
本文介绍在使用函数计算部署AI推理应用时,模型存储的常用方法,并对这些方法的优缺点和适用场景进行比较分析。
背景信息
函数的存储类型请参见函数存储选型。其中,适合用作GPU存储模型的包括以下两种。
除此之外,GPU函数使用自定义容器镜像部署业务,因此还可以将模型文件直接放置到容器镜像中。
每种方法都有其独特的应用场景和技术特点,选择模型存储方式时应当考虑具体需求、执行环境以及团队的工作流程,以达到模型存储在效率和成本上的平衡。
模型随容器镜像分发
将训练好的模型和相关应用代码一起打包在容器镜像中,模型文件随容器镜像分发,这是最直接的方法之一。
优缺点
优点:
便利性:创建好镜像后,可以直接运行它进行推理而无需额外配置。
一致性:确保每个环境中的模型版本都是一致的,减少了由于不同环境中模型版本差异导致的问题。
缺点:
镜像体积:镜像可能会非常大,特别是对于大尺寸模型。
更新耗时:每次模型更新时都需要重新构建和分发镜像,这可能是一个耗时的过程。
说明
为了提升函数实例的冷启动速度,平台会对容器镜像进行预处理。如果镜像尺寸过大,一方面可能会超出平台对镜像大小的限制,另一方面也会导致镜像加速预处理所需时间的延长。
关于平台镜像大小限制,请参见GPU镜像大小限制是多少?
关于镜像预处理和函数状态的信息,请参见自定义镜像函数状态及调用。
使用场景
模型尺寸相对较小,例如百兆字节左右。
模型变更频率较低,可以考虑将模型打包在容器镜像中。
如果您的模型文件较大、迭代频繁或随镜像发布时超过平台镜像大小限制,建议模型与镜像分离。
模型放在NAS文件存储
函数计算平台支持将NAS文件系统挂载到函数实例的指定目录,将模型存储在NAS文件系统,应用程序通过访问NAS挂载点目录实现模型文件的加载。
优缺点
优点:
兼容性:相比
FUSE类文件系统,NAS提供的POSIX文件接口较为完整和成熟,因此在应用兼容性方面表现较好。容量:NAS能够提供PiB级的存储容量。
缺点:
依赖VPC网络:一方面,需要为函数配置VPC访问通道才能访问NAS挂载点,在配置时涉及的云产品权限点相对较多;另一方面,函数实例冷启动时,平台为实例建立VPC访问通道会产生秒级的耗时。
内容管理方式比较单一:NAS文件系统需要挂载才能使用,相对单一,需要建立相应的业务流程将模型文件分发到NAS实例上。
不支持双活和多AZ,详情请参见NAS常见问题。
说明
在大量容器同时启动加载模型的场景下,容易触及NAS的带宽瓶颈,导致实例启动耗时增加,甚至因超时而失败。例如,定时HPA批量设置GPU快照、突发流量触发大量弹性GPU实例的创建。
可以从控制台查看NAS性能监控(读吞吐)。
可以通过向NAS增加数据量的方式来提升NAS读写吞吐量。
采用NAS来存储模型文件,建议选用通用型NAS中的“性能型”,其主要原因在于该类型NAS可以提供较高的初始读带宽,约600MB/s,详情请参见通用型NAS。
使用场景
在函数计算弹性GPU实例时,需要快速的启动性能。
模型放在OSS对象存储
函数计算平台支持将对象存储OSS Bucket挂载到函数实例的指定目录,应用程序可以直接从OSS挂载点加载模型。
优点
带宽:OSS的带宽上限较高,相比NAS不易出现函数实例间带宽争抢现象,详情请见OSS使用限制及性能指标。与此同时,还可以通过开通OSS加速器获得更高的吞吐能力。
管理方法多样:
配置简单:相比NAS文件系统,函数实例挂载OSS Bucket无需打通VPC,即配即用。
成本:若仅比较容量和吞吐速率,相比NAS,一般来说OSS的成本更优。
说明
从实现原理上,OSS挂载使用FUSE用户态文件系统机制实现。应用访问OSS挂载点上的文件时,平台最终将其转换为OSS API调用实现对数据的访问。因此OSS挂载还有以下特征:
其工作在用户态,会占用函数实例的资源配额,如CPU、内存、临时存储等,因此建议在较大规格的GPU实例上使用。
数据的访问使用OSS API,其吞吐量和时延最终受限于OSS API服务,因此更适合访问数量较少的大文件(如模型加载场景),不宜用于访问大量小文件。
相比随机读写,OSS挂载对顺序读写更友好。特别地,在加载大文件时,顺序读将能够充分利用文件系统的预读机制,从而达到更优的网络吞吐速率和加载时延。
以safetensors文件为例,使用针对顺序读优化过的版本将大幅缩短从OSS挂载点加载模型文件的耗时:load_file: load tensors ordered by their offsets。
若无法调整应用的IO模式,则可以考虑在加载文件前,先顺序读取一遍文件,将内容预热到系统PageCache,应用后续将从PageCache加载文件。
使用场景
大量实例并行加载模型,需要更高的存储吞吐能力,以避免实例间带宽不足的情况。
需要本地冗余,或者多地域部署的场景。
访问数量较少的大文件(比如模型加载场景),并且IO模式为顺序读取。
总结对比
对比项 | 随镜像分发 | NAS挂载 | OSS挂载 |
模型尺寸 |
| 无 | 无 |
吞吐 | 较快 |
