本文为您介绍如何将MySQL整库同步Kafka,从而降低多个任务对MySQL数据库造成的压力。
背景信息
MySQL CDC数据表主要用于获取MySQL数据,并可以实时同步数据表中的修改,经常用在复杂的计算场景。例如,作为一张维表和其他数据表做Join操作。在使用中,同一张MySQL表可能被多个作业依赖,当多个任务使用同一张MySQL表做处理时,MySQL数据库会启动多个连接,对MySQL服务器和网络造成很大的压力。
方案架构
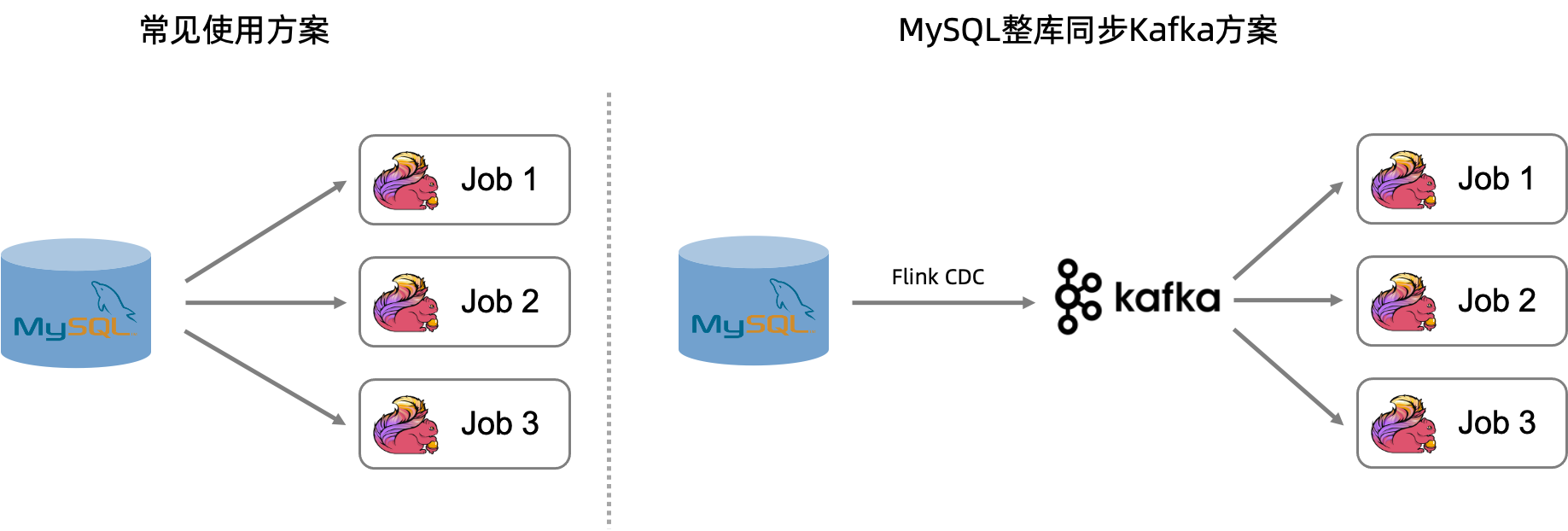
为缓解上游MySQL数据库的压力,阿里云Flink实时计算已提供将MySQL整库同步至Kafka的能力。该方案通过引入Kafka作为中间层,并采用Flink CDC数据摄入作业同步至Kafka来实现。
在一个作业中,上游MySQL的数据实时同步至Kafka,每张MySQL表以Upsert方式写入相应的Kafka Topic,然后使用Upsert Kafka连接器读取Topic中的数据替代访问MySQL表,从而有效降低多个任务对MySQL数据库造成的压力。
使用限制
同步的MySQL表必须包含主键。
支持使用自建Kafka集群、EMR的Kafka集群、云消息队列 Kafka 版。使用云消息队列 Kafka 版时,只能通过默认接入点使用。
Kafka集群的存储空间必须大于源表数据的存储空间,否则会因存储空间不足导致数据丢失。因为整库同步Kafka建立的topic都是compacted topic,即topic的每个消息键(Key)仅保留最近的一条消息,但是数据不会过期,compacted topic里相当于保存了与源库的表相同大小的数据。
实践场景
例如,在订单评论实时分析场景下,假设有用户表(user),订单表(order)和用户评论表(feedback)三张表。各个表包含数据如下图所示。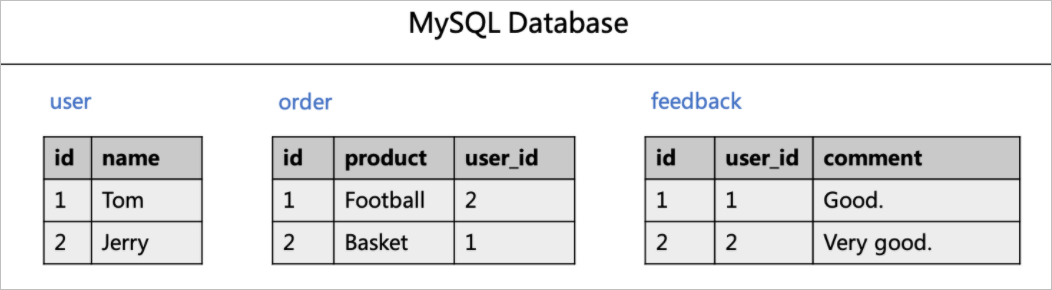
在展示用户订单信息和用户评论时,需要通过关联用户表(user)来获取用户名(name字段)信息。SQL示例如下。
-- 将订单信息和用户表做join,展示每个订单的用户名和商品名。
SELECT order.id as order_id, product, user.name as user_name
FROM order LEFT JOIN user
ON order.user_id = user.id;
-- 将评论和用户表做join,展示每个评论的内容和对应用户名。
SELECT feedback.id as feedback_id, comment, user.name as user_name
FROM feedback LEFT JOIN user
ON feedback.user_id = user.id;对于以上两个SQL任务,user表在两个作业中都被使用了一次。运行时,两个作业都会读取MySQL的全量数据和增量数据。全量读取需要创建MySQL连接,增量读取需要创建Binlog Client。随着作业的不断增多,MySQL连接和Binlog Client资源也会对应增长,会给上游数据库产生极大的压力,为了缓解对上游MySQL数据库的压力,通过CDAS或CTAS语法将上游的MySQL数据实时同步到Kafka中,提供给多个下游作业消费。
前提条件
已开通实时计算Flink版,详情请参见开通实时计算Flink版。
已开通云消息队列Kafka,详情请参见部署消息队列Kafka实例。
已开通RDS MySQL,详情请参见创建RDS MySQL实例。
实时计算Flink版、云数据库RDS MySQL、云消息队列Kafka需要在同一VPC下。如果不在同一VPC,需要先打通跨VPC的网络或者使用公网的形式访问,详情请参见如何访问跨VPC的其他服务?和如何访问公网?。
通过RAM用户或RAM角色等身份访问对应资源时,需要其具备对应资源的权限。
准备工作
创建RDS MySQL实例并准备数据源
创建RDS MySQL数据库,详情请参见创建数据库。
为目标实例创建名称为
order_dw的数据库。准备MySQL CDC数据源。
在目标实例详情页面,单击上方的登录数据库。
