的分区读取。
Flink实时计算引擎VVR 6.0.2及以上版本的实现是默认固定每5分钟获取一次当前分区数,当发现新的分区之后,直接交给TM的Source算子读取新的分区数据,不需要作业Failover。因此Source能在1-5分钟内感知分区发生的变化。
报错:BackPressure Exceed reject Limit
报错详情
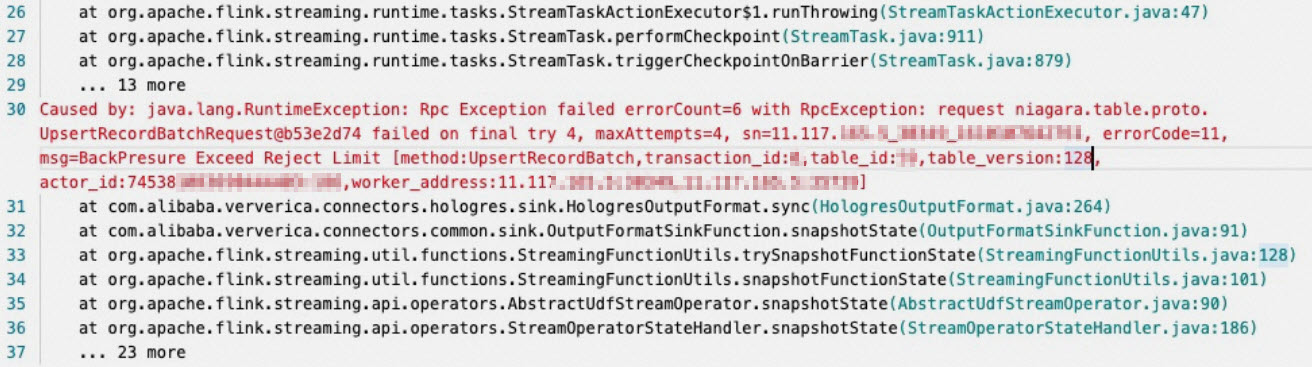
报错原因
Hologres写入压力比较大导致的。
解决方案
可以将实例信息提供给Hologres技术支持,以进行升级操作。
报错:remaining connection slots are reserved for non-replication superuser connections
报错详情
Caused by: com.alibaba.hologres.client.exception.HoloClientWithDetailsException: failed records 1, first:Record{schema=org.postgresql.model.TableSchema@188365, values=[f06b41455c694d24a18d0552b8b0****, com.chot.tpfymnq.meta, 2022-04-02 19:46:40.0, 28, 1, null], bitSet={0, 1, 2, 3, 4}},first err:[106]FATAL: remaining connection slots are reserved for non-replication superuser connections at com.alibaba.hologres.client.impl.Worker.handlePutAction(Worker.java:406) ~[?:?] at com.alibaba.hologres.client.impl.Worker.run(Worker.java:118) ~[?:?] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_302] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_302] ... 1 more Caused by: com.alibaba.hologres.org.postgresql.util.PSQLException: FATAL: remaining connection slots are reserved for non-replication superuser connections at com.alibaba.hologres.org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2553) ~[?:?] at com.alibaba.hologres.org.postgresql.core.v3.QueryExecutorImpl.readStartupMessages(QueryExecutorImpl.java:2665) ~[?:?] at com.alibaba.hologres.org.postgresql.core.v3.QueryExecutorImpl.<init>(QueryExecutorImpl.java:147) ~[?:?] at com.alibaba.hologres.org.postgresql.core.v3.ConnectionFactoryImpl.openConnectionImpl(ConnectionFactoryImpl.java:273) ~[?:?] at com.alibaba.hologres.org.postgresql.core.ConnectionFactory.openConnection(ConnectionFactory.java:51) ~[?:?] at com.alibaba.hologres.org.postgresql.jdbc.PgConnection.<init>(PgConnection.java:240) ~[?:?] at com.alibaba.hologres.org.postgresql.Driver.makeConnection(Driver.java:478) ~[?:?] at com.alibaba.hologres.org.postgresql.Driver.connect(Driver.java:277) ~[?:?] at java.sql.DriverManager.getConnection(DriverManager.java:674) ~[?:1.8.0_302] at java.sql.DriverManager.getConnection(DriverManager.java:217) ~[?:1.8.0_302] at com.alibaba.hologres.client.impl.ConnectionHolder.buildConnection(ConnectionHolder.java:122) ~[?:?] at com.alibaba.hologres.client.impl.ConnectionHolder.retryExecute(ConnectionHolder.java:195) ~[?:?] at