|
|
兼容性 | 好 | 好 |
|
IO模式适应能力 | 好 | 好 | 适合顺序读写场景。随机读需转化为PageCache访问以获得更优吞吐 |
管理方法 | 容器镜像 | VPC内挂载后使用 |
|
多AZ | 支持 | 不支持 | 支持 |
成本 | 不产生额外费用 | 一般来说NAS比OSS略高,请以各产品当前计费规则为准
| |
基于以上对比,根据FC GPU不同使用模式、不同容器并发启动数量、不同模型管理需求等维度,FC GPU模型托管的最佳实践如下:
测试数据
本文介绍以下两种方式,通过对比不同场景下不同存储介质加载文件的耗时,来分析其性能差异,耗时越低,代表存储性能越高。
方式一:不同模型的文件加载耗时
测量从不同存储介质加载模型权重文件safetensors至GPU显存的耗时,对比不同模型下不同存储方式的性能差异。
测试环境
实例规格:Ada卡型,8核,64GB内存
OSS加速器容量:10T,对应最大吞吐为3000MB/s
NAS规格:通用性能型,容量对应最大吞吐为600MB/s
safetensors版本
0.5.3本次测试的选取的模型和模型尺寸大小如下表:
模型
尺寸(GB)
Anything-v4.5-pruned-mergedVae.safetensors
3.97
Anything-v5.0-PRT-RE.safetensors
1.99
CounterfeitV30_v30.safetensors
3.95
Deliberate_v2.safetensors
1.99
DreamShaper_6_NoVae.safetensors
5.55
cetusMix_Coda2.safetensors
3.59
chilloutmix_NiPrunedFp32Fix.safetensors
3.97
flux1-dev.safetensors
22.2
revAnimated_v122.safetensors
5.13
sd_xl_base_1.0.safetensors
6.46
结果展示
如下图所示,纵坐标代表时间,横坐标代表不同的模型以及ossfs,accel、ossfs和nas三种模型存储方式。
柱体颜色 | 存储方式 | 技术特性 |
蓝色 | ossfs,accel | OSS加速器Endpoint |
橙色 | ossfs | 普通OSS Endpoint |
灰色 | nas | NAS文件系统挂载点 |
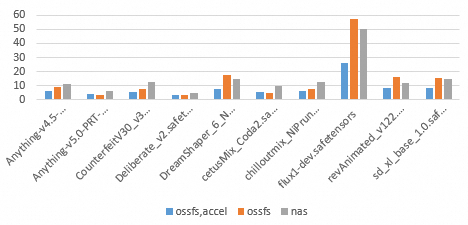
测试结论
吞吐能力:OSS存储相较NAS的核心优势在于吞吐性能,测试数据显示,普通OSS Endpoint的读吞吐也经常可达600MB/s或以上。
随机读影响:在个别文件的表现上,如相对较大的flux1-dev.safetensors和较小的revAnimated_v122.safetensors,普通OSS相比OSS加速器耗时明显增加,比NAS耗时也更长,这既源于平台针对OSS加速器所做的随机读优化效果,也因NAS相比普通OSS在随机读场景下表现得更可预期。
方式二:不同并发的文件加载耗时
使用22.2GB大模型 flux1-dev.safetensors,测试 4/8/16 并发下加载flux1-dev.safetensors文件至GPU显存的时延分布。
测试环境
实例规格:Ada.3,8核,64GB内存
OSS加速器容量:80T,对应最大吞吐为24000MB/s
NAS规格:通用性能型,容量对应最大吞吐为600MB/s
safetensors版本
0.5.3
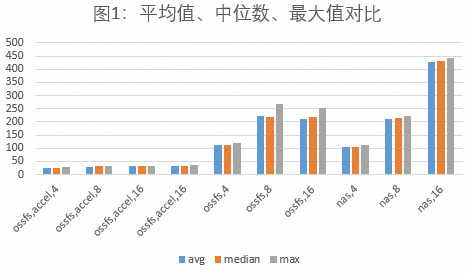
结果展示
如下图1所示,统计不同存储方式,包括ossfs,accel,N、ossfs,N和nas,N在不同并发下的最大耗时、平均耗时和耗时中位数。N表示最小实例数。
存储方式 | 技术特性 |
ossfs,accel,N | OSS加速器Endpoint |
ossfs,N | 普通OSS Endpoint |
nas,N | NAS文件系统挂载点 |
柱体颜色 | 代表数值 |
蓝色 | 平均耗时 |
橙色 | 耗时中位数 |
灰色 | 最大耗时 |
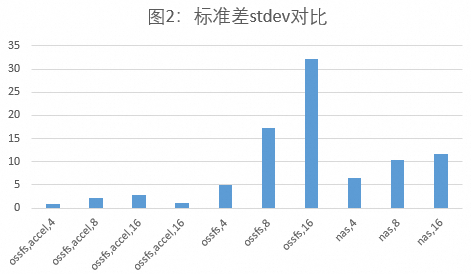
如下图2,统计不同存储方式,包括ossfs,accel,N、ossfs,N和nas,N在不同并发下的标准差,N表示最小实例数。
测试结论
吞吐能力:OSS存储相较 NAS 的核心优势在于吞吐性能,OSS加速器优势更显著。普通OSS的吞吐能力也经常能超过600MB/s,而OSS加速器的吞吐能力更可达到预期值(见图1)。
稳定性:在高实例并发场景下,普通OSS相比NAS有更低的加载时延,但是标准差更高,这种情况下,NAS比普通OSS的吞吐能力更可预期(见图2)。
需要注意的是:加载不同safetensors文件时产生的随机IO情况不一样,相较于NAS,对从普通OSS挂载加载模型的耗时影响更明显。