在弹出的DMS页面中,填写创建的数据库账号名和密码,然后单击登录。
登录成功后,在左侧双击
order_dw数据库,切换数据库。在SQL Console区域编写三张业务表的建表DDL以及插入的数据语句。
CREATE TABLE `user` ( id bigint not null primary key, name varchar(50) not null ); CREATE TABLE `order` ( id bigint not null primary key, product varchar(50) not null, user_id bigint not null ); CREATE TABLE `feedback` ( id bigint not null primary key, user_id bigint not null, comment varchar(50) not null ); -- 准备数据 INSERT INTO `user` VALUES(1, 'Tom'),(2, 'Jerry'); INSERT INTO `order` VALUES (1, 'Football', 2), (2, 'Basket', 1); INSERT INTO `feedback` VALUES (1, 1, 'Good.'), (2, 2, 'Very good');
单击执行,单击直接执行。
操作步骤
创建并启动一个Flink CDC数据摄入任务,将上游的MySQL数据实时同步到Kafka中,提供给多个下游作业消费。整库同步作业会自动创建topic,topic名称支持通过route模块定义,topic分区数和副本数会使用Kafka集群的默认配置,并且cleanup.policy会设置为compact。
默认Topic名称
整库同步任务建立的Kafka topic名称格式默认是用逗号连接MySQL数据库名和表名,如下作业会创建三个topic:order_dw.user,order_dw.order和order_dw.feedback。
在页面,新建Flink CDC数据摄入作业,并将如下代码拷贝到YAML编辑器。
source: type: mysql name: MySQL Source hostname: #{hostname} port: 3306 username: #{usernmae} password: #{password} tables: order_dw.\.* server-id: 28601-28604 sink: type: upsert-kafka name: upsert-kafka Sink properties.bootstrap.servers: xxxx.alikafka.aliyuncs.com:9092 # 阿里云消息队列Kafka版需要配置如下参数 aliyun.kafka.accessKeyId: #{ak} aliyun.kafka.accessKeySecret: #{sk} aliyun.kafka.instanceId: #{instanceId} aliyun.kafka.endpoint: #{endpoint} aliyun.kafka.regionId: #{regionId}单击右上方的部署,进行作业部署。
单击左侧导航栏的,单击目标作业操作列的启动,选择无状态启动后单击启动。
指定Topic名称
整库同步任务可以使用route指定每个表的topic名称,如下作业会创建三个topic:user1,order2和feedback3。
在页面,新建Flink CDC数据摄入作业,并将如下代码拷贝到YAML编辑器。
