
本文为您介绍数据正确性有关的常见问题。
报错:doesn't support consuming update and delete changes which is produced by node TableSourceScan
Lindorm Connector默认启用的upsert materialize算子因毫秒级时间戳精度导致数据被覆盖或错误删除,如何解决?
为什么作业没有输出?
场景描述
上线运行作业后,下游结果表中没有数据。
排错流程图
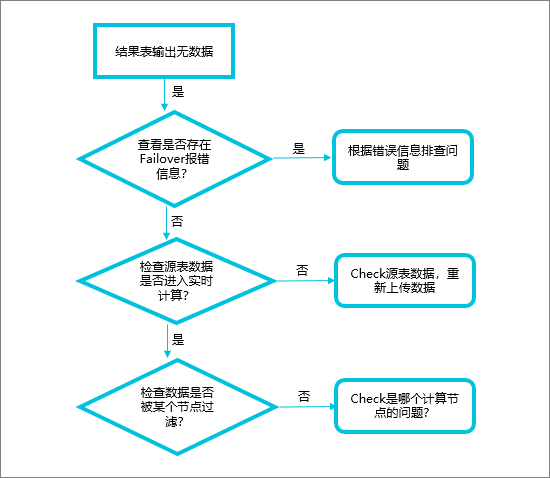
检查作业中是否存在Failover
排错指引
查看Failover报错信息,分析作业运行异常原因。
解决方案
解决Failover问题,使作业正常运行。
检查源表数据是否进入实时计算Flink版
排错指引
这种情况下没有Failover,但数据延时会很大,请查看监控告警页面numRecordsInOfSource,检查各Source输入是否有数据。
解决方案
检查源表,保证上游有数据进入实时计算Flink版。
检查数据是否被某个节点过滤
在其他配置中添加
pipeline.operator-chaining: 'false',具体操作请参见如何配置自定义的作业运行参数?。将节点拆分,然后观察每个节点的Bytes Received(输入)和Bytes Sent(输出),确定数据在哪个节点被过滤,如果某个节点输出为0,输入不为0,说明数据被这个节点过滤了。常见的导致数据无输出的算子包括join、window或where。检查下游是否由于默认缓存机制缓存了数据
解决方案:排除作业的业务逻辑异常后,调整下游存储的batchsize的大小。
重要如果batchsize参数设置得过小,则可能会造成下游数据库I/O压力过大、存在性能瓶颈的风险。例如,如果将batchsize设置为1,说明处理完一条数据,就会请求一次数据库,大数据场景下会导致数据库压力增大。
检查下游RDS,是否存在死锁
您可以使用print结果表,将计算结果打印到日志中,对日志进行分析,判断无输出结果的原因。详情请参见如何在控制台查看print数据结果?
如何定位Flink无法读取源数据的问题?
当Flink无法读取源数据时,建议从以下几个方面进行排查并处理:
检查上游存储和实时计算Flink版之间网络是否连通。
实时计算Flink版仅支持访问相同地域、相同VPC下的存储。如果您有访问跨VPC存储资源或者通过公网访问实时计算Flink版的特殊需求,请查看以下文档:
如果您需要跨VPC访问存储资源,则可以通过5种方式解决,详情请参见如何访问跨VPC的其他服务?。
如果您需要通过公网访问实时计算Flink版,则可以使用阿里云提供的NAT网关实现VPC网络和公网的连通。详情请参见实时计算Flink版如何访问公网?
