
本文中含有需要您注意的重要提示信息,忽略该信息可能对您的业务造成影响,请务必仔细阅读。
配置MaxCompute Catalog后,您可以在Flink全托管作业开发中直接访问MaxCompute中存储的表,无需再定义Schema。本文为您介绍如何在Flink全托管模式下创建、查看、使用及删除MaxCompute Catalog。
背景信息
MaxCompute Catalog通过查询MaxCompute服务来获取MaxCompute中已存储物理表的Schema信息,您无需在Flink SQL中声明MaxCompute连接表的Schema便可以获取具体的字段信息。MaxCompute Catalog具有以下功能特点:
MaxCompute Catalog中的数据库名对应MaxCompute的项目名,您可以通过切换数据库来使用不同MaxCompute项目中的表。
MaxCompute Catalog中的表名对应MaxCompute中存储的物理表名,自动映射数据类型,无需再通过DDL语句手动注册MaxCompute表,提升开发效率和正确性。
MaxCompute Catalog提供的表可以直接作为Flink SQL作业中的源表、维表和结果表使用。
在MaxCompute Catalog中创建表能够自动在MaxCompute服务中创建对应的物理表,并自动映射数据类型,提升开发效率。
本文将从以下方面为您介绍如何管理MaxCompute Catalog:
使用限制
仅Flink计算引擎VVR 6.0.7及以上版本支持配置MaxCompute Catalog。
MaxCompute Catalog不支持创建数据库,即MaxCompute中的项目。
MaxCompute Catalog不支持修改表结构。
MaxCompute Catalog不支持CREATE TABLE AS(CTAS)语句。
创建MaxCompute Catalog
支持UI与SQL命令两种方式配置MaxCompute Catalog,推荐使用UI方式配置MaxCompute Catalog。
UI方式(推荐)
进入数据管理页面。
登录实时计算控制台,单击目标工作空间操作列下的控制台。
单击数据管理。
单击创建Catalog,选择ODPS后,单击下一步。
填写参数配置信息。
重要Catalog创建完成后,以下配置信息都不支持修改。如果需要修改,您需要删除掉已创建的Catalog,重新进行创建。
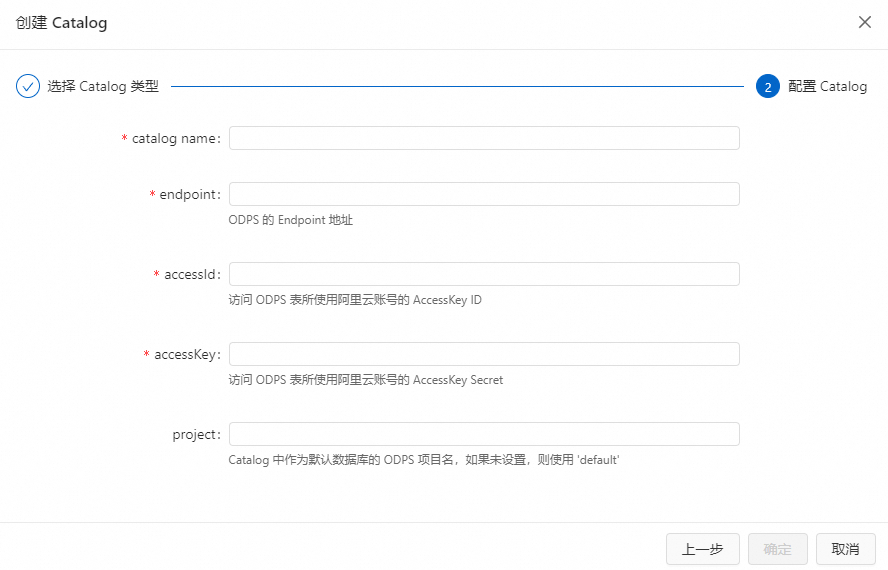
参数
说明
类型
是否必填
备注
catalog name
MaxCompute Catalog的名称。
String
是
请填写为自定义的英文名。
endpoint
MaxCompute服务连接站点。
String
是
具体站点请参见Endpoint。
accessId
访问MaxCompute服务所使用阿里云账号的AccessKey ID。
String
是
该账号需要对Catalog访问的项目有admin权限。
accessKey
访问MaxCompute服务所使用阿里云账号的AccessKey Secret。
String
是
无。
project
Catalog中作为默认数据库的MaxCompute项目名。
String
否
若不设置该值,默认项目为default。
说明Catalog创建成功后,元数据中将展示您填写的项目和您上述填写的阿里云账号所创建的项目。
catalog.schema.enabled
Flink Catalog概念中的Database是否映射为Schema层级。
Boolean
否
Schema是用于对Project下的Table、Resource、UDF进行归类的机制。一个Project下可以包含多个Schema。详情请参见Schema操作。
参数取值如下:
false(默认值):Flink Catalog概念中的Database映射为MaxCompute Project。适用于未开启Schema功能的MaxCompute服务。
true:Flink Catalog概念中的Database映射为MaxCompute Schema。适用于已开启Schema功能的MaxCompute服务。
单击确定。
创建完成后,元数据下即可查看新建的Catalog。
重要如果创建Catalog使用的AK/SK权限不具备项目权限,则相应项目的信息也不会显示在元数据中,但不影响对Catalog的正常读写。
SQL方式
在数据查询文本编辑区域,输入配置MaxCompute Catalog的命令。
CREATE CATALOG `<catalogName>` WITH ( 'type' = 'odps', 'endpoint' = '<odpsEndpoint>', 'accessId' = '<aliyunAccountAccessId>', 'accessKey' = '<aliyunAccountAccessKey>', 'project' = '<defaultProject>', 'userAccount' = '<RAMUserAccount>' );参数详情如下表所示。
参数
说明
类型
是否必填
备注
catalogName
MaxCompute Catalog的名称。
String
是
请填写为自定义的英文名。
type
Catalog类型。
String
是