source: type: mysql name: MySQL Source hostname: #{hostname} port: 3306 username: #{usernmae} password: #{password} tables: order_dw.\.* server-id: 28601-28604 route: - source-table: order_dw.user sink-table: user1 - source-table: order_dw.order sink-table: order2 - source-table: order_dw.feedback sink-table: feedback3 sink: type: upsert-kafka name: upsert-kafka Sink properties.bootstrap.servers: xxxx.alikafka.aliyuncs.com:9092 # 阿里云消息队列Kafka版需要配置如下参数 aliyun.kafka.accessKeyId: #{ak} aliyun.kafka.accessKeySecret: #{sk} aliyun.kafka.instanceId: #{instanceId} aliyun.kafka.endpoint: #{endpoint} aliyun.kafka.regionId: #{regionId}单击右上方的部署,进行作业部署。
单击左侧导航栏的,单击目标作业操作列的启动,选择无状态启动后单击启动。
批量设置Topic名称
整库同步任务可以使用route批量指定生成的topic名称模式,如下作业会创建三个topic:topic_user,topic_order和topic_feedback。
在页面,新建Flink CDC数据摄入作业,并将如下代码拷贝到YAML编辑器。
source: type: mysql name: MySQL Source hostname: #{hostname} port: 3306 username: #{usernmae} password: #{password} tables: order_dw.\.* server-id: 28601-28604 route: - source-table: order_dw.\.* sink-table: topic_<> replace-symbol: <> sink: type: upsert-kafka name: upsert-kafka Sink properties.bootstrap.servers: xxxx.alikafka.aliyuncs.com:9092 # 阿里云消息队列Kafka版需要配置如下参数 aliyun.kafka.accessKeyId: #{ak} aliyun.kafka.accessKeySecret: #{sk} aliyun.kafka.instanceId: #{instanceId} aliyun.kafka.endpoint: #{endpoint} aliyun.kafka.regionId: #{regionId}单击右上方的部署,进行作业部署。
单击左侧导航栏的,单击目标作业操作列的启动,选择无状态启动后单击启动。
实时消费Kafka数据。
上游MySQL数据库中的数据会以JSON格式写入Kafka中,一个Kafka Topic可以提供给多个下游作业消费,下游作业消费Topic中的数据来获取数据库表的最新数据。对于同步到Kafka的表,消费方式有以下两种:
通过Catalog直接消费
作为源表,从Kafka Topic中读取数据。
在页面,新建SQL流作业,并将如下代码拷贝到SQL编辑器。
CREATE TEMPORARY TABLE print_user_proudct( order_id BIGINT, product STRING, user_name STRING ) WITH ( 'connector'='print', 'logger'='true' ); CREATE TEMPORARY TABLE print_user_feedback( feedback_id BIGINT, `comment` STRING, user_name STRING ) WITH ( 'connector'='print', 'logger'='true' ); BEGIN STATEMENT SET; --写入多个Sink时,必填。 -- 将订单信息和Kafka JSON Catalog中的用户表做join,展示每个订单的用户名和商品名。 INSERT INTO print_user_proudct SELECT `order`.key_id as order_id, value_product as product, `user`.value_name as user_name FROM `kafka-catalog`.