检查上游存储中是否已配置了白名单。
上游存储中需要配置的产品有Kafka和ES。您可以按照以下步骤配置白名单:
获取实时计算Flink版虚拟交换机的网段。
获取方法请参见设置白名单。
在上游存储中配置实时计算Flink版白名单。
上游存储中配置白名单的方法,请参见对应DDL文档的前提条件中的文档链接,例如Kafka源表前提条件。
检查DDL中定义的字段类型、字段顺序和字段大小写是否和物理表一致。
为了确保一致性,您可以按照物理表的字段类型和顺序,以及使用相同的大小写规范来编写DDL。上游存储支持的字段类型和实时计算Flink版支持的字段类型可能不完全一致,但存在一定的映射关系。您需要按照DDL定义的字段类型映射关系一对一匹配,详情请参见对应DDL文档类型映射文档,例如日志服务SLS源表类型映射。
查看源表Taskmanager.log日志中是否有异常信息。
如果有异常报错,请先按照报错提示处理问题。查看源表Taskmanager.log日志的操作如下:
在页面,单击目标作业名称。
在状态总览页签,单击Source节点。
在SubTasks页签操作列,单击Open TaskManager Log Page。
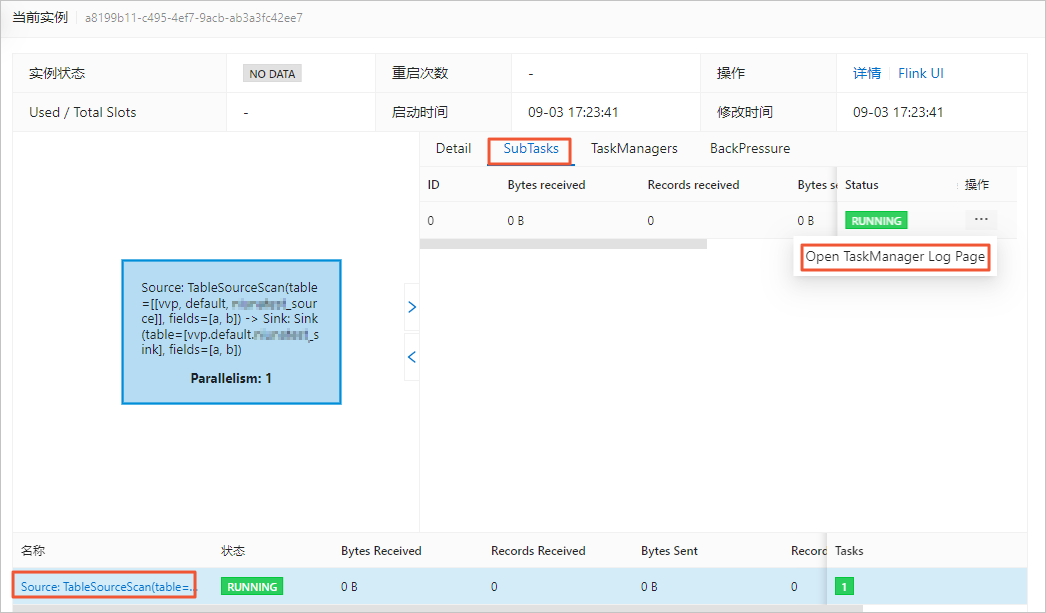
在logs页签,查看日志信息。
在当前页面查找最后一个Caused by信息,即第一个Failover中的Caused by信息,往往是导致作业异常的根因,根据该根因的提示信息,可以快速定位作业异常的原因。
如何定位Flink无法将数据写入到结果表的问题?
当Flink无法将数据写入到结果表时,建议从以下几个方面进行排查并处理:
确认下游存储和实时计算Flink版之间网络是否连通。
实时计算Flink版仅支持访问相同地域、相同VPC下的存储。如果您有访问跨VPC存储资源或者通过公网访问实时计算Flink版的特殊需求,请查看以下文档:
如果您需要跨VPC访问存储资源,则可以通过5种方式解决,详情请参见如何访问跨VPC的其他服务?。
如果您需要通过公网访问实时计算Flink版,则可以使用阿里云提供的NAT网关实现VPC网络和公网的连通。详情请参见实时计算Flink版如何访问公网?