com.alibaba.hologres.client.impl.ConnectionHolder.retryExecute(ConnectionHolder.java:184) ~[?:?] at com.alibaba.hologres.client.impl.Worker.doHandlePutAction(Worker.java:460) ~[?:?] at com.alibaba.hologres.client.impl.Worker.handlePutAction(Worker.java:389) ~[?:?] at com.alibaba.hologres.client.impl.Worker.run(Worker.java:118) ~[?:?] at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) ~[?:1.8.0_302] at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) ~[?:1.8.0_302] ... 1 more报错原因
一般为连接数超出。
解决方案
查看每个接入节点(Frontend,FE) 连接的app_name,查看flink-connector使用的HoloGRES Client连接数。
查看是否有其他作业在连接Hologres。
释放连接数。详情请参见连接数管理。
报错:no table is defined in publication
报错详情
删除表并重建同名表可能导致作业出现
no table is defined in publication。问题原因
表被删除时,和表绑定的publication没有被删除。
解决方案
在Hologres中执行
select * from pg_publication where pubname not in (select pubname from pg_publication_tables);命令,查询删表时未一起被清理的publication信息。执行
drop publication xx;语句删除残留的publication。重新启动作业。
Flink的Hologres Sink连接器的Checkpoint间隔和Hologres数据的最终可见性有什么关系?
Flink Hologres Sink连接器的Checkpoint(CP)间隔与Hologres数据的最终可见性没有直接关系,CP间隔影响数据恢复的SLA,但并不决定最终数据在Hologres中的可见时间。
Hologres连接器不支持事务,仅定期将数据flush到数据库。CP间隔仅保证每次CP时数据一定已刷新到数据库,但并不代表最长会等待该间隔时间。事实上,如果缓冲区满足一定条件(详见实时数仓Hologres、实时数仓Hologres和实时数仓Hologres),数据就会更早flush到下游。一般数仓不需要保证事务一致性,连接器会在后台异步刷新数据,在CP时再强制执行一次flush,以备异常恢复。
作业上线抛出permission denied for database异常
报错原因
实时计算引擎VVR 8.0.4起,连接器如果发现用户使用的Hologres实例大于2.0版本,会强制使用JDBC模式消费Binlog。如果Hologres实例是2.0及以上版本,且用户不是Superuser,使用JDBC模式消费Binlog需要特别进行权限的配置。
解决方案
如果用户不是SuperUser,使用JDBC模式消费Binlog需要进行权限配置。
user_name为阿里云账号ID或RAM用户,详情请参见账号概述。
-- 专家权限模型下为用户授予CREATE权限,以及赋予用户实例的Replication Role权限 GRANT CREATE ON DATABASE <db_name> TO <user_name>; alter role <user_name> replication; -- 如果Database开启了简单权限模型(SLMP),无法执行GRANT语句,使用spm_grant为用户授予DB的Admin权限,也可以在Holoweb中直接赋权 call spm_grant('<db_name>_admin', '<user_name>'); alter role <user_name> replication;
作业从检查点恢复过程中,发生table id parsed from checkpoint is different from the current table id异常
报错原因
这是由于实时计算引擎VVR 8.0.5~VVR 8.0.8版本,Hologres Binlog源表从checkpoint恢复时,会强制检查hologres表的table id,如果当前表的table id和checkpoint中保存的不一致,会无法从checkpoint恢复。此异常表示作业运行期间,用户对源表进行了TRUNCATE或其他重建表操作。
解决方案
建议升级到VVR-8.0.9及以上版本启动作业。考虑到业务场景的复杂性,在VVR 8.0.9取消了对table id的强制检查,但仍然不推荐对Binlog源表做重建表操作。重建表时原有表的历史Binlog会全部清除,Flink使用旧表的消费位点去消费新表的数据,可能导致数据不一致等不符合预期的情况。
通过JDBC模式消费Binlog时数据精度不符合预期问题
问题原因
实时计算引擎VVR 8.0.10及之前版本中,如果Flink DDL中声明的Binlog源表
DECIMAL类型的精度与Hologres不一致,会导致精度不符合预期。解决方案