`kafka`.`order`/*+OPTIONS('properties.group.id'='<yourGroupName>', 'scan.startup.mode'='earliest-offset')*/ as `order` --指定group和启动模式 LEFT JOIN `kafka-catalog`.`kafka`.`user`/*+OPTIONS('properties.group.id'='<yourGroupName>', 'scan.startup.mode'='earliest-offset')*/ as `user` --指定group和启动模式 ON `order`.value_user_id = `user`.key_id; -- 将评论和用户表做join,展示每个评论的内容和对应用户名。 INSERT INTO print_user_feedback SELECT feedback.key_id as feedback_id, value_comment as `comment`, `user`.value_name as user_name FROM `kafka-catalog`.`kafka`.feedback/*+OPTIONS('properties.group.id'='<yourGroupName>', 'scan.startup.mode'='earliest-offset')*/ as feedback --指定group和启动模式 LEFT JOIN `kafka-catalog`.`kafka`.`user`/*+OPTIONS('properties.group.id'='<yourGroupName>', 'scan.startup.mode'='earliest-offset')*/ as `user` --指定group和启动模式 ON feedback.value_user_id = `user`.key_id; END; --写入多个Sink时,必填。本示例通过Print连接器直接打印结果,您也可以输出到连接器的结果表中进一步分析计算。写入多个SINK语法,详情请参见INSERT INTO语句。
说明在直接使用时,由于可能发生了Schema变更,Kafka JSON Catalog解析出的Schema可能与MySQL对应表存在差异,例如出现已经删除的字段,部分字段可能出现为null的情况。
Catalog读取出的Schema由消费到的数据的字段组成。如果存在删除的字段且消息未过期,则会出现一些已经不存在的字段,这样的字段值会为null,该情况无需特殊处理。
单击右上方的部署,进行作业部署。
单击左侧导航栏的,单击目标作业操作列的启动,选择无状态启动后单击启动。
通过创建临时表的方式消费
自定义Schema,从临时表中读取数据。
在页面,新建SQL流作业,并将如下代码拷贝到SQL编辑器。
CREATE TEMPORARY TABLE user_source ( key_id BIGINT, value_name STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'user', 'properties.bootstrap.servers' = '<yourKafkaBrokers>', 'scan.startup.mode' = 'earliest-offset', 'key.format' = 'json', 'value.format' = 'json', 'key.fields' = 'key_id', 'key.fields-prefix' = 'key_', 'value.fields-prefix' = 'value_', 'value.fields-include' = 'EXCEPT_KEY', 'value.json.infer-schema.flatten-nested-columns.enable' = 'false', 'value.json.infer-schema.primitive-as-string' = 