固定值为odps。
endpoint
MaxCompute服务连接站点。
String
是
具体站点请参见Endpoint。
accessId
访问MaxCompute服务所使用阿里云账号的AccessKey ID。
String
是
该账号需要对Catalog访问的项目有admin权限。
accessKey
访问MaxCompute服务所使用阿里云账号的AccessKey Secret。
String
是
无。
project
Catalog中作为默认数据库的MaxCompute项目名。
String
否
若不设置该值,默认项目为default。
userAccount
阿里云账号或RAM用户名称。
String
否
若使用的AccessKey非主账号,仅对主账号下的部分项目有admin权限,则需要设置该参数为账号名称,例如
RAM$[<account_name>:]<RAM_name>,MaxCompute Catalog将仅展示该账号有权限的项目列表。MaxCompute用户权限管理参见用户规划与管理。
选中创建Catalog的代码后,单击左侧代码行数上的运行。

查看MaxCompute Catalog
UI方式(推荐)
进入数据管理页面。
登录实时计算控制台。
单击目标工作空间操作列下的控制台。
单击数据管理。
在Catalog列表页面,查看Catalog名称和类型。
如果您需要查看目标Catalog下的数据库和表,请单击查看。
SQL方式
在数据查询文本编辑区域,输入以下命令:
DESCRIBE `<catalogName>`.`<projectName>`.`<tableName>`;参数
说明
catalogName
MaxCompute Catalog名称。
projectName
MaxCompute中的项目名。
tableName
MaxCompute中存储的物理表名。
选中查看Catalog的代码后,单击左侧代码行数上的运行。
运行成功后,可以在编辑区域下方的结果一栏中看到MaxCompute物理表在Flink中对应的Schema信息。
使用MaxCompute Catalog
通过Catalog创建MaxCompute物理表
通过Flink SQL DDL,在MaxCompute Catalog中创建表时,会自动在对应的MaxCompute项目中创建对应的物理表,并自动将Flink中的类型转换为MaxCompute中的类型,支持创建非分区表和分区表。
创建非分区表示例:
CREATE TABLE `<catalogName>`.`<projectName>`.`<tableName>` (
f0 INT,
f1 BIGINT,
f2 DOUBLE,
f3 STRING
);执行完成后,您可以在MaxCompute中查看对应项目中的表,可以看到已创建对应名字的非分区表,其列名称、类型与Flink DDL中对应。
创建分区表示例:
CREATE TABLE `<catalogName>`.`<projectName>`.`<tableName>` (
f0 INT,
f1 BIGINT,
f2 DOUBLE,
f3 STRING,
ds STRING
) PARTITIONED BY (ds);在Flink DDL的Schema末尾添加分区列,并在PARTITIONED BY语句中声明分区列名,执行完成后查看对应MaxCompute项目中的表,可以看到已创建对应名字的分区表,其普通列为f0、f1、f2、f3,分区列为ds。
MaxCompute中列名均为小写,而Flink中列名区分大小写,若DDL中列名包含大写字母将被自动转换成小写,若DDL中包含多个转换成小写后同名的列,则会报错。
从MaxCompute Catalog表中读取数据
MaxCompute Catalog能够从MaxCompute服务读取物理表的Schema,因此无需在Flink中声明对应Schema即可直接读取数据。例如:
SELECT * FROM `<catalogName>`.`<projectName>`.`<tableName>`;不声明任何参数的默认行为为全量读取所有分区,若您需要读取特定分区,或使用增量源表模式,可以参考大数据计算服务MaxCompute中的参数设置,在SQL注释中声明,例如:
读取特定分区:
SELECT * FROM `<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('partition' = 'ds=230613') */;使用增量源表模式:
SELECT * FROM `<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('startPartition' = 'ds=230613') */;使用维表模式:
SELECT * FROM `<anotherTable>` AS l LEFT JOIN
`<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('partition' = 'max_pt()', 'cache' = 'ALL') */
FOR SYSTEM_TIME AS OF l.proc_time AS r