在VVR 8.0.11中,该问题已得到修复。但仍请确保Flink与Hologres 的
DECIMAL类型精度一致,以避免精度缺失导致的数据丢失。
删除表并重建同名表可能导致作业出现no table is defined in publication或者The table xxx has no slot named xxx异常
报错原因
表被删除时,和表绑定的publication没有被删除。
解决方案
方案1:可以在hologres中执行
select * from pg_publication where pubname not in (select pubname from pg_publication_tables);语句,查询删表时未一起被清理的publication,并执行drop publication xx;语句删除残留的publication,之后重新启动作业即可。方案2:选择VVR 8.0.5及以上版本,连接器会自动执行清理操作。
报错:Caused by: com.aliyun.openservices.aliyun.log.producer.errors.LogSizeTooLargeException: the logs is 8785684 bytes which is larger than MAX_BATCH_SIZE_IN_BYTES 8388608
报错详情
Caused by: com.aliyun.openservices.aliyun.log.producer.errors.LogSizeTooLargeException: the logs is 8785684 bytes which is larger than MAX_BATCH_SIZE_IN_BYTES 8388608 at com.aliyun.openservices.aliyun.log.producer.internals.LogAccumulator.ensureValidLogSize(LogAccumulator.java:249) at com.aliyun.openservices.aliyun.log.producer.internals.LogAccumulator.doAppend(LogAccumulator.java:103) at com.aliyun.openservices.aliyun.log.producer.internals.LogAccumulator.append(LogAccumulator.java:84) at com.aliyun.openservices.aliyun.log.producer.LogProducer.send(LogProducer.java:385) at com.aliyun.openservices.aliyun.log.producer.LogProducer.send(LogProducer.java:308) at com.aliyun.openservices.aliyun.log.producer.LogProducer.send(LogProducer.java:211) at com.alibaba.ververica.connectors.sls.sink.SLSOutputFormat.writeRecord(SLSOutputFo rmat.java:100)报错原因
写入SLS的单行日志超过8 MB,无法再写入数据。
解决方案
更改启动位点,跳过超大异常数据,详情请参见作业启动。
恢复失败的Flink程序时,TaskManager发生OOM,源表报错java.lang.OutOfMemoryError: Java heap space
报错原因
通常是由于SLS消息体过大导致。SLS连接器是通过批量获取的方式请求数据,LogGroup由batchGetSize参数控制,默认为100。因此每次会收到最多100个LogGroup。在日常运行时,Flink消费及时,一般不会收到100个LogGroup,但在Failover时会积攒了大量未消费的数据。如果单个LogGroup占用内存*100>JVM可用内存,则TaskManager会发生OOM。
解决方案
减小batchGetSize参数值。
如何设置Paimon源表的消费位点?
您可以通过scan.mode参数设置Paimon源表的消费位点。scan.mode参数的可选值以及行为如下。
参数值 | 批读行为 | 流读行为 |
default | 默认值,根据其他参数确定实际的行为。
如果以上两个参数都没有设置,则行为与latest-full参数值相同。 | |
latest-full | 产出表的最新snapshot。 | 作业启动时,首先产生表的最新snapshot,之后持续产生增量数据。 |
compacted-full | 产出表最近一次compact后的snapshot。 | 作业启动时,首先产出表最近一次compact后的snapshot,之后持续产出增量数据。 |
latest | 与latest-full相同。 | 作业启动时不产生表的最新snapshot,之后持续产生增量数据。 |
from-timestamp | 产出表在 | 作业启动时不产出snapshot,之后持续产出从 |
from-snapshot | 产出表的snapshot,snapshot编号由 | 作业启动时不产出snapshot,之后持续产出从 |
from-snapshot-full | 与from-snapshot相同。 | 作业启动时产出表的snapshot,snapshot编号由 |
如何设置分区自动过期?