'false' ); CREATE TEMPORARY TABLE order_source ( key_id BIGINT, value_product STRING, value_user_id BIGINT ) WITH ( 'connector' = 'kafka', 'topic' = 'order', 'properties.bootstrap.servers' = '<yourKafkaBrokers>', 'scan.startup.mode' = 'earliest-offset', 'key.format' = 'json', 'value.format' = 'json', 'key.fields' = 'key_id', 'key.fields-prefix' = 'key_', 'value.fields-prefix' = 'value_', 'value.fields-include' = 'EXCEPT_KEY', 'value.json.infer-schema.flatten-nested-columns.enable' = 'false', 'value.json.infer-schema.primitive-as-string' = 'false' ); CREATE TEMPORARY TABLE feedback_source ( key_id BIGINT, value_user_id BIGINT, value_comment STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'feedback', 'properties.bootstrap.servers' = '<yourKafkaBrokers>', 'scan.startup.mode' = 'earliest-offset', 'key.format' = 'json', 'value.format' = 'json', 'key.fields' = 'key_id', 'key.fields-prefix' = 'key_', 'value.fields-prefix' = 'value_', 'value.fields-include' = 'EXCEPT_KEY', 'value.json.infer-schema.flatten-nested-columns.enable' = 'false', 'value.json.infer-schema.primitive-as-string' = 'false' ); CREATE TEMPORARY TABLE print_user_proudct( order_id BIGINT, product STRING, user_name STRING ) WITH ( 'connector'='print', 'logger'='true' ); CREATE TEMPORARY TABLE print_user_feedback( feedback_id BIGINT, `comment` STRING, user_name STRING ) WITH ( 'connector'='print', 'logger'='true' ); BEGIN STATEMENT SET; --写入多个Sink时,必填。 -- 将订单信息和Kafka JSON Catalog中的用户表做join,展示每个订单的用户名和商品名。 INSERT INTO print_user_proudct SELECT order_source.key_id as order_id, value_product as product, user_source.value_name as user_name FROM order_source LEFT JOIN user_source ON order_source.value_user_id = user_source.key_id; -- 将评论和用户表做join,展示每个评论的内容和对应用户名。 