确认下游存储中是否已配置了白名单。
下游存储中需要配置白名单的产品包括RDS MySQL、Kafka、ES、云原生数据仓库AnalyticDB MySQL版3.0、HBase、Redis和ClickHouse。您可以按照以下步骤配置白名单:
获取实时计算Flink版虚拟交换机的网段。
获取方法请参见设置白名单。
在下游存储中配置实时计算Flink版白名单。
下游存储中配置白名单的方法,请参见对应DDL文档的前提条件中的文档链接,例如RDS MySQL结果表前提条件。
确认DDL中定义的字段类型、字段顺序和字段大小写是否和物理表一致。
为了确保一致性,您可以按照物理表的字段类型和顺序,以及使用相同的大小写规范来编写DDL。下游存储支持的字段类型和实时计算Flink版支持的字段类型可能不完全一致,但存在一定的映射关系。您需要按照DDL定义的字段类型映射关系一对一匹配,详情请参见对应DDL文档类型映射,例如日志服务SLS结果表类型映射。
确认数据是否被中间节点过滤了,例如WHERE、JOIN和窗口等。
具体请查看Vertex拓扑图上每个计算节点数据输入和输出情况。例如WHERE节点输入为5,输出为0,则代表被WHERE节点过滤了,因此下游存储中无数据写入。
确认下游存储中设置的输出条件相关参数的默认值是否合适。
如果您的数据源的数据量较小,但结果表DDL定制中设置的输出条件的默认值较大,会导致一直达不到输出条件,而无法下发数据至下游存储。此时,您需要将输出条件相关参数的默认值改小。常见的下游存储中的输出条件参数情况如下表所示。
输出条件
参数
涉及的下游存储
一次批量写入的条数。
batchSize
每次批量写入数据的最大数据条数。
batchCount
Odps tunnel writer缓冲区Flush间隔。
flushIntervalMs
写入HBase前,内存中缓存的数据量(字节)大小。
sink.buffer-flush.max-size
写入HBase前,内存中缓存的数据条数。
sink.buffer-flush.max-rows
将缓存数据周期性写入到HBase的间隔,可以控制写入HBase的延迟。
sink.buffer-flush.interval
Hologres Sink节点数据攒批的最大值。
jdbcWriteBatchSize
确认窗口是否因为乱序而导致数据无法输出。
假如,实时计算Flink版一开始就流入一条2100年的未来数据,它的Watermark为2100年,系统会默认2100年前的数据已被处理完,只会处理比2100年大的数据。而后续流入的2021年的正常数据因为Watermark小于2100年而被丢弃。直到出现大于2100年的数据流入实时计算Flink版,则会触发窗口关闭而输出数据,否则就会导致结果表一直没有数据输出。
您可以通过Print Sink或者Log4j的方式确认数据源中是否存在乱序的数据,详情请参见print结果表和配置作业日志输出。找到乱序数据后,您可以过滤或者采取延迟触发窗口计算的方式处理乱序的数据。
确认是否因为个别并发没有数据而导致数据无法输出。
如果作业为多并发,但个别并发没有数据流入实时计算Flink版,则它的Watermark就为1970年0点0分,而多个并发的Watermark取最小值,因此就永远没有满足窗口结束的Watermark,无法触发窗口结束而输出数据。
此时,您需要检查您上游的Vertex拓扑图的Subtask每个并发是不是都有数据流入。如果有个别并发无数据,建议调整作业并发数小于等于源表Shard数,从而保证所有并发都有数据。
确认Kafka的某个分区是否无数据,从而导致数据无法输出。
如果Kafka某个分区没有数据,则会影响Watermark的产生,从而导致Kafka源表数据基于Event Time的窗口后,不能输出数据。解决方案请参见为什么Kafka源表数据基于Event Time的窗口后,不能输出数据?。
如何定位数据丢失的问题?