ON l.id = r.id;其他大数据计算服务MaxCompute中支持的源表和维表参数均可以通过该方式进行设置。但需要注意的是,MaxCompute Catalog中不保存Watermark信息,若需要在以源表读取数据时指定Watermark,可以使用CREATE TABLE ... LIKE ...语句,例如:
CREATE TABLE `<newTable>` ( WATERMARK FOR ts AS ts )
LIKE `<catalogName>`.`<projectName>`.`<tableName>`;其中ts为MaxCompute物理表中类型为DATETIME的列,该类型可以在Flink中被设置为事件时间并添加Watermark信息,创建完成后,从newTable读取的数据均带有Watermark。
向MaxCompute Catalog表中写入数据
MaxCompute Catalog支持以固定分区或动态分区模式写入数据,参见大数据计算服务MaxCompute。例如有MaxCompute物理表有二级分区ds和hh,可以使用如下语句写入数据:
-- 写入固定分区
INSERT INTO `<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('partition' = 'ds=20231024,hh=09') */
SELECT <otherColumns>, '20231024', '09' FROM `<anotherTable>`;
-- 写入动态分区
INSERT INTO `<catalogName>`.`<projectName>`.`<tableName>`
/*+ OPTIONS('partition' = 'ds,hh') */
SELECT <otherColumns>, ds, hh FROM `<anotherTable>`;SELECT中,分区列需要按分区层级顺序放置在其他普通列之后。
删除MaxCompute Catalog
删除MaxCompute Catalog不会影响已运行的作业,但会导致使用该Catalog下表的作业,在上线或重启时报无法找到该表的错误,请您谨慎操作。
UI方式
进入数据管理页面。
登录实时计算控制台。
单击目标工作空间操作列下的控制台。
单击数据管理。
在Catalog列表页面,单击目标Catalog名称对应操作列下的删除。
在弹出的对话框中,单击删除。
说明删除完成后,在左侧元数据区域下即可查看目标Catalog已删除。
SQL命令方式
在数据查询文本编辑区域,输入以下命令。
DROP CATALOG `<catalogName>`;其中,<catalogName>为您要删除的目标MaxCompute Catalog名称。
警告删除MaxCompute Catalog不会影响已运行的作业,但对未上线或者需要暂停恢复的作业均产生影响,请您谨慎操作。
选中删除Catalog的命令,鼠标右键选择运行。
在左侧元数据区域,查看目标Catalog是否已删除。
MaxCompute与Flink的类型映射
MaxCompute支持的类型参见2.0数据类型版本。
MaxCompute至Flink
读取已有MaxCompute物理表时,字段的MaxCompute类型将按下表映射为Flink类型。
MaxCompute类型 | Flink类型 |
BOOLEAN | BOOLEAN |
TINYINT | TINYINT |
SMALLINT | SMALLINT |
INT | INTEGER |
BIGINT | BIGINT |
FLOAT | FLOAT |
DOUBLE | DOUBLE |
DECIMAL(precision, scale) | DECIMAL(precision, scale) |
CHAR(n) | CHAR(n) |
VARCHAR(n) | VARCHAR(n) |
STRING | STRING |
BINARY | BYTES |
DATE | DATE |
DATETIME | TIMESTAMP(3) |
TIMESTAMP | TIMESTAMP(9) |
ARRAY | ARRAY |
MAP | MAP |
STRUCT | ROW |
JSON | STRING |
Flink至MaxCompute
通过Flink DDL在Catalog创建MaxCompute表时,Flink DDL中的字段类型将按下表映射为MaxCompute类型。
Flink类型 | MaxCompute类型 |
BOOLEAN | BOOLEAN |
TINYINT | TINYINT |
SMALLINT | SMALLINT |
INTEGER | INT |
BIGINT | BIGINT |
FLOAT | FLOAT |
DOUBLE | DOUBLE |
DECIMAL(precision, scale) | DECIMAL(precision, scale) |
CHAR(n) | CHAR(n) |
VARCHAR / STRING | STRING |
BINARY | BINARY |
VARBINARY / BYTES | BINARY |
DATE | DATE |
TIMESTAMP(n<=3) | DATETIME |
TIMESTAMP(3<n<=9) | TIMESTAMP |
ARRAY | ARRAY |
MAP | MAP |
ROW | STRUCT |