INSERT INTO print_user_feedback SELECT feedback_source.key_id as feedback_id, value_comment as `comment`, user_source.value_name as user_name FROM feedback_source LEFT JOIN user_source ON feedback_source.value_user_id = user_source.key_id; END; --写入多个Sink时,必填。本示例通过Print连接器直接打印结果,您也可以输出到连接器的结果表中进一步分析计算。写入多个SINK语法,详情请参见INSERT INTO语句。
临时表配置参数见下表:
参数
说明
备注
connector
Connector类型。
固定值为kafka。
topic
对应的Topic名称。
和Kafka JSON Catalog的描述保持一致。
properties.bootstrap.servers
Kafka Broker地址。
格式为
host:port,host:port,host:port,以英文逗号(,)分割。scan.startup.mode
Kafka读取数据的启动位点。
取值如下:
earliest-offset:从Kafka最早分区开始读取。
latest-offset:从Kafka最新位点开始读取。
group-offsets(默认值):从指定的properties.group.id已提交的位点开始读取。
timestamp:从scan.startup.timestamp-millis指定的时间戳开始读取。
specific-offsets:从scan.startup.specific-offsets指定的偏移量开始读取。
说明
该参数在作业无状态启动时生效。作业在从checkpoint重启或状态恢复时,会优先使用状态中保存的进度恢复读取。
key.format
Flink Kafka Connector在序列化或反序列化Kafka的消息键(Key)时使用的格式。
固定值为json。
key.fields
Kafka消息key部分对应的源表或结果表字段。
多个字段名以分号(;)分隔。例如
field1;field2。key.fields-prefix
为所有Kafka消息键(Key)指定自定义前缀,以避免与消息体(Value)或Metadata字段重名。
需要和Kafka JSON Catalog的key.fields-prefix参数值保持一致。
value.format
Flink Kafka Connector在序列化或反序列化Kafka的消息体(Value)时使用的格式。
固定值为json。
value.fields-prefix
为所有Kafka消息体(Value)指定自定义前缀,以避免与消息键(Key)或Metadata字段重名。
需要和Kafka JSON Catalog的value.fields-prefix参数值保持一致。
value.fields-include
定义消息体在处理消息键字段时的策略。
固定值为EXCEPT_KEY。表示消息体中不包含消息键的字段。
value.json.infer-schema.flatten-nested-columns.enable
Kafka消息体(Value)是否递归式地展开JSON中的嵌套列。
对应Catalog的infer-schema.flatten-nested-columns.enable参数配置值。
value.json.infer-schema.primitive-as-string
Kafka消息体(Value)是否推导所有基本类型为String类型。
对应Catalog的infer-schema.primitive-as-string参数配置值。
单击右上方的部署,进行作业部署。
单击左侧导航栏的,单击目标作业操作列的启动,选择无状态启动后单击启动。
查看作业结果。
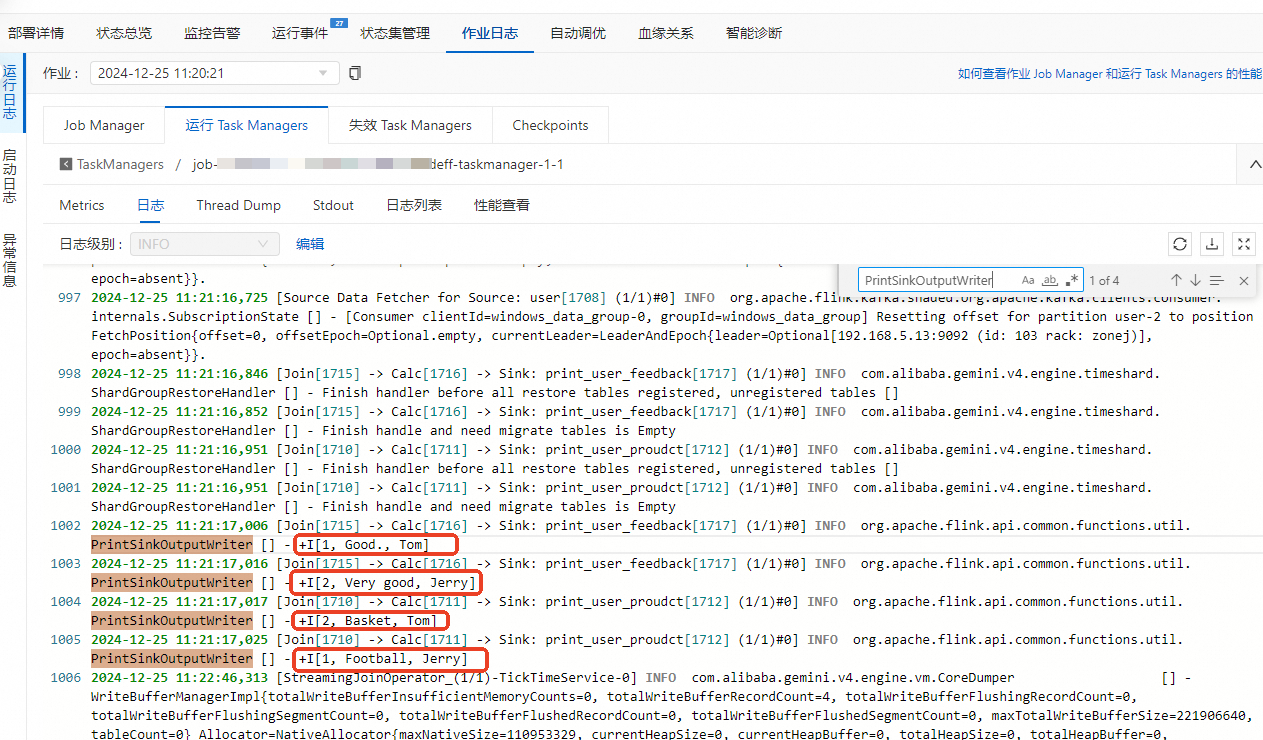
单击左侧导航栏的,单击目标作业。
在作业日志页签,单击运行Task Managers页签下的Path, ID的任务。
单击日志,在页面搜索
PrintSinkOutputWriter相关的日志信息。