数据经过JOIN、WHERE或窗口等节点时,数据量减少是正常现象,这是因条件限制被过滤或JOIN不上。但如果您的数据丢失异常,建议从以下几个方面进行排查并处理:
确认维表Cache缓存策略是否有问题。
如果维表DDL中Cache缓存策略设置的有问题,则会导致维表的数据没有被拉取到,从而导致数据丢失。此时建议检查并修改作业Cache策略。作业Cache策略详情请参见各维表的Cache策略,例如HBase维表Cache参数。
确认函数使用方法是否不正确。
如果您在作业中使用了to_timestamp_tz、date_format等函数,而函数的使用方法不正确,导致数据转换出问题,数据被丢失。
此时,您可以通过Print Sink或者Log4j的方式,单独将使用的函数的信息打印到日志中,确认函数的使用方法是否正确。详情请参见print结果表或配置作业日志输出。
确认数据是否乱序。
如果作业中存在乱序的数据,这些乱序的数据的Watermark不在新窗口的开窗和关窗时间范围内,导致这些数据被丢弃。例如下图中11秒的数据在16秒进入15~20秒的窗口,而它的Watermark为11,会被系统认为是迟到数据,从而导致被丢弃。
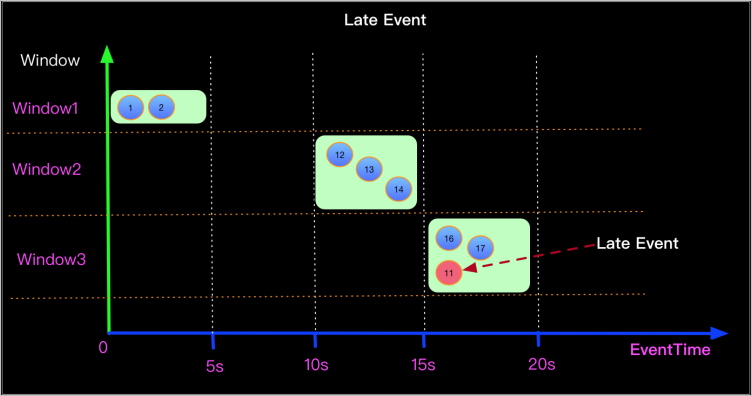
通常丢失的数据都是一个窗口的,您可以通过Print Sink或者Log4j的方式确认数据源中是否存在乱序的数据。详情请参见print结果表或配置作业日志输出。
找到乱序数据后,可以根据乱序的程度,合理地设置Watermark,采取延迟触发窗口计算的方式处理乱序的数据。例如该示例中,可以定义Watermark生成策略为Watermark = Event time -5s,从而让乱序的数据可以被正确地处理。建议以整天整时整分开窗口求聚合,否则数据乱序严重,增加offset后还是会有数据丢失问题。
CDC模式消费Hologres时row_number去重结果异常
异常结果
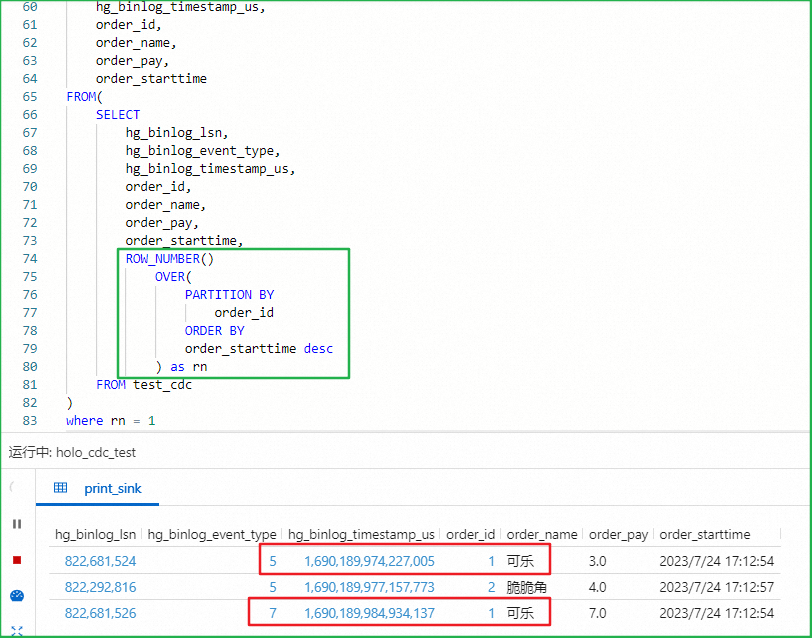
异常原因
在CDC模式下,如果下游包含回撤算子(例如使用ROW_NUMBER OVER WINDOW去重),就需要设置Hologres源表WITH参数中upsertSource为true,此时源表会以Upsert方式从Hologres中读取数据。
解决方案
在Hologres源表WITH参数中添加配置
'upsertSource' = 'true',可以避免数据重复。
作业数据不准确,该如何排查?