Paimon表支持自动删除存活时长大于分区过期时长的分区的功能,以节省存储成本。详情如下:
存活时长:当前系统时间减去分区值转化后的时间戳。分区值转化后的时间戳是按照以下顺序转化而得:
通过格式串
partition.timestamp-pattern参数,将一个分区值转换为时间字符串。在该格式串中,分区列由美元符号($)加上列名表示。例如,假设分区列由year、month、day、hour四列组成,格式串
$year-$month-$day $hour:00:00会将分区year=2023,month=04,day=21,hour=17转换为字符串2023-04-21 17:00:00。通过格式串
partition.timestamp-formatter参数,将时间字符串转换为时间戳。如果该参数没有设置,将默认尝试
yyyy-MM-dd HH:mm:ss与yyyy-MM-dd两个格式串。任何Java的DateTimeFormatter兼容的格式串都可以使用。
分区过期时间:您设置的
partition.expiration-time参数值。
存储中一直查不到数据,应该如何处理?
如果是数据未刷盘,这是正常现象,因为Flink的writer是按照以下策略去刷数据到磁盘的:
某个bucket在内存积攒到一定大小(默认值为64 MB)。
总的buffer大小积攒到一定大小(默认值为1 GB)。
触发Checkpoint,将内存里的数据全部flush出去。
如果是流写,请确保已开启Checkpoint。
数据有重复时,应该如何去做?
如果您是COW写,则需要开启参数write.insert.drop.duplicates。
COW写每个bucket的第一个文件默认是不去重的,只有增量的数据会去重,全局去重需要开启该参数;MOR写不需要开启任何参数,定义好primary key后默认全局去重。
说明从Hudi 0.10.0版本开始,该属性改名为write.precombine,且默认值为true。
如果需要多partition去重,则需开启参数index.global.enabled为true。
说明从Hudi 0.10.0版本开始,该属性默认为true。
当
index.type=bucket时,设置index.global.enabled参数为true是无效的,因为Bucket索引不支持跨分区的变更。因此,即使开启了全局索引,也无法实现多分区的去重功能。
对于长时间周期的更新,例如更新一个月前的数据,需将index.state.ttl调大(单位为天)。
索引是判断数据重复的核心数据结构,index.state.ttl设置了索引保存的时间,默认为1.5天,设置小于0代表永久保存。
说明从Hudi 0.10.0版本开始,该属性默认为0。
为什么Merge On Read只有log文件?
问题原因:Hudi只有在执行压缩后才会生成Parquet文件,否则只有Log文件。而Merge On Read默认开启异步压缩,策略是5个commits压缩一次,只有当条件满足才会触发压缩任务。
解决方案:通过调整压缩间隔compaction.delta_commits参数,更快触发压缩任务。
报错:multi-statement be found
问题详情
Flink作业写数据至AnalyticDB MySQL版(ADB),作业异常重启报错
Caused by: java.sql.SQLSyntaxErrorException: [13000, 2024101216171419216823505703151806929] multi-statement be found.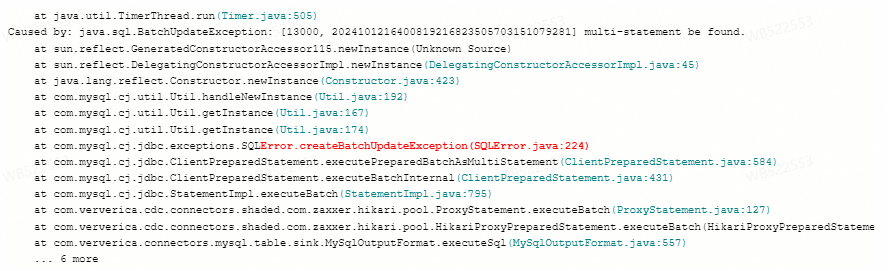
问题原因
AnalyticDB MySQL版(ADB)数据库启用
ALLOW_MULTI_QUERIES=true配置时,与MySQL JDBC Driver 8.x版本结合使用,出现兼容性问题。解决方案
联系技术支持获取5.1.46版本的MySQL JDBC Driver的自定义ADB 3.0连接器,然后将它应用于您的Flink任务中,自定义连接器使用方法请参见管理自定义连接器。
在ADB表的URI上配置参数
allowMultiQueries=true,例如jdbc:mysql://xxxxx.ads.aliyuncs.com:3306/xxx?allowMultiQueries=true'。
报错No suitable driver found for
问题原因
自定义连接器未找到对应的驱动程序(Driver)。
解决方案
通过
Class.forName提前在工厂类(Factory)中加载驱动程序(Driver)。把Driver驱动放到附加依赖里,并且添加参数
kubernetes.application-mode.classpath.include-user-jar: true,添加参数方法请参见如何配置自定义的作业运行参数?