调整日志级别
将作业的日志级别调至INFO,确保能够捕获打印的日志信息。详情请参见修改运行作业日志级别。
开启算子探查功能
可以在不修改作业的情况下看到中间结果的输出,操作详情请参见算子探查(公测)。
分析运行日志
在状态总览页签的DAG图中复制算子名称,在日志列表中Log Name为inspect-taskmanager_0.out的页面搜索查看具体算子的输出。
优化与验证
根据日志定位问题后,修复异常算子的逻辑,重新提交作业并验证数据准确性。
报错:doesn't support consuming update and delete changes which is produced by node TableSourceScan
报错详情
Table sink 'vvp.default.***' doesn't support consuming update and delete changes which is produced by node TableSourceScan(table=[[vvp, default, ***]], fields=[id,b, content]) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.wrapExecutor(DelegateOperationExecutor.java:286) at org.apache.flink.table.sqlserver.execution.DelegateOperationExecutor.validate(DelegateOperationExecutor.java:211) at org.apache.flink.table.sqlserver.FlinkSqlServiceImpl.validate(FlinkSqlServiceImpl.java:741) at org.apache.flink.table.sqlserver.proto.FlinkSqlServiceGrpc$MethodHandlers.invoke(FlinkSqlServiceGrpc.java:2522) at io.grpc.stub.ServerCalls$UnaryServerCallHandler$UnaryServerCallListener.onHalfClose(ServerCalls.java:172) at io.grpc.internal.ServerCallImpl$ServerStreamListenerImpl.halfClosed(ServerCallImpl.java:331) at io.grpc.internal.ServerImpl$JumpToApplicationThreadServerStreamListener$1HalfClosed.runInContext(ServerImpl.java:820) at io.grpc.internal.ContextRunnable.run(ContextRunnable.java:37) at io.grpc.internal.SerializingExecutor.run(SerializingExecutor.java:123) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1147) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:622) at java.lang.Thread.run(Thread.java:834)报错原因
Append类型Sink无法接收上游update记录。
解决方案
使用支持写入update记录的Sink,例如Upsert Kafka等。详情请参见Upsert Kafka结果表。
Lindorm Connector默认启用的upsert materialize算子因毫秒级时间戳精度导致数据被覆盖或错误删除,如何解决?
问题背景
默认情况下,Lindorm Connector在写入数据前会自动启用 upsert materialize 算子(默认值:AUTO)。该算子可能生成相同主键下的 DELETE + INSERT 组合操作记录。由于Lindorm以毫秒级时间戳(Timestamp)管理数据版本,若同一主键的数据在同一毫秒内被多次写入,系统将无法区分写入顺序,从而可能导致数据意外覆盖或错误删除。
技术原理
时间戳精度限制:Lindorm以毫秒为粒度管理数据版本。若同一主键的多条记录在同一毫秒内写入,系统无法区分写入顺序,可能引发版本冲突。
写入语义差异:Lindorm仅支持
UPSERT语义(覆盖写入),而缺乏对完整的CHANGELOG语义(如DELETE标记的精确回滚)的支持。因此,upsert materialize算子的保序逻辑在Lindorm场景下无实际意义,反而可能因DELETE + INSERT组合操作引发数据异常。
风险影响
同一毫秒内的并发写入可能触发非预期的 DELETE + INSERT 逻辑,造成数据丢失或状态错误。
解决方案
建议显式关闭 upsert materialize 算子,以规避潜在风险。
适用场景:所有通过Flink写入Lindorm的任务。
生效方式:可在作业运行参数或SQL语句中全局设置,通过以下配置实现:
SET 'table.exec.sink.upsert-materialize' = 'NONE';注意事项:关闭后需确保业务逻辑能容忍最终一致性(如通过唯一主键保证